 電子發(fā)燒友App
電子發(fā)燒友App


1. 引言
多核數(shù)字信號(hào)處理器(DSP)是近年來(lái)針對(duì)高性能嵌入式應(yīng)用而出現(xiàn)的一類多核微處理器(CMP)。相比傳統(tǒng)的單核處理器,多核處理器在提高并行處理能力的同時(shí)也需要更高的存儲(chǔ)帶寬和更靈活的存儲(chǔ)結(jié)構(gòu)。便箋存儲(chǔ)器(SPM)是一種小容量的片上存儲(chǔ)器,具有全局地址空間,可以由訪存指令直接訪問(wèn)。SPM僅僅包含存儲(chǔ)陣列和譯碼邏輯,沒有Cache那樣復(fù)雜的Tag比較邏輯和替換策略,在電路面積和功耗方面比Cache更具優(yōu)勢(shì)。另外,SPM采用固定的存儲(chǔ)映射方式,沒有訪問(wèn)失效問(wèn)題,能夠保證單拍(或確定節(jié)拍)的訪問(wèn)時(shí)間,便于用戶顯式地管理和調(diào)度其中的數(shù)據(jù),適合嵌入式實(shí)時(shí)計(jì)算的特點(diǎn)。
根據(jù)多核DSP的應(yīng)用需求,并結(jié)合SPM的結(jié)構(gòu)特征和共享存儲(chǔ)的編程優(yōu)勢(shì),本文提出了一種面向多核DSP的快速共享數(shù)據(jù)緩沖池FSDP,對(duì)其進(jìn)行了設(shè)計(jì)實(shí)現(xiàn)和模擬分析。分析結(jié)果表明,F(xiàn)SDP對(duì)于DSP核間細(xì)粒度共享數(shù)據(jù)(例如某些全局變量、公共系數(shù)矩陣等)的傳輸具有很高的效率,相比類似的VS-SPM結(jié)構(gòu)能夠?qū)⒊绦蛐阅芴岣?7%,與傳統(tǒng)的共享數(shù)據(jù)Cache結(jié)合使用能夠?qū)悩?gòu)多核DSP的性能提高13%。
本文的組織結(jié)構(gòu)如下。第2部分介紹了國(guó)內(nèi)外的研究現(xiàn)狀,第3部分介紹了異構(gòu)多核DSP的總體結(jié)構(gòu)原型,第4部分詳細(xì)介紹了FSDP的組成結(jié)構(gòu)、訪問(wèn)方法和同步機(jī)制。第5部分介紹了設(shè)計(jì)優(yōu)化方法,構(gòu)建了關(guān)于最佳單體容量的分析模型。第6部分介紹了設(shè)計(jì)實(shí)現(xiàn)和模擬分析結(jié)果。最后一部分總結(jié)了全文。
2. 相關(guān)工作
近年來(lái),國(guó)外學(xué)者在SPM領(lǐng)域已經(jīng)展開了積極的研究。Banakar等人針對(duì)計(jì)算密集型應(yīng)用,使用專用工具(CACTI)計(jì)算出了各種容量的SPM和Cache的面積和功耗,使用Trace模擬器進(jìn)行了性能對(duì)比。結(jié)果表明,同樣容量的SPM的平均功耗比Cache降低了40%。Issenin等人也認(rèn)為,如果通過(guò)數(shù)據(jù)重用技術(shù),將經(jīng)常使用的數(shù)據(jù)放在小容量的SPM中,用片內(nèi)局部傳輸代替片外全局傳輸,不但可以節(jié)省約一半的功耗,而且大大提高了傳輸效率。Kandemir和Suhendra等人基于一種虛擬共享便箋式存儲(chǔ)器(VS-SPM)的多核處理器原型,如圖1所示。通過(guò)任務(wù)映射、調(diào)度、SPM劃分和數(shù)據(jù)分配等編譯優(yōu)化算法,提高片內(nèi)數(shù)據(jù)重用性,減少不必要的片外訪存,其宣稱的實(shí)驗(yàn)結(jié)果能夠把嵌入式應(yīng)用的性能提高80%。
這些已有的工作主要是從軟件的角度研究如何優(yōu)化SPM的存儲(chǔ)分配與管理,而且大部分是基于單核處理器的研究,對(duì)于多核處理器環(huán)境下SPM的體系結(jié)構(gòu)研究還不夠充分。特別在共享存儲(chǔ)的方式下,必須根據(jù)實(shí)際應(yīng)用中核間數(shù)據(jù)共享與傳輸?shù)奶攸c(diǎn),研究速度快、結(jié)構(gòu)靈活的SPM存儲(chǔ)結(jié)構(gòu)。本文提出的FSDP采用多體并行和交叉訪問(wèn)的方式,訪問(wèn)延遲小,存取速度快;提供了硬件信號(hào)燈和軟件查詢兩種同步機(jī)制,同步開銷低,編程使用靈活。
3. 異構(gòu)多核DSP總體結(jié)構(gòu)
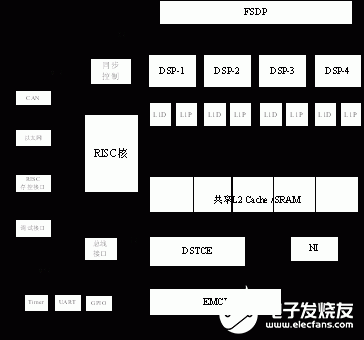
圖1 異構(gòu)多核DSP“SDSP”的總體結(jié)構(gòu)
異構(gòu)多核DSP“SDSP”的總體結(jié)構(gòu)如圖1所示,它由四個(gè)精簡(jiǎn)的32位浮點(diǎn)DSP核與一個(gè)32位的RISC核構(gòu)成。DSP核采用課題組自行研制的32位高性能浮點(diǎn)DSP“YHFT-DSP700”的精簡(jiǎn)內(nèi)核。該DSP內(nèi)核主頻300MHz,8流出超長(zhǎng)指令字(VLIW)結(jié)構(gòu)。四個(gè)DSP內(nèi)核共享存儲(chǔ)空間。每個(gè)DSP核具有私有的一級(jí)數(shù)據(jù)Cache(L1D)和一級(jí)指令Cache(L1P),共享二級(jí)Cache/SRAM(L2)和FSDP。FSDP與L1D處于同一個(gè)存儲(chǔ)層次,具有不可Cache的全局存儲(chǔ)空間,可以被四個(gè)DSP核的訪存指令直接訪問(wèn)。
RISC核采用開放體系結(jié)構(gòu)與源碼的LEON處理器。LEON是一款高度可配置的32位通用RISC處理器,兼容SPARC V8指令集,采用7級(jí)整數(shù)流水線,指令Cache和數(shù)據(jù)Cache分離。片上集成了AMBA 2.0總線,掛接存儲(chǔ)控制器、PCI模塊、CAN接口等外設(shè)模塊。
4. 快速共享數(shù)據(jù)緩沖池FSDP體系結(jié)構(gòu)
FSDP是一個(gè)四通道共享存儲(chǔ)結(jié)構(gòu),每個(gè)DSP核對(duì)應(yīng)一個(gè)通道,每個(gè)通道包括兩個(gè)大小相同的存儲(chǔ)體SAi和SBi(i=1,2,3,4)、存控邏輯和讀寫隊(duì)列。四個(gè)通道依次順序編址,通過(guò)高速交叉開關(guān)(Crossbar)構(gòu)成整個(gè)共享數(shù)據(jù)緩沖池,如圖2所示。另外,F(xiàn)SDP采用了一組控制寄存器,通過(guò)公共的配置總線與四個(gè)DSP核相連,用于同步/互斥、狀態(tài)查詢、優(yōu)先級(jí)控制等操作。
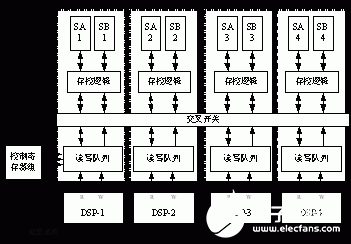
圖2 FSDP的組成結(jié)構(gòu)及其與DSP核的連接關(guān)系
FSDP采用多體并行交叉訪問(wèn)的機(jī)制,提供了“私有”和“共享”兩種工作模式,支持多個(gè)DSP核的并行訪問(wèn)與核間數(shù)據(jù)流的傳輸。FSDP基于釋放一致性共享存儲(chǔ)模型,為用戶提供了硬件自動(dòng)阻塞和軟件手工查詢兩種同步機(jī)制。多核DSP程序產(chǎn)生的中間結(jié)果、公共變量、系數(shù)常量、查找表等數(shù)據(jù)結(jié)構(gòu)都可以通過(guò)FSDP實(shí)現(xiàn)快速的細(xì)粒度數(shù)據(jù)傳輸與交換。而大批量的全局?jǐn)?shù)據(jù)和用戶程序則存放在片外存儲(chǔ)器中,通過(guò)兩級(jí)Cache進(jìn)行訪問(wèn)。下面,本文將詳細(xì)介紹FSDP的組成結(jié)構(gòu)和關(guān)鍵技術(shù)。
4.1 帶旁路的讀寫隊(duì)列與解耦的存控邏輯
為了緩存因訪問(wèn)沖突或同步失敗而被阻塞的讀/寫訪問(wèn),我們?yōu)槊總€(gè)DSP核分別設(shè)置了讀/寫隊(duì)列,直接緩存各個(gè)DSP核Load/Store單元發(fā)出的訪問(wèn)請(qǐng)求。為了縮短訪問(wèn)延遲,我們?yōu)樽x/寫隊(duì)列設(shè)置了旁路邏輯。當(dāng)沒有訪問(wèn)沖突且核間同步握手成功時(shí),讀寫請(qǐng)求不需進(jìn)入讀寫隊(duì)列,由旁路邏輯將請(qǐng)求直接發(fā)送給相應(yīng)的存控邏輯。這一設(shè)計(jì)縮短了訪問(wèn)延遲,有效增強(qiáng)了FSDP的傳輸效率。下圖3給出了帶旁路的讀寫隊(duì)列結(jié)構(gòu)。為了加快地址譯碼速度,本文將地址譯碼邏輯和訪問(wèn)控制邏輯進(jìn)行了解耦處理,將譯碼器置于旁路邏輯之前,縮短控制邏輯的關(guān)鍵路徑,提高了FSDP的訪問(wèn)速度。
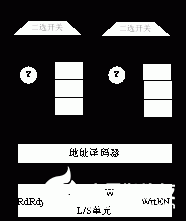
圖3 帶旁路的讀寫隊(duì)列
4.2 雙模式操作與交叉訪問(wèn)
本文為FSDP設(shè)計(jì)了“私有”和“共享”兩種工作模式。
在私有模式下,任意DSP核DSP-i只能讀寫與其對(duì)應(yīng)通道內(nèi)的兩個(gè)存儲(chǔ)體SAi和SBi(i=1,2,3,4),不能訪問(wèn)其他的通道;在共享模式下,每個(gè)DSP核可以讀取另外三個(gè)通道的數(shù)據(jù),但不能向其中寫入數(shù)據(jù)。任意DSP核必須通過(guò)其對(duì)應(yīng)通道的兩個(gè)存儲(chǔ)體與其他DSP核交換共享數(shù)據(jù)。
可見,在私有模式下,所有的存儲(chǔ)體都不存在訪問(wèn)競(jìng)爭(zhēng),訪問(wèn)速度快。在共享模式下,F(xiàn)SDP不存在多核寫沖突的問(wèn)題,簡(jiǎn)化了維護(hù)數(shù)據(jù)一致性的硬件開銷,提高了核間共享數(shù)據(jù)的傳輸速度,有利于提高嵌入式應(yīng)用的實(shí)時(shí)性。
在任務(wù)流水的計(jì)算模式下,DSP核間的共享數(shù)據(jù)相繼構(gòu)成“生產(chǎn)者-消費(fèi)者”關(guān)系:前一個(gè)核的計(jì)算輸出直接作為下一個(gè)核的計(jì)算輸入。為了有效支持這種傳輸模式,我們?cè)贔SDP中采用了交叉訪問(wèn)的機(jī)制:
當(dāng)“生產(chǎn)者”DSP-i向存儲(chǔ)體SAi寫入第一塊共享數(shù)據(jù)之后,釋放該存儲(chǔ)體,轉(zhuǎn)而向SBi寫入第二塊共享數(shù)據(jù);
“消費(fèi)者”DSP-j(j≠i)啟動(dòng)讀訪問(wèn),從SAi讀出第一塊共享數(shù)據(jù);
當(dāng)這一過(guò)程完成后,雙方交叉,DSP-i釋放存儲(chǔ)體SBi,向SAi寫入第三塊共享數(shù)據(jù),DSP-j則從SBi讀出第二塊共享數(shù)據(jù),依此類推,直至傳輸完成。
因此,在寫入第一塊共享數(shù)據(jù)之后,讀寫操作就可以并行執(zhí)行。當(dāng)雙方的計(jì)算負(fù)載均衡,速度匹配的時(shí)候,DSP核之間可以進(jìn)行流水傳輸,同步等待延遲最小,傳輸效率達(dá)到最高。
4.3 釋放一致性模型與基于信號(hào)燈的快速同步機(jī)制
在共享存儲(chǔ)的釋放一致性(RC)模型中,同步操作包括“獲取”和“釋放”兩種操作,分別用于取得對(duì)共享存儲(chǔ)單元的獨(dú)占性訪問(wèn)權(quán)和解除這一訪問(wèn)權(quán)。參照基本的RC模型,本文為FSDP設(shè)計(jì)了一套簡(jiǎn)潔、高效的控制邏輯和同步機(jī)制。
首先,為每個(gè)存儲(chǔ)體設(shè)置3個(gè)“信號(hào)燈”寄存器,分別對(duì)應(yīng)除本通道之外的其他3個(gè)DSP核,作為同步/互斥操作的硬件鎖。“信號(hào)燈”寄存器映射了全局共享的物理地址,通過(guò)公共配置總線與四個(gè)DSP核相連。每個(gè)“信號(hào)燈”具有“點(diǎn)亮”和“熄滅”兩種狀態(tài),分別表示存儲(chǔ)體內(nèi)的共享數(shù)據(jù)“已寫入”和“已讀出”。DSP核通過(guò)同步指令改寫“信號(hào)燈”寄存器的狀態(tài),實(shí)現(xiàn)核間的同步操作。具體的數(shù)據(jù)一致性協(xié)議為:
當(dāng)“生產(chǎn)者”DSP-i向某個(gè)存儲(chǔ)體寫入共享數(shù)據(jù)后,將其“信號(hào)燈”置為“點(diǎn)亮”狀態(tài)。若這批共享數(shù)據(jù)有2~3個(gè)“消費(fèi)者”,則點(diǎn)亮相應(yīng)的2~3個(gè)“信號(hào)燈”。在某個(gè)“信號(hào)燈”處于“熄滅”狀態(tài)時(shí),相應(yīng)的DSP核對(duì)該存儲(chǔ)體的讀請(qǐng)求全部進(jìn)入讀隊(duì)列等待。
當(dāng)“消費(fèi)者”DSP-j讀出某個(gè)存儲(chǔ)體的共享數(shù)據(jù)后,將該存儲(chǔ)體與自己對(duì)應(yīng)的“信號(hào)燈”置為“熄滅”狀態(tài)。當(dāng)某個(gè)存儲(chǔ)體的所有3個(gè)“信號(hào)燈”都“熄滅”時(shí),該存儲(chǔ)體被釋放,處于可寫狀態(tài);否則,DSP核對(duì)該存儲(chǔ)體的寫請(qǐng)求全部進(jìn)入寫隊(duì)列等待。
“點(diǎn)亮”和“熄滅”信號(hào)燈的順序一致性由DSP核對(duì)公共配置總線的獨(dú)占性訪問(wèn)來(lái)保證。
需要說(shuō)明的是,DSP核不一定要將其對(duì)應(yīng)的存儲(chǔ)體寫滿才能點(diǎn)亮“信號(hào)燈”,一次同步操作所傳輸?shù)臄?shù)據(jù)量最小可以是一個(gè)字節(jié),最大不超過(guò)單個(gè)存儲(chǔ)體的容量。
由于FSDP的訪存通路與同步操作通路(即配置總線)是相互分離的,因此可能出現(xiàn)同步操作指令通過(guò)配置總線先于訪存指令提前執(zhí)行的錯(cuò)誤情況。本文通過(guò)軟件延遲槽的方式解決這一問(wèn)題:由編譯器通過(guò)指令調(diào)度技術(shù),在最后一條共享數(shù)據(jù)的讀指令和“熄燈”指令之間插入1~2條無(wú)關(guān)指令或空操作(NOP),作為等待共享數(shù)據(jù)返回的延遲槽,確保最后一個(gè)讀請(qǐng)求被處理之后再執(zhí)行“熄燈”操作。具體所需的軟件延遲槽數(shù)量取決于DSP流水線的設(shè)計(jì)。對(duì)于本文而言,如果DSP核在發(fā)出Load指令的第3拍沒有接收到返回的數(shù)據(jù),則暫停指令派發(fā),因此只需要2個(gè)延遲槽。圖4給出了兩個(gè)DSP核i和j傳遞共享數(shù)據(jù)的實(shí)例。
(a)延遲槽與同步操作的程序?qū)嵗?/p>
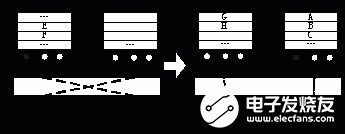
(b)存儲(chǔ)體的內(nèi)容變化與信號(hào)燈狀態(tài)
圖4 兩個(gè)DSP核通過(guò)兩個(gè)存儲(chǔ)體傳遞共享數(shù)據(jù)的例子
本文最終的優(yōu)化設(shè)計(jì)表明,任意兩個(gè)DSP核利用一對(duì)LOAD-STORE指令再加上一次同步操作,總共只需4拍即可完成一個(gè)共享數(shù)據(jù)字的傳遞,從而實(shí)現(xiàn)了核間細(xì)粒度共享數(shù)據(jù)的快速傳輸。當(dāng)需要傳輸?shù)墓蚕頂?shù)據(jù)量超過(guò)FSDP單通道存儲(chǔ)容量時(shí),可以將數(shù)據(jù)分塊,進(jìn)行多次傳輸。
除了這種對(duì)程序員透明的硬件同步機(jī)制之外,F(xiàn)SDP還支持基于軟件查詢的同步機(jī)制。即在每次改變信號(hào)燈狀態(tài)前,插入一段查詢“信號(hào)燈”狀態(tài)的例程,然后根據(jù)查詢的結(jié)果決定程序的流向。
4.4 消除讀訪問(wèn)沖突
在FSDP的共享模式下存在多DSP核同時(shí)讀一個(gè)存儲(chǔ)體的沖突。雖然利用仲裁邏輯配合隊(duì)列機(jī)制可以緩解沖突,但是,這種方式降低了FSDP的并行性。另外,可以采用存儲(chǔ)體復(fù)制或者采用多端口存儲(chǔ)體的方式。為此,本文進(jìn)行了對(duì)比實(shí)驗(yàn),結(jié)果表明,4個(gè)1KB大小的單端口SRAM在工作頻率和面積上都優(yōu)于4端口1KB的全定制SRAM模塊,而且單端口SRAM可以由EDA工具快速編譯生成,便于設(shè)計(jì)實(shí)現(xiàn)。因此,對(duì)于FSDP這類小容量的便箋存儲(chǔ)器,本文采用存儲(chǔ)體復(fù)制的方式解決訪問(wèn)沖突:將原來(lái)的每個(gè)存儲(chǔ)體換成4個(gè)同樣大小的單端口存儲(chǔ)體,構(gòu)成具有4個(gè)虛擬端口的存儲(chǔ)體,如圖5所示。
在處理讀寫訪問(wèn)時(shí),存控邏輯自動(dòng)進(jìn)行數(shù)據(jù)寫復(fù)制和讀端口的分配工作,讀寫過(guò)程中對(duì)用戶都是透明的。這種方式完全消除了多核的讀訪問(wèn)沖突,實(shí)現(xiàn)了最大的共享訪問(wèn)帶寬,提高了FSDP的并行性和實(shí)時(shí)性。
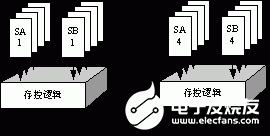
圖5 存儲(chǔ)體復(fù)制構(gòu)成虛擬多端口存儲(chǔ)體
5. 性能分析
5.1 分析模型與設(shè)計(jì)實(shí)現(xiàn)
本文構(gòu)建了整個(gè)SDSP的C語(yǔ)言模擬器SDSP-Sim。SDSP-Sim是一個(gè)時(shí)鐘精確的模擬器,能夠運(yùn)行經(jīng)過(guò)編譯和手工分配的多核DSP應(yīng)用程序,報(bào)告程序運(yùn)行的各種統(tǒng)計(jì)信息和計(jì)算結(jié)果。每個(gè)處理器核占用一個(gè)模擬進(jìn)程,RISC與DSP核之間采用進(jìn)程通信的方式傳輸控制信息。本文以MediaBench基準(zhǔn)程序集為基礎(chǔ),選擇了6組典型的多媒體類與通信類應(yīng)用程序,用于評(píng)測(cè)FSDP的性能,如表1所示。為了滿足多核DSP的并行計(jì)算需求,對(duì)于原來(lái)復(fù)雜度較低的一些測(cè)試程序,例如PEGWIT和JPEG_c,本文擴(kuò)大了它們的數(shù)據(jù)集。對(duì)于MP3解碼程序MP3_d則將其擴(kuò)展為兩路并行解碼器2MP3_d。由于SDSP的并行編譯器開發(fā)工作還沒有完成,本文仍采用手工的方式對(duì)測(cè)試程序進(jìn)行并行化映射。
表1 用于性能評(píng)測(cè)的測(cè)試程序說(shuō)明

本文采用SMIC 0.13μm CMOS工藝庫(kù)對(duì)FSDP進(jìn)行了設(shè)計(jì)實(shí)現(xiàn)。其中各存儲(chǔ)體采用EDA工具生成的單端口SRAM。下表2給出了FSDP的各項(xiàng)設(shè)計(jì)指標(biāo)。其中,“無(wú)阻塞讀延遲”是指在同步成功且沒有沖突的情況下,從DSP核發(fā)出讀請(qǐng)求到獲得返回?cái)?shù)據(jù)之間的時(shí)間間隔。
表2 0.13μm CMOS工藝下四通道FSDP的各項(xiàng)性能指標(biāo)

5.2 性能對(duì)比
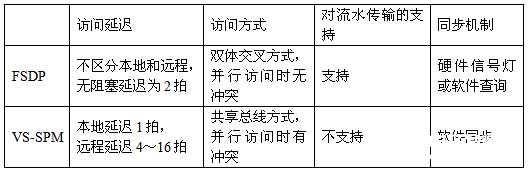
對(duì)于多核處理器共享SPM的研究,前人的工作主要是針對(duì)SPM的編譯優(yōu)化和數(shù)據(jù)劃分算法的研究。文獻(xiàn)0介紹的VS-SPM(虛擬共享便箋存儲(chǔ)器)原型結(jié)構(gòu)與本文的FSDP有類似之處,它根據(jù)SPM與處理器核的關(guān)系,將SPM分成本地SPM和遠(yuǎn)程SPM,各個(gè)處理器核通過(guò)共享總線訪問(wèn)各SPM模塊。下表3對(duì)比了本文的FSDP與VS-SPM在結(jié)構(gòu)上的差異。VS-SPM主要是針對(duì)編譯優(yōu)化和數(shù)據(jù)劃分算法優(yōu)化而設(shè)計(jì)的,其硬件優(yōu)化程度和訪問(wèn)速度都不及FSDP,而且沒有解決多個(gè)處理器核并行訪問(wèn)沖突的問(wèn)題,不支持核間數(shù)據(jù)的流水傳輸。
表3 FSDP與VS-SPM的結(jié)構(gòu)對(duì)比
本文建立了VS-SPM的結(jié)構(gòu)模型,將DSP核間同樣一批共享數(shù)據(jù)先后映射到VS-SPM和FSDP的存儲(chǔ)空間上,分別得到兩種結(jié)構(gòu)下程序的執(zhí)行時(shí)間TVS-SPM和TF-SDP,然后按照(1)式計(jì)算出FSDP相對(duì)VS-SPM的性能加速比。

圖6給出了6組測(cè)試程序的實(shí)驗(yàn)結(jié)果。結(jié)果表明,通過(guò)FSDP在DSP核之間傳輸共享數(shù)據(jù)相比通過(guò)VS-SPM傳輸具有明顯的性能優(yōu)勢(shì),6組程序的平均性能加速比達(dá)到了1.37。
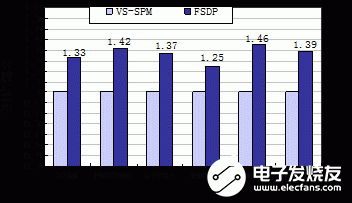
圖6 FSDP相對(duì)VS-SPM的性能加速比
在引入FSDP之前,異構(gòu)多核DSP主要通過(guò)共享L2 Cache傳輸DSP核間的共享數(shù)據(jù)。為了評(píng)測(cè)FSDP對(duì)系統(tǒng)性能的加速作用,本文比較了下列三種數(shù)據(jù)映射方式下異構(gòu)多核DSP的計(jì)算性能:
僅用L2 Cache:DSP核間的共享數(shù)據(jù)全部通過(guò)L2傳輸;
僅用FSDP:DSP核間的共享數(shù)據(jù)全部通過(guò)FSDP傳輸;
FSDP + L2:將DSP核間的不規(guī)則共享數(shù)據(jù)映射到FSDP的地址空間,其余的共享數(shù)據(jù)流仍通過(guò)L2傳輸。
利用SDSP-Sim軟件模擬器分別得到上述三種映射方式下程序的執(zhí)行時(shí)間,然后以第一種映射方式下的執(zhí)行時(shí)間為基準(zhǔn),計(jì)算出另外兩種方式的性能加速比,結(jié)果如圖7所示:
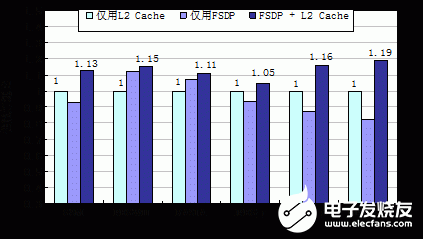
圖7 三種數(shù)據(jù)映射方式下系統(tǒng)的計(jì)算性能對(duì)比
實(shí)驗(yàn)結(jié)果表明,在FSDP + L2 Cache方式下,程序的性能是最高的。6組程序的平均性能加速比為1.13。本文分析認(rèn)為:
對(duì)于核間共享數(shù)據(jù)包含大量細(xì)粒度數(shù)據(jù)和不規(guī)則數(shù)據(jù)流的應(yīng)用程序(例如PEGWIT和RASTA),僅用FSDP相比僅通過(guò)L2 Cache傳輸共享數(shù)據(jù)具有更高的計(jì)算性能;
對(duì)于核間共享數(shù)據(jù)量較大和數(shù)據(jù)流分布比較密集的應(yīng)用程序(例如2MP3_d和MPEG2_e),僅用FSDP傳輸共享數(shù)據(jù)的計(jì)算性能較低,這是因?yàn)镕SDP對(duì)共享數(shù)據(jù)的分塊處理使得同步開銷在執(zhí)行時(shí)間中的比例增大,影響了總執(zhí)行時(shí)間;
FSDP與共享數(shù)據(jù)Cache結(jié)合使用進(jìn)一步提高了共享存儲(chǔ)多核DSP的片內(nèi)數(shù)據(jù)重用性,減少了對(duì)片外數(shù)據(jù)的長(zhǎng)延遲訪問(wèn),因而能夠獲得最佳的計(jì)算性能。其中,對(duì)于需要緊耦合共享的小容量數(shù)據(jù)或者非常不規(guī)則的短數(shù)據(jù)流,優(yōu)先選擇通過(guò)FSDP傳輸,減少通過(guò)共享Cache的長(zhǎng)延遲訪問(wèn)開銷;反之,對(duì)于大塊數(shù)據(jù)的共享或者規(guī)則數(shù)據(jù)流的傳輸,則宜采用共享Cache的方式,降低數(shù)據(jù)頻繁分塊的同步開銷。
5.3 擴(kuò)展性分析
在消除了FSDP的訪問(wèn)沖突之后,所有DSP核可以同時(shí)訪問(wèn)不同的存儲(chǔ)體。理論上來(lái)看,F(xiàn)SDP的訪問(wèn)帶寬可以隨著DSP核數(shù)量的增長(zhǎng)而線性增長(zhǎng),具有良好的可擴(kuò)展性。為此,我們進(jìn)行了分析與實(shí)驗(yàn)。定義B為FSDP的有效訪問(wèn)帶寬,即在考慮訪存延遲和工作頻率的情況下所有DSP核訪問(wèn)FSDP的實(shí)際存儲(chǔ)帶寬;N表示DSP核的數(shù)量。本文在N=1~8的情況下分別對(duì)FSDP進(jìn)行了單獨(dú)的設(shè)計(jì)實(shí)現(xiàn),得到了B與N的關(guān)系,如圖8所示。
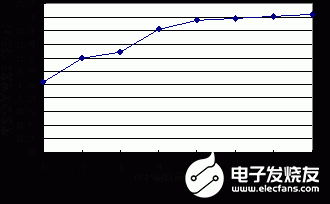
圖8 FSDP有效訪問(wèn)帶寬與DSP核數(shù)量的關(guān)系
由實(shí)驗(yàn)結(jié)果可見,當(dāng)N小于5時(shí), B快速增長(zhǎng),與N呈近似的線性關(guān)系。隨著N的進(jìn)一步增大,DSP核與存儲(chǔ)體之間的控制邏輯開銷、互連總線和交叉開關(guān)端口數(shù)量以O(shè)(N2)量級(jí)增長(zhǎng),F(xiàn)SDP的工作頻率開始下降,訪問(wèn)延遲越來(lái)越大,F(xiàn)SDP的有效訪問(wèn)帶寬增長(zhǎng)十分緩慢。因此,F(xiàn)SDP更適合于5核以內(nèi)的多核DSP。當(dāng)DSP核數(shù)量超過(guò)8核以上時(shí),我們將以4核為一個(gè)超節(jié)點(diǎn)進(jìn)行結(jié)構(gòu)擴(kuò)展。超節(jié)點(diǎn)內(nèi)部采用FSDP實(shí)現(xiàn)緊耦合的數(shù)據(jù)傳輸,超節(jié)點(diǎn)之間通過(guò)片上網(wǎng)絡(luò)(NoC)或者其他共享存儲(chǔ)結(jié)構(gòu)進(jìn)行數(shù)據(jù)傳輸。
7 結(jié)束語(yǔ)
相比傳統(tǒng)的Cache結(jié)構(gòu),便箋式存儲(chǔ)器具有更靈活的結(jié)構(gòu)、簡(jiǎn)潔的控制邏輯、更低的訪問(wèn)延遲和方便的數(shù)據(jù)管理等諸多優(yōu)勢(shì)。本文針對(duì)多核DSP架構(gòu)設(shè)計(jì)的快速共享數(shù)據(jù)緩沖池FSDP結(jié)合了便箋式存儲(chǔ)器的結(jié)構(gòu)特點(diǎn)和共享存儲(chǔ)結(jié)構(gòu)的編程需要,采用軟/硬件聯(lián)合的設(shè)計(jì)方法,為多核DSP之間傳輸細(xì)粒度共享數(shù)據(jù)提供了一個(gè)緊耦合的快速通路,相比共享二級(jí)Cache和DMA傳輸方式具有更好的傳輸效率,是一種新型而實(shí)用的、可擴(kuò)展多核共享存儲(chǔ)結(jié)構(gòu)。今后,我們將深入研究面向多核處理器的高性能共享存儲(chǔ)結(jié)構(gòu),增強(qiáng)片上存儲(chǔ)的可擴(kuò)展性和可重構(gòu)能力,進(jìn)一步提高多核SoC的存儲(chǔ)帶寬。
責(zé)任編輯:gt











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論