 電子發燒友App
電子發燒友App


Observer協處理器通常在一個特定的事件(諸如Get或Put)之前或之后發生,相當于RDBMS中的觸發器。Endpoint協處理器則類似于RDBMS中的存儲過程,因為它可以讓你在RegionServer上對數據執行自定義計算,而不是在客戶端上執行計算。
1 協處理器簡介
如果要統計HBase中的數據,比如統計某個字段的最大值、統計滿足某種條件的記錄數、統計各種記錄的特點并按照記錄特點分類等等,常規的做法是把HBase中整個表的數據Scan出來,或者加一個Filter,進行一些初步的過濾,然后在客戶端進行統計處理。但是這么做會有很大的副作用,比如占用大量的網絡帶寬(大數據量尤為明顯),RPC的壓力也是不容小覷的。
HBase作為列式數據庫最經常被人詬病的特性包括:無法輕易建立“二級索引”,難以執行求和、計數、排序等操作。比如,在舊版本的(《0.92)HBase中,統計數據表的總行數,需要使用Counter方法,執行一次MapReduce Job才能得到。雖然HBase在數據存儲層中集成了MapReduce,能夠有效進行數據表的分布式計算,然而在很多情況下,做一些簡單的相加或者聚合計算的時候,如果直接將計算過程放置在server端,能夠減少網絡開銷,從而獲得很好的性能提升。于是,HBase在0.92之后引入了協處理器(coprocessors),實現了一些激動人心的新特性:能夠輕易建立二次索引、復雜過濾器以及訪問控制等。
簡單理解來說,協處理器是HBase讓用戶的部分邏輯在數據存放端即HBase服務端進行計算的機制,它允許用戶在HBase服務端運行自己的代碼。
2 協處理器的分類
協處理器分為兩種類型:系統協處理器可以全局導入Region Server上的所有數據表,表協處理器是用戶可以指定一張表使用的協處理器。協處理器框架為了更好支持其行為的靈活性,提供了兩個不同方面的插件。一個是觀察者(Observer),類似于關系數據庫的觸發器。另一個是終端(Endpoint),動態的終端有點像存儲過程。
Observer的設計意圖是允許用戶通過插入代碼來重載協處理器框架的upcall方法,而具體的事件觸發的callback方法由HBase的核心代碼來執行。協處理器框架處理所有的callback調用細節,協處理器自身只需要插入添加或者改變的功能。
Endpoint是動態RPC插件的接口,它的實現代碼被安裝在服務器端,從而能夠通過HBase RPC喚醒。客戶端類庫提供了非常方便的方法來調用這些動態接口,它們可以在任意時候調用一個終端,它們的實現代碼會被目標Region遠程執行,結果會返回到終端。用戶可以結合使用這些強大的插件接口,為HBase添加全新的特性。
3 Protocol Buffer的使用
由于下面的Endpoint編碼示例使用了Google公司的混合語言數據標準Protocol Buffer,所以首先了解一下這個常用于RPC系統的工具。
3.1 ProtocolBuffer介紹
Protocol Buffer是一種輕便高效的結構化數據存儲格式,可以用于結構化數據串行化,很適合做數據存儲或RPC數據交換格式。它可用于通訊協議、數據存儲等領域的語言無關、平臺無關、可擴展的序列化結構數據格式。目前提供了C++、Java、Python三種語言的 API。
為什么要使用Protocol Buffer呢?先看一個在實際開發中經常會遇到的系統場景:我們的客戶端程序是使用Java開發的,可能運行自不同的平臺,如Linux、Windows或者是Android,而我們的服務器程序通常是基于Linux平臺并使用C++開發完成的。在這兩種程序之間進行數據通訊時存在多種方式用于設計消息格式,如:
1、直接傳遞C/C++語言中字節對齊的結構體數據,只要結構體的聲明為定長格式,那么該方式對于C/C++程序而言就非常方便了,僅需將接收到的數據按照結構體類型強行轉換即可。事實上對于變長結構體也不會非常麻煩。在發送數據時,也只需定義一個結構體變量并設置各個成員變量的值之后,再以char*的方式將該二進制數據發送到遠端。反之,該方式對于Java開發者而言就會非常繁瑣,首先需要將接收到的數據存于ByteBuffer之中,再根據約定的字節序逐個讀取每個字段,并將讀取后的值再賦值給另外一個值對象中的域變量,以便于程序中其他代碼邏輯的編寫。對于該類型程序而言,聯調的基準是必須客戶端和服務器雙方均完成了消息報文構建程序的編寫后才能展開,而該設計方式將會直接導致Java程序開發的進度過慢。即便是Debug階段,也會經常遇到Java程序中出現各種域字段拼接的小錯誤。
2、使用SOAP協議(WebService)作為消息報文的格式載體,由該方式生成的報文是基于文本格式的,同時還存在大量的XML描述信息,因此將會大大增加網絡IO的負擔。又由于XML解析的復雜性,這也會大幅降低報文解析的性能。總之,使用該設計方式將會使系統的整體運行性能明顯下降。
對于以上兩種方式所產生的問題,Protocol Buffer均可以很好的解決,不僅如此,Protocol Buffer還有一個非常重要的優點就是可以保證同一消息報文新舊版本之間的兼容性。
3.2 安裝Protocol Buffer
// 在https://developers.google.com/protocol-buffers/docs/downloads下載protobuf-2.6.1.tar.gz后解壓至指定目錄
$ tar -xvf protobuf-2.6.1.tar.gz -C app/
// 刪除壓縮包
$ rm protobuf-2.6.1.tar.gz
// 安裝c++編譯器相關包
$ sudo apt-get install g++
// 編譯安裝protobuf
$ cd app/protobuf-2.6.1/
$ 。/configure
$ make
$ make check
$ sudo make install
// 添加到lib
$ vim ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
$ source ~/.bashrc
// 驗證是否安裝成功
$ protoc --version
3.3 編寫proto文件
首先需要編寫一個 proto 文件,定義程序中需要處理的結構化數據。proto 文件非常類似java或者C語言的數據定義。如下代碼給出了示例中定義RPC接口的 endpoint.proto文件內容:
[plain] view plain copy// 定義常用選項
option java_package = “com.hbase.demo.endpoint”; //指定生成Java代碼的包名
option java_outer_classname = “Sum”; //指定生成Java代碼的外部類名稱
option java_generic_services = true; //基于服務定義產生抽象服務代碼
option optimize_for = SPEED; //指定優化級別
// 定義請求包
message SumRequest {
required string family = 1; //列族
required string column = 2; //列名
}
// 定義回復包
message SumResponse {
required int64 sum = 1 [default = 0]; //求和結果
}
// 定義RPC服務
service SumService {
//獲取求和結果
rpc getSum(SumRequest)
returns (SumResponse);
}
3.4 編譯proto文件
// 將proto文件編譯生成java代碼
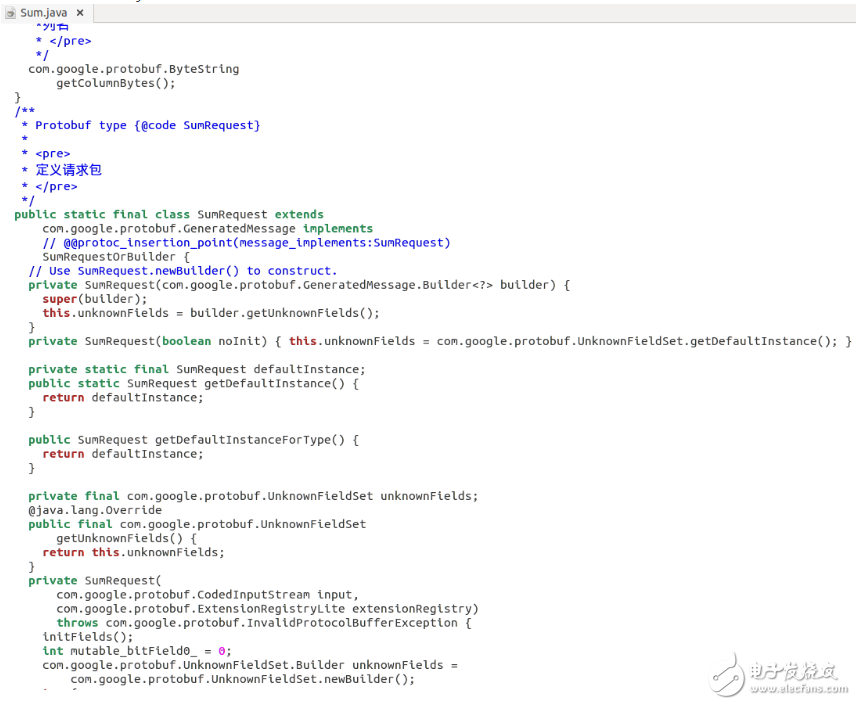
$ protoc endpoint.proto --java_out=。/
// 生成的文件Sum.java如下圖所示:
4 Endpoint編碼示例
業務邏輯如求和、排序等功能放在服務端,在服務端完成計算后將結果發送給客戶端,可以減少數據的傳輸量。下面的示例將在HBase的服務端生成一個RPC服務,即在服務端對指定表的指定列值進行求和計算,并將計算結果返回給客戶端。客戶端調用該RPC服務,獲取響應結果后輸出。
4.1 服務端代碼
首先,將通過Protocol Buffer生成的RPC接口文件Sum.java導入項目,然后在項目中新建類SumEndPoint編寫服務端代碼:
[java] view plain copypackage com.hbase.demo.endpoint;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.Coprocessor;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.coprocessor.CoprocessorException;
import org.apache.hadoop.hbase.coprocessor.CoprocessorService;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.protobuf.ResponseConverter;
import org.apache.hadoop.hbase.regionserver.InternalScanner;
import org.apache.hadoop.hbase.util.Bytes;
import com.google.protobuf.RpcCallback;
import com.google.protobuf.RpcController;
import com.google.protobuf.Service;
import com.hbase.demo.endpoint.Sum.SumRequest;
import com.hbase.demo.endpoint.Sum.SumResponse;
import com.hbase.demo.endpoint.Sum.SumService;
/**
* @author developer
* 說明:hbase協處理器endpooint的服務端代碼
* 功能:繼承通過protocol buffer生成的rpc接口,在服務端獲取指定列的數據后進行求和操作,最后將結果返回客戶端
*/
public class SumEndPoint extends SumService implements Coprocessor,CoprocessorService {
private RegionCoprocessorEnvironment env; // 定義環境
@Override
public Service getService() {
return this;
}
@Override
public void getSum(RpcController controller, SumRequest request, RpcCallback《SumResponse》 done) {
// 定義變量
SumResponse response = null;
InternalScanner scanner = null;
// 設置掃描對象
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(request.getFamily()));
scan.addColumn(Bytes.toBytes(request.getFamily()), Bytes.toBytes(request.getColumn()));
// 掃描每個region,取值后求和
try {
scanner = env.getRegion().getScanner(scan);
List《Cell》 results = new ArrayList《Cell》();
boolean hasMore = false;
Long sum = 0L;
do {
hasMore = scanner.next(results);
for (Cell cell : results) {
sum += Long.parseLong(new String(CellUtil.cloneValue(cell)));
}
results.clear();
} while (hasMore);
// 設置返回結果
response = SumResponse.newBuilder().setSum(sum).build();
} catch (IOException e) {
ResponseConverter.setControllerException(controller, e);
} finally {
if (scanner != null) {
try {
scanner.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 將rpc結果返回給客戶端
done.run(response);
}
// 協處理器初始化時調用的方法
@Override
public void start(CoprocessorEnvironment env) throws IOException {
if (env instanceof RegionCoprocessorEnvironment) {
this.env = (RegionCoprocessorEnvironment)env;
} else {
throw new CoprocessorException(“no load region”);
}
}
// 協處理器結束時調用的方法
@Override
public void stop(CoprocessorEnvironment env) throws IOException {
}
}
4.2 客戶端代碼
在項目中新建類SumClient作為調用RPC服務的客戶端測試程序,代碼如下:
[java] view plain copypackage com.hbase.demo.endpoint;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.coprocessor.Batch;
import org.apache.hadoop.hbase.ipc.BlockingRpcCallback;
import com.google.protobuf.ServiceException;
import com.hbase.demo.endpoint.Sum.SumRequest;
import com.hbase.demo.endpoint.Sum.SumResponse;
import com.hbase.demo.endpoint.Sum.SumService;
/**
* @author developer
* 說明:hbase協處理器endpooint的客戶端代碼
* 功能:從服務端獲取對hbase表指定列的數據的求和結果
*/
public class SumClient {
public static void main(String[] args) throws ServiceException, Throwable {
long sum = 0L;
// 配置HBse
Configuration conf = HBaseConfiguration.create();
conf.set(“hbase.zookeeper.quorum”, “localhost”);
conf.set(“hbase.zookeeper.property.clientPort”, “2222”);
// 建立一個數據庫的連接
Connection conn = ConnectionFactory.createConnection(conf);
// 獲取表
HTable table = (HTable) conn.getTable(TableName.valueOf(“sum_table”));
// 設置請求對象
final SumRequest request = SumRequest.newBuilder().setFamily(“info”).setColumn(“score”).build();
// 獲得返回值
Map《byte[], Long》 result = table.coprocessorService(SumService.class, null, null,
new Batch.Call《SumService, Long》() {
@Override
public Long call(SumService service) throws IOException {
BlockingRpcCallback《SumResponse》 rpcCallback = new BlockingRpcCallback《SumResponse》();
service.getSum(null, request, rpcCallback);
SumResponse response = (SumResponse) rpcCallback.get();
return response.hasSum() ? response.getSum() : 0L;
}
});
// 將返回值進行迭代相加
for (Long v : result.values()) {
sum += v;
}
// 結果輸出
System.out.println(“sum: ” + sum);
// 關閉資源
table.close();
conn.close();
}
}
4.3 加載Endpoint
// 將Sum類和SumEndPoint類打包后上傳到HDFS
$ hadoopfs -put endpoint_sum.jar /input
// 修改hbase配置文件,添加配置
$ vimapp/hbase-1.2.0-cdh5.7.1/conf/hbase-site.xml
[html] view plain copy《property》
《name》hbase.table.sanity.checks《/name》
《value》false《/value》
《/property》
// 重啟hbase
$stop-hbase.sh
$start-hbase.sh
// 啟動hbase shell
$hbase shell
// 創建表sum_table
》 create‘sum_table’,‘info’
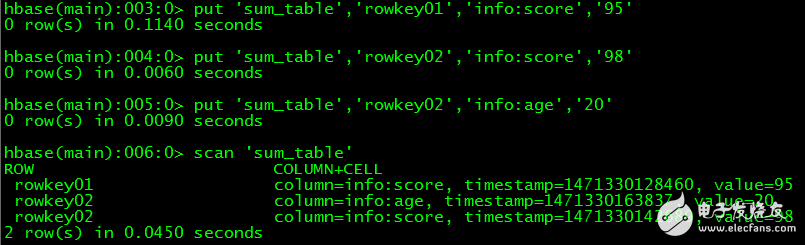
// 插入測試數據
》 put‘sum_table’,‘rowkey01’,‘info:score’,‘95’
》 put‘sum_table’,‘rowkey02’,‘info:score’,‘98’
》 put‘sum_table’,‘rowkey02’,‘info:age’,‘20’
// 查看數據
》 scan‘sum_table’
// 加載協處理器
》disable ‘sum_table’
》 alter‘sum_table’,METHOD =》‘table_att’,‘coprocessor’ =》‘hdfs://localhost:9000/input/endpoint_sum.jar|com.hbase.demo.endpoint.SumEndPoint|100’
》enable ‘sum_table’

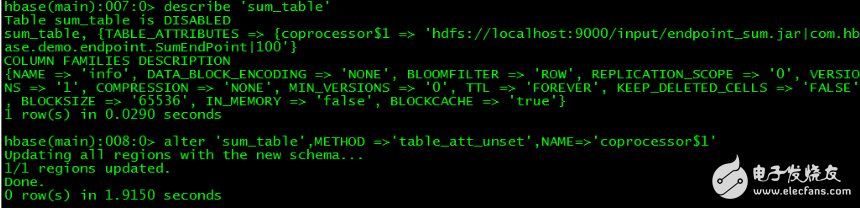
// 如果要卸載協處理器,可以先查看表中協處理器名,然后通過命令卸載
》disable ‘sum_table’
》 describe‘sum_table’
》 alter‘sum_table’,METHOD =》‘table_att_unset’,NAME=》‘coprocessor$1’
》 enable‘sum_table’
4.4 測試
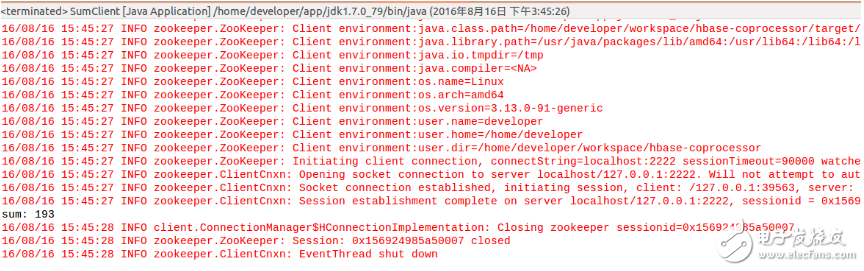
在eclipse中運行客戶端程序SumClient,輸出結果為193,正好符合預期,如下圖所示:
5 Observer編碼示例
一般來說,對數據庫建立索引,往往需要單獨的數據結構來存儲索引的數據。在hbase表中,除了使用rowkey索引數據外,還可以另外建立一張索引表,查詢時先查詢索引表,然后用查詢結果查詢數據表。下面這個示例演示如何使用Observer協處理器生成HBase表的二級索引:將數據表ob_table中列info:name的值作為索引表index_ob_table的rowkey,將數據表ob_table中列info:score的值作為索引表index_ob_table中列info:score的值建立二級索引,當用戶向數據表中插入數據時,索引表將自動插入二級索引,從而為查詢業務數據提供了便利。
5.1 代碼
在項目中新建類PutObserver作為Observer協處理器應用邏輯類,代碼如下:
[java] view plain copypackage com.hbase.demo.observer;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author developer
* 說明:hbase協處理器observer的應用邏輯代碼
* 功能:在應用了該observer的hbase表中,所有的put操作,都會將每行數據的info:name列值作為rowkey、info:score列值作為value
* 寫入另一張二級索引表index_ob_table,可以提高對于特定字段的查詢效率
*/
@SuppressWarnings(“deprecation”)
public class PutObserver extends BaseRegionObserver{
@Override
public void postPut(ObserverContext《RegionCoprocessorEnvironment》 e,
Put put, WALEdit edit, Durability durability) throws IOException {
// 獲取二級索引表
HTableInterface table = e.getEnvironment().getTable(TableName.valueOf(“index_ob_table”));
// 獲取值
List《Cell》 cellList1 = put.get(Bytes.toBytes(“info”), Bytes.toBytes(“name”));
List《Cell》 cellList2 = put.get(Bytes.toBytes(“info”), Bytes.toBytes(“score”));
// 將數據插入二級索引表
for (Cell cell1 : cellList1) {
// 列info:name的值作為二級索引表的rowkey
Put indexPut = new Put(CellUtil.cloneValue(cell1));
for (Cell cell2 : cellList2) {
// 列info:score的值作為二級索引表中列info:score的值
indexPut.add(Bytes.toBytes(“info”), Bytes.toBytes(“score”), CellUtil.cloneValue(cell2));
}
// 數據插入二級索引表
table.put(indexPut);
}
// 關閉資源
table.close();
}
}
5.2 加載Observer
// 將PutObserver類打包后上傳到HDFS
$ hadoopfs -put ovserver_put.jar /input
// 啟動hbase shell
$hbase shell
// 創建數據表ob_table
》 create‘ob_table’,‘info’
// 創建二級索引表ob_table
》 create‘index_ob_table’,‘info’
// 加載協處理器
》disable ‘ob_table’
》 alter‘ob_table’,METHOD =》‘table_att’,‘coprocessor’ =》‘hdfs://localhost:9000/input/observer_put.jar|com.hbase.demo.observer.PutObserver|100’
》 enable‘ob_table’
// 查看數據表ob_table
》 describe‘ob_table’

5.3 測試
// 在eclipse項目中編寫一個客戶端,向數據表ob_table中插入測試數據
[java] view plain copypackage com.hbase.demo.observer;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class Test {
public static void main(String[] args) throws IOException {
// 配置HBse
Configuration conf = HBaseConfiguration.create();
conf.set(“hbase.zookeeper.quorum”, “localhost”);
conf.set(“hbase.zookeeper.property.clientPort”, “2222”);
// 建立一個數據庫的連接
Connection conn = ConnectionFactory.createConnection(conf);
// 獲取表
HTable table = (HTable) conn.getTable(TableName.valueOf(“ob_table”));
// 插入測試數據
Put put = new Put(Bytes.toBytes(“rowkey01”));
put.addColumn(Bytes.toBytes(“info”), Bytes.toBytes(“name”), Bytes.toBytes(“carl”));
put.addColumn(Bytes.toBytes(“info”), Bytes.toBytes(“score”), Bytes.toBytes(“92”));
table.put(put);
// 關閉資源
table.close();
conn.close();
}
}
// 插入數據后,在hbase shell中查看數據表ob_table中的數據
$hbase shell
》 scan‘ob_table’

//在hbase shell中查看二級索引表index_ob_table中的數據
》 scan‘index_ob_table’












 工商網監
工商網監
評論