 電子發燒友App
電子發燒友App


1、引言
隨著微電子技術的不斷發展,超大規模集成電路的集成度和工藝水平不斷提高,將整個應用電子系統集成在一個芯片中(SoC),已成為現代電子系統設計的趨勢。作為SoC的核心控制部分——微處理器,極大地影響了整個系統的設計。
本文所設計實現的微處理器符合Michael Slater對RISC的定義,采用流水線并行技術提高其執行效率。本文主要討論了RISC微處理器各關鍵模塊的設計與實現,通過對模塊的分析設計合理的流水線,并著重討論了流水線相關性問題,及其解決辦法,最后給出綜合和仿真結果。
2 、體系結構
2.1 指令集
微處理器指令長度固定為32位,指令格式如圖1,三種指令格式分別為寄存器(R)類型、立即(I)類型和跳轉(J)類型,結構固定簡單,便于設計和譯碼。微處理器主要實現了數據處理常用的指令,包括有算術運算(add,sub,addi,subi)、邏輯運算(and,andi,or,ori,nor,xor,xori)、比較運算(slt,sltu,slti,sltiu)、移位(rotr,rotl,srl,sll,sra,)、load/stroe指令(lw,sw)、分支跳轉指令(bne,beq,bgez,bgtz,blez,bltz,jump)和其它指令(nop,rst,clr) 共32條指令。
2.2 系統結構
微處理器系統結構如圖2所示,主要由ALU、譯碼單元、指令存儲器、數據存儲器、寄存器堆和寫回邏輯等構成。系統特點如下:采用Harvard結構;32個32位的寄存器,16KB的片內指令存儲器,16KB片內數據存儲器;32位地址,尋址方式簡單,只有立即數尋址、寄存器尋址和寄存器間接尋址三種。
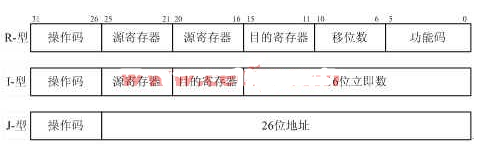
圖1、指令格式
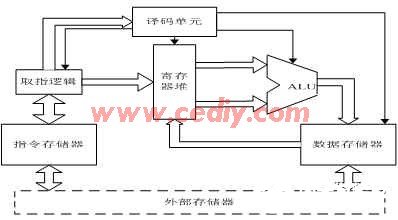
圖2、微處理器系統結構圖
3、關鍵部件
ALU是處理器的核心部件,主要完成算術、邏輯、比較和移位等運算。該ALU數據寬度為32位,操作碼寬度為5位。ALU根據譯碼單元提供的操作碼,進行各種算術邏輯運算。
寄存器堆regbank,RISC處理器的大部分指令通過寄存器來進行,所以寄存器的設計關系到整個體系結構,根據對體系結構的分析,需要設計32個通用寄存器。在FPGA設計中我們可以使用Xilinx的IP核生成器生成雙口RAM[3],寬度為32,深度為32,一端只讀,另一端支持讀寫。
譯碼單元控制著處理器各個部件的運行,通過對指令進行譯碼產生信號,控制各模塊的操作,包括指令取指操作,寄存器堆存取操作,ALU操作,操作數選擇,數據存儲器訪問和數據寫回等。
指令存儲器、數據存儲器,是分別用以存放程序指令和數據的存儲單元。在本設計中指令存儲器以單口RAM IP核生成,并賦予初值,數據寬度為32位,深度為4096,即16KB大小。數據存儲器也以單口RAM IP核生成,支持讀寫,寫模式為只寫,數據寬度為32位,深度為4096,即16KB大小。
取指邏輯包括程序計數器PC和地址加法器,主要完成從指令存儲器讀取指令和計算下一條指令的地址。
除了以上關鍵部件外,處理器還包括其它部件,如操作數選擇單元,寫回邏輯單元等。
4、 流水線設計
4.1 流水線
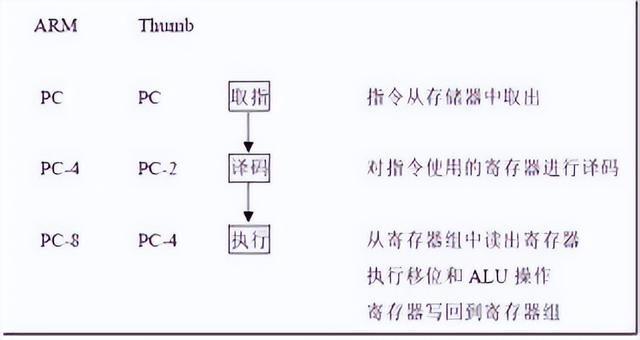
流水線是提高CPU處理速度的關鍵技術,為了提高指令執行速度,將整個執行過程劃分為幾個單元,各個單元完成固定部分工作,就像工廠的流水線作業一樣。在流水線劃分之前先對各處理關鍵模塊通過綜合工具進行大概的時延分析,在這使用ISE內嵌的綜合工具XST,雖然XST在算術、功能等方面不如業界流行的綜合工具Synplify Pro,但憑著對自己的器件熟悉,XST對Xilinx 芯片的支持是最直接。關鍵部件綜合測試內部邏輯延時情況如下表1,從表中可以看到,最大延時部件是ALU(10.19ns),由于采用流水線,ALU源操作數據有多個選擇,所以如果以ALU和數據選擇器作為一個流水段,其他流水段的組合時延不超過這一階段即可。經過分析,該流水線分為五段,即取指、譯指、執行、訪問存儲器和寫回五個階段。預測系統時鐘期為13.5ns。

4.2 流水線相關性問題及其解決
由于流水線的并行處理,產生指令相關性問題,一般存在三種相關:結構相關、數據相關和控制相關。在這主要討論數據相關和控制相關二種。
數據相關,是指當一條指令的執行依賴于前面某一條未執行完指令執行結果時,這兩條指令將發生數據相關。數據相關的解決通常有兩種方法,一是推后分析法,即遇到數據相關時,推后本條指令的分析,直到相關的數據寫入寄存器堆中;另一種是旁路技術(Forwarding)[4],即不必等到所需的數據寫入到相關的寄存器中,而是經過專門設置的數據通路讀取所需要的數據。這兩種方法各有春秋,推后分析法容易設計,但因等待相關數據寫入寄存器堆而引起了流水線斷流;旁路技術(Forwarding),利用專用數據路徑消除了一部分流水線斷流,提高了處理器的速度,但要占用一定的邏輯資源。如果你的可編程邏輯芯片資源足夠,采用旁路技術不失為一個提高處理器速度的好辦法。本設計就是通過設置專用數據通路解數據相關,將前面相關指令還未寫入寄存器堆的執行結果,提前提供給運算器使用,以減少流水線斷流,但相關指令是load指令,并數據還沒讀出時,只能通過延遲一個周期以保證操作數的正確性。
控制相關,是指當執行到分支跳轉指令時,因無條件分支目標地址還未計算出來,條件分支還未知條件是否成立等原因,而與后面的指令發生相關。控制相關問題的解決一般通過兩方面來解決,一方面通過盡早判斷分支條件是否成立和盡早計算出分支轉移的PC值來解決,在本設計中,分支跳轉條件的判斷和分支跳轉目標地址的計算,提前到譯碼階段由專門的比較器和加法單元來完成,這樣比在執行階段進行條件判斷和地址計算流水線可以減少斷流;另一方面通過轉移預測技術的硬件“猜測法”來解決,是指在當前還無法確定分支跳轉指令的執行情況,無法確定下一條指令時,依據指令過去的行為來預測將來的行為。在本設計中通過選址單元猜測分支條件不成立,繼續執行本指令的下一地址指令。猜測是否成功由譯碼單元決定,如果預測成功繼續執行,否則重新取指并預取的指令無效。
4.3 流水線時序設計
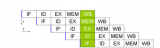
根據對各關鍵部件和流水線相關性的分析,設計系統流水線時序如圖3所示。流水線的各個階段在時鐘上升時開始執行。取指階段在時鐘上升沿時讀取程序計數器的指令地址,在本周期的時鐘下降沿時從指令存儲器讀取指令。由于在同一周期內要對寄存器堆進行寫操作和讀操作,為了避免因數據帶來的沖突,寄存器堆在前半周期進行寫操作,后半周期進行讀操作。
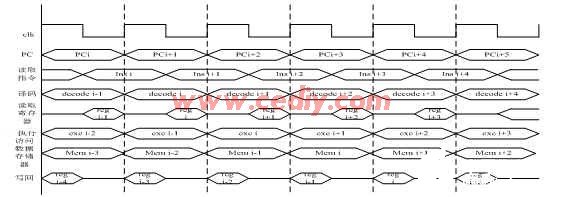
圖3、系統時序圖
4.4 流水線各階段設計與實現
取指階段,主要完成兩個任務,一是根據程序計數器PC里的指令地址從指令存儲器I_mem里讀取指。另一個任務主要完成PC+1計算和下一條指令地址的猜測。對下一條指令的猜測主要是假設分支條件不成立,猜測下一條指令地址是本指令地址的下一地址,除了對下一條指令的猜測,還完成對上一次的猜測的確認。本指令地址的確認主要是完成如果上一條指令是分支指令時,如果分支條件不成立,本指令地址猜測是正確,指令有效,繼續執行,否則本指令無效,重新再取指。
譯碼階段,是整個系統中的關鍵控制階段,不但進行指令譯碼,從寄存器堆中讀取操作數,而且判斷分支指令的跳轉條件,計算跳轉地址和處理數據相關性問題。這一階段主要器件有譯碼單元,寄存器堆,加法器,比較器和地址選擇器等。譯碼單元,可以說是核心控制單元,根據指令代碼譯碼成各種控制信號控制各個單元的控制,而且進行數據相關處理。
譯碼單元,因采用旁路技術來解決數據相關性問題,因此在譯碼單元中參照前兩條指令的目的寄存器號來確定是否發生數據相關性,如果發生數據相關,產生delay信號,使下一條指令重新取指。譯碼單元主要控制信號如下:
op_alu[4:0]:ALU操作控制信號,控制ALU執行相應的算術邏輯運算。
delay:延遲控制信號,盡管采用了設置專用路徑,避免了大部分的因數據相關帶來的延遲,但是當指令的源操作數是前一條指令是load讀存儲器指令或乘法指令的結果時,需要延遲一個周期,以解決寫后讀的數據相關性問題。
bj[1:0]:分支跳轉信號,控制地址選擇器選擇跳轉地址。
alua[1:0],alub[1:0]:ALU操作數選擇控制信號,ALU源操作數一般來自寄存器或立即數,但當采用設置專用路徑技術后,還有可能來自于與該指令相關的前兩條指令當前的運行結果。最后一些使能控制信號,如寄存器寫使能、數據存儲器讀寫使能等。
執行階段主要完成指令的邏輯運算工作,ALU根據操作控制碼對所提供的操作數進行相應的操作。讀/寫儲存階段主要完成存儲器中數據的讀取和寫入,是微處理器系統中比較復雜的功能,在這主要完成微處理器內部數據存儲器的讀寫。寫回階段是流水線的最后一個階段,它將運行結果寫回目的寄存器中。
5、 綜合與仿真結果
本設計采用ISE的開發環境,各個功能模塊均分別在XST和ISE Simulator進行了邏輯綜合和功能仿真。選擇目標器件為4vfx12ff668-10,頂層模塊綜合結果如表2。
從綜合結果可以看出,該處理器占FPGA芯片可編程邏輯單元不超過10%,最大工作頻率達到74.59MHz,達到了設計要求。

使用ISE自帶的仿真工器進行功能仿真,測試程序如下:
1: 20010001; //addi $1,$0,1; 6:14430003; //bne $2,$3,3;
2: 00201024; //and $2,$1,$0; 7: 24240000; //subi $4,$1,0;
3: 8C020002; //lw $2,2; 8: 00231024; //and $2,$1,$3;
4: 00221827; //rotr $1,$3,2; 9: 00412822; //sub $5,$2,$1;
5: 00030881; //xor $3,$1,$2; 10:08000005; //jump 5;
通過對波形的分析,如圖4,該處理器達到了設計目的,各條指令能夠正確執行,當發生數據相關時,ALU通過專用路線能夠獲得正確的操作數,或者發生延時。當遇到分支跳轉指令時,取指邏輯能夠猜測下一條指令地址,并指令譯碼后判斷猜測是否正確。

圖4、仿真測試波形
6 、結論
流水線處理器的設計關鍵是流水線各階段的設計和因流水線引起的各種相關性問題的解決。本文通過對RISC處理器各關鍵部件進行分析,合理安排流水線。在流水線設計中,通過對因流水線引起的相關性問題進行分析研究,采用旁路技術來解決數據相關性的寫后讀問題,采用硬件猜測法預取分支跳轉指令的目標指令,以減少流水線斷流提高處理器處理速度,從綜合和仿真的結果可以看到設計達到了預期的目標。本設計使用Verilog進行硬件描述設計,具有較好的可讀性和可移植性,可以根據需要進行功能的增減,與其他IP核集合成SoC系統。
本文作者創新點:通過對RISC處理器的分析,設計處理器關鍵模塊,并進行時延分析,合理地設計流水線。在流水線相關性問題方面,采用旁路技術來解決數據相關性的寫后讀問題,采用硬件猜測法預取分支跳轉指令的目標指令,以減少流水線斷流提高處理器處理速度。
責任編輯:gt













 工商網監
工商網監
評論