 電子發燒友App
電子發燒友App


串口通信具有傳輸距離遠、傳輸穩定、簡單實用等特點,已被廣泛應用于工業控制、數據采集、網絡通信等領域。在這些應用領域中,串口通信用于實時地從各個串口接收數據,而向各個串口發送的主要是控制信息,一般不要求嚴格的實時性。因此提高串口設備接收的實時性至關重要。
設備接收到數據時,系統可通過兩種途徑獲取數據包到達的信息。一種是中斷方式,利用硬件中斷機制實現設備和系統的應答對話,即當外部設備需要CPU處理數據時,設備就發一個中斷信號給系統,系統在收到中斷請求時要保存中斷現場,調用相應的中斷服務程序響應設備的中斷請求,退出中斷處理程序后要恢復現場。上下文的切換要占據系統開銷,在數據量過載時會使得中斷頻率過高,CPU忙于處理硬件中斷,上層應用程序對于數據包的處理無法執行,而中斷程序還不斷往隊列中放數據,系統將自陷在中斷響應這一環節,產生所謂的“活鎖”。另一種是輪詢方式,系統每隔一定時間便檢查一次物理設備,若設備“報告”有數據到達,則調用相應的處理程序。但固定的輪詢周期增加了數據等待處理時間,降低了系統實時性。而且當數據量比較小時,頻繁查詢沒有數據達到的設備也是對CPU資源的浪費。
可見中斷和輪詢方式都不能滿足不同負載情況下系統的實時性要求。本文借鑒Linux系統中NAPI[1]方法,結合中斷與輪詢的優點,提出一種輪詢與中斷結合的調度方式。這種調度機制在多串口系統中,當負載在不同的串口通道不均衡時,可以提高CPU的利用效率,并能滿足業務的時延要求。另外,根據到達數據量分析得出了輪詢、中斷切換門限和輪詢周期。
1 算法描述
在同一系統中處理相同業務量時,中斷和輪詢處理的時間相同。因為過程相同,都是把數據從外設緩沖搬移到CPU內存中,所不同的是中斷進行上下文切換要占據系統開銷,而輪詢只是查詢一下寄存器狀態。相比之下,輪詢占用CPU的時間很短,一般中斷為幾個μs,輪詢為幾百ns,根據不同系統而有差別。相反,在數據量比較小的情況下輪詢中存在空轉情況,無疑增加了系統開銷。
目前,處理中斷和輪詢互換的方法有定時中斷法(Clocked Interrupts),即設置一個定時器,定時器到時,如果有中斷,則響應中斷,調用中斷服務程序處理數據。這種方法在數據量大時類似于輪詢,在負載小時中斷由異步事件觸發降低了開銷。但是這種機制需要一個精確的、頻率很高的系統時鐘,并且這種方法受固定定時周期的限制,不是在任何情況下都有效。
在并行系統中還應用了一種叫輪詢定時(Polling Watchdog)的機制,這種方法主要是為了解決接收處理中的等待時延問題。基本思想就是在輪詢接收開始時設置一個看門狗定時器,以滿足業務的最小時延要求,而且中斷要在接收超時才產生。此方法的不足之處是在負載小時解決不了輪詢空轉問題。
混合中斷、輪詢方式(HIP)主要應用在網絡接口系統中。工作方式為基于觀測接收的負載,改變切換門限,自動在中斷和輪詢兩種方式中切換。中斷方式沒有考慮到超時中斷,當數據到達間隔很大時,會降低實時性。在比較中斷和輪詢開銷時,定義VI+V(B)為中斷開銷,其中VI為中斷的固有開銷,V(B)為系統接收B字節數據的開銷,VP+V(B)為輪詢開銷,VP為輪詢的固有開銷。但在一次輪詢和中斷接收中,中斷和輪詢所接收的數據可能不相等,中斷開銷和輪詢開銷便失去了比較意義。
以上幾種方法均有不足,但在多路串口系統中,還各有不同的特點,即在每個獨立的通道可能存在不同的負載情況。如果對全部的串口通道統一應用中斷方式或查詢方式,則顯然不能適應各自串口通道的數據量,不能滿足系統實時性和高效率的綜合要求。根據這一特點,提出了在多路串口系統中,輪詢和中斷相結合的接收策略,在中斷方式下還靈活應用了批中斷技術。
算法描述:
com0=polling.。.comN=polling
For comID←0 up to comMAX
If TI》γ or PU=PUMAX Then
comID=interrupt
DelList(comID)
N路串口的初始狀態為輪詢,檢查輪詢隊列,如果數據到達間隔時間TI大于門限γ或者輪詢空轉次數PU等于空轉門限PUMAX,則該端口改為中斷狀態,在輪詢隊列中刪除該端口。根據不同的系統,間隔時間門限γ和空轉門限PUMAX的取值不同。
If TI《γ Then
comID=polling
AddList(comID)
在中斷狀態下,如果數據到達間隔時間TI小于門限γ,則該端口改為輪詢狀態,在輪詢隊列中增加該端口。
2 門限設計
如果事件隨機發生而且發生頻率很低,以致大多數輪詢都認為事件沒有發生,則中斷就會是首選的事件通知機制;如果事件定期發生且可以預測,而大多數輪詢都發現事件已發生,則首選機制是輪詢。在這兩者之間存在這樣一種情況,即輪詢行為和反應型行為的效果都相同,在它們之間如何選擇都無關緊要。這種情況即為所尋找的輪詢和中斷的切換門限。
2.1 門限度量標準的選擇
數據多少的衡量都是以單位時間內的吞吐量計算,即數據速率。如果以吞吐率的多少作為切換門限的標準,則在分組定長情況下,這種計算方法可以近似體現出負載情況,但當分組不定長時就不能體現實際負載了,如圖1所示的四種情況。
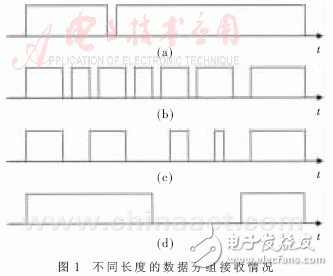
圖1(a)和圖1(b)的分組長度不同,但之間的到達間隔都很小。計算得出圖1(b)單位時間的吞吐率明顯要比圖1(a)小,但如果圖1(b)采用中斷方式,就要頻繁地響應中斷,效率將大大降低。圖1(d)的分組很長,一次接收中接收到的數據非常多,但之間的到達間隔很長,如果計算吞吐率選擇的單位時間正好為數據接收時間,在這一段時間內吞吐率很大,則誤認為數據量很大,選擇輪詢方式接收。相比之下,圖1(c)和圖1(d)選用中斷方式更為理想。
根據以上分析可以發現,用數據到達的時間間隔可以近似地表示數據量的大小。如果數據到達間隔很小,且頻繁到達,則認為負載很大,選擇輪詢方式;如果數據到達間隔很大,則認為負載很小,選擇中斷方式。在輪詢方式中,如果根據已知的到達時間,推算出下一數據的到達時間,根據計算出的結果來設定輪詢周期,則輪詢效率更加提升。
2.2 門限的計算
上述計算到達間隔判斷切換時機的方式,不能體現數據到達間隔的變化規律。可選用平均到達時間的均方根和均值的比值作為判斷切換的標準,這個比值系數代表了平均到達時間的變化程度。當比值小時表明預測的值與平均值偏差很小,數據到達的間隔時間是有規律的,可以預測。這種情況顯然要應用輪詢方式,把輪詢周期設為平均到達間隔時間。
平均到達間隔時間的計算方法如下式:
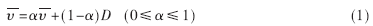
式中:D為最后一個數據到達的間隔時間;α為平均到達間隔時間的加權系數,α控制著D相對于以往的到達時間間隔歷史所占的比重。用這種方法,平均到達間隔時間就可以積累到達間隔時間了。
平均到達時間的方差用下式估計:
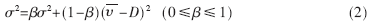
式中:β為到達間隔時間的方差加權系數,且控制估計器的記憶性。σ2開方就得到平均到達間隔時間的均方根σ了。
下式表明了切換到輪詢時的門限:

式中:γ為預測門限,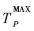 為系統可容忍的最大輪詢周期,在本系統中為滿足上層的應用,為20 ms。
為系統可容忍的最大輪詢周期,在本系統中為滿足上層的應用,為20 ms。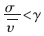 表明數據到達間隔規律;
表明數據到達間隔規律;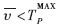 表明平均到達間隔小于系統所能忍受的最小間隔。數據到達不頻繁,認為滿足以上兩個條件時切換到輪詢模式;當滿足的條件相反時,切換到中斷方式。
表明平均到達間隔小于系統所能忍受的最小間隔。數據到達不頻繁,認為滿足以上兩個條件時切換到輪詢模式;當滿足的條件相反時,切換到中斷方式。
3 實例分析
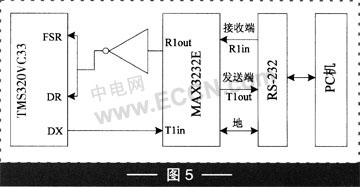
在可接收10路空中信號的多串口系統中對該算法進行實現,系統結構如圖2。該系統可將數據信息(主要為語音數據)接收后轉換為以太網數據包,通過10MHz以太網口送出。同時,它從以太網口接收來自控制臺的各類指令,完成相應的處理任務。
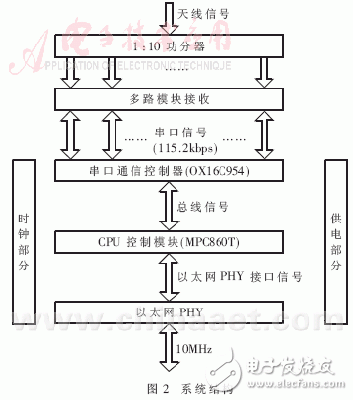
信號經過1:10功分器,分給10個RF接收模塊,完成RF接收,輸出串行信號,每路串口為串行信號的最大速率115.2kbps,RF接收模塊每20ms發一個數據包,一個數據包最大為30bit。之后串行信號經過3片OX16C954(每片有4路UART)轉換成并行總線信號,輸出給MPC860T(CPU)。每片OX16C954設置有128B的環形緩沖區,所以經過時間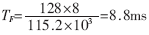 緩沖區就會被寫滿。為了保證不丟失數據,應該在8.8ms內完成對10個終端接收模塊進行一次接收。OX16C954中斷門限設為64B,當接收緩沖超過64B時,OX16C954產生接收中斷。在OX16C954還設置有超時中斷,當從接收最后一個停止位中心開始計時,在四個符號周期內沒有接收新的信息,即
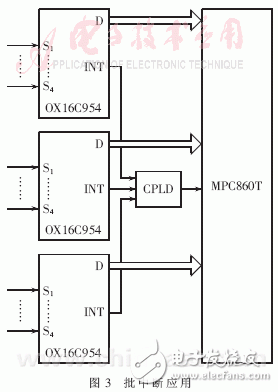
緩沖區就會被寫滿。為了保證不丟失數據,應該在8.8ms內完成對10個終端接收模塊進行一次接收。OX16C954中斷門限設為64B,當接收緩沖超過64B時,OX16C954產生接收中斷。在OX16C954還設置有超時中斷,當從接收最后一個停止位中心開始計時,在四個符號周期內沒有接收新的信息,即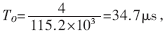 就產生超時中斷。批中斷的應用如圖3。多個串口通過CPLD共享一個中斷源,在中斷頻繁,多個串口同時產生中斷的情況下,實現了批中斷,節約了中斷資源,提高了中斷效率。
就產生超時中斷。批中斷的應用如圖3。多個串口通過CPLD共享一個中斷源,在中斷頻繁,多個串口同時產生中斷的情況下,實現了批中斷,節約了中斷資源,提高了中斷效率。
本系統的設計基于VxWorks操作系統。VxWorks操作系統提供對多種處理器的廣泛支持,具有完善的開發環境、開放的軟件接口、優異的實時性能和全面可靠的網絡功能及良好的可裁剪性,適用于各種嵌入式環境的開發。
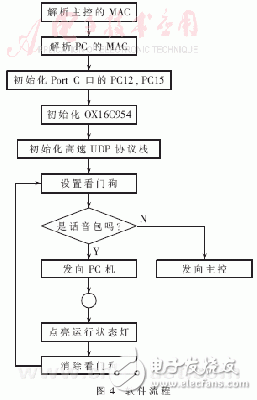
程序實現過程:系統加電待操作系統啟動之后,應用程序首先根據主控和PC機的IP地址,得到它們的MAC地址,為以后進行UDP數據傳送做準備;初始化MPC860T的Port C口,把PC12、PC15初始化為數據輸出口,分別用于點亮運行時的狀態燈和設置/清除硬件看門狗;初始化OX16C954,打開10路串口,接收終端模塊的數據;同時向終端模塊發送數據,初始化UDP協議棧;最后,進入無限循環中,從各個串口收集數據,解開數據包,以UDP的方式,把話音包發給PC機,把非話音包發給主控;同時,從網絡上接收來自主控的UDP數據,根據端口號,把數據轉發給各個終端模塊。PC機不直接向DPM發送UDP數據,只有主控向各個終端發送數據,故由DPM至PC機的數據為單向。管理看門狗,每循環一次,開關一次看門狗,處理一次狀態燈。整個程序的流程如圖4所示。
在10路都沒有數據的極限情況下測量輪詢開銷VP。在這種極限情況下,應用全中斷的方式,10路串口沒有數據不會產生中斷,中斷開銷為0;應用全輪詢的方式,CPU每次只查詢外部寄存器但不接收數據,所以每次CPU都是空轉,測量出來的為輪詢的固定開銷VP=163.84μs。在這種情況下,中斷顯然要優于輪詢。
3.1 均衡負載
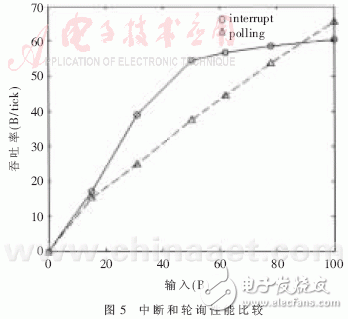
在多路負載均衡的情況下,測量中斷吞吐率OI= B1為達到OX16C954中斷門限后,觸發的接收中斷所接收的數據量(B1≥64B);B2為產生超時中斷時所接收的數據量(B2≤64B)。輪詢吞吐率OP=
B1為達到OX16C954中斷門限后,觸發的接收中斷所接收的數據量(B1≥64B);B2為產生超時中斷時所接收的數據量(B2≤64B)。輪詢吞吐率OP=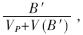 B′為輪詢接收的數據量。如圖5所示,在VxWorks系統中1tick=1/8000(s)。因為設置了中斷門限,所以中斷在數據量低的時刻有一個躍變;輪詢的躍變由輪詢的周期設置,如果改變輪詢周期,躍變點將發生轉移。輪詢的吞吐率隨輸入數據量的增加而呈線性增長;在數據量低時中斷要優于輪詢,隨著數據量的增長輪詢就要優于中斷,在兩者相交的時刻,通過實驗可以找到γ和PUMAX的值。
B′為輪詢接收的數據量。如圖5所示,在VxWorks系統中1tick=1/8000(s)。因為設置了中斷門限,所以中斷在數據量低的時刻有一個躍變;輪詢的躍變由輪詢的周期設置,如果改變輪詢周期,躍變點將發生轉移。輪詢的吞吐率隨輸入數據量的增加而呈線性增長;在數據量低時中斷要優于輪詢,隨著數據量的增長輪詢就要優于中斷,在兩者相交的時刻,通過實驗可以找到γ和PUMAX的值。
3.2 非均衡負載情況
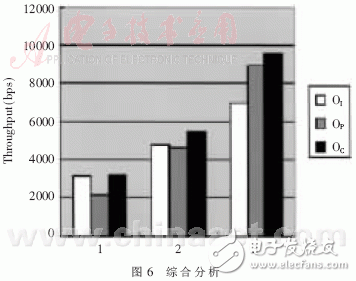
非均衡負載情況,即m1路數據負載大、m2路數據負載小的情況(m1+m2=10)下,測量OI、OP和OC(中斷和輪詢相結合的吞吐率)。如圖6所示,在橫坐標為1處,為m1=3,m2=7的情況,由于應用了批中斷,中斷的效率要優于輪詢,中斷和輪詢相結合的方法要略優于中斷;在橫坐標為2處,為m1=5,m2=5的情況,相結合的方法要略優于中斷和輪詢;在橫坐標3處為m1=7,m2=3的情況,相結合的方法近似輪詢,要優于中斷。
本文在綜合分析各種串口接收方式不足的基礎上,提出了中斷和輪詢相結合的方法。實驗結果表明,在滿足系統實時性要求的前提下,改進后的高速多串口系統吞吐率比應用單一的中斷或輪詢方式在多路高速串口系統中、各串口負載不均衡的情況下,得到了明顯的提高。









 工商網監
工商網監
評論