控制器由系統板和接口板組成:系統板是由LPC2214 和S3C44B0X 及其相關外圍電路構成的,是控制器的核心;接口電路板主要負責系統板和機床電器之間的驅動,電平匹配。系統的硬件結構參考圖1。
2020-12-20 12:24:17 4327
4327 
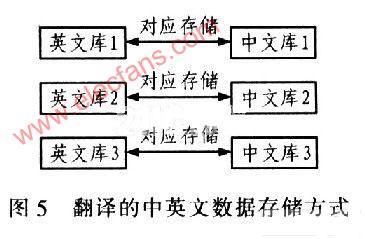
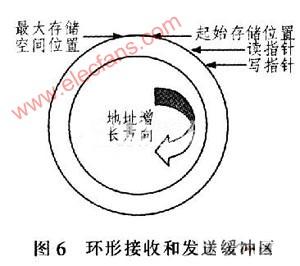
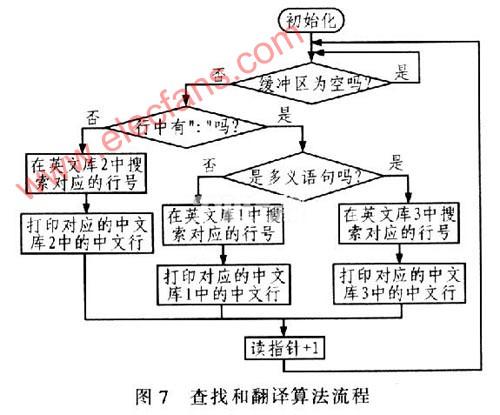
為了改進某焊接設備只能輸出打印英文單據的情況,設計了由高性能ARM7控制器——LPC2214為核心的英文轉中文翻譯器,詳細論述了具體的硬件電路和優化的軟件算法的設計原理,實驗結果
2011-09-29 15:48:281485 相對于ARM上一代的主流ARM7/ARM9內核架構,新一代Cortex內核架構的啟動方式有了比較大的變化。ARM7/ARM9內核的控制器在復位后,CPU會從存儲空間的絕對地址0x000000取出
2021-08-20 06:32:00
我想用89c51作為能見能檢測的主控芯片采集的數據量通過串口 發給人機界面用arm7作為主控芯片 連接led集束顯示屏顯示信息那么我有點不懂是如何通信的呢希望高人給與指點 拿rs232 嵌入式就選lpc2214為例能給予解釋
2013-05-28 13:39:20
AD元器件中英文對照
2015-04-19 15:56:19
Allegro PCB Editor 16.2菜單中英文對照
2015-05-20 09:10:36
求Altium 中英文對照表!{:soso_e163:}
2012-09-02 10:40:39
傳感器知識。中英文翻譯。
2016-09-24 19:57:49
static 6.engr unit 7.engr disp HART475菜單中英文對照 1. TEST DEVICE 測試設備 1. Seft 自檢2. Statics 狀態 2. DIAG
2017-08-29 10:52:08
我做了一個程序,上級要求最好能做成中英雙文(不是軟件語言,是寫出來的程序的語言),然后我就像通過控件標簽文本屬性來設置,做一個中英文的枚舉,英文顯示默認標簽,中文顯示中文,可是運行程序切換語言會出現如圖報錯,請問有人幫忙解答一下報錯原因和解決辦法,或推薦解決中英文切換的其他有效辦法嗎???
2020-02-29 21:20:48
哪位大神有labview8.5中英文切換的插件!!!求發一份不勝感激!!
2014-06-26 20:57:16
Unicode,當然文本要在控件中正常顯示,而不是顯示編碼的十六進制。主要是為了對中英文混合的字符串進行操作。最好能提供實例的程序供我參考,謝謝!
2015-04-29 09:32:05
NXP LPC2214 ARM7芯片的引腳無法輸出問題:工程是從LPC2138用過來的,增加了P2.3口的控制發現GPIOP2.3 無法輸出高電平/*配置IO管腳映射*/PINSEL0
2022-02-07 08:16:12
Protel%2BDXP元件中英文對照,方便大家使用
2013-10-25 20:20:10
proteus 器件庫中英文對照
2017-07-29 16:54:43
SMT常用術語之中英文對比
2012-08-06 11:25:24
STM32是如何驅動OLED屏幕顯示中英文字符的?有哪些具體操作?
2021-10-21 06:56:42
Verilog黃金參考(中英文)
2017-09-26 14:10:30
allegro16.6中英文對照
2016-08-25 11:03:19
labview2014有沒有中英文切換的功能,要怎樣設置
2015-02-06 22:00:36
課程推薦>>每天1小時,龍哥手把手教您LabVIEW視覺設計許多程序都有中英文界面切換功能,這邊網友動手做了一個中英文界面切換的小程序labview8.5:[hide][/hide]labview2009:[hide] [/hide]
2011-12-12 16:09:05
不同的程序都能一鍵翻譯成英文?接下來我們一步步實現以上功能:1.labview實現自動聯網中英文翻譯通過有道的翻譯api實現一鍵翻譯可方便的實現中英文互譯這是需要中英文切換的主vi前面版程序框圖參數1布爾1請
2020-07-26 01:12:04
labview怎么判斷字符串中英文的個數啊?
2017-01-21 11:31:15
proteus元件名稱中英文對照表
2012-07-17 21:27:12
proteus常用元件中英文對照表_說明
2023-09-28 08:29:23
protues仿真中英文對照軟件
2012-06-10 16:53:29
protues元件中英文對照。。。。。。。。。。。。。。。。。。
2015-12-11 13:53:12
protues元件庫中英文對照表
2012-12-06 21:02:25
元器件中英文對照
2019-02-09 23:33:36
LPC2100系列ARM7微控制器的加密原理說明LPC2100系列ARM7微控制器的加密程序實現LPC2100系列ARM7微控制器工程模板中可加密的目標
2021-04-22 06:46:05
程序界面要實現中英文切換,現在都有哪些方法,目前自己用的LCE工具包。但是程序有點龐大,界面有點多,全部切換起來有點費時,給位大佬還有什么快捷的方法嗎。。
2019-10-24 09:21:48
用于復雜的馬達控制應用。總之飛利浦ARM嵌入式微控制器應用領域包括工業控制、通信、安防系統、醫療儀器、航空航天、汽車和消費電子等,覆蓋了從低端到高端的嵌入式產品應用。 以ARM7微核心的體系架構 以
2008-06-17 11:56:19
時序、讀數據時序完成的,命令和數據的各個字節均由最低有效位開始逐位傳送。在程序中,先初始化LPC2214的Time1定時器,將其定時時間設定為10μs,Delay子程序的作用是使其延遲time倍的10
2018-12-17 11:23:39
程序中,先初始化LPC2214的Time1定時器,將其定時時間設定為10μs,Delay子程序的作用是使其延遲time倍的10μs。Reset、WriteByte、ReadByte分別是初始化、讀、寫
2018-12-03 15:27:30
基于嵌入式微控制器LPC2214的遠程圖像監控系統摘要:針對傳統圖像監控系統所存在的缺陷,綜合應用嵌入式系統、以太網、圖像采集和壓縮等技術,開發了一套以嵌入式L inux和LPC2214為開發平臺,能實現遠程智能化的圖像監控系統,并給出了其總體結構. [hide][/hide]
2009-12-01 10:23:26
如何去設計一種基于ARM7的LCD控制器?
2021-06-07 07:24:38
我要做一個中英文切換的功能,現在按鈕什么的都能切換(用的標簽和標題切換實現),但是選項卡不能切換成中英文,現在我用lce試了試也是沒有頭緒,希望大神們幫幫忙!!!!!
2018-01-17 16:37:09
情況如下:我自己制作了一個硬件模塊,用的是 lpc2214,現在需要將 ucos-ii 移植到上面去.我用板子做 ZLG 公司提供的實驗,是可以做的,如 led 燈等,按道理說串口等硬件應該沒有問題
2023-02-28 14:23:57
如何用proteus仿真學習1602的中英文顯示?
2021-09-29 06:57:29
最好直接中英文的,哪位大哥有相關的發給我謝謝,
2016-05-10 19:17:17
過大,浪費紙張等缺點。因此,為了解決上述問題,根據實際工程項目應用需要,提出一種基于ARM的英文轉中文的翻譯器設計方案,該設計是在原有設備和支持中文打印的熱敏打印機之間增加一塊以ARM為核心的電路板作為英文
2019-10-23 06:11:50
摩斯碼翻譯器,,,,,,,,,,,,
2013-11-08 21:22:23
最全的電子元件中英文對照1
2013-01-29 19:11:28
求STC89C52的芯片資料,最好中英文都有的。在線等。。等
2013-06-03 13:58:17
如何去選擇一款音頻解碼芯片?如何去實現一種VS1003控制協議?一種基于LPC2214和uC/OS-II的音頻處理方案
2021-06-08 06:43:34
因為畢業論文,需要外文翻譯,中英文都有,,有的可以發我郵箱1044929907@qq.com。。。
2012-06-01 21:28:57
求關于labview虛擬儀器外文文獻(中英文對照)
2015-06-06 18:03:24
`allegro16.6中英文對照,主要是cadence下的每個程序是具體做什么的,謝謝了!(初學者還不懂)`
2014-08-04 16:58:18
電子元器件名稱中英文對照表相關資料分享
2021-03-29 07:30:04
電機銘牌參數中英文對照及簡介
2021-01-28 06:25:10
誰有數碼相機電路圖里的英文翻譯嗎???有的請發給我······我的郵箱1225146687@qq.com 謝謝·····
2012-10-03 17:08:29
如何去切換Altium Designer界面的中英文輸入法呢?
2022-02-14 06:10:00
用keil做一個中英文切換程序,試了幾次沒有成功。建立了一個結構體,卻無法調用。希望看到的大神們幫忙解惑!!不勝感激!!
2018-11-26 10:30:35
因為電路要盡量小,又要省電,所以希望用單片機,比如LPC2214,直接驅動3.5寸彩色LCD,比如TM035KDH03。只是顯示靜態圖像或者文字,不要求動態顯示圖像。只是不敢肯定是否行得通,那位有經驗的老師給個回應吧!謝謝!
2019-10-28 07:51:34
LPC2114/2124/2212/2214使用指南1. 介紹概述LPC2114/2124/2212/2214是基于一個支持實時仿真和跟蹤的16/32位ARM7TDMI-STM CPU的微控制器,并帶有128/256 k字節(kB)嵌入的高速Flash存儲器。128位寬
2008-08-24 17:07:20 154
154 The LPC2212/LPC2214 are based on a 16/32 bit ARM7TDMI-S™ CPU with real-timeemulation
2008-12-25 19:37:2932 論述了基于ARM7 體系微控制器LPC2214 的發電機負序電流監測儀SL-1 的組成結構和具體實現。詳細介紹了負序電流模擬運算電路和以LPC2214 為核心的控制電路的工作原理,軟件上給出
2009-07-30 11:35:3410 品質名詞中英文對照
2009-11-19 17:27:2510 目前流行的ARM芯片內核有ARM7TDMI、ARM720T、ARM9TDMI、ARM992T、ARM940T、ARM946T、ARM966T和ARM10TDMI等,Philips LPC2214是基于ARM7TDMI-S的高性能32位RISC微控制器,它集成了Thumb擴展指令集,256KB可在系
2009-11-24 11:34:4561 基于LPC2214的實時時鐘芯片( ISL1208 )驅動程序
LPC2210是基于一個支持實時仿真和跟蹤的16/32位ARM7TDMI-STM CPU。對代碼規模有嚴格控制的應用可使用16位Thumb模式將代碼
2010-02-09 15:47:28102 LPC2212、LPC2214 ARM微控制器數據手冊The LPC2212/2214 are based on a 16/32-bit ARM7TDMI-S CPU with real-time
2010-04-07 16:31:3847
FPC常用術語中英文對照
2006-06-30 19:45:572311 基于LPC2214和uC/OS-II的音頻處理方案
基于 LPC2214和uC/OS-II的嵌入式平臺 目前流行的ARM芯片內核有ARM7TDMI、ARM720T、ARM9TDMI、ARM992T、ARM940T、ARM946T
2007-05-24 09:29:211096 單片機的英文翻譯
單片機的英文全稱:Single-Chip Microcomputer
單片機又稱單片微控制器,它不是
2009-03-30 10:44:459230 電子專業詞匯翻譯中英文對照(新手必備知識)
1 backplane 背板 2 Band gap volt
2009-05-16 09:32:194651
金屬廢料中英文對照
金屬廢料中英文對照 中文名 英文名 品質描述 606
2009-11-14 16:42:08646 1. 加密原理說明
LPC2100系列ARM7微控制器是世界首款可加密的ARM芯片,對其加密的方法是通過用戶程序在指定地址上設置規定的數據。PHILIPS公司規定,對于LPC2100
2010-08-29 09:44:001513 基于ARM的中英文翻
2011-01-06 17:19:13131 目前流行的 ARM 芯片內核有ARM7TDMI、ARM720T、ARM9TDMI、ARM992T、ARM940T、ARM946T、ARM966T和ARM10TDMI等,Philips LPC2214是基于ARM7TDMI-S的高性能32位RISC微控制器,它集成了Thumb擴展指令集,256KB可在系統
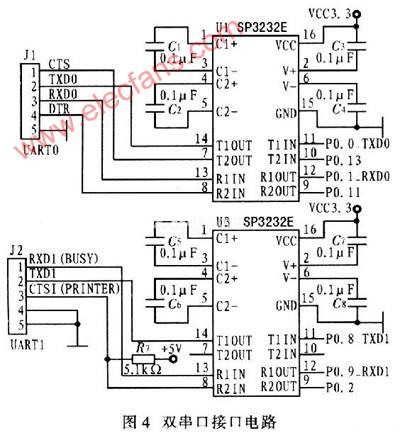
2011-06-02 17:21:52143 本文為基于LPC2214的 嵌入式系統 USB接口模塊設計,實現了與PC機之間的通信。
2011-06-29 15:22:3461 本系統實現的英語轉換漢語翻譯器在軟硬件方面都采取較好的方案,硬件集成度高,電路板尺寸小,英語轉換漢語翻譯器從實驗結果來看,打印輸出效果良好。
2011-11-09 11:39:002529 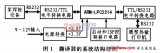
介紹了一種基于FPGA的多軸控制器,控制器主要由ARM7(LPC2214)和FPGA(EP2C5T144C8)及其外圍電路組成,用于同時控制多路電機的運動。利用Verilog HDL 硬件描述語言在FPGA中實現了電機控制邏
2013-04-27 16:23:1182 基于LPC2214單片機測量兩相流流速..
2016-01-04 15:25:1337 PROTEL 中常用的庫元件(中英文),里邊是關于protel軟件元件庫的中英文對照,有需要的可以看一下。
2016-04-28 15:35:130 一篇關于微弱信號處理的外文文獻的英文翻譯,在微弱信號的處理、放大、轉換有一定的介紹。
2016-04-28 18:02:310 單片機、嵌入式中英文翻譯,有關單片機系統介紹的中英文,較詳細。
2016-05-06 16:43:3920 大族電機-振鏡掃描系統中英文
2016-12-25 22:17:450 稅控收款機是指具有特定稅控功能的電子收款機,它是集軟硬件為一體的嵌入式系統,硬件設計考慮高性價比和高可靠性,軟件設計考慮系統的穩定性和可靠性。根據這一原則,本文介紹了一種基于ARM控制器LPC2214的稅控收款機的設計方案。
2018-07-18 08:54:00616 
介紹了一種基于fpga的多軸控制器,控制器主要由arm7(LPC2214)和fpga(EP2C5T144C8)及其外圍電路組成,用于同時控制多路電機的運動。利用Verilog HDL硬件描述
2018-06-14 08:24:006000 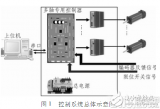
本文檔的主要內容詳細介紹的是開關電源專業名詞的中英文翻譯。
2020-03-23 11:36:2414 本文以DS1990A為例,對其與LPC2214之間一線串行通信方式進行研究。
2021-03-23 13:55:071673 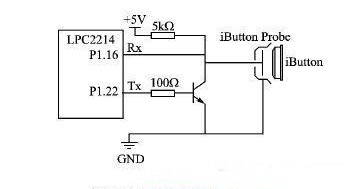
得云里霧里。針對這些難題,專注人工智能22年的AI翻譯領軍者科大訊飛,推出了一款專業中英文翻譯機——訊飛雙屏翻譯機,通過軟硬件雙向升級,開創翻譯雙屏時代,帶來全新流暢體驗,為廣大用戶提供精準快速的翻譯服務,支持
2021-08-30 16:25:091405 
NXP LPC2214 ARM7芯片的引腳無法輸出問題:工程是從LPC2138用過來的,增加了P2.3口的控制發現GPIOP2.3 無法輸出高電平/*配置IO管腳映射*/PINSEL0
2021-12-04 10:51:059 這是一個論文文章,基于ARM控制器LPC2214的稅控收款機系統的設計與實現。
2022-09-23 17:19:470
正在加载...
 電子發燒友App
電子發燒友App













 工商網監
工商網監
評論