 電子發燒友App
電子發燒友App


使用一類新興的高效算法,任何開發人員現在都可以在低功耗、資源受限的系統上部署復雜的關鍵字識別功能。這個由兩部分組成的系列的第一部分展示了如何使用 FPGA 來做到這一點。在第二部分中,我們將展示如何使用 MCU 來做到這一點。
關鍵字發現 (KWS) 技術已成為可穿戴設備、物聯網設備和其他智能產品越來越重要的功能。機器學習方法可以提供卓越的 KWS 準確性,但這些產品的功能和性能限制直到最近限制了大型企業或經驗豐富的機器學習專家對機器學習 KWS 解決方案的使用。
然而,開發人員越來越需要在可穿戴設備和其他物聯網設備中在能夠在這些設備的資源限制內運行的更高效的 KWS 引擎上實現語音激活的 KWS 功能。深度可分離卷積神經網絡 (DS-CNN) 架構修改了傳統的 CNN 以提供所需的效率。
使用硬件優化的神經網絡庫,開發人員可以實現需要最少資源的基于 MCU 的 DS-CNN 推理引擎。本文描述了 DS-CNN 架構,并展示了開發人員如何在 MCU 上實現 DS-CNN KWS。
為什么選擇 KWS?
消費者對使用“Alexa”、“Hey Siri”或“Ok Google”等短語的智能手機和家用電器上的語音激活功能的接受度已迅速演變為對幾乎所有為用戶交互而設計的產品的語音服務的廣泛需求。在這些服務的基礎上,準確的語音識別依賴于各種人工智能方法來識別口語單詞,并將單詞和詞組解釋為適合應用程序的命令。
然而,快速準確地完成整個語音命令序列所需的資源開始超過低成本線路供電消費集線器的能力,更不用說電池供電的個人電子產品了。
語音命令管道要求
為了在這些產品上提供語音激活,開發人員將語音命令管道拆分或將語音命令限制為幾個非常簡單的詞,例如“開”和“關”。在資源有限的消費產品上,開發人員使用神經網絡推理引擎實現 KWS 功能,該引擎能夠為 Alexa、Siri 或 Google 的簡單命令或命令激活短語提供所需的高精度、低延遲響應(圖 1)。
在這里,設計將輸入音頻流數字化,提取語音特征,并將這些特征傳遞給神經網絡以識別關鍵字。
?
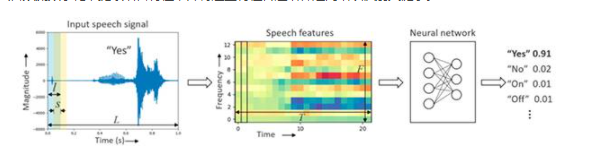
圖 1:使用 KWS 進行語音激活使用處理管道從音頻輸入信號中提取頻域特征,并對提取的特征進行分類,以預測輸入信號對應于用于訓練神經網絡的標簽之一的概率。(圖片來源:Arm?)
通過將幅度調制的音頻輸入流轉換為頻譜圖中的特征,開發人員可以利用卷積神經網絡 (CNN) 模型經過驗證的能力,根據神經網絡訓練期間使用的標簽之一對口語進行準確分類。2對于更復雜的語音接口,命令處理管道超出了設備本身。在 KWS 推理引擎檢測到激活關鍵字或短語后,產品將數字化的音頻流傳遞給基于云的服務,能夠更有效地處理復雜的語音處理和命令識別操作。
盡管如此,設備資源可用性和推理引擎資源需求之間的沖突仍使開發人員試圖將這些方法應用于更小的可穿戴設備和物聯網設備設計的嘗試。盡管經典的 CNN 相對容易理解且易于訓練,但這些模型仍然可能是資源密集型的。隨著 CNN 模型在識別圖像方面的準確度大幅提高,CNN 的大小和復雜度也顯著增加。
結果是非常精確的 CNN 模型,需要數十億計算密集型通用矩陣乘法 (GEMM) 操作進行訓練。一旦經過訓練,相應的推理模型可能會占用數百兆內存,并且需要非常大量的 GEMM 操作才能進行單個推理。
對于電池供電的可穿戴設備和物聯網設備,有效的 KWS 推理模型必須能夠在有限的內存中運行且處理要求低。此外,由于 KWS 推理引擎必須在“始終開啟”模式下運行才能執行其功能,因此它必須能夠以最低功耗運行。
在越來越有吸引力的可穿戴設備和物聯網設備領域,神經網絡的潛力與有限資源之間的這種二分法引起了機器學習專家的極大關注。結果是開發了優化基本 CNN 模型的技術,并出現了替代神經網絡架構,能夠彌合小型資源受限設備的性能要求和資源能力之間的差距。
小尺寸型號
在創建小型模型的技術中,機器學習專家已經應用了網絡修剪和參數量化等優化方法來生成 CNN 變體,這些變體能夠提供幾乎與完整 CNN 一樣準確的結果,但只使用了一小部分資源。這些降低精度的神經網絡的成功為二值化神經網絡 (BNN) 架構鋪平了道路,該架構將模型參數從 32 位浮點數,甚至早期 CNN 中的 16 位和 8 位浮點數減少到 1 位價值觀。如第 1 部分所述,Lattice Semiconductor機器學習SensAI?平臺使用這種高效的 BNN 架構作為 1 毫瓦 (mW) KWS 解決方案的基礎,該解決方案在其基于 FPGA 的iCE40 UltraPlus移動開發平臺,或 MDP。
除了網絡修剪和參數量化等簡化技術外,還有其他降低資源需求的方法可以修改 CNN 架構本身的拓撲結構。在這些替代架構中,深度可分離卷積神經網絡提供了一種特別有效的方法來創建能夠在通用 MCU 上運行的小型、資源高效模型。
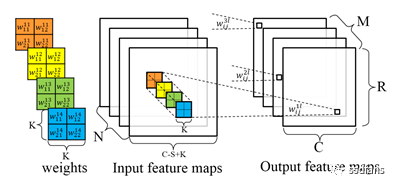
在早期工作的基礎上,谷歌機器學習專家找到了一種通過關注卷積層本身來提高 CNN 效率的方法。在傳統的 CNN 中,每個卷積層過濾輸入特征并在一個步驟中將它們組合成一組新的特征(圖 2,頂部)。
?
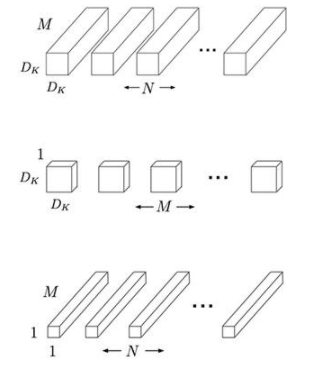
圖 2:與全卷積(上)不同,深度可分離卷積首先使用 D K xD K濾波器(中)分別過濾 M 個輸入通道中的每一個,并使用逐點 1 x 1 卷積來創建 N 個新特征。(圖片來源:谷歌)
新方法將過濾和特征生成分為兩個獨立的階段,統稱為深度可分離卷積。第一階段執行深度卷積,該卷積在輸入的每個通道上充當空間濾波器(圖 2,中間)。因為第一階段不創建新特征(深度神經網絡架構的核心目標),所以第二階段執行逐點 1 x 1 卷積(圖 2,底部),它結合第一階段的輸出以生成新特征。
這種 DS-CNN 架構在用于移動和嵌入式視覺應用的 Google MobileNet 模型中使用,減少了參數和相關操作的數量,從而產生更小的模型,需要顯著更少的計算來獲得準確的結果。3
與全卷積相比,在 MobileNet 模型中使用深度可分離卷積在行業標準 ImageNet 數據集上僅降低了 1% 的準確度,但使用了不到 12% 的乘加運算和所需的模型參數數量的 14%用于傳統 ImageNet CNN 模型中的全卷積。
盡管 DS-CNN 最初是為圖像識別而開發的,但這些相同的模型可以通過將音頻輸入流轉換為頻譜圖來提供一組可用的特征來提供音頻識別。實際上,音頻前端將音頻流轉換為 DS-CNN 可以分類的一組特征。對于語音處理,前端產生的特征通常采用梅爾頻率倒譜系數(MFCC)的形式,它更接近人類的聽覺特征,同時顯著降低了傳遞給 DS-CNN 分類器的特征集的維數。這正是 ARM ML-KWS-for-MCU開源軟件存儲庫中使用的方法。
DS-CNN 實現
ARM KWS 存儲庫旨在演示在 Arm Cortex ? -M 系列 MCU 上的 KWS 實施,在包括傳統 CNN、DS-CNN 等在內的多種架構中提供了大量預訓練的 TensorFlow 模型。使用谷歌速度命令數據集4訓練,模型將音頻輸入分類為 12 個可能的類別之一:“是”、“否”、“上”、“下”、“左”、“右”、“開”、“ Off”、“Stop”、“Go”、“silence”(不說話)和“unknown”(代表 Google 數據集中包含的其他詞)。
開發人員可以立即使用這些預訓練模型來比較這些替代神經網絡架構的推理性能并檢查它們的內部結構。例如,在 ARM 的預訓練 DS-CNN 模型上運行 TensorFlow 的import_pb_to_tensorboard Python 實用程序后,開發人員可以使用 TensorBoard 可視化模型的基于 MobileNet 的架構。
?
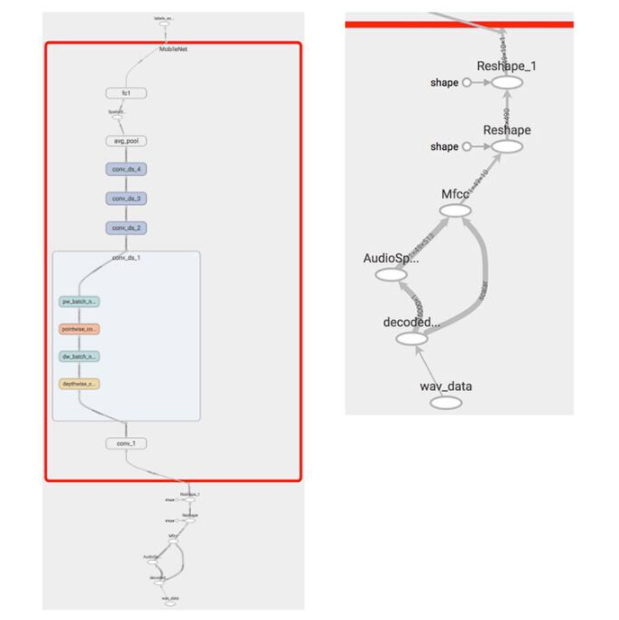
圖 3:在 TensorBoard 中顯示的 Arm 預訓練 KWS 模型將熟悉的 MobileNet DS-CNN 模型(左紅色輪廓)與使用梅爾頻率倒譜系數 (MFCC) 的頻域特征提取階段(右擴展)相結合. (圖片來源:Digi-Key Electronics)
正如在 TensorBoard 中所展示的那樣,MobileNet 架構用深度可分離卷積替換了傳統 CNN 架構中除第一個完整卷積層之外的所有卷積層。
如前所述,這些階段中的每一個都包括深度卷積和點卷積階段,每個階段都輸入一個 batchnorm 內核以對輸出結果進行歸一化(圖 3,左)。DS-CNN 模型使用一個特殊的 TensorFlow 融合 batchnorm 函數,它將多個選項組合到一個內核中。
此外,通過放大音頻輸入特征提取階段(圖 3,右),開發人員可以檢查音頻處理序列,包括音頻解碼、頻譜圖生成和 MFCC 濾波。MFCC 生成的特征通過一對重塑階段來創建 MobileNet 分類器所需的張量形狀。
可以想象,開發人員可以在基于 MCU 的系統(包括Raspberry Pi )上運行來自 TensorFlow 或其他機器學習框架的訓練模型。5使用這種方法,開發人員可以量化經過訓練的模型,以生成能夠在這些系統上運行的較小版本。但是,如果沒有圖形處理單元 (GPU) 或其他硬件支持 GEMM 加速,推理延遲可能會令用戶對語音激活性能的預期失望。
ARM 通過其對 ARM Cortex 微控制器軟件接口標準 (CMSIS) 的神經網絡 (NN) 擴展提供了一種替代方法。CMSIS-NN 提供一整套 CNN 功能,充分利用 ARM Cortex-M7 處理器(例如STMicroelectronics 的 STM32F7 MCU 系列中的那些)中內置的 DSP 擴展。除了傳統的 CNN 函數外,CMSIS-NN 應用程序編程接口 (API) 還支持深度可分離卷積,其中一對函數對應于 DS-CNN 架構下的深度和逐點 1 x 1 卷積階段:
ARM_status ARM_depthwise_separable_conv_HWC_q7_nonsquare
ARM_status ARM_convolve_1x1_HWC_q7_fast_nonsquare
該 API 還在專門為方形輸入張量設計的版本中提供了這兩個函數。
ARM 在示例代碼中使用這些函數,該示例代碼演示了一個完整的基于 DS-CNN 的 KWS 應用程序,該應用程序在 STMicroelectronics STM32F746G-DISCO開發板上運行,該開發板圍繞STM32F746NGH6 MCU 構建。在示例代碼的核心,原生 CMSIS-NN C++ 模塊實現了 CS-DNN(清單 1)。
void DS_CNN::run_nn(q7_t* in_data, q7_t* out_data)
{
//CONV1 : regular convolution
ARM_convolve_HWC_q7_basic_nonsquare(in_data, CONV1_IN_X, CONV1_IN_Y, 1, conv1_wt, CONV1_OUT_CH, CONV1_KX, CONV1_KY, CONV1_PX, CONV1_PY, CONV1_SX, CONV1_SY, conv1_bias, CONV1_BIAS_LSHIFT, CONV1_OUT_RSHIFT, buffer1, CONV1_OUT_X, CONV1_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV1_OUT_X*CONV1_OUT_Y*CONV1_OUT_CH);
// conv2:ds + pw conv // depthwise可分開的cons(批次范圍折疊為conv wts/bias) arm_depthwise_separible_conv_hwc_hwc_hwc_hwc_q7_nonsquare(buffer1,conv2_in_in_x,conv2_in_y,conv2_in_y,
conv1_out_conve_c__cond_ss_s_ds_s_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_d, conv2_ds_bias,CONV2_DS_BIAS_LSHIFT,CONV2_DS_OUT_RSHIFT,buffer2,CONV2_OUT_X,CONV2_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV2_OUT_X*CONV2_OUT_Y*CONV2_OUT_CH); // 逐點卷積 ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV2_OUT_X, CONV2_OUT_Y, CONV1_OUT_CH, conv2_pw_wt, CONV2_OUT_CH, 1, 1, 0, 0, 1, 1, conv2_pw_bias, CONV2_PW_BIAS_LSHIFT,
CONV2_PW_OUT_RSHIFT, buffer1, CONV2_OUT_X, CONV2_bufferY, (NULL), CONV2_buff_Y, (NULL)_ ARM_relu_q7(buffer1,CONV2_OUT_X*CONV2_OUT_Y*CONV2_OUT_CH);
//CONV3 : DS + PW conv
//Depthwise separable conv (batch norm params folded into conv wts/bias)
ARM_depthwise_separable_conv_HWC_q7_nonsquare(buffer1,CONV3_IN_X,CONV3_IN_Y,CONV2_OUT_CH,conv3_ds_wt,CONV2_OUT_CH,CONV3_DS_KX,CONV3_DS_KY,CONV3_DS_PX,CONV3_DS_PY,CONV3_DS_SX,CONV3_DS_SY,conv3_ds_bias,CONV3_DS_BIAS_LSHIFT,CONV3_DS_OUT_RSHIFT,buffer2,CONV3_OUT_X,CONV3_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV3_OUT_X*CONV3_OUT_Y*CONV3_OUT_CH);
//Pointwise conv
ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV3_OUT_X, CONV3_OUT_Y, CONV2_OUT_CH, conv3_pw_wt, CONV3_OUT_CH, 1, 1, 0, 0, 1, 1, conv3_pw_bias, CONV3_PW_BIAS_LSHIFT, CONV3_PW_OUT_RSHIFT, buffer1, CONV3_OUT_X, CONV3_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV3_OUT_X*CONV3_OUT_Y*CONV3_OUT_CH);
//CONV4 : DS + PW conv
//Depthwise separable conv (batch norm params folded into conv wts/bias)
ARM_depthwise_separable_conv_HWC_q7_nonsquare(buffer1,CONV4_IN_X,CONV4_IN_Y,CONV3_OUT_CH,conv4_ds_wt,CONV3_OUT_CH,CONV4_DS_KX,CONV4_DS_KY,CONV4_DS_PX,CONV4_DS_PY,CONV4_DS_SX,CONV4_DS_SY,conv4_ds_bias,CONV4_DS_BIAS_LSHIFT,CONV4_DS_OUT_RSHIFT,buffer2,CONV4_OUT_X,CONV4_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV4_OUT_X*CONV4_OUT_Y*CONV4_OUT_CH);
//Pointwise conv
ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV4_OUT_X, CONV4_OUT_Y, CONV3_OUT_CH, conv4_pw_wt, CONV4_OUT_CH, 1, 1, 0, 0, 1, 1, conv4_pw_bias, CONV4_PW_BIAS_LSHIFT, CONV4_PW_OUT_RSHIFT, buffer1, CONV4_OUT_X, CONV4_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV4_OUT_X*CONV4_OUT_Y*CONV4_OUT_CH);
//CONV5 : DS + PW conv
//Depthwise separable conv (batch norm params folded into conv wts/bias)
ARM_depthwise_separable_conv_HWC_q7_nonsquare(buffer1,CONV5_IN_X,CONV5_IN_Y,CONV4_OUT_CH,conv5_ds_wt,CONV4_OUT_CH,CONV5_DS_KX,CONV5_DS_KY,CONV5_DS_PX,CONV5_DS_PY,CONV5_DS_SX,CONV5_DS_SY,conv5_ds_bias,CONV5_DS_BIAS_LSHIFT,CONV5_DS_OUT_RSHIFT,buffer2,CONV5_OUT_X,CONV5_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV5_OUT_X*CONV5_OUT_Y*CONV5_OUT_CH);
//Pointwise conv
ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV5_OUT_X, CONV5_OUT_Y, CONV4_OUT_CH, conv5_pw_wt, CONV5_OUT_CH, 1, 1, 0, 0, 1, 1, conv5_pw_bias, CONV5_PW_BIAS_LSHIFT, CONV5_PW_OUT_RSHIFT, buffer1, CONV5_OUT_X, CONV5_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV5_OUT_X*CONV5_OUT_Y*CONV5_OUT_CH);
//Average pool
ARM_avepool_q7_HWC_nonsquare (buffer1,CONV5_OUT_X,CONV5_OUT_Y,CONV5_OUT_CH,CONV5_OUT_X,CONV5_OUT_Y,0,0,1,1,1,1,NULL,buffer2, 2);
ARM_fully_connected_q7(buffer2, final_fc_wt, CONV5_OUT_CH, OUT_DIM, FINAL_FC_BIAS_LSHIFT, FINAL_FC_OUT_RSHIFT, final_fc_bias, out_data, (q15_t*)col_buffer);
}
清單 1:ARM ML-KWS-for-MCU 軟件存儲庫包含一個 C++ DS-CNN 模型,其中一個完整的卷積層后跟幾個深度可分離卷積(框),每個都使用深度卷積和 1 x 1 卷積函數(黃色突出顯示)在硬件優化的 ARM CMSIS-NN 軟件庫中支持。(代碼來源:ARM)
盡管 C++ DS-CNN 實現與前面展示的 TensorBoard DS-CNN 模型略有不同,但總體方法保持不變。在初始全卷積核之后,一系列深度可分離卷積核輸入最終池化層和全連接層,以生成每個輸出通道的預測值(對應于用于訓練模型的 12 個類標簽)。
KWS 應用程序將此模型與代碼相結合,以提供對 STM32F746G-DISCO 開發板收集的實時音頻流的推斷。在這里,主函數初始化推理引擎,啟用音頻采樣,然后進入由單個等待中斷 (WFI) 調用組成的無限循環(清單 2)。
char output_class[12][8] = {“Silence”, “Unknown”,“yes”,“no”,“up”,“down”,
“left”,“right”,“on”,“off”,“stop”,“go”};
int main()
{
pc.baud(9600);
kws = new KWS_F746NG(recording_win,averaging_window_len);
init_plot();
kws-》start_kws();
T.start();
while (1) {
/* A dummy loop to wait for the interrupts. Feature extraction and
neural network inference are done in the interrupt service routine. */
__WFI();
}
}
/*
* The audio recording works with two ping-pong buffers.
* The data for each window will be tranfered by the DMA, which sends
* sends an interrupt after the transfer is completed.
*/
// Manages the DMA Transfer complete interrupt.
void BSP_AUDIO_IN_TransferComplete_CallBack(void)
{
ARM_copy_q7((q7_t *)kws-》audio_buffer_in + kws-》audio_block_size*4, (q7_t *)kws-》audio_buffer_out + kws-》audio_block_size*4, kws-》audio_block_size*4);
if(kws-》frame_len != kws-》frame_shift) {
//copy the last (frame_len - frame_shift) audio data to the start
ARM_copy_q7((q7_t *)(kws-》audio_buffer)+2*(kws-》audio_buffer_size-(kws-》frame_len-kws-》frame_shift)), (q7_t *)kws-》audio_buffer, 2*(kws-》frame_len-kws-》frame_shift));
}
// copy the new recording data
for (int i=0;i《kws-》audio_block_size;i++) {
kws-》audio_buffer[kws-》frame_len-kws-》frame_shift+i] = kws-》audio_buffer_in[2*kws-》audio_block_size+i*2];
}
run_kws();
return;
}
// Manages the DMA Half Transfer complete interrupt.
void BSP_AUDIO_IN_HalfTransfer_CallBack(void)
{
ARM_copy_q7((q7_t *)kws-》audio_buffer_in, (q7_t *)kws-》audio_buffer_out, kws-》audio_block_size*4);
if(kws-》frame_len!=kws-》frame_shift) {
//copy the last (frame_len - frame_shift) audio data to the start
ARM_copy_q7((q7_t *)(kws-》audio_buffer)+2*(kws-》audio_buffer_size-(kws-》frame_len-kws-》frame_shift)), (q7_t *)kws-》audio_buffer, 2*(kws-》frame_len-kws-》frame_shift));
}
// copy the new recording data
for (int i=0;i《kws-》audio_block_size;i++) {
kws-》audio_buffer[kws-》frame_len-kws-》frame_shift+i] = kws-》audio_buffer_in[i*2];
}
run_kws();
return;
}
void run_kws()
{
kws-》extract_features(); //extract mfcc features
kws-》classify(); //classify using dnn
kws-》average_predictions();
plot_mfcc();
plot_waveform();
int max_ind = kws-》get_top_class(kws-》averaged_output);
if(kws-》averaged_output[max_ind]》detection_threshold*128/100)
sprintf(lcd_output_string,“%d%% %s”,((int)kws-》averaged_output[max_ind]*100/128),output_class[max_ind]);
lcd.ClearStringLine(8);
lcd.DisplayStringAt(0, LINE(8), (uint8_t *) lcd_output_string, CENTER_MODE);
}
清單 2:在 ARM ML-KWS-for-MCU 軟件存儲庫中,DS-CNN KWS 應用程序的主例程(通過KWS_F746NG)實例化推理引擎,激活 STM32F746G-DISCO 開發板的音頻子系統,并進入無限循環,等待中斷調用執行推理的完成例程 ( run_kws())。(代碼來源:ARM)
包含在此main例程中的回調函數提供完成例程,這些例程緩沖記錄的數據并通過調用run_kws(). 該run_kws函數調用對推理引擎實例的調用以提取特征、對結果進行分類并提供預測,以指示記錄的音頻樣本屬于如前所述的原始訓練中使用的 12 個類之一的概率。
推理引擎本身是通過一系列調用實例化的,從main實例化KWS_F746NG類的調用開始,該類本身是類的子KWS_DS_NN類。后一個類使用父類封裝了前面顯示的 C++ DS-CNN 模型,該類KWS實現了特定的推理引擎方法:extract_features()、classify()等(清單 3)。
#include “kws.h”
KWS::KWS()
{
}
KWS::~KWS()
{
delete mfcc;
delete mfcc_buffer;
delete output;
delete predictions;
delete averaged_output;
}
void KWS::init_kws()
{
num_mfcc_features = nn-》get_num_mfcc_features();
num_frames = nn-》get_num_frames();
frame_len = nn-》get_frame_len();
frame_shift = nn-》get_frame_shift();
int mfcc_dec_bits = nn-》get_in_dec_bits();
num_out_classes = nn-》get_num_out_classes();
mfcc = new MFCC(num_mfcc_features, frame_len, mfcc_dec_bits);
mfcc_buffer = new q7_t[num_frames*num_mfcc_features];
output = new q7_t[num_out_classes];
averaged_output = new q7_t[num_out_classes];
predictions = new q7_t[sliding_window_len*num_out_classes];
audio_block_size = recording_win*frame_shift;
audio_buffer_size = audio_block_size + frame_len - frame_shift;
}
void KWS::extract_features()
{
if(num_frames》recording_win) {
//move old features left
memmove(mfcc_buffer,mfcc_buffer+(recording_win*num_mfcc_features),(num_frames-recording_win)*num_mfcc_features);
}
//compute features only for the newly recorded audio
int32_t mfcc_buffer_head = (num_frames-recording_win)*num_mfcc_features;
for (uint16_t f = 0; f 《 recording_win; f++) {
mfcc-》mfcc_compute(audio_buffer+(f*frame_shift),&mfcc_buffer[mfcc_buffer_head]);
mfcc_buffer_head += num_mfcc_features;
}
}
void KWS::classify()
{
nn-》run_nn(mfcc_buffer, output);
// Softmax
ARM_softmax_q7(output,num_out_classes,output);
}
int KWS::get_top_class(q7_t* prediction)
{
int max_ind=0;
int max_val=-128;
for(int i=0;i《num_out_classes;i++) {
if(max_val《prediction[i]) {
max_val = prediction[i];
max_ind = i;
}
}
return max_ind;
}
void KWS::average_predictions()
{
//shift right old predictions
ARM_copy_q7((q7_t *)predictions, (q7_t *)(predictions+num_out_classes), (sliding_window_len-1)*num_out_classes);
//add new predictions
ARM_copy_q7((q7_t *)output, (q7_t *)predictions, num_out_classes);
//compute averages
int sum;
for(int j=0;j《num_out_classes;j++) {
sum=0;
for(int i=0;i《sliding_window_len;i++)
sum += predictions[i*num_out_classes+j];
averaged_output[j] = (q7_t)(sum/sliding_window_len);
}
}
清單 3:在 ARM DS-CNN KWS 應用程序中,KWS 模塊在基本 DS-CNN 類上添加了執行推理操作所需的方法,包括特征提取、分類和生成由平均窗口平滑的結果。(代碼來源:ARM)
所有這些軟件復雜性都隱藏在一個簡單的使用模型后面,其中主程序通過實例化推理引擎來啟動該過程,并在音頻輸入可用時使用其完成程序執行推理。據 ARM 稱,在 STM32F746G-DISCO 開發板上運行的這個示例 CMSIS-NN 實現只需要大約 12 毫秒 (ms) 即可完成一個推理周期,其中包括音頻數據緩沖區復制、特征提取和 DS-CNN 模型執行。同樣重要的是,完整的 KWS 應用程序只需要大約 70 KB 的內存。
結論
隨著 KWS 功能作為一項要求變得越來越重要,資源有限的可穿戴設備和其他物聯網設計的開發人員需要占用空間小的推理引擎。ARM CMSIS-NN 旨在利用 ARM Cortex-M7 MCU 中的 DSP 功能,為實現優化的神經網絡架構(如 DS-CNN)奠定了基礎,能夠滿足這些要求。
在基于 ARM Cortex-M7 MCU 的開發系統上運行的 KWS 推理引擎可以在資源有限的物聯網設備輕松支持的內存占用中實現接近 10 次推理/秒的性能。
















 工商網監
工商網監
評論