 電子發燒友App
電子發燒友App


-----注:以下文章純手打原創,評測數據從第三方應用角度測評,如您是以下IC原廠,有專業性的偏頗建議請及時聯系小編。
說起評測,大家往往想起手機,電腦,汽車等等,相信大家經常在數碼IT網站看到各種各樣的數碼產品白電家電等功能性能評測,也經常被各種產品發布會,新媒體的手機跑分大賽,電腦跑分數值刷屏。------ 今天 我們來個中國通用32位MCU芯片 跑分大戰
說起MCU,在物聯網,智能硬件興起的當下,萬物智能,萬物互聯,小到插座,開關,燈泡都是智能的時代。MCU便是其中不可缺少的大腦核心。
小編對當下幾款國內外熱門的32位MCU進行橫向PK評測。挑選了目前市場常見的幾家軟硬件兼容32位ARM MCU如下:
STM32F103VET6
GD32F103VET6
HK32F103VET6
AT32F413RCT7
CKS32F103RC
眾所周知,衡量MCU處理器的一個重要指標就是性能,另外一個重要指標便是功耗。本期我們先從性能開始,跑分大賽。本次跑分我們把以上所有MCU都運行在同一主頻,去評測同一主頻下的各個MCU性能跑分數據。
在MCU處理器領域評分的 Benchmarks 非常眾多,有某些個人開發的程序,也有某些標準組織,或者商業公司開發的Benchmarks, 在此就不以一一列舉。今天我們選用在嵌入式處理器領域最為知名和常見的 Benchmarks 就是CoreMark。
CoreMark是用來衡量嵌入式系統中中心處理單元(CPU,或叫做微控制器MCU)性能的標準。該標準于2009年由EEMBC組織的Shay Gla-On提出,并且試圖將其發展成為工業標準,從而代替陳舊的Dhrystone標準。代碼使用C語言寫成,包含如下的運算法則:列舉(尋找并排序),數學矩陣操作(普通矩陣運算)和狀態機(用來確定輸入流中是否包含有效數字),最后還包括CRC(循環冗余校驗)。
CoreMark是一個綜合基準,用于測量嵌入式系統中使用的中央處理器(CPU)的性能。CoreMark也是STM32每次發布新品芯片必然要秀的跑分數據。
測試環境:
硬件:統一STM32F103開發板,換上各廠商的測試芯片。
軟件:統一同一主頻下, 同一COREMARK程序,同時運行并打印跑分測試結果。
由于STM32F103自帶Prefetchbuff ,所以以下會有開和不開的兩個跑分。
測試項目及文件函數解讀:
---注:花一點篇幅介紹下測試代碼,普通讀者可以略去直接跳到后面測試結果,測試程序,可以聯系官網下載。
1、鏈接列表
(1)概要
core_list_join.c
函數:
(2)描述
此Benchmark所做的項目 1.將一個項目插入列表2.從列表中刪除一個項目。3.撤銷刪除操作。4.在列表中找到一個項目5.反轉一個列表6.在不遞歸的情況下對列表進行排序。
雖然增加了間接訪問數據的級別,但這種結構是現實的,可用于許多用于中小型列表的嵌入式應用程序。
列表本身將在將被傳遞給初始化函數的一塊內存上初始化。盡管通常鏈表使用malloc作為新節點,但嵌入式應用程序有時會直接控制小數據結構(如數組和列表)的內存以避免系統調用的開銷,因此這種方法是現實的。
鏈表將被初始化,以使得列表指針的四分之一指向存儲器中的順序區域,并且列表指針的三分之一以非順序方式分布。這樣做是為了模擬一個鏈接列表,其中添加/刪除操作會暫時中斷整齊的順序,然后一系列可能來自連續內存位置的添加。
對于基準本身:
將執行多個查找操作。這些查找操作可能會導致整個列表被遍歷。每次查找的結果將成為輸出鏈的一部分。列表將使用基于data16值的合并排序進行排序,然后根據列表的一部分導出data16項目的CRC。CRC將成為產品鏈的一部分。
列表將使用基于idx值的合并排序再次排序。這種排序將保證列表在離開函數之前返回到主狀態,這樣函數的多次迭代將具有相同的結果。列表部分的data16的CRC將再次被計算并成為輸出鏈的一部分。
每個單元中的實際數據16將根據單個16b輸入進行偽隨機編碼,這些輸入在編譯時無法確定。此外,用于CRC的列表部分也將傳遞給該函數,并根據在運行時無法確定的輸入來確定。
使用鏈接列表的基準。鏈接列表是許多應用程序中使用的常見數據結構。就我們的目的而言,這將鍛煉處理器的內存單元。特別是使用列表指針來查找和更改數據。
相反,被傳入的內存塊用于創建一個列表,并且該基準會小心不要添加更多項目,然后可以通過內存塊調整。移植層將確保我們有一個有效的內存塊。
所有操作均已完成,無需使用任何額外內存。
2、矩陣操縱基準
(1)概要
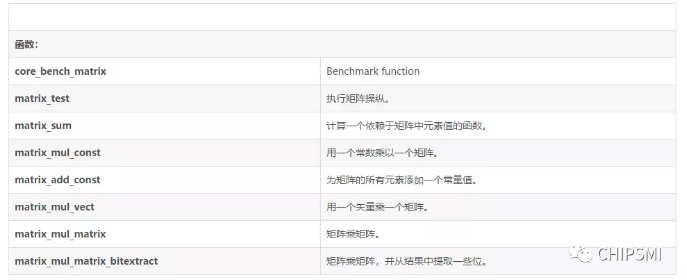
(2)描述
Matrixmanipulation benchmark,這個非常簡單的算法構成了許多更復雜算法的基礎。緊密的內部循環是許多優化(編譯器以及基于硬件)的重點,因此與嵌入式處理相關。
它所做的測試包含1.用一個常數乘以一個矩陣。2.為矩陣的所有元素添加一個常量值。3.用一個矢量乘一個矩陣。4.用矩陣乘以一個矩陣。5.將矩陣乘以矩陣。6.并從結果中提取一些bits。
總可用數據空間將被分為3部分
NxN矩陣A 用較小的值初始化(上部3/4位全部為零)。
NxN矩陣B 初始化為中等值(上半部分全部為零)。
NxN矩陣C 用于結果。
A和B的實際值必須根據編譯時不可用的輸入來派生。
1、狀態機基準
(1)概要
core_state.c
函數:
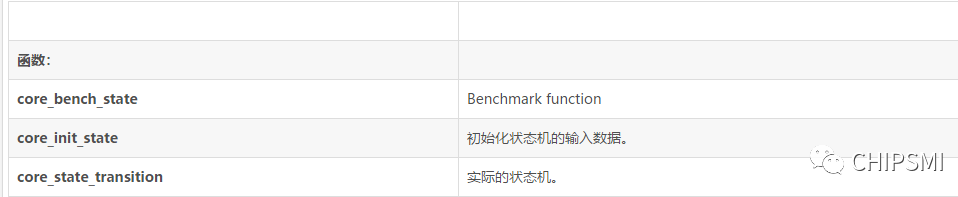
(2)描述
許多嵌入式產品都使用這種簡單的狀態機。對于更復雜的狀態機,有時會使用狀態轉換表實現,而直接編碼的交易速度易于維護。由于在CoreMark中使用狀態機的主要目的是為了鍛煉switch/if的運轉情況,我們使用的是小型moore機器。特別是,這臺機器測試字符串輸入的類型,試圖確定輸入是數字還是別的東西。
測試結果:
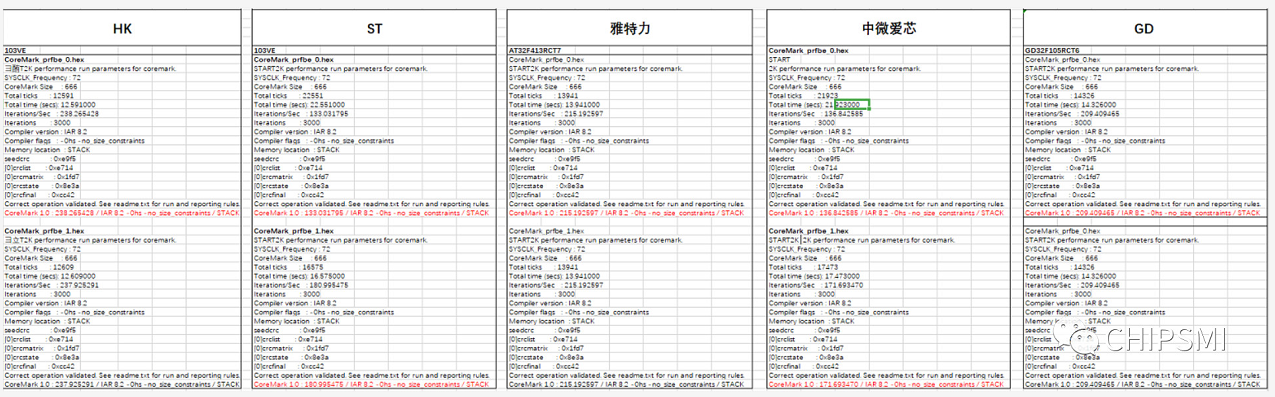
前三名CoreMark分數
HK32F103VET6 238 分
AT32F413RCT7 215 分
GD32F103VET6 209 分
是不是跟小編一樣很是意外,我們一一來看后面的數據。
STM32F103的跑分結果,沒什么好說,直接上圖。 開了Prefetchbuff 跑分多了近50分。
兆易創新GD32 MCU是中國高性能通用微控制器領域的先期領跑者,國內第一個推出的Arm Cortex-M3及Cortex-M4 內核通用MCU產品系列,19個系列300余款產品,當之無愧的ST以外的市場佼佼者。這次橫向評測的型號GD32F103 采用的雙DIE設計。(2019最新的E系是單DIE,但代碼不兼容)GD的FLASH跟MCU合封,這個設計最直接的劣勢就是效率低,功耗大。因為兩顆DIE, MCU跟FLASH分開,取址效率,程序執行效率低,功耗變大。但GD每顆型號都多加了32K 甚至更大的RAM,上電就把FLASH里的程序放到 RAM里面,這也是GD宣傳主打的所謂的 Flash零等待技術,沒有了提取指令的時間,通過這個設計來彌補硬件架構上的硬傷。但弊端也很明顯,成本高,且超出RAM的部分程序,代碼執行效率就非常非常低了。此次測試程序代碼大小應該完全是在RAM能提取的部分內。測試之前,猜測GD應該跑分最高。果然GD跑分209分,至于排名第三,是不是因為程序和數據共用一個RAM?
雅特力是位于重慶的一家微控制器芯片(MCU)設計公司,專攻32位 ARM Cortex?-M4 MCU產品, 也是***UMC旗下投資的公司,這次橫向評測采用的雅特力芯片AT32F413 也是本次所有測試芯片MCU里面唯一一個M4核的芯片。雅特力采用M4高性能 高主頻 先進工藝制程 ,用M4降維兼容ST的 M3系列。主打就是高性能路線。M4的優勢就不過多介紹,內核帶單精度浮點運算單元(FPU),支持所有ARM ? 單精度數據處理指令和數據類型,更快的處理速度,浮點運算能力,綜合效率M4遠超M3。測試之前,小編猜測應該雅特力是最高跑分的競爭者之一,果然跑分215分 排名第二。
航順芯片,說實話在2018年之前開發布會,沙龍,展覽因為業界看不懂褒貶不一,2019年在深圳國際嵌入式展會廣場巨大廣告牌“打出通用/專用32位MCU/SOC孵化100+MCU原廠”血紅的“中國科學院 深圳市產業基金 中國航空工業集團聯合打造”被吸引。對于國人很多夸張的宣傳,什么最牛,第一,最穩定,功耗最低,小編其實是不感冒的,但是航順這幾年逐步占領市場越來越多的得到客戶好評而好奇產生沖動一探究竟。說太多吹太多沒有用,不服來干。小編一直是這種事實說話的態度。在展會上向航順芯片申請樣品,航順接待人員非常熱情,大方提供各種M0 M3 M4樣品,此次測試前基本完全不太看好,但跑分卻是本次最大的黑馬,238分第一,確實大跌眼鏡,大大超乎意料。怪不得國企央企國資都聯合背書站臺,估計他們看中的就是航順的核心技術能力,此前業界各種褒貶和友商互相抬高自己打壓同行航順依然一邊營銷建立品牌一邊地推得到很多客戶認可,航順核心技術能力他們應該胸有成竹。但有意打探航順幾位創始人,他們都表示不太方便透露,跑分 性能穩定性 兼容性 功耗低 抗干擾等綜合水平好不好其實非常簡單,應用客戶一測試就知道。翻閱了下HK的芯片手冊,新加入的cache 可以提升指令效率,但cache也才1K。至于跑分這么高的原因,小編也只能猜測是不是采用了什么黑科技,CPU跟MEMORY的架構優化做到了很極致。
中微愛芯是中科芯控股旗下的,中字頭,中規中矩,跑分也中規中矩。此次跑分是國產唯一家開Prefetchbuff和不開 Prefetchbuff分數有差異的。各項分數也是跟ST差不多。開Prefetchbuff居然還比ST低了幾分 171分。從純模仿的角度,是比較完全按照ST的方式。其余幾家國產基本都擯棄了prefetchbuff的做法。我有更快的速度,有cache,有M4,開不開都已經從跑分碾壓上完全體現了,完全的模仿有沒有必要?當然這只是芯片眾多細節的一點。
最后, 國內芯片Coremark跑分都超過了ST,這點很欣慰 (中微愛芯開prefetchbuff 的跑分比ST差一點點)。但這完全得益于后發優勢,新的架構和新的工藝。有喜有憂,畢竟STM32F103已是十年前的芯片了,國產芯片仍然任重道遠。
2007年STM32首發, 中途歷經.18, .13的工藝,改了幾版到現在的版本也是十年前的事了。STM32之父、意法半導體微控制器事業部Daniel Colonna曾說過,“十年前我們選擇了蝴蝶作為STM32的代表Logo,意味著我們要利用STM32,為工程師、開發者們釋放更多創造力。” 如今這只蝴蝶扇動了STM32芯片占據全球市場半壁江山的份額,這幾年國產芯片把STM32作為模仿對標學習的對象當之無愧。
記得曾和一個朋友聊天,這么多家仿STM32的芯片。哪家做的最好?國產芯片和國外芯片的差距,到底在哪里?仿STM32,軟硬件完全兼容,市場替換快?客戶接受度高? 小編的看法確是,模仿或許只是一個切入口。明星模仿秀,比如模仿張學友,一個活生生的自然人硬要做到一模一樣,甚至連吃飯走路都刻意要做成一樣,最后把自身很多優點習慣都丟掉,甚至走路說話都不正常,這到底是好還是不好?從模仿的角度切入,方便客戶替換,便于開發者上手這點很好,但不同的設計架構電路IP理念,不同時期的工藝,純粹為了模仿而模仿,甚至降維降級去做兼容,有時候討好的不一定是終端使用者,反而是芯片設計本身的一種浪費和冗雜。模仿卻不全仿,抄襲但可以逆襲。同樣作為終端應用者的我們也要給與國產芯片更多的耐心與包容,國產替換的過程,一行代碼不兼容,一個配置設定不同,就質疑芯片本身,或許使用者本身完全也不全會測試和應用,甚至是外行,過多的關注產品銷售和客戶本身,卻忽略了芯片和方案應用的源本。就像航順,中微等等國產剛出來的時候被質疑被互損詆毀一樣,或許有時候不是芯片不好,是你應用不好。這次跑分的結果或許也能說明某些。中國芯不僅僅是一種情懷,也更需要更包容和更理解的土壤,需要更多的應用者使用者去嘗試去參與去等待去共同進步。
創新,革新,做好自己,做更好的自己。從模仿到創新,從抄襲到逆襲。此次的測評跑分國產芯片全面超越ST,除了后發優勢,國產芯片的創新,加入cache,M4,程序RAM,跑分全面超越國外芯片。但愿我們能看到一個新的芯時代的開啟。
跑分是衡量MCU芯片性能的一個非常非常重要標準,但不是唯一標準,下期將從另外維度評測。由于測試的環境外設,軟件硬件的不兼容性,為了確保測試公平一致性,某些代碼不兼容的國產芯片(靈動 華大等等)此期暫時不在本文列出。(類似華為手機小米手機跑分比賽,都是安卓平臺,有較強的可比性。蘋果自建生態跑分的參考性就會有換算的條件)




























 工商網監
工商網監
評論