 電子發燒友App
電子發燒友App


本文是該系列的最后一篇文章。該系列文章在我的網頁上已載有數月,由于Vulkan產品的發布占用了我很多時間,最后收官之作的發表可能有些晚,希望大家還能關注它。本文中,我將闡述為何Vulkan比上一代API更適合硬件,同時,我還將深入PowerVR GPU的一些細節,并援引具體案例。
OpenGL ES
首先,讓我們看看當下行業領先的API及其問題存在的原因。距OpenGL ES的發行已有12年多,而API是基于OpenGL ES的產品。OpenGL早在23年前便已設計問世,其最初設計的硬件與當下使用的各式硬件大為不同。
狀態機
OpenGL是一款大型的全球狀態機,每次操作均需要考慮當前狀態的各個部分,如混合模式、當前的著色器、深度測試信息等。所有的事情看似一個簡單的制動開關或杠桿,可以不計實際的后果隨意改變開關狀態——它只是一個函數調用?對于現代硬件而言這是不切實際的——例如很多狀態會被轉化為著色代碼。
在移動產品的高效性一文中,我已經提到,考慮到掛接及渲染期間CPU的使用率,著色器修復是不確定的。還有另一個我之前未提及的問題——著色器本身的低效率。如果必須修復著色器狀態,則會出現優化后編譯,即附加至剩余的著色器中是有效的。如果在編譯時狀態已知,則可以一直優化編譯,以避免出現幾條指令。為解決此問題,驅動器可能會進行背景的重新編譯,但這本身也是一個問題(消耗更多的CPU時間)。
隱含同步
OpenGL ES假設很多東西是相互隱含同步的。只有引入柵欄時,計算著色器及其不良反應才被認為是任何形式的異步工作。大部分API僅僅只是工作——事實上這可以歸結為資源跟蹤、緩存刷新和場景后的依賴關系鏈建設。
驅動器不可能非常準確地檢測依賴項——它們十分保守,以能實現OpenGL ES功能。這意味著將不可避免地進行一些不必要的緩存刷新或不必要的序列化工作——換言之,硬件需要做更多的工作。
立即模式
自始至終,OpenGL ES中指定的命令應該嚴格按照規定的先后順序來執行。一個簡單的命令如繪制調用通常被當作一個單一的整體工作單元,其在GPU中有規定的隊列順序。這種行為即立即執行模式——每個指定的工作以某種方式被即刻發送至GPU進行處理。
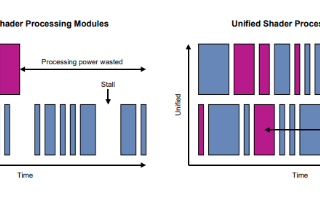
在過去,立即渲染模式(IMR)架構可以很好地映射到這種思維方式中,但現代IMR傾向于批量處理工作以提高性能。
基于區塊貼圖的渲染 (TBR)或基于區塊貼圖的延遲渲染 (TBDR)從未以這種方式工作。迄今為止存在的最多產的類型是GPU架構類型:這些架構類型的主要工作單元非常大——渲染通道便是很好的詮釋——所有的繪制調用都集中在相同的幀緩沖區中。
TBR和TBDR都有兩級渲染,早期階段主要處理幾何圖形及在屏幕空間貼圖中進行分類排序。第二階段則將貼圖柵格化,使整個貼圖完全保存在片上幀緩沖區中——這可節省大量的帶寬,其在移動市場占據優勢。Rys Sommefeldt做了更詳細的闡述,感興趣的可以查閱他的文章。
關鍵在于,在光柵化階段,繪制調用是無意義的——一個單一的繪制調用可能產生多個貼圖的光柵化,每個貼圖包含了多個繪制調用的工作。如果某些信息引起繪圖之間的沖刷,則整個渲染就會分裂,這就需要對很多貼圖進行再次渲染。在貼圖開始和結束時,必須加載幀緩沖區數據到貼圖中,并隨后進行存儲——這樣重復多次后便失去了基于區塊貼圖架構的優勢,而架構本身是極力避免消耗此類帶寬的。
總之,現代硬件傾向于批量處理工作,且提交單個繪制調用會降低效率。在OpenGL ES中有很多操作迫使驅動器提交單個繪制調用,這一點大家有目共睹。在TBR或TBDR中,這會產生很多不必要的且驅動器無力應對的帶寬。
Vulkan
我可能呈現給大家的OpenGL ES是比較沉悶的形象,但不要灰心,不然當今的移動世界便不會有如此多精彩的圖像內容。
Vulkan甚至比一個高度優化的OpenGL ES驅動器做的更好。我以前提過,Vulkan是顯式的,且需要在應用程序中獲取大量的信息——所有這些都是確保Vulkan可以流暢地工作,且不會產生很多用戶不可見的成本。
管線
Vulkan假定所有的狀態都將被再次啟用,因此其比OpenGL ES看起來更為靜態。管線多采用先前的動態狀態,并與著色器一起被編譯。這意味著任何先前需要著色器修復的信息現在可以提前被編譯。在編譯時擁有這些信息意味著可以對繪制調用即刻使用的著色器和狀態進行完整的編譯和優化,且不需要在渲染循環中將這些信息進行打包處理。
很多許多情況下,一個應用程序可能僅使用一個著色器及一組或兩組狀態——保持低成本。然而某些情況下,需要設置很多不同的狀態,因此會產生大量的管線對象。Vulkan沒有降低管線對象數量,同時,通過使用管線緩存編譯整個著色器組所花費的時間應該具有可比性(或更快)。創建一組管線時,管線緩存是可以與創建信息一起被傳輸的對象,且緩存的是有用信息或管線所需的編譯狀態和著色器。如果兩個管線具有相同的著色器,但狀態略有不同,那么創建和編譯的成本將遠低于單獨編譯的成本。
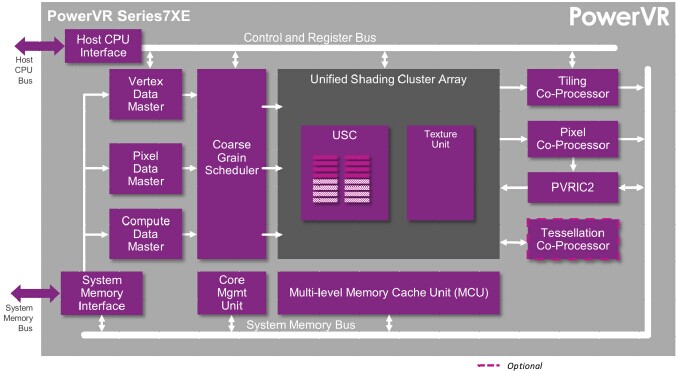
PowerVR GPU的管線
以混合狀態為例——眾所周知,我們沒有用于混合的固定功能硬件。通常不太需要此類硬件——片上存儲非常快,直接在著色器內核中混合會更加簡單。隨后,在OpenGL ES中設置混合模式會產生一組指令,其表示在當前著色結束時進行混合修復。
正如我之前所說,著色器修復可能引起效率降低。而著色器分析顯示,混合修復則情況不會太糟,其通常只有一個或兩個指令。這看似不切實際,不然今天我們就得重新審視我們的方案,但其確實合乎情理。Vulkan在創建管線時就給了全方位的信息,使我們在編譯之前就可以折疊這些指令,精簡著色器的處理工作。其他狀態如幀緩沖區格式和頂點布局可分為相似的類型(更瑣碎和不常見的狀態)。
顯示同步
相比其他圖形API,該API的各操作之間有更多的同步控制。主要用“what”、“when”、“where”和“how”信息來描述內存和執行依賴關系。
?依賴關系中涉及的對象和操作是什么?
?依賴關系何時開始何時結束?
?依賴關系在管線的哪個位置生成(如頂點著色)以及其必須在哪個位置實現(如片段著色)?
?相互依賴的雙方如何使用圖像?
所有這些信息可以使驅動器建立一個全面的依賴關系鏈,且如果應用程序可準確表示依賴關系,那么便可以僅僅等待需要絕對刷新的緩存和絕對完成的操作。
PowerVR GPU的顯示同步
在基于區塊貼圖的架構中,工作分為了兩個部分——幾何貼圖階段和光柵化階段。在OpenGL ES中,只有任務相當繁重的手控同步——柵格、隱式同步和內存屏障。光柵化階段無需等待,或者說只有在貼圖階段才需要等待——驅動器通過啟發式算法來實現等待或者完整的同步事件才需要等待——這將嚴重影響性能。通常,我們在OpenGL ES中使用大量的啟發式算法來完成這項工作,但付出的代價是這樣往往過于保守,導致性能大為降低。
在Vulkan中,可以使用為每個同步事件描述的管線級數來決定執行哪個硬件階段。如果在事件早期片段階段需要等待,則可以執行貼圖階段來提前獲取繪制調用,以求得先機,并在處理過程中提升性能。同樣,如果貼圖階段的任務需要等待,則表明在光柵化之前便已經開始執行任務。這兩種情況都會導致任務之間的延遲時間縮短,并通過允許多個任務的重疊減少在GPU上不必要的空閑時間。
命令緩沖區和硬件隊列
Vulkan使用延期命令提交模型——將繪制調用記錄成許多命令緩沖區,隨后應用程序將這些緩沖區作為獨立的操作提交至硬件中。這樣便可以提前了解場景大部分的信息,并適合地優化提交內容,而這些曾經在OpenGL中是很難實現的。
單獨的硬件隊列可以很好地映射到現代GPU中——其通常有一個或多個前端輸入隊列用來處理命令輸入。準確地曝光這些隊列可以給應用程序展示一個底層硬件視圖,而這個視圖本是不存在的。例如,如果GPU有一個用于圖形命令的前端——應該在API中僅曝光一個圖形隊列。隊列提交是外部同步的,所以驅動器在處理多個線程時不需要持有鎖,且由于有一個緊密的映射到硬件中,隊列提交是一個相對低成本的操作。
PowerVR GPU的命令緩沖區和硬件隊列
PowerVR以不同的順序運行,這可能原本是對即時光柵化程序的預期,正如上所述。為獲得所需的硬件效率,以一個特定的方式排列操作至關重要(而不是即刻提交頂點和光柵任務)。在Vulkan中,應用程序提前在命令緩沖區記錄中明確布局了所有的依賴關系。記錄命令緩沖區時,可確定最有效的操作序列并恰當地提交工作任務——OpenGL中的工作任務必須動態完成。正如之前所述,繪制調用的命令緩沖區可以用于貼圖任務和光柵化任務,并被硬件直接消耗。
提交這些命令緩沖區至隊列時,功能的實現則非常簡單,就如同將那些生成的任務放入應用程序提供了信號量的硬件中一樣。硬件前端映射至API隊列的比例并非1:1的,因為Vulkan圖像隊列由兩個硬件前端(貼圖和光柵化)表示。而這兩個前端的差別則由API的其他部分表示,如渲染通道對象和詳細的同步模型。
渲染通道
渲染通道將一組命令集分成片段。由于渲染通道在基于區塊貼圖的架構中是有效的工作單元,這些片段的命令緩沖區非常相似。渲染通道不允許出現可能會導致貼圖中期幀沖刷的命令。其僅允許繪制調用和其他選擇命令,因為貼圖需要渲染通道提供的信息來有效運行。
渲染通道由多個子通道組成,每一個通道都能通過本地數據給定像素位置來與后續的子通道交流信息。每個子通道可以定義其附件的加載和存儲操作、與其他子通道的執行依賴關系以及從先前或已保存的通道中讀取的附件清單。
通過使用子通道信息傳輸,應用程序可以采用簡單的后處理技術如色度分級或光暈。更有趣的是,如果應用程序使用延遲渲染技術,這可能 (強烈推薦!)是來表述G緩沖區的子通道依賴關系和輸入附件。
在許多情況下,如果附件僅作為中間體使用(Vulkan中存在的比較延遲的分配內存類型)或用作瞬態附件使用,則不需要分配附件。渲染通道中任何需使用的附件(在渲染結束時沒有從外源加載或存儲)可以被標記為瞬態,這使得延遲的內存對象分配方案可以綁定至附件中。延遲分配的內存對象在初次創建時可能不會立刻有任何實際的物理內存支持——它們可能完全是空的,也可能是部分分配或完全分配的——這取決于架構。在大多數情況下,它們應該為對象生命周期保持初始狀態,但如果出于某種原因需要分配更多內存,則可以進行后期綁定操作。需要預先了解內存對象的最大尺寸,并查詢這些內存對象當前允諾的內存。
PowerVR GPU的渲染通道
正如上所述,渲染通道禁止任何會導致中期幀沖刷的平鋪架構。于我們而言的確如此,且通過渲染通道顯式地描述每個渲染和加載/存儲操作的開端和結束,PowerVR GPU就能以最小的帶寬進行操作——僅在渲染完成后才編寫附件。
子通道依賴關系也絕對不允許存在架構在光柵化階段發生沖刷的情況——這意味著可能要結合多個子通道和依賴關系至一個單一的渲染通道中。其結果便是不存在渲染的停止和啟動,且沒有顯式存儲的中間附件不需要寫入內存——它們可以存入貼圖內存中。輸入附件至子通道中,當從先前的子通道中進行編寫時,可準確地映射到硬件的片上貼圖內存中。這一點你若很熟悉,可能我們在附件問題上使用了相同的EXT_shader_pixel_local_storage或EXT_shader_framebuffer_fetch。
架構中延遲分配的內存開始是未分配的,因為我們事先了解通常沒有理由分配任何內存——其僅作為一個API構造,在渲染期間僅作為一個片上內存的寄存器格式化塊進行映射。偶爾,在幀緩沖區創建時可能分配少量的內存,或在非常罕見的情況下,可能需要分配整個內存對象。
Conclusion 總結
相比OpenGL ES,Vulkan映射對于硬件而言更具優勢。雖然很多人關注Vulkan改善CPU性能和效率,但很多GPU性能和效率也可以進行改善——只不過它們更精細。
談論移動市場的游戲機品質圖像有點陳詞濫調,但它卻無時無刻不出現在我們的生活中!隨著移動GPU不斷改善且更有效率,Vulkan也成為邁向游戲機品質圖像之路的堅實一步。
這是本系列的最后一篇文章(有點晚但是完成了!),希望該系列文章可以發揮其價值。請關注我們Twitter (@ImaginationPR @PowerVRInsider)上來自PowerVR團隊的最新新聞和公告。您還可以查閱Vulkan的相關博客和在線研討會獲取資訊。
Vulkan現已發布,其詳細信息也即將與大家見面。游戲開發者大會即將召開,敬請期待。尤其不要錯過開發者的一天,屆時我們將討論Vulkan及其他PowerVR主題。我將描述如何在Vulkan中實現高效渲染的技術,且我將加入圖形小組,討論Vulkan對圖形生態系統的影響。感謝您的閱讀!


















 工商網監
工商網監
評論