 電子發燒友App
電子發燒友App


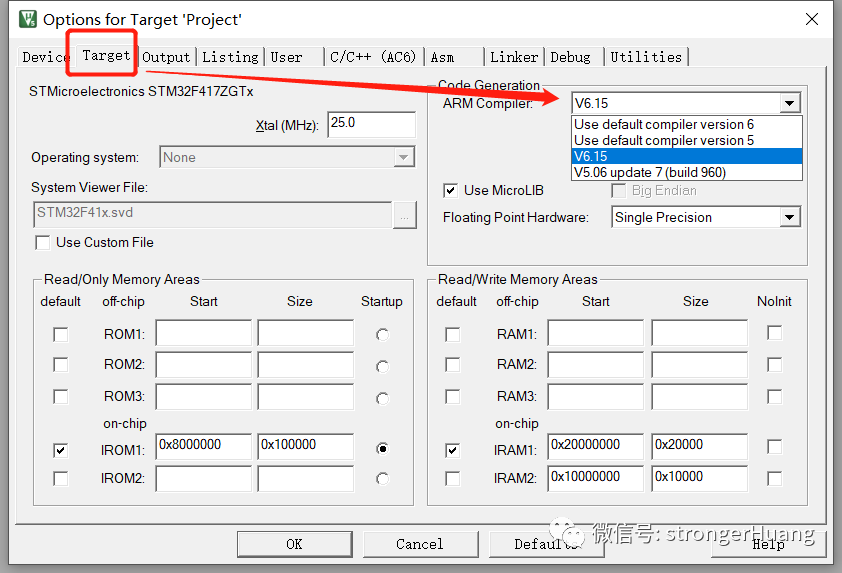
option -》 c/c++ -》 language/code genderation -》 optimization選項下的優化等級
優化級別說明(僅供參考):
則其中的 Code Optimization 欄就是用來設置C51的優化級別。共有9個優化級別(書上這么寫的),高優化級別中包含了前面所有的優化級別。現將各個級別說明如下:
0級優化:
1、常數折疊:只要有可能,編譯器就執行將表達式化為常數數字的計算,其中包括運行地址的計算。
2、簡單訪問優化:對8051系統的內部數據和位地址進行訪問優化。
3、跳轉優化:編譯器總是將跳轉延至最終目標上,因此跳轉到跳轉之間的命令被刪除。
1級優化:
1、死碼消除:無用的代碼段被消除。
2、跳轉否決:根據一個測試回溯,條件跳轉被仔細檢查,以決定是否能夠簡化或刪除。
2級優化:
1、數據覆蓋:適于靜態覆蓋的數據和位段被鑒別并標記出來。連接定位器BL51通過對全局數據流的分析,選擇可靜態覆蓋的段。
3級優化:
1、“窺孔”優化:將冗余的MOV命令去掉,包括不必要的從存儲器裝入對象及裝入常數的操作。另外如果能節省存儲空間或者程序執行時間,復雜操作將由簡單操作所代替。
4級優化:
1、寄存器變量:使自動變量和函數參數盡可能位于工作寄存器中,只要有可能,將不為這些變量保留數據存儲器空間。
2、擴展訪問優化:來自IDATA、XDATA、PDATA和CODE區域的變量直接包含在操作之中,因此大多數時候沒有必要將其裝入中間寄存器。
3、局部公共子式消除:如果表達式中有一個重復執行的計算,第一次計算的結果被保存,只要有可能,將被用作后續的計算,因此可從代碼中消除繁雜的計算。
4、CASE/SWITCH語句優化:將CASE/SWITCH語句作為跳轉表或跳轉串優化。
5級優化:
1、全局公共子式消除:只要有可能,函數內部相同的子表達式只計算一次。中間結果存入一個寄存器以代替新的計算。
2、簡單循環優化:以常量占據一段內存的循環再運行時被優化。
6級優化:
1、回路循環:如果程序代碼能更快更有效地執行,程序回路將進行循環。
7級優化:
1、擴展入口優化:在適合時對寄存器變量使用DPTR數據指針,指針和數組訪問被優化以減小程序代碼和提高執行速度。
8級優化:
1、公共尾部合并:對同一個函數有多處調用時,一些設置代碼可被重復使用,從而減小程序代碼長度。
9級優化:
1、公共子程序塊:檢測重復使用的指令序列,并將它們轉換為子程序。C51甚至會重新安排代碼以獲得更多的重復使用指令序列。
當然,優化級別并非越高越好,應該根據具體要求適當選擇。
Keil C51總線外設操作問題的深入分析
閱讀了《單片機與嵌入式系統應用》2005年第10期雜志《經驗交流》欄目的一篇文章《Keil C51對同一端口的連續讀取方法》(原文)后,筆者認為該文并未就此問題進行深入準確的分析 文章中提到的兩種解決方法并不直接和簡單。筆者認為這并非是Keil C51中不能處理對一個端口進行連續讀寫的問題,而是對Kei1 C51的使用不夠熟悉和設計不夠細致的問題,因此特撰寫本文。
本文中對原文提到的問題,提出了三種不同于原文的解決方法。每種方法都比原文中提到的方法更直接和簡單,設計也更規范。
1 問題回顧和分析
原文中提到:在實際工作中遇到對同一端口反復連續讀取,Keil C51編譯并未達到預期的結果。原文作者對C編譯出來的匯編程序進行分析發現,對同一端口的第二次讀取語句并未被編譯。但可惜原文作者并未分析沒有被編譯的原因,而是匆忙地采用一些不太規范的方法試驗出了兩種解決辦法。
對此問題,翻閱Keil C51的手冊很容易發現:KeilC51的編譯器有一個優化設置,不同的優化設置,會產生不同的編譯結果。一般情況缺省編譯優化設置被設定為8級優化,實際最高可設定為9級優化:
1. Dead code elimination。
2.Data overlaying。
3.Peephole optimization。
4.Register variables。
5.Common subexpression elimination。
6.Loop rotation。
7.Extended Index Access Optimizing。
8.Reuse Common Entry Code。
9.Common Block Subroutines。
而以上的問題,正是由于Keil C51編譯優化產生的。因為在原文程序中將外設地址直接按如下定義:
unsigned char xdata MAX197 _at_ 0x8000
采用_at_將變量MAX197定義到外部擴展RAM 指定地址0x8000。因此,Keil C51優化編譯理所當然認為重復讀第二次是沒有用的,直接用第一次讀取的結果就可以了,因此編譯器跳過了第二條讀取語句。至此,問題就一目了然了。
2 解決方法
由以上分析很容易就能提出很好的解決辦法。
2.1 最簡單最直接的辦法
程序一點都不用修改,將Keil C51的編譯優化選擇設置為0(不優化)就可以了。選擇project窗口的Target,然后打開“Options for Target”設置對話框,選擇“C51”選項卡,將“Code Optimiztaion”中的“Level”選擇為“0:Costant folding”。再次編譯后,大家會發現編譯結果為:
CLR MAXHBEN
MOV DPTR,#MAX197
MOVX A,@DPTR
MOV R7,A
MOV down8,R7
SETB MAXHBEN
MOV DPTR,#MAX197
MOVX A,@DPTR
MOV R7,A
MOV up4,R7
兩次讀取操作都被編譯出來了。
2.2 最好的方法
告訴Keil C51,這個地址不是一般的擴展RAM,而是連接的設備,具有“揮發”特性,每次讀取都是有意義的。可以修改變量定義,增加“volatile”關鍵字說明其特征:
unsigned char volatile xdata MAX197 _at_ 0x8000;
也可以在程序中包含系統頭文件;“#include”,然后在程序中修改變量,定義為直接地址:
#define MAX197 XBYTE
這樣,Keil C51的設置仍然可以保留高級優化,且編譯結果中,同樣兩次讀取并不會被優化跳過。
附表:Keil C51中的優化級別及優化作用 級別 說明
0 常數合并:編譯器預先計算結果,盡可能用常數代替表達式。包括運行地址計算。
優化簡單訪問:編譯器優化訪問8051系統的內部數據和位地址。
跳轉優化:編譯器總是擴展跳轉到最終目標,多級跳轉指令被刪除。
1 死代碼刪除:沒用的代碼段被刪除。
拒絕跳轉:嚴密的檢查條件跳轉,以確定是否可以倒置測試邏輯來改進或刪除。
2 數據覆蓋:適合靜態覆蓋的數據和位段被確定,并內部標識。BL51連接/定位器可以通過全局數據流分析,選擇可被覆蓋的段。
3 窺孔優化:清除多余的MOV指令。這包括不必要的從存儲區加載和常數加載操作。當存儲空間或執行時間可節省時,用簡單操作代替復雜操作。
4 寄存器變量:如有可能,自動變量和函數參數分配到寄存器上。為這些變量保留的存儲區就省略了。
優化擴展訪問:IDATA、XDATA、PDATA和CODE的變量直接包含在操作中。在多數時間沒必要使用中間寄存器。
局部公共子表達式刪除:如果用一個表達式重復進行相同的計算,則保存第一次計算結果,后面有可能就用這結果。多余的計算就被刪除。
Case/Switch優化:包含SWITCH和CASE的代碼優化為跳轉表或跳轉隊列。
5 全局公共子表達式刪除:一個函數內相同的子表達式有可能就只計算一次。中間結果保存在寄存器中,在一個新的計算中使用。
簡單循環優化:用一個常數填充存儲區的循環程序被修改和優化。
6 循環優化:如果結果程序代碼更快和有效則程序對循環進行優化。
7 擴展索引訪問優化:適當時對寄存器變量用DPTR。對指針和數組訪問進行執行速度和代碼大小優化。
8 公共尾部合并:當一個函數有多個調用,一些設置代碼可以復用,因此減少程序大小。
9 公共塊子程序:檢測循環指令序列,并轉換成子程序。Cx51甚至重排代碼以得到更大的循環序列。














 工商網監
工商網監
評論