 電子發(fā)燒友App
電子發(fā)燒友App


在這篇文章中,我們將探索MIPS軍工級I級I6500 CPU處理器的異構(gòu)設(shè)計(jì)如何大幅提升性能及降低功耗。
高性能處理器通常使用深度多指令執(zhí)行、分支預(yù)測及無序處理等技術(shù)以使性能最大化,但這卻可能會影響功效。
如果其中一些任務(wù)是并行的,隨之便會在一系列CPU中進(jìn)行分區(qū),這樣便可以提供高性能高效的方案。為此,CPU供應(yīng)商提供了多核集群,操作系統(tǒng)和應(yīng)用程序開發(fā)人員則設(shè)計(jì)了相關(guān)軟件以開發(fā)這些功能。
采用多線程
即使采用無序執(zhí)行,通常的工作負(fù)載使得CPU將大多數(shù)時間花在等待內(nèi)存系統(tǒng)的訪問上。新引入的MIPS I6500支持多線程,即每個線程作為單獨(dú)的處理器出現(xiàn)在軟件中。根據(jù)不同的應(yīng)用程序,添加第二個線程至CPU中時,通常10%的面積需要總體性能提升40%。MIPS I6500可以容納6個CPU,每個都有4個線程,這樣就不必在單個集群中運(yùn)行24個線程。
MIPS I6500集群添加了對系統(tǒng)層硬件相干性的支持,并使用AMBA ACE添加接口至系統(tǒng)中。AMBA ACE是一個一致性總線接口,可以兼容最常用的相干NoC產(chǎn)品,如 NetSpeed公司的Gemini及Arteris公司的Ncore。有了NetSpeed Gemini 產(chǎn)品,64 MIPS I6500集群將可以連接高達(dá)384個處理器,運(yùn)行1536個線程,這著實(shí)令人驚嘆。
對于許多消費(fèi)產(chǎn)品,其所需的處理性能隨著時間的推移可能會有很大的差別。通常,它們只是偶爾需要峰值性能。大多數(shù)的時間卻只需要較低的性能,而這通過使用一個更簡單更高效的處理器大幅降低總功耗便可以實(shí)現(xiàn)。
信息共享
將任務(wù)從一個處理器移至另一個處理器需要每個處理器可以共享相同的指令集及系統(tǒng)內(nèi)存信息。這通過共享虛擬內(nèi)存(支持向量機(jī))便可以實(shí)現(xiàn)。程序中的任何指針必須繼續(xù)指向相同的代碼或數(shù)據(jù),且初始處理器中任何不良緩沖必須讓隨后的處理器可見。

圖一:內(nèi)存在集群中傳輸時的移動軌跡

圖二:集群內(nèi)傳輸時內(nèi)存移動軌跡更短速度更快
維持處理器之間的緩存一致性
緩存一致性可以通過軟件管理。這要求最初的處理器(CPU A)在傳輸任務(wù)至后續(xù)處理器(CPU B)之前沖刷主存儲器的緩存。CPU B從主存儲器中獲取數(shù)據(jù)和指令。這個過程可能生成許多內(nèi)存訪問,因此將耗費(fèi)時間和功率。訪問主存儲器所需的功率比獲取緩存時的功率高一個數(shù)量級,所以這種影響還將被放大。為了解決這一問題,I6500 CPU集群支持硬件緩存一致性,以將功耗和性能成本降至最低。
在使用I6500集群的系統(tǒng)中,當(dāng)一個任務(wù)從CPUA傳輸至CPU B中時,CPU B將訪問駐留在CPU A中的本地緩存線路。硬件緩存一致性將跟蹤這些緩存線路的位置,并在必要時窺探緩存情況,以確保訪問數(shù)據(jù)的正確性。
I6500集群的另一個優(yōu)勢是可以在集群中被發(fā)現(xiàn)。在典型的異構(gòu)系統(tǒng)中,高性能處理器駐留在一個集群中,面積更小更高效的處理器駐留在另一個集群中。在這些不同類型處理器之間進(jìn)行任務(wù)傳輸時,新處理器第1層和第2層的緩存都是非激活的。要激活這些緩存需要一定的時間,并需要先前的緩存層在過渡階段仍然保持活躍。
MIPS I6500是不同的。我們稱這種差異性為“異構(gòu)內(nèi)置”,這意味著I6500支持異構(gòu)混合類型的處理器,允許高性能和功率優(yōu)化處理器處在同一集群中。將任務(wù)從一種類型的處理器傳輸至另一類處理器中將更有效,因?yàn)橹挥械?層緩存是未激活的,窺探上一層緩存的成本降低,因而過渡時間變得更短。
CPU配置專用加速器
CPU是通用的設(shè)備。其靈活性使其可以處理任何任務(wù),且任務(wù)處理具有成本效率。而PowerVR GPU能夠高性能高效率地處理更大且高度并行的計(jì)算任務(wù),其代價是靈活性相比CPU則較為降低,但其同時支持良好的軟件開發(fā)生態(tài)系統(tǒng)環(huán)境如OpenCL。
專用硬件加速器的專業(yè)化又有效地融合了多種性能,其性能效率相比CPU又高出了幾個數(shù)量級,不過相應(yīng)地靈活性則大為降低。
不過,多次使用加速器操作可以將潛在的性能和功效最大化。專業(yè)計(jì)算元素如音頻和視頻處理以及機(jī)器學(xué)習(xí)中使用的神經(jīng)網(wǎng)絡(luò)處理器使用了相似的數(shù)學(xué)運(yùn)算。此類操作使用最為廣泛的是向量點(diǎn)積(每向量中對應(yīng)元素產(chǎn)品的總和)。配置在CPU上的專用加速器使用此函數(shù)則可以顯著地提高性能并節(jié)省功率,同時又保留了CPU的靈活性。
通過增加單指令多數(shù)據(jù)(SIMD)功能與浮點(diǎn)算術(shù)邏輯單元(ALU)可以將硬件加速耦合至CPU中。不過,盡管通過SIMD處理數(shù)據(jù),CPU仍然作為直接內(nèi)存訪問(DMA)控制器移動數(shù)據(jù),且CPU是非常低效的直接記憶器存取(DMA)控制器。
相反,異構(gòu)系統(tǒng)本質(zhì)上卻可以二者兼得。它包含了一些專用的硬件加速器,可以與大量的CPU耦合,提供更大的功效,同時又大量保留了CPU的靈活性。
功率的節(jié)省及性能的提升取決于加速器進(jìn)行有用工作的時間。適合加速器的工作包范圍較廣——你可以預(yù)期少量的大型任務(wù),又可以預(yù)期大量的小型任務(wù)。

圖3:最小函數(shù)來證明轉(zhuǎn)換成本的降低
在CPU與加速器之間進(jìn)行傳輸處理將產(chǎn)生成本,限制任務(wù)的大小將節(jié)省功耗或提高性能。對于較小的任務(wù),節(jié)省的功耗及傳輸任務(wù)所需的時間將超過使用加速器所需的功耗及節(jié)省的時間。
降低數(shù)據(jù)傳輸成本
I6500具有共享硬件虛擬內(nèi)存功能,可以保持緩存一致性。這就大大節(jié)省了傳輸任務(wù)所需的成本,因?yàn)槠湎藬?shù)據(jù)復(fù)制和緩存沖刷的工作。
為進(jìn)一步減少時間及功率成本,還需要借助一些其他的技術(shù)。HSA Foundation開發(fā)了一個支持系統(tǒng)中異構(gòu)處理元素集成的環(huán)境,其擴(kuò)展超越了CPU和GPU。HSA系統(tǒng)有一個名為HSAIL的中間語言,該語言提供了一種常見的編譯路徑至異構(gòu)指令集架構(gòu)(ISA)中,極大地簡化了系統(tǒng)軟件開發(fā),并同時定義了用戶模式隊(duì)列。
這些隊(duì)列使任務(wù)有序進(jìn)行,且信號在其它處理元素中觸發(fā)任務(wù),使得序列任務(wù)的執(zhí)行成本較低。
相干單元
除了集群中的CPU ,MIPS I6500還支持許多IO相干單元(IOCU)。這些IOCU具有內(nèi)存管理單元(MMU)功能,當(dāng)處理CPU的任務(wù)時,其可以將任務(wù)處理映射至物理地址空間,并以同樣的方式經(jīng)過共享的第二層緩存,保持與所有本地緩存的一致性。對于許多系統(tǒng)而言,這種功能使加速器可以與CPU進(jìn)行有效的集成。
對于加速器中較大的任務(wù),直接內(nèi)存訪問(DMA)引擎的帶寬可以非常大,甚至可能被存儲系統(tǒng)的容量限制住。這樣一來,加速器中內(nèi)存系統(tǒng)的處理任務(wù)將進(jìn)行列隊(duì),且將列隊(duì)延遲添加至CPU共享了相同端口及路徑的任務(wù)中。處理大型數(shù)據(jù)集的加速器對任務(wù)處理有些依賴,允許加速器預(yù)取數(shù)據(jù)。這樣,即使是CPU中不共享的內(nèi)存延遲也可以高度容忍。

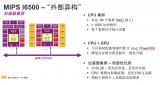
圖4:使用了I6500、PowerVR GPU和加速器的異構(gòu)系統(tǒng)圖
MIPS I6500及其相干的總線接口允許加速器使用獨(dú)立的系統(tǒng)內(nèi)存路徑并同時保留CPU集群的一致性。我們稱之為“異構(gòu)外置”。
異構(gòu)的優(yōu)勢
異構(gòu)系統(tǒng)可以大幅提升系統(tǒng)性能、降低系統(tǒng)功耗,使系統(tǒng)不因工藝精簡而受到限制。多線程、異構(gòu)和一致性CPU集群如MIPS I6500則是這些系統(tǒng)最完美的搭檔。
它們在許多市場的下一代產(chǎn)品中都占據(jù)優(yōu)勢,如:高級駕駛員輔助系統(tǒng)(ADAS)及自動駕駛、網(wǎng)絡(luò)、無人機(jī)、工業(yè)自動化、安全、視頻分析、機(jī)器學(xué)習(xí)等。
Follow @ImaginationTech
英文鏈接:
https://imgtec.com/blog/heterogeneous-inside-revolutionary-mips-i6500-pr...








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論