 電子發(fā)燒友App
電子發(fā)燒友App


圖像閾值化分割是一種傳統(tǒng)的最常用的圖像分割方法,因其實現(xiàn)簡單、計算量小、性能較穩(wěn)定而成為圖像分割中最基本和應(yīng)用最廣泛的分割技術(shù)。它特別適用于目標和背景占據(jù)不同灰度級范圍的圖像。它不僅可以極大的壓縮數(shù)據(jù)量,而且也大大簡化了分析和處理步驟,因此在很多情況下,是進行圖像分析、特征提取與模式識別之前的必要的圖像預(yù)處理過程。
圖像閾值化的目的是要按照灰度級,對像素集合進行一個劃分,得到的每個子集形成一個與現(xiàn)實景物相對應(yīng)的區(qū)域,各個區(qū)域內(nèi)部具有一致的屬性,而相鄰區(qū)域不具有這種一致屬性。這樣的劃分可以通過從灰度級出發(fā)選取一個或多個閾值來實現(xiàn)。
基本原理
基本原理是:通過設(shè)定不同的特征閾值,把圖像象素點分為若干類。
常用的特征包括:直接來自原始圖像的灰度或彩色特征;由原始灰度或彩色值變換得到的特征。
設(shè)原始圖像為f(x,y),按照一定的準則f(x,y)中找到特征值T,將圖像分割為兩個部分,分割后的圖像為:
若取:b0=0(黑),b1=1(白),即為我們通常所說的圖像二值化。
圖像分割的意義:
在一幅圖像中,人們常常只對其中的部分目標感興趣,這些目標通常占據(jù)一定的區(qū)域,并且在某些特性(如灰度、輪廓、顏色和紋理等)上和臨近的圖像有差別。這些特性差別可能非常明顯,也可能很細微,以至肉眼察覺不出來。隨著計算機圖像處理技術(shù)的發(fā)展,使得人們可以通過計算機來獲取和處理圖像信息。圖像識別的基礎(chǔ)是圖像分割,其作用是把反映物體真實情況的、占據(jù)不同區(qū)域的、具有不同特性的目標區(qū)分開來,并形成數(shù)字特征。圖像分割是圖像識別和圖像理解的基本前提步驟,圖像分割質(zhì)量的好壞直接影響后續(xù)圖像處理的效果,甚至決定其成敗,因此,圖像分割的作用是至關(guān)重要的。
函數(shù)原型
1、opencv官方介紹:opencv官方grabcut介紹
2、網(wǎng)上童鞋翻譯解釋:學(xué)習(xí)OpenCV——學(xué)習(xí)grabcut算法
3、大致內(nèi)容如下:
函數(shù)原型:
void grabCut(InputArray img, InputOutputArray mask, Rect rect,
InputOutputArray bgdModel, InputOutputArray fgdModel,
int iterCount, int mode=GC_EVAL )
img:待分割的源圖像,必須是8位3通道(CV_8UC3)圖像,在處理的過程中不會被修改;
mask:掩碼圖像,大小和原圖像一致。可以有如下幾種取值:
GC_BGD(=0),背景;
GC_FGD(=1),前景;
GC_PR_BGD(=2),可能的背景;
GC_PR_FGD(=3),可能的前景。
rect:用于限定需要進行分割的圖像范圍,只有該矩形窗口內(nèi)的圖像部分才被處理;
bgdModel:背景模型,如果為null,函數(shù)內(nèi)部會自動創(chuàng)建一個bgdModel;
fgdModel:前景模型,如果為null,函數(shù)內(nèi)部會自動創(chuàng)建一個fgdModel;
iterCount:迭代次數(shù),必須大于0;
mode:用于指示grabCut函數(shù)進行什么操作。可以有如下幾種選擇:
GC_INIT_WITH_RECT(=0),用矩形窗初始化GrabCut;
GC_INIT_WITH_MASK(=1),用掩碼圖像初始化GrabCut;
GC_EVAL(=2),執(zhí)行分割。
基本原理:
首先用戶在圖片上畫一個方框,grabCut默認方框內(nèi)部為前景,設(shè)置掩碼為2,方框外部都是背景,設(shè)置掩碼為0。然后根據(jù)算法,
將方框內(nèi)部檢查出來是背景的位置,掩碼由2改為0。最后,經(jīng)過算法處理,方框中掩碼依然為2的,就是檢查出來的前景,其他為背景。
實例講解1
這些例子都主要是根據(jù)opencv自帶的例子:opencvsamplescppgrabcut.cpp 簡化修改而來。
源代碼
代碼如下:
#include “opencv2/highgui/highgui.hpp”
#include “opencv2/imgproc/imgproc.hpp”
#include 《iostream》
using namespace std;
using namespace cv;
string filename;
Mat image;
string winName = “show”;
Rect rect;
Mat mask;
const Scalar GREEN = Scalar(0,255,0);
Mat bgdModel, fgdModel;
void setRectInMask(){
rect.x = 110;
rect.y = 220;
rect.width = 100;
rect.height = 100;
}
static void getBinMask( const Mat& comMask, Mat& binMask ){
binMask.create( comMask.size(), CV_8UC1 );
binMask = comMask & 1;
}
int main(int argc, char* argv[]){
Mat binMask, res;
filename = argv[1];
image = imread( filename, 1 );
mask.create(image.size(), CV_8UC1);
mask.setTo(GC_BGD);
setRectInMask();
(mask(rect)).setTo(Scalar(GC_PR_FGD));
rectangle(image, Point(rect.x, rect.y), Point(rect.x + rect.width, rect.y + rect.height ), GREEN, 2);
imshow(winName, image);
image = imread( filename, 1 );
grabCut(image, mask, rect, bgdModel, fgdModel, 1, GC_INIT_WITH_RECT);
getBinMask(mask, binMask);
image.copyTo(res, binMask);
imshow(“result”, res);
waitKey(0);
return 0;
}.
代碼講解
1、首先是裝載需要處理的源圖片。
filename = argv[1];
image = imread( filename, 1 );
2、設(shè)置掩碼,首先創(chuàng)建了一個和源圖片一樣大小的掩碼空間。接著將整個掩碼空間設(shè)置為背景:GC_BGD。接著創(chuàng)建了一個rect,對應(yīng)左上角坐標為:
(110,220),長寬都為100。接著在掩碼空間mask對應(yīng)左邊位置的掩碼設(shè)置為GC_PR_FGD(疑似為前景)。這個rect就是需要分離前景背景的空間。同時
在源圖像上,rect對應(yīng)的需要被處理位置畫出綠色方框框選。接著將畫了綠色方框之后的源圖片顯示出來。
mask.create(image.size(), CV_8UC1);
mask.setTo(GC_BGD);
setRectInMask();
(mask(rect)).setTo(Scalar(GC_PR_FGD));
rectangle(image, Point(rect.x, rect.y), Point(rect.x + rect.width, rect.y + rect.height ), GREEN, 2);
imshow(winName, image);
3、之前的源圖像被畫了綠色方框,所以需要重新裝載一遍源圖像。接著使用函數(shù)grabCut,根據(jù)傳入的相關(guān)參數(shù),進行前景背景分離操作。最后在生成的
結(jié)果保存在mask中,背景被置為0,前景被置為1。接著將mask結(jié)果篩選到binMask中。最后使用image.copyTo(res, binMask);將原圖像根據(jù)binMask作為掩碼,
將篩選出來的前景復(fù)制到目標圖像res中。并將目標圖像顯示出來。
效果演示
圖像融合(去裂縫處理)
從下圖可以看出,兩圖的拼接并不自然,原因就在于拼接圖的交界處,兩圖因為光照色澤的原因使得兩圖交界處的過渡很糟糕,所以需要特定的處理解決這種不自然。這里的處理思路是加權(quán)融合,在重疊部分由前一幅圖像慢慢過渡到第二幅圖像,即將圖像的重疊區(qū)域的像素值按一定的權(quán)值相加合成新的圖像。
//優(yōu)化兩圖的連接處,使得拼接自然
void OptimizeSeam(Mat& img1, Mat& trans, Mat& dst)
{
int start = MIN(corners.left_top.x, corners.left_bottom.x);//開始位置,即重疊區(qū)域的左邊界
double processWidth = img1.cols - start;//重疊區(qū)域的寬度
int rows = dst.rows;
int cols = img1.cols; //注意,是列數(shù)*通道數(shù)
double alpha = 1;//img1中像素的權(quán)重
for (int i = 0; i 《 rows; i++)
{
uchar* p = img1.ptr《uchar》(i); //獲取第i行的首地址
uchar* t = trans.ptr《uchar》(i);
uchar* d = dst.ptr《uchar》(i);
for (int j = start; j 《 cols; j++)
{
//如果遇到圖像trans中無像素的黑點,則完全拷貝img1中的數(shù)據(jù)
if (t[j * 3] == 0 && t[j * 3 + 1] == 0 && t[j * 3 + 2] == 0)
{
alpha = 1;
}
else
{
//img1中像素的權(quán)重,與當前處理點距重疊區(qū)域左邊界的距離成正比,實驗證明,這種方法確實好
alpha = (processWidth - (j - start)) / processWidth;
}
d[j * 3] = p[j * 3] * alpha + t[j * 3] * (1 - alpha);
d[j * 3 + 1] = p[j * 3 + 1] * alpha + t[j * 3 + 1] * (1 - alpha);
d[j * 3 + 2] = p[j * 3 + 2] * alpha + t[j * 3 + 2] * (1 - alpha);
}
}
驗證拼接效果
最后給出完整的SURF算法實現(xiàn)的拼接代碼。
#include “highgui/highgui.hpp”
#include “opencv2/nonfree/nonfree.hpp”
#include “opencv2/legacy/legacy.hpp”
#include 《iostream》
using namespace cv;
using namespace std;
void OptimizeSeam(Mat& img1, Mat& trans, Mat& dst);
typedef struct
{
Point2f left_top;
Point2f left_bottom;
Point2f right_top;
Point2f right_bottom;
}four_corners_t;
four_corners_t corners;
void CalcCorners(const Mat& H, const Mat& src)
{
double v2[] = { 0, 0, 1 };//左上角
double v1[3];//變換后的坐標值
Mat V2 = Mat(3, 1, CV_64FC1, v2); //列向量
Mat V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
//左上角(0,0,1)
cout 《《 “V2: ” 《《 V2 《《 endl;
cout 《《 “V1: ” 《《 V1 《《 endl;
corners.left_top.x = v1[0] / v1[2];
corners.left_top.y = v1[1] / v1[2];
//左下角(0,src.rows,1)
v2[0] = 0;
v2[1] = src.rows;
v2[2] = 1;
V2 = Mat(3, 1, CV_64FC1, v2); //列向量
V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
corners.left_bottom.x = v1[0] / v1[2];
corners.left_bottom.y = v1[1] / v1[2];
//右上角(src.cols,0,1)
v2[0] = src.cols;
v2[1] = 0;
v2[2] = 1;
V2 = Mat(3, 1, CV_64FC1, v2); //列向量
V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
corners.right_top.x = v1[0] / v1[2];
corners.right_top.y = v1[1] / v1[2];
//右下角(src.cols,src.rows,1)
v2[0] = src.cols;
v2[1] = src.rows;
v2[2] = 1;
V2 = Mat(3, 1, CV_64FC1, v2); //列向量
V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
corners.right_bottom.x = v1[0] / v1[2];
corners.right_bottom.y = v1[1] / v1[2];
}
int main(int argc, char *argv[])
{
Mat image01 = imread(“g5.jpg”, 1); //右圖
Mat image02 = imread(“g4.jpg”, 1); //左圖
imshow(“p2”, image01);
imshow(“p1”, image02);
//灰度圖轉(zhuǎn)換
Mat image1, image2;
cvtColor(image01, image1, CV_RGB2GRAY);
cvtColor(image02, image2, CV_RGB2GRAY);
//提取特征點
SurfFeatureDetector Detector(2000);
vector《KeyPoint》 keyPoint1, keyPoint2;
Detector.detect(image1, keyPoint1);
Detector.detect(image2, keyPoint2);
//特征點描述,為下邊的特征點匹配做準備
SurfDescriptorExtractor Descriptor;
Mat imageDesc1, imageDesc2;
Descriptor.compute(image1, keyPoint1, imageDesc1);
Descriptor.compute(image2, keyPoint2, imageDesc2);
FlannBasedMatcher matcher;
vector《vector《DMatch》 》 matchePoints;
vector《DMatch》 GoodMatchePoints;
vector《Mat》 train_desc(1, imageDesc1);
matcher.add(train_desc);
matcher.train();
matcher.knnMatch(imageDesc2, matchePoints, 2);
cout 《《 “total match points: ” 《《 matchePoints.size() 《《 endl;
// Lowe‘s algorithm,獲取優(yōu)秀匹配點
for (int i = 0; i 《 matchePoints.size(); i++)
{
if (matchePoints[i][0].distance 《 0.4 * matchePoints[i][1].distance)
{
GoodMatchePoints.push_back(matchePoints[i][0]);
}
}
Mat first_match;
drawMatches(image02, keyPoint2, image01, keyPoint1, GoodMatchePoints, first_match);
imshow(“first_match ”, first_match);
vector《Point2f》 imagePoints1, imagePoints2;
for (int i = 0; i《GoodMatchePoints.size(); i++)
{
imagePoints2.push_back(keyPoint2[GoodMatchePoints[i].queryIdx].pt);
imagePoints1.push_back(keyPoint1[GoodMatchePoints[i].trainIdx].pt);
}
//獲取圖像1到圖像2的投影映射矩陣 尺寸為3*3
Mat homo = findHomography(imagePoints1, imagePoints2, CV_RANSAC);
////也可以使用getPerspectiveTransform方法獲得透視變換矩陣,不過要求只能有4個點,效果稍差
//Mat homo=getPerspectiveTransform(imagePoints1,imagePoints2);
cout 《《 “變換矩陣為: ” 《《 homo 《《 endl 《《 endl; //輸出映射矩陣
//計算配準圖的四個頂點坐標
CalcCorners(homo, image01);
cout 《《 “l(fā)eft_top:” 《《 corners.left_top 《《 endl;
cout 《《 “l(fā)eft_bottom:” 《《 corners.left_bottom 《《 endl;
cout 《《 “right_top:” 《《 corners.right_top 《《 endl;
cout 《《 “right_bottom:” 《《 corners.right_bottom 《《 endl;
//圖像配準
Mat imageTransform1, imageTransform2;
warpPerspective(image01, imageTransform1, homo, Size(MAX(corners.right_top.x, corners.right_bottom.x), image02.rows));
//warpPerspective(image01, imageTransform2, adjustMat*homo, Size(image02.cols*1.3, image02.rows*1.8));
imshow(“直接經(jīng)過透視矩陣變換”, imageTransform1);
imwrite(“trans1.jpg”, imageTransform1);
//創(chuàng)建拼接后的圖,需提前計算圖的大小
int dst_width = imageTransform1.cols; //取最右點的長度為拼接圖的長度
int dst_height = image02.rows;
Mat dst(dst_height, dst_width, CV_8UC3);
dst.setTo(0);
imageTransform1.copyTo(dst(Rect(0, 0, imageTransform1.cols, imageTransform1.rows))); image02.copyTo(dst(Rect(0, 0, image02.cols, image02.rows)));
imshow(“b_dst”, dst);
OptimizeSeam(image02, imageTransform1, dst);
imshow(“dst”, dst);
imwrite(“dst.jpg”, dst);
waitKey();
return 0;
}
//優(yōu)化兩圖的連接處,使得拼接自然
void OptimizeSeam(Mat& img1, Mat& trans, Mat& dst)
{
int start = MIN(corners.left_top.x, corners.left_bottom.x);//開始位置,即重疊區(qū)域的左邊界
double processWidth = img1.cols - start;//重疊區(qū)域的寬度
int rows = dst.rows;
int cols = img1.cols; //注意,是列數(shù)*通道數(shù)
double alpha = 1;//img1中像素的權(quán)重
for (int i = 0; i 《 rows; i++)
{
uchar* p = img1.ptr《uchar》(i); //獲取第i行的首地址
uchar* t = trans.ptr《uchar》(i);
uchar* d = dst.ptr《uchar》(i);
for (int j = start; j 《 cols; j++)
{
//如果遇到圖像trans中無像素的黑點,則完全拷貝img1中的數(shù)據(jù)
if (t[j * 3] == 0 && t[j * 3 + 1] == 0 && t[j * 3 + 2] == 0)
{
alpha = 1;
}
else
{
//img1中像素的權(quán)重,與當前處理點距重疊區(qū)域左邊界的距離成正比,實驗證明,這種方法確實好
alpha = (processWidth - (j - start)) / processWidth;
}
d[j * 3] = p[j * 3] * alpha + t[j * 3] * (1 - alpha);
d[j * 3 + 1] = p[j * 3 + 1] * alpha + t[j * 3 + 1] * (1 - alpha);
d[j * 3 + 2] = p[j * 3 + 2] * alpha + t[j * 3 + 2] * (1 - alpha);
}
}
}
}









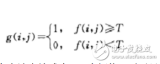














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論