 電子發燒友App
電子發燒友App


對于復雜的系統,魯棒性是非常重要的。為了協助客戶建立魯棒性系統,KeyStone器件提供了多種硬件保護機制,如內存保護、EDC。本文介紹如何利用這些特性在KeyStone器件上建立一個魯棒的系統。同時提供了與文檔配套的例程。
1 簡介
如圖1所示,KeyStone器件提供了多種協助客戶建立魯棒性應用的特性。
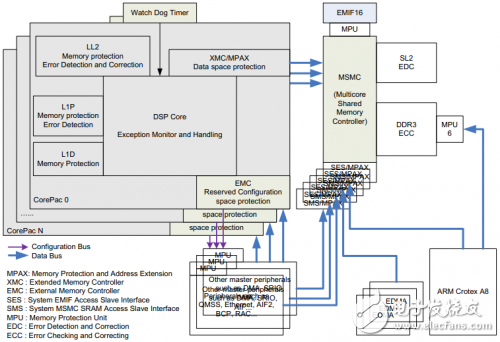
圖1 KeyStone器件魯棒系統
如圖1所示,在LL2、L1P及L1D中集成了內存保護模塊;LL2、SL2及DDR控制器中集成了錯誤檢查糾正模塊;L1P 集成了錯誤檢測模塊。MPAX和MPU模塊附在總線上,用于監控檢測以避免非法的總線訪問。每個DSP CorePac有一個獨立的MPAX用于監控與MSMC連接的總線。
對于系統中其他的master,根據權限ID進行分類。對每個權限ID,在MSMC中集成了2個MPAX用于監視與該權限ID 相關的訪問。其中一個是SES MPAX 用于保護對DDR3的訪問,另一個是SMS MPAX 用于保護對SL2的訪問。關于每個master對應的權限ID,參考相應的器件手冊。
某些外設的配置端口上添加了MPU,用于保護對該外設配置區域的非法訪問。但是并非所有的外設都受MPU的保護,具體參考相應器件手冊中受MPU保護的外設列表。每個CorePac有一個看門狗定時器用于監視其活動,如果該核死機,看門狗可以觸發不可屏蔽中斷或者復位信號。
EMC可以避免DSP core訪問沒有映射的的配置空間,XMC則可以避免DSP core訪問沒有映射的數據空間。所有這些功能都由硬件模塊實現,使用這些功能對系統性能基本上沒有影響。使用EDC會對存儲器的訪問性能稍有影響,但從整個系統層面上看,它幾乎是微不足道的。
在出現問題時,所有這些模塊可以向DSP core觸發異常,DSP core的異常監控模塊可以記錄這些狀態并觸發異常服務程序執行相應的操作。本文討論這些特性的應用,并給出相關基于寄存器層CSL 實現的例程。代碼使用如下方式定義寄存器指針。

上述各種特性具體描述分布于各自子系統的文檔中,本文最后的參考章節中列出了所有相關的文檔。在看本文之前,假設客戶已經閱讀了相關屬性對應的文檔,所以本文旨在提供相關的補充信息。
本文適用于KeyStone 1系列DSP,例程在TCI6614 EVM,C6670 EVM,C6678 EVM上進行了驗證。對于其他的KeyStone器件包擴KeyStone 2系列,基本功能都是一樣的,一些細節上的些許差異請參閱相應器件手冊。
2 內存保護
文檔“Memory Protection On KeyStone Devices(SPRWIKI9012)”中討論了KeyStone器件上的內存保護屬性,其中包括其它文檔中沒有的很多有用信息,本節在其基礎上做一些總結和補充。
表1 總結列出不同內存保護模塊的差異。
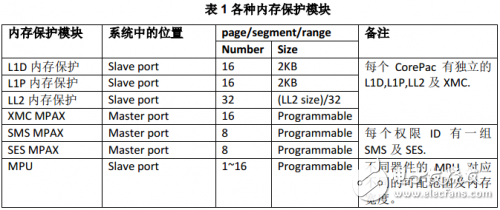
系統中有多個master和slave,位于slave輸入端口的保護模塊用于阻止來自其他master對該slave的非法訪問;位于master輸出端口的保護模塊用于阻止該master對所有其他slave的非法訪問。每個內存頁、分片或范圍的保護屬性都是可編程的。
2.1 L1及LL2內存保護
關于L1及LL2內存保護的基本信息參考“TMS320C66x CorePac User Guide(SPUGW0)”中內存保護章節。
L1及LL2內存保護只區分7個外部請求ID,但是系統可能有16個權限ID。默認情況下,系統權限ID 0~5映射到CorePac AID 0~5,所有其他的權限ID均映射到AIDx。
CorePac AID與系統權限ID之間的映射關系可由EMC編程配置,具體參考“TMS320C66x CorePac User Guide(SPUGW0)”中“外部存儲控制器(EMC)”章節。注意,IDMA的AID與其所屬CorePac的數值一致,EDMA傳輸的權限ID與配置并發起這個傳輸的核的編號一致。
通常L1被配置為cache,此時所有L1相關的內存保護屬性寄存器應該清零從而阻止其他master的對L1的訪問。
CorePac內部內存保護模塊(保護L1,LL2及XMC/MPAX)的寄存器被一個鎖保護起來。默認情況下,這些寄存器沒有被鎖住,用戶軟件可以使用自定義的密鑰鎖住這些寄存器,然后,只有用該密鑰進行解鎖后才可以訪問這些寄存器。
2.2 共享內存保護–MPAX
關于CorePac共享內存保護的基本信息參考“TMS320C66x CorePac User Guide(SPRUGW0)”中“擴展存儲控制器(XMC)”章節;關于系統中其他master的共享內存保護基本信息參考“KeyStone Architecture Multicore Shared Memory Controller User Guide (SPRUGW7)”中“內存保護及地址擴展(MPAX)”章節。如下是例程中關于XMC/MPAX的配置樣例,每一行代表MPAX中的一個分片配置。
邏輯地址低于0x0C00_0000 的地址訪問不會進入XMC。對地址空間0x0000_0000~0x07FF_FFFF
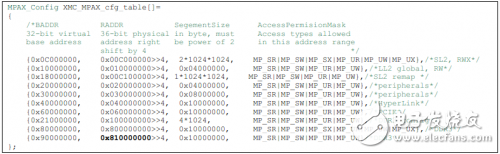
進行訪問時,在C66x CorePac內部進行地址解析。這塊地址范圍包括內部及外部配置總線,及L1D、L1P、L2存儲空間。對位于0x0C00_0000~0x0FFF_FFFF區間的邏輯地址訪問時,會經過L1 cache,并且在讀操作時會經過預取緩存,與該地址范圍對應的內存屬性配置寄存器MAR是硬件拉死的,不可修改。也就是說對該邏輯地址空間的訪問在進入XMC MPAX之前不會經過L2 cache,所以這塊邏輯地址空間稱為“快速SL2 RAM 路徑”。對大于等于0x1000_0000的邏輯地址訪問會首先經過L2 cache控制器,然后經過XMC MPAX,這種常規路徑會增加一個cycle 的時延。
根據上述配置例子,在訪問SL2時,采用邏輯地址0x0C00_0000的訪問速率高于使用重映射后的邏輯地址0x1800_0000。但是0x1800_0000對應的內存屬性寄存器MAR 是可編程的,因此可以配置通過0x1800_0000訪問的SL2為non-cacheable及non-prefetchable。
注意替換地址RADDR是36-bit物理地址>>4。常見的DDR3錯誤配置如下:
![]()
或者

注意DDR3起始物理地址為0x8:0000_0000,而0x9:0000_0000相對起始地址有4GB的偏移,在大多數系統中這是一個非法的地址。
在真實系統中,應該充分利用好MPAX的所有片段更好地將存儲空間劃分成盡可能多的小片,并仔細設定各個分片的訪問限定屬性。
不用的地址不應該映射,MPAX會拒絕對未映射的地址訪問并上報異常事件,從而有助于捕獲軟件錯誤。
SMS/MPAX只允許對SL2的訪問,如下為其配置例子:

SES/MPAX是用于保護對DDR3的訪問,如下為其配置例子:

當兩個master通過共享memory交換數據時,應該確保兩個master使用的邏輯地址映射到相同的物理地址。注意EDMA的權限ID是繼承于對其配置的CorePac。
警告:
在修改一條MPAX表項時,需要確保此時沒有對該表項所覆蓋地址的訪問。在修改之前,需要先將該表項覆蓋地址對應的cache及預取緩存中的數據進行回寫及失效操作。
對于MPAX的配置,推薦在程序開始之初且沒有使用任何共享存儲空間之前完成。用于CorePac MPAX配置的代碼和數據應該放在LL2。
如果要運行時動態修改一個MPAX表項,安全的方法是先將新的配置寫到一個未使用的編號高度表項,然后清掉舊的表項。這是由于編號高度表項的優先級高于編號低端表項。
在修改MPAX表項之前需要先執行如下操作:
1.將MPAX表項對應的存儲空間內容從cache中剔除出去。即使對于屬性為不可寫的存儲空間,應該使用CACHE_wbInvL2()而非CACHE_inv L2()。
2.如果對受影響的存儲器空間使能了預取功能,則需要對預取緩存執行失效操作。
3.執行“MFENCE”確保回寫及失效操作完成。
CorePac的MPAX寄存器受CorePac的內存保護寄存器鎖保護。SES及SMS的MPAX內存保護屬性寄存器被MSMC內部分別用于SES及SMS的鎖保護。MSMC內部其他寄存器被MSMC內部用于非MPAX 的鎖保護。
2.3 外設配置端口保護–MPU
關于MPU的基本信息參考“KeyStone Architecture Memory Protection Unit User Guide (SPRUGW5)”。
MPU0、MPU1、MPU2及MPU3對所有KeyStone 1器件是相同的。但是對于不同的器件,其附加MPU的個數,每個MPU 支持的地址范圍表項數,MPU的默認配置均有所差異。具體可參考相關器件手冊的“內存保護單元(MPU)”章節。
MPU與MPAX的區別在于,如果訪問地址不在MPU任何一個地址范圍內,則該地址訪問是允許的;而當該地址與MPAX中任意表項地址范圍不匹配時,則該地址訪問被拒絕。
注意,如果沒有被MPPA的設置所拒絕,MPU單元默認所有的訪問都是許可的。對于一個地址訪問,MPU首先將訪問的權限ID與MPPA寄存器的AID bit配置進行核對,如果與權限ID對應的AID bit為0,則不需要核對地址范圍,該訪問被許可。如MPPA=0則允許所有的對該空間的訪問,如果要拒絕任意對該空間的訪問則需要將MPPA配置為0x03FFFC00。L1及LL2內存保護的MPPA設置則有所不同,當MPPA中AID bit為0是拒絕相應的訪問。
當傳輸與MPU中多個地址范圍匹配時,所有重疊的范圍必須允許其訪問,否則該訪問會被拒絕。最終賦予的訪問權限與所有匹配表項中最低的權限等級一致。如某傳輸與2個表項匹配,其中一個是RW,另一個是RX,則最終的權限是R。這與MPAX也是不一樣的。如果一個地址落入多個MPAX表項,編號高的表項優先于編號低的表項。MPAX 只會用編號最高的表項決定權限,并忽略其他匹配的表項。
如下與本文對應例程中一個對MPU1的配置例子。每行代表MPU中一個配置范圍。

如上配置知,隊列保護如下:
隊列0~2047只可由AID0~7進行寫(PUSH)操作;
隊列2048~6143可由AID11以外所有的AID進行寫(PUSH)操作;
隊列6144~8191只可由AID8~15(AID11除外)進行寫(PUSH)操作。
TCI6614上的MPU6用于避免ARM對DDR3的非法操作。注意,MPU6是用于低32-bit DDR物理地址范圍的保護。注意,為了清除MPU異常/中斷事件,必須在服務程序的最后向EOI寄存器寫0。
TCI6614的MPU事件與其他KeyStone器件有所不同。TCI6614中所有的MPU0~7事件被合并為一個事件并作為一個系統事件連接到CIC0。由于TCI6614 MPU事件是電平中斷而非脈沖中斷事件,所有必須首先清除MPU事件標志,然后才可以清CIC標志。對于脈沖中斷事件,必須首選清CIC標志,然后清源標志。
另外,只有在通過PSC使能BCP后,才可以訪問TCI6614中用于BCP的MPU5。即在訪問TCI6614中MPU5寄存器時,如果此時BCP沒有被使能,則該訪問將觸發訪問錯誤。
2.4 預留區域保護
預留區域(非法地址)被自動保護。對非法地址進行讀操作時將返回垃圾數據,寫操作則會被阻止。對預留區域的訪問可以產生異常,這有益于捕獲軟件bug。
由于DSP core的訪問會經過L1D控制器,所以DSP core對非法地址的訪問會觸發L1D內存保護異常。DSP core從非法地址執行時將觸發指令獲取異常。對于非法寫操作,觸發的異常取決于相應的目的地址。DMA對非法地址訪問時,DMA模塊會上報總線錯誤。DMA錯誤事件可以作為異常路由到DSP core。
3 EDC
EDC(Error Detection and Correction)用于存儲器軟錯誤(Soft Error)。軟錯誤是一個錯誤的信號或數據,但是并不意味著硬件被破壞。在觀測到一個軟錯誤后,并不意味著系統可靠性會下降。在宇宙飛船中這種類型的錯誤稱為單一事件擾亂。在內存系統中,一個軟錯誤會改變程序中的一條指令或者一個數據值。軟錯誤通常可以通過器件的重啟進行糾正,而硬件錯誤通常不能通過重啟來恢復。軟錯誤不會對系統硬件造成破壞;僅僅會對處理的代碼或數據造成錯誤。產生軟錯誤的原因有:
1.阿爾法粒子輻射及宇宙射線產生能量中子及質子。發生的概率取決于器件的地理位置及周圍環境。通常,一個器件在幾年中才會出現幾次。
2.軟錯誤也可由隨機噪聲、干擾或信號完整性錯誤引發,如板載電感應或電容串擾。如果軟錯誤發送概率高于上述條目1 中的理論值,則應該檢查硬件設計找出其他原因。一個常見的原因是供電電源電壓低于預期,導致器件對噪聲或干擾的影響更敏感。
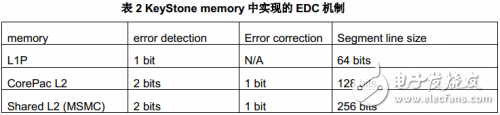
KeyStone器件各級memory中都實現了EDC機制,下表對不同memory模塊的實現機制進行了比較。
3.1 L1P錯誤檢測
關于L1P及LL2 EDC基本信息參考“TMS320C66x DSP CorePac User Guide(SPRUGW0)”。校驗比特生成與核對:校驗比特在進行64-bit對齊的DMA寫或L1P cache緩存時生成。非64-bit對齊的DMA 訪問將使校驗信息失效。在256-bit對齊的程序讀取或64-bit對齊的DMA讀操作時,L1P EDC邏輯會核對校驗信息。
錯誤檢查設置:器件復位后默認情況下L1P錯誤檢查特性是關閉的。一旦L1PEDCMD寄存器中的“EN”bit被置位,所有L1P memory中的ED邏輯被使能。下面是從應用代碼中摘錄的L1P ED功能使能例子。
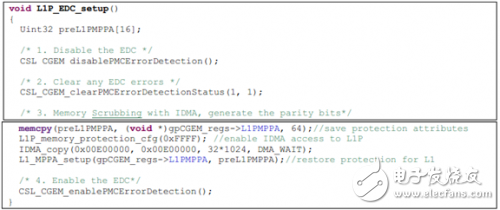
注意:要使L1P ED功能工作正常,必須同時使能L2 EDC。
對L1P cache訪問時的錯誤處理: 對從L1P cache中獲取程序產生的校驗錯誤,沒有專用的系統事件,然而,錯誤檢測邏輯會發送一個直接的異常事件給DSP(IERR.IFX事件),然后用戶可以使用內部異常事件獲取這個錯誤。L1PEDSTAT寄存器的PERR bit會被置位。L1PEDARRD寄存器會記錄包含錯誤bit的的地址信息。在L1P錯誤對應的異常處理服務函數中,需要對包含錯誤地址的cache line進行失效操作。
對DMA訪問的錯誤處理:對DMA/IDMA訪問產生的校驗錯誤,對應#113號系統事件。用戶可以使用這個事件獲取錯誤。L1PEDSTAT寄存器的DERR比特位會被置位,并且L1PEDARRD寄存器會記錄包含錯誤bit的地址信息。
L1P EDC功能驗證:通過置位LPEDCMD寄存器中的SUSP比特可以暫停L1P EDC邏輯。使用該特性,可以軟件模仿EDC錯誤并驗證EDC功能。與本文對應的例程中提供了驗證L1P EDC功能的代碼,對應函數L1P_ED_test()。
3.2 LL2錯誤檢查與糾正
校驗比特生成與核對:在對L2以128 bits為單元進行內存寫操作時會產生相應的校驗信息。非128-bit對齊或者小于128 bits的寫操作會使校驗信息失效。對128-bit對齊的memory讀操作時,LL2 EDC邏輯會核對校驗信息。更多信息參考“TMS320C66x DSP CorePac User Guide(SPRUGW0)”。
錯誤檢查及糾正配置:器件復位后默認情況下LL2 EDC特性是被關閉的。與某些C64+DSP不同的是,KeyStone DSP不能對內存分塊使能EDC。一旦EDC使能,EDC邏輯對整個CorePac L2內存生效。然而,可以對不同的內存訪問請求者分別使能,如L1D控制器、L1P控制器或DMA控制器。例如,如果用戶只需要對代碼段使用EDC,需要使能下面三個域:
1.設置L2EDCMD寄存器中的EN bit以使能LL2 EDC邏輯;
2.設置L2EDCEN寄存器中的PL2SEN比特以使能L1 SRAM的EDC邏輯對L1P訪問的檢查;
3.設置L2EDCEN寄存器中的PL2CEN比特以使能L2 cache的EDC邏輯對L1P訪問的檢查。
從關閉到使能狀態轉變時,LL2 EDC邏輯不會初始化校驗RAM。因此,在進入使能狀態后,校驗RAM中的值是隨機值,需要用戶軟件對其進行初始化。對L2 EDC的配置必須遵循“TMS320C66x DSP CorePac User Guide(SPRUGW0)”中闡述的EDC配置順序。下面是從例程中摘錄的L2 EDC使能函數參考代碼:

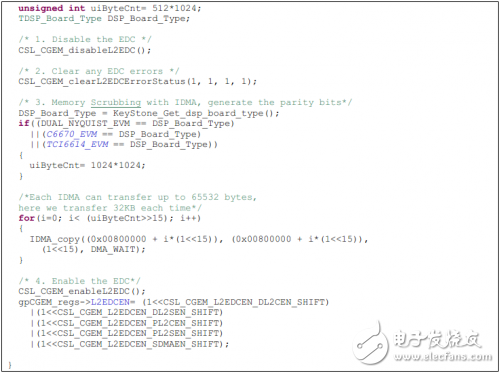
對來自L1D控制器的訪問錯誤處理:在經過L1D cache從LL2中獲取數據時,對所有這些數據會進行錯誤檢查,但是不會有任何的糾正。不管是1-bit或者是多bit錯誤,將會通過#117號系統事件(L2_ED2:不可糾正比特錯誤檢測)上報給DSP core。
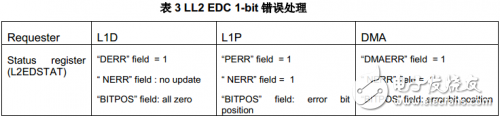
對來自L1P及DMA控制器的訪問錯誤處理:1-bit錯誤可以被糾正并通過#116號系統事件(L2_ED1:可被糾正的比特錯誤)上報 。2-bit錯誤可以被檢測,并通過#117號系統事件上報該錯誤。下表列出對于不同存儲器訪問請求者,相應的1-bit錯誤處理細節。

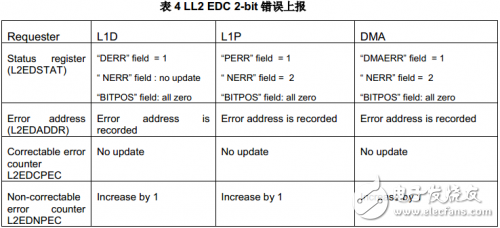
錯誤計數器(L2EDCPEC, L2EDNPEC)非常有用,可用于在長時間運行的系統中評估校驗比特錯誤發生的種類與概率。下表列出對不同存儲器訪問請求者,相應的2-bit錯誤處理細節。
對于大于2bits的錯誤,EDC邏輯可能會檢測并報告為1-bit或2-bit錯誤,或者EDC根本檢測不到該錯誤。所以說,KeyStone系列EDC硬件邏輯只能保證檢測2-bit錯誤或糾正1-bit錯誤。
通常軟錯誤出現的概率很低,首先出現1-bit錯誤,在相對長時間后,第二個錯誤bit也許會產生。由于1-bit 錯誤可以被糾正,而2-bit錯誤不能被糾正,所以我們應該盡可能在第二個比特錯誤出現前糾正好第一個比特錯誤。
糾正1-bit錯誤的操作通常稱為“刷新”。為了刷新一塊存儲器,可以使用IDMA,把IDMA的源地址與目的地址設為相同的地址;字節長度設置為期望覆蓋的內存塊。地址訪問必須是128-bit對齊,并且整塊的內存范圍長度必須是128bits的整數倍。在IDMA從LL2讀取數據時,對于存在有效校驗信息的128-bit字,EDC硬件會糾正可能存在于其中的1-bit錯誤。當IDMA把數據回寫到相同的地址時,EDC會對數據產生校驗信息并標識其為有效。
刷新操作通常是在1-bit錯誤中斷服務函數中進行。但是在1-bit錯誤發生之后2-bit錯誤發生之前,某些數據也許不會被訪問,在沒有訪問時1-bit錯誤是不會被自動上報的。為了避免這種情況,應該周期性地刷新整塊存儲器區間來糾正潛在的1-bit錯誤。下面是一段LL2 EDC刷新的代碼例子。
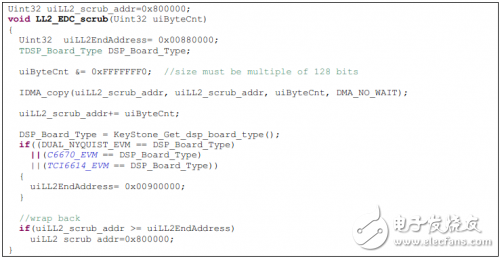
通常,這個函數可以在一個定時中斷中調用。如在一個600秒周期的定時中斷中調用該函數。

這樣, 1MB的存儲區間會每7天被刷新一遍。由于刷新操作會與正常的內存操作相競爭,因此會影響正常內存操作的性能。所以刷新操作不能太頻繁,但是必須在2-bit錯誤產生前完成。在設計時必須權衡考慮。LL2 EDC功能驗證:通過設置L2EDCMD寄存器中的SUSP比特可以暫停LL2 EDC邏輯。使用該特性,可以軟件模仿EDC錯誤并驗證EDC功能。與本文對應的例程中提供了驗證LL2 EDC功能的代碼,對應函數LL2_ED_test()。
3.3 SL2錯誤檢測與糾正
對共享存儲器SL2的基本信息,參考“KeyStone Architecture Multicore Shared Memory Controller User Guide(SPRUGW7)”。校驗比特產生與核對:有兩種機制用于MSMC校驗信息的產生與檢測:
1.對任意master發起的256-bit內存段的寫操作時,校驗信息會被更新并設置為有效。小于256bits的寫操作會使校驗信息失效。當DSP master發起256-bit內存段的的讀操作時,校驗信息會被檢查。
2.MSMC包含一個后臺錯誤糾正硬件稱作刷新引擎,用于周期刷新存儲器的內容。刷新的周期數可以通過SMEDCC 寄存器中的REFDEL比特域來配置,每次刷新會讀取并回寫大小是4個32字節的塊。在檢測并糾正1-bit或者檢查到2-bit錯誤時,刷新引擎還會上報EDC錯誤。在MSMC用戶手冊中有具體的機制細節描述。
DSP復位后,MSMC硬件會使校驗信息失效,并重新初始化校驗信息。在第一次讀MSMC存儲器時,軟件必須先檢查SMEDCC中的PRR比特(校驗RAM是否準備好的狀態信息)。
錯誤檢測與糾正配置:DSP復位后SL2 EDC邏輯的刷新引擎被使能,并且會在后臺產生校驗信息。軟件不需要像LL2 EDC一樣使用DMA進行存儲器刷新,只需要查詢SMEDCC寄存器中的PRR(校驗RAM準備)比特位來確認校驗比特已經產生。為了使能錯誤糾正,SMEDCC中的ECM比特同樣應該使能。請注意,錯誤糾正邏輯會對從SL2的讀操作增加1cycle的時延(訪問流水線增加了一級),不過訪問吞吐量并不會降低。
下面是使能MSMC EDC功能的例程:
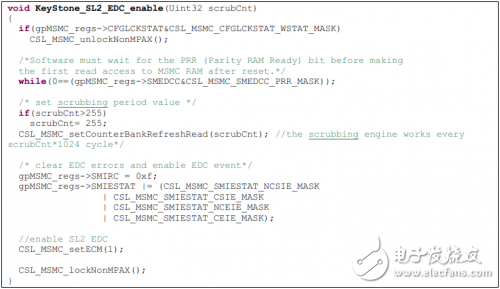
錯誤上報機制:MSMC用戶手冊中有詳細的錯誤上報機制信息,這里總結如下表。

請注意,由刷新引擎上報的錯誤地址是從0開始的地址偏移,而為非刷新訪問記錄的錯誤地址是器件中從0x0C000000開始的SL2地址。

MSMC EDC功能驗證:可以通過設置SMEDCTST寄存器中的PFn比特位(bit0~3)來暫停MSMC EDC邏輯。SMEDCTST 的地址偏移是0x58。每個SL2 RAM bank對應PFn中一個比特(PF0~3與bank0~3依次對應),每個比特可以用于禁止對校驗RAM的寫操作。這樣可以凍結bank對應的校驗RAM,因此可以通過故意注入錯誤來破壞SL2存儲內容與校驗信息的一致性,從而測試檢測糾正邏輯。具體的順序如下:
1.向測試bank中的某一個位置寫一個已知值,這樣可以正確地為這個位置初始化一個校驗值。
2.向SMEDCSTST對應的PF比特寫1以凍結該校驗值。
3.向上述被寫的位置寫任意字節來改變該位置的數值,如果檢驗糾正功能則寫一個1-bit差異的值,如果檢驗檢測功能則寫一個存在2-bit差異的值。此時該位置的校驗值與其存儲的數值沒有同步。
4.讀回該位置的值,將會產生所選類型的校驗錯誤。
與本文對應的例程中提供了相應的代碼用于驗證SL2 EDC功能,對應的函數為SL2_EDC_test()。
4 其它魯棒性特性
4.1看門狗定時器
對應看門狗定時器的基本知識,請參考“KeyStone Architecture Timer64 User Guide(SPRUGV5)”中“看門狗定時器模式”章節。
定時器0~(N-1)可用于N個core的看門狗。在TCI6614中定時器8是ARM的看門狗定時器。在看門狗模式下,定時器倒計時到0時產生一個事件。需要由軟件在倒計時終止前向定時器寫數,然后計數重新開始。如果計數到0,會產生一個定時器事件。看門狗定時器事件可以觸發本核復位、器件復位或者NMI異常,這可以通過配置相應器件手冊中描述的“復位復用寄存器(RSTMUXx)”來選擇。
使看門狗事件觸發NMI異常具有更高的靈活性,在NMI異常服務函數中,錯誤的原因及某些關鍵的狀態信息可以被記錄下來,或者上報給上位機來進行故障分析,然后如果它不能自恢復則可以再由軟件來復位器件。
4.2 EDMA錯誤檢測
關于基本的EDMA CC錯誤信息可以參考“KeyStone Architecture Enhanced Direct Memory Access(EDMA3)Controller User Guide(SPRUGS5)”中的“錯誤中斷”章節。
關于基本的EDMA TC錯誤信息可以參考“KeyStone Architecture Enhanced Direct Memory Access(EDMA3) Controller User Guide(SPRUGS5)”中的“錯誤產生”章節。
所有的EDMA錯誤事件可作為異常被路由到CorePac。事件丟失錯誤是一種最常見的EDMA CC錯誤,意味著EDMA不能按要求及時完成數據的傳輸,或者錯誤的事件觸發了不應該的EDMA傳輸。總線錯誤是一種最常見的EDMA TC 錯誤,通常意味著EDMA訪問了錯誤的地址(如預留地址或受保護的地址)。
4.3 中斷丟失檢測
中斷丟失或遺漏是實時系統中常見也是常被忽略的問題。中斷丟失檢測是一種用于捕捉這種異常的有效方法。對基本的中斷丟失檢測信息參考“TMS320C66x DSP CorePac User Guide(SPRUGW0)”中“中斷錯誤事件”章節。
軟件系統應該對路由到DSP core且有對應軟件服務的中斷使能中斷丟失檢測。在所有中斷配置完畢后可以添加如下代碼使能中斷丟失檢測:

注意,當使能中斷丟失檢測并在CCS/Emulator下使用斷點或單步進行調測時,由于在仿真停止時中斷沒有被響應,所有此時中斷丟失錯誤上報的概率很高。如果想忽略它,可以在調測時暫時對某些或全部中斷關閉中斷丟失檢測,但是注意不要忘記在正式發布的程序中重新使能該功能。
5 異常處理
關于異常處理的基本信息參考“TMS320C66x DSP CPU and Instruction Set Reference Guide(SPRUGH7)”中“CPU 異常”一節。
關于中斷或異常事件路由的基本信息參考“TMS320C66x DSP CorePac User Guide(SPRUGW0)”中“中斷控制器”章節。
5.1 異常事件路由
所有源自或由CorePac觸發的錯誤事件均直接路由到CorePac的中斷控制器。常被當作異常處理的錯誤如下表所示。
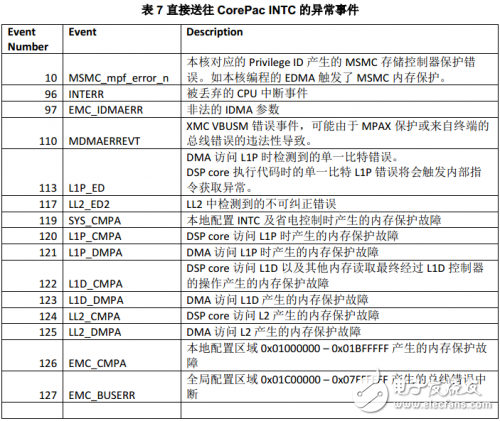
一些其他非致命的錯誤事件,如可糾正的LL2 EDC錯誤,應該被路由到中斷而非異常。源自或者由器件中共享模塊觸發的錯誤事件被路由到CIC。CIC基本信息參考“KeyStone Architecture Chip Interrupt Controller(CIC) User Guide(SPRUGW4)”。
CIC事件中常被當作異常處理的事件如下表所示。
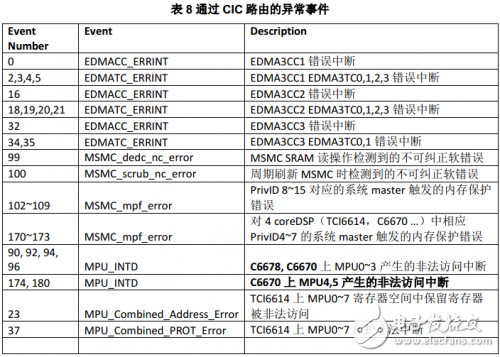
每種這樣的異常事件只能路由到一個CorePac。通常所有的這些事件被路由到一個CorePac。下圖描述DSP core 內部控制異常處理的開關。
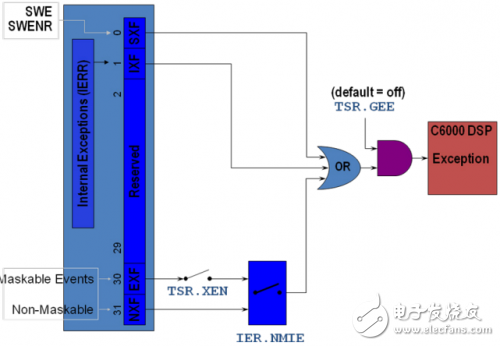
圖2 DSP核異常控制開關
一旦軟件置位TSR.GEE 及IER.NMIE,不能再由軟件清除,只能在復位后被清除。TSR.XEN可以由軟件置位并清除。XEN可以在進入異常服務函數中由硬件自動清除,并在退出異常服務函數時自動恢復原來的狀態。因此,默認情況下,在中斷服務函數中,TSR.GEE=1,IER.NMIE=1及TSR.XEN=0.
5.2 異常服務函數
異常函數中應該記錄或上報異常原因及相關信息,用于故障分析。關鍵的記錄信息是NRP。NRP是異常返回指針,通常用于確定異常觸發的位置。實際上,非法操作與NRP捕獲之間的時延大概在10~100個DSP Core cycles 之間,具體的時延取決于很多因素,如操作類型,產生異常事件的模塊等等。例如對于向一個被MPU保護的寄存器執行寫操作,其時延包括:從DSP core到寄存器的寫指令時延;錯誤事件從MPU到CIC然后到CorePac異常模塊的路由時延。因此,當我們獲得NRP后,應從NRP指向的位置向后搜索大概10~100cycles來找有問題的操作。
不過,某些異常NRP是沒有意義的,例如,對于指令獲取異常及非法操作碼異常。這通常發生在當程序跳轉到一個非法的地址時,這時NRP也指向一個非法的地址。我們真正想知道的是在程序跳轉到非法地址前到底發生了什么,但是這并不能從NRP推導出來。在這種情況下,寄存器B3,A4,B4,B14及B15也許會有所幫助。B3可能還保存著上次函數調用的返回指針;A4及B4也許保存著上次函數調用的參數;B15是棧指針;B14是指向某些全局變量的數據指針。更多的細節可以參考“TMS320C6000 Optimizing Compiler User Guide(SPRUG187)” 中“7.4 函數結構及調用約定”章節。根據這些信息,我們也許可以推導出在程序跳轉到非法地址前發生了什么。注意,B3,A4,B4可能在異常發生前已經被修改用于保存其它信息,所以它們也許不是有用的。實際上,B3,A4,B4包含有價值信息的概率還是很高的,所以這些寄存器是值得記錄并分析的。
通用寄存器的值不能用C 代碼記錄,而必須用匯編代碼來記錄。下面的例子是將B3,A4,B4,B14,B15 寄存器記錄在“exception_record”中,然后調用 “Exception_service_routine”。
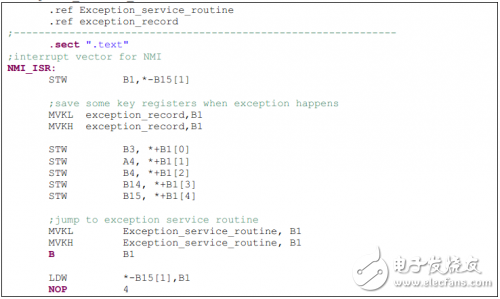
其它需要記錄的基本信息有:EFR,IERR,NTSR,TSCL/TSCH.EFR用于判決異常類型:內部、外部或是NMI。對于內部異常,內部異常的原因記錄在IERR。NTSR記錄異常發生時的DSP core狀態。記錄的TSCL/TSCH用于確定異常發生前器件運行的時長。
對于外部異常,通過檢查INTC及CIC標志寄存器來決定異常原因。對應一個特定的異常,往往有特定的狀態寄存器可以檢查、記錄或上報。例如對應內存保護異常,需要記錄的關鍵信息是故障地址。參考各模塊的用戶指南了解相關狀態或標志的更多細節。
通常,異常服務函數將這些異常信息保存在一個類似如下的數據結構中。
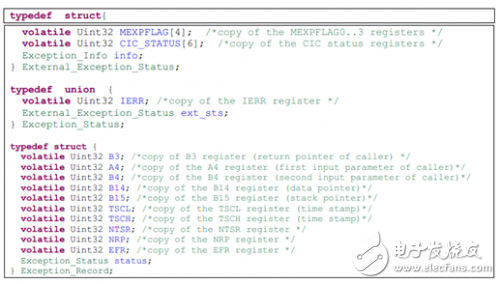
可以在異常服務函數中將這些數據結構中的信息傳遞給主機,或者將其導出來進行錯誤分析。
通常異常服務函數處理的錯誤是致命的,用戶不應該期望從異常服務函數中返回。另外,軟件也不總是能從異常服務函數中安全返回,阻止從異常中安全返回的條件有:
1.被異常終止的SPLOOPs不能正確地重新開始。在返回前應該核實NTSR中的SPLX比特數值為0.
2.中斷被堵塞時發生的異常不能正確地重新開始。在返回前應該核實NTSR中的IB比特數值為0.
3.在不能被安全中斷的代碼處(如一個保護多個賦值的緊湊循環)發生的異常不能正確地返回。編譯器通常會在代碼中的這些地方關閉中斷;查看NTSR中的GIE比特值為1來驗證滿足這個條件。
4.NRP不是一個合法的地址。
所以通常異常服務函數以一個while(1)循環作為結束。默認情況下在異常服務程序中,TSR.GEE=1,IER.NMIE=1 及TSR.XEN=0.即在異常服務程序中NMI及內部異常是使能的。
當一個使能的異常發生在第一個異常服務程序中時,復位向量指向的程序會被執行。這時NTSR和NRP不會發生改變。TSR復制到ITSR,此時的PC復制到IRP。此時為了避免其他外部異常,硬件將TSR設置為默認的異常處理值,NMIE中的IER比特被清零。
通常中斷服務表中的復位向量是跳轉到程序起始位置如_c_int00,這樣,嵌套異常會重啟程序。然而這并非大部分用戶所期望的,我們通常期望的是異常發生時在異常服務程序執行完后結束程序。為了避免嵌套異常導致程序重啟,可以給嵌套異常添加一個額外的異常服務程序,用戶可以修改復位向量跳轉到嵌套異常服務程序。在KeyStone器件中,加載程序不依賴于復位向量啟動程序,所以修改復位向量不會影響程序的加載。
6 例程
本文相關的例程可以在TCI6614 EVM, C6670 EVM及C6678 EVM上跑通。如下為工程目錄結構:
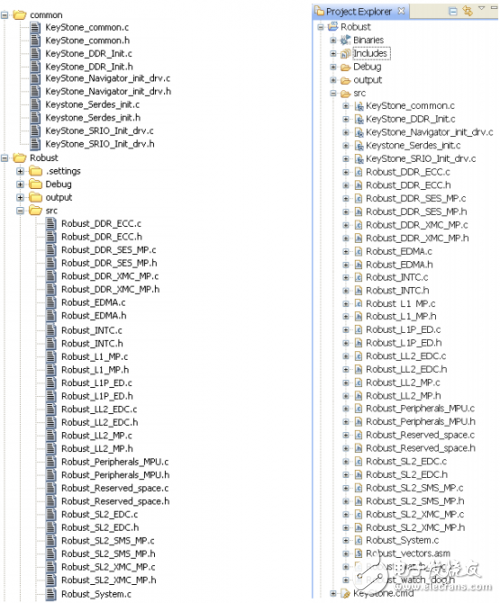
圖3 例程目錄結果
“common“文件夾中包含通用代碼如DDR 初始化及DMA、定時器、多核導航器、SRIO驅動等。內存保護初始化代碼、EDC及異常處理的代碼包含在KeyStone_common.c。
“src”文件夾中的每個c文件包含一個測試用例代碼。主函數在 “Robust_System.c”。在 “Robust_System.c“的開頭有一些宏開關,每個開關用于使能或關閉一個測試用例。
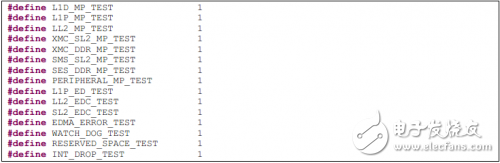
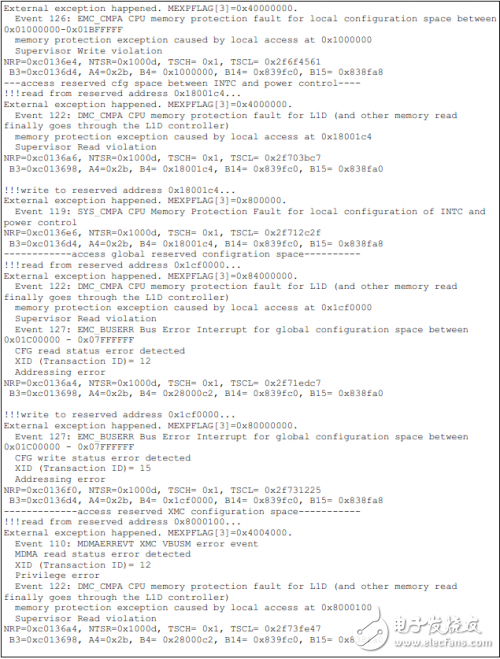
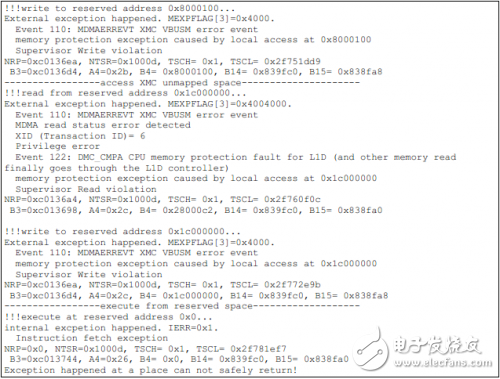
如果使能多個測試用例,每個用例會依次執行。由于程序并不能總是安全地從異常服務程序中返回,因此有可能在一個測試用例后輸出如下信息,然后測試流程被終止。

如果出現這種情況,可以關閉這個測試用例然后重新測試其他的用例。在EVM上運行例程的步驟如下:
1.解壓例程,將CCS workspace切換到解壓后的文件夾;
2.在workspace中導入工程;
3.如果發生代碼修改對工程重新編譯,也許需要在編譯選項中修改CSL保護路徑;
4.設置EVM板上的器件加載模式為No boot模式;
5.將代碼加載到DSP core0,運行;
6.查看CCS stdout窗口瀏覽測試結果。
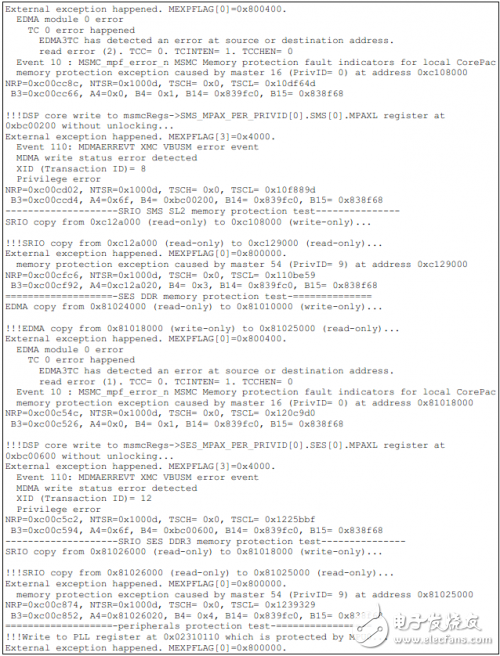
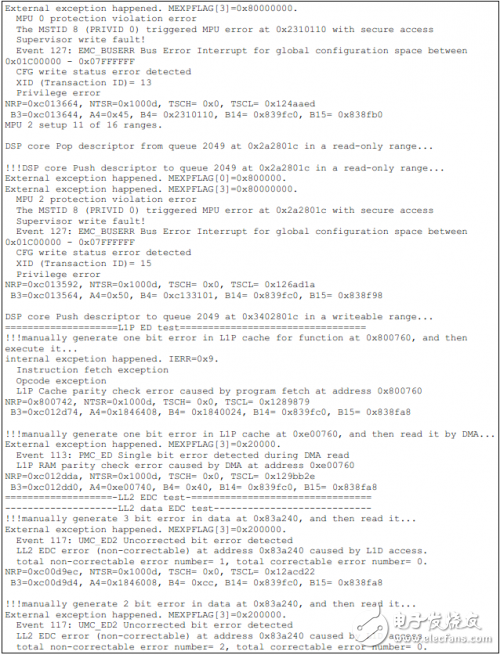
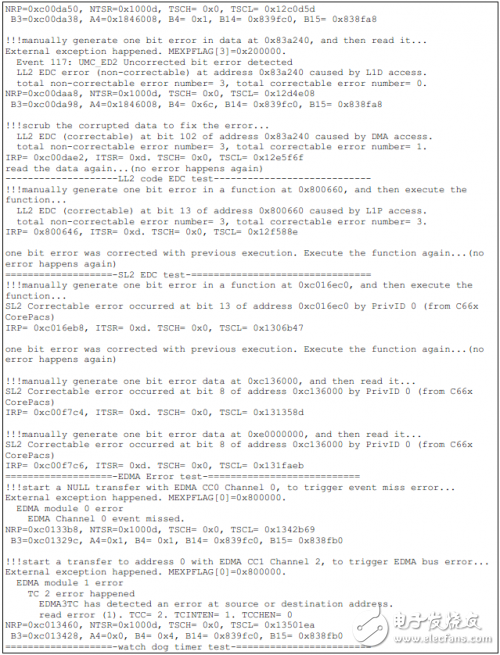
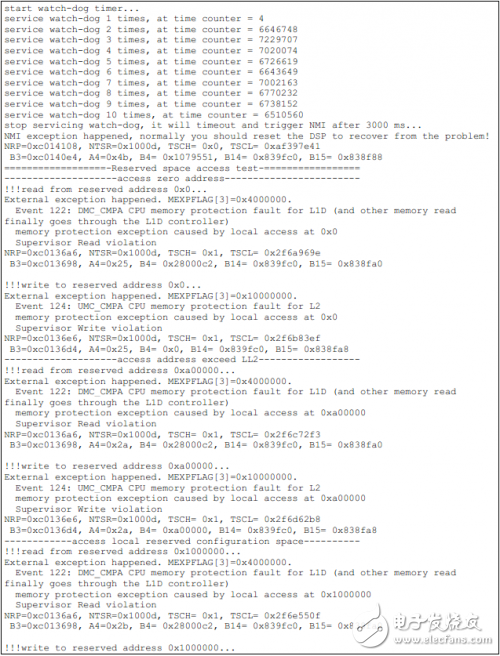
如下為TCI6614上的測試結果。
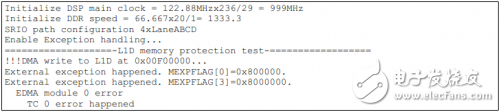
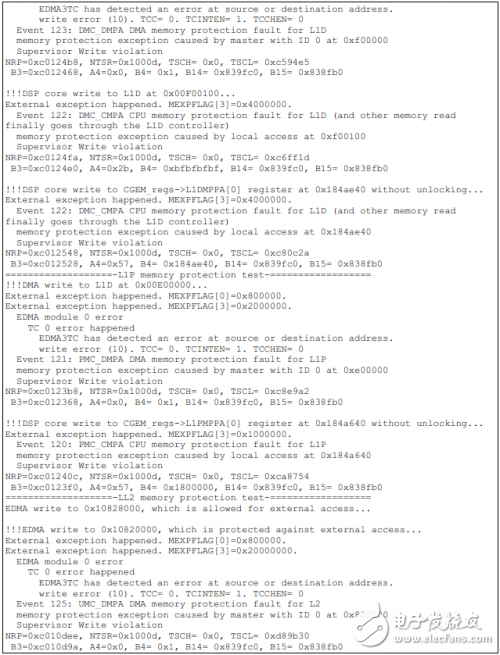
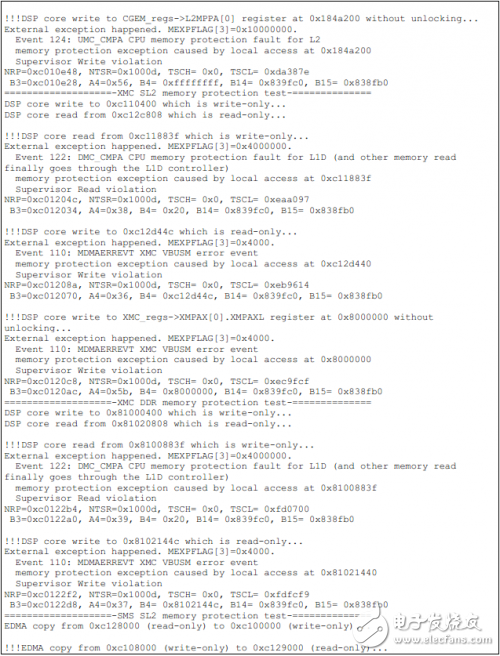











 工商網監
工商網監
評論