 電子發燒友App
電子發燒友App


在上一篇文章中,我談到了GPU架構的工作原理。這是一個比較新穎的架構,與其他架構的工作方式不太相同,我們稱之為基于區塊貼圖的延遲渲染或TBDR。從概念而言,其基本前提非常簡單。
首先,我們把屏幕分成小的區塊,使之操作簡單且大小適于完全放在GPU上,大量減少訪問內存。這部分我先做闡釋,不熟悉此部分的請先行了解。
第二部分需使用第一部分生成的信息——渲染貼圖的原語列表——盡可能多地延遲隨后生成的像素,所以渲染盡量不會放過每個細節之處。讓我們先來看看硬件的工作。

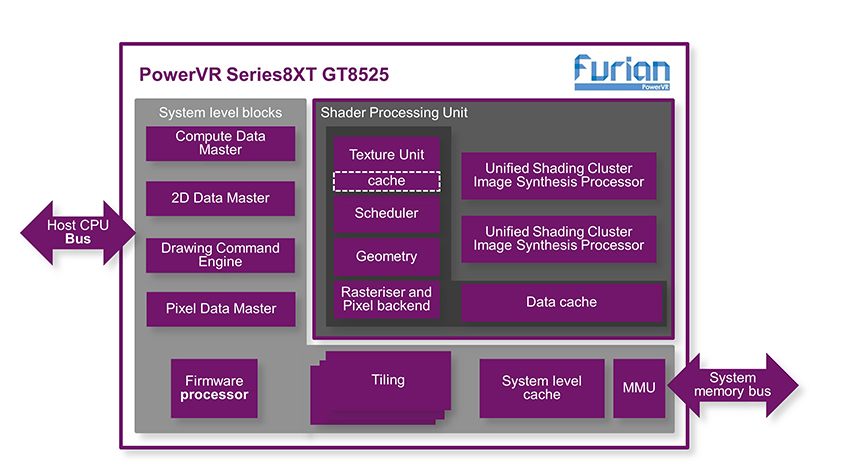
TBDR上的數據報告:PowerVR Rogue的延遲渲染
參數緩沖區
在我的上一篇文章中提到,硬件所需完成的最后一件事便是填滿參數緩沖區(PB)。回顧一下,PB本質上是一個打包的區塊貼圖列表,填充了形成貼圖的轉換幾何圖,硬件同樣可以對其進行有效的計算。記住,我們不必使用簡單且效率低下的方法來計算究竟是哪個幾何對象構成了貼圖。實際上,我們可以準確地計算貼圖,因而不必要浪費時間處理那些最終不會對貼圖產生影響的原語。
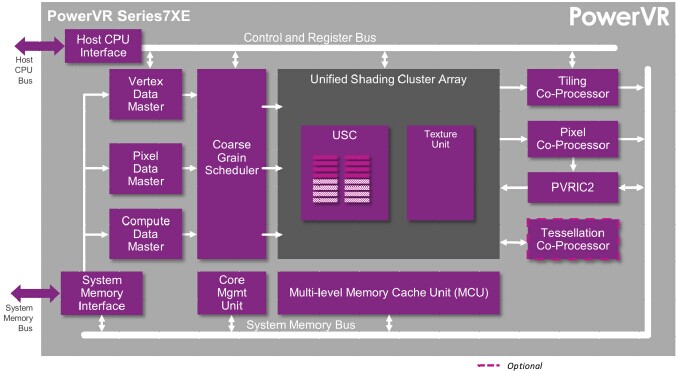
因此,GPU建立了中間數據結構,并具有完整的三角形列表。接下來便是光柵化,,并把那些三角形變成像素,且在內核中對像素進行著色。對于我們的架構而言,光柵化尤為復雜:驅動GPU效率的關鍵事物投射在這部分管道中,接下來讓我們逐步了解相關過程。
另外,一些讀者可能會很驚訝地發現,光柵化并不僅僅發生在一個簡單的稱之為光柵格的單片上。在所有GPU中,無論大小,都是由許多子塊組成的比較緊湊的面向數據流的管道在運行。使之在不成為影響吞吐量的瓶頸下保持平衡則非常困難,且由于任務的性質,固定功能邏輯比可編程著色器內核更加合適。
提取PB數據至內核中
首先,我們需要從內存中提取貼圖列表至內核中,然后解析他們的狀態、位置數據和一些控制位,使GPU可以恰當的運行幾何對象。數據可以被壓縮,所以區塊負責讀取數據,即我們所說的參數獲取,其也能解壓數據。由于區塊存在內存訪問,一些獲取內存延遲的情況必須容許,所以可以從內存中預讀取及突發讀取數據,使PB中的數據可以再次進入內核中。目前為止,一切很順利。
邊緣方程
既然我們已經把三角形放置在內核中,接下來便是將它們變成像素。注意,我們是在3D而非2D空間處理幾何對象,而您的屏幕是一個2D平面。所以我們需要采取某種方式,將渲染的3D計算視圖映射到2D屏幕上。

接受來自參數提取物的原語的硬件字節,在柵格化像素的過程中負責設置定義三角形邊界的三角方程,因此我們在屏幕上看到的不僅僅是點,還有三角形的呈現。由于涉及到一些計算,硬件字節在固定的設置下有其專用且實際上非常復雜的浮點單元。
接下來便是三角形的邊界計算方程。三角形共享準確深度值時,深度偏置可以起作用。這樣便不必糾結于哪個邊界應該可視化,且一些角度的計算可以為進一步形成的區塊提供有關幾何圖像構成的信息。
平面方程
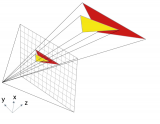
有了一組邊界方程,便可結合邊界方程定義三角幾何,猶如3D空間中的三棱鏡。在頭腦中想象圖像可能有違直覺,因為您從未真正看過其3D效果。您需要一些想象的線條來構建可視化的圖像。
其次,需要一個穿過棱鏡的2D切片,這樣當三角形的2D效果呈現在屏幕上時,可以基本拉平圖像,并找出棱鏡的字節。這是一個重要的里程碑。要實現上述過程,便需要一個四階方程來定義通過棱鏡的平面片,而棱鏡則由邊界方程定義。
在硬件中評估四階方程,其給出的平面片可以映射到貼圖的像素中。接下來對屏幕貼圖做一些闡述以助于理解此部分內容。
貼圖大小
任何貼圖架構都要在貼圖大小和存儲空間之間進行一些權衡。在我們的案例中,我們需要一些用于參數緩沖區的存儲空間來儲存貼圖的三角形列表。而這個存儲空間位于系統內存中。其次,還需要GPU芯片內的存儲空間,用于處理貼圖中的像素。
因此對于這兩個貼圖理論上的尺寸,一個貼圖是另一個的四倍 (兩倍X軸和兩倍Y軸),且渲染分辨率是1080 p。顯然,如果尺寸較小,則需要較多的貼圖,這意味著參數緩沖區中需要有更多的貼圖列表,但可與貼圖交叉的三角形則更少,因此所需GPU存儲也更小。反之亦然。我們只需較少的貼圖列表,因為貼圖不可能足夠多,但每個貼圖的三角形平均數量則可能會增多,且由于每個貼圖是像素的4倍,因此需要4倍的GPU存儲空間。
所以,在我們的架構中,貼圖的尺寸趨于偏小。John和他的團隊在計算最優尺寸時則考慮的更多,但尺寸等都是最大的考慮因素。目前,Rogue上用于一般渲染的像素是32×32,但其比起過去在SGX上的渲染像素要更小,且架構也非方形矩陣。
多重采樣
在一般渲染時,還需考慮一件事情:多重采樣。這里不對MSAA作全面介紹——以后發表的文章中將會詳述——但它卻可以提高圖像質量,因為它比常規的渲染(通常為一個像素)所生成的像素樣品更多,且使用這些額外的數據可以在樣品中濾除圖像中的高頻信號。
因此如果為每個像素生成的數據更多,我們需要相應的存儲空間。幾個方式可以嘗試。一個是在系統內存中存儲額外的樣品;另一個是使用GPU存儲,這樣在處理MSAA時便不需要消耗非GPU帶寬。
采用第二種方式時,在GPU中為多重采樣數據分配一些存儲,以提高效率及降低外部內存帶寬。存儲的形式不在本文討論范圍之內,但顯然這應該著色器內核的一部分,這樣USC便可以迅速對之訪問。
實際柵格化
回到我們之前討論的柵格化。每個區塊貼圖中的三角形都會生成一個邊界方程,我們在合成圖像處理器(ISP)中對這些邊界方程和平面方程進行共同評估。ISP是GPU設計的核心,因為有了ISP,延期渲染才得以進行。
評估方程后,對貼圖中每個像素樣品位置的三角形顯示結果進行測試(或如果是多重采樣,則對采樣位置進行測試),看看哪些像素位于即將產生的三角形內。這時,我們才最終完成柵格化:通過評估邊界方程且對貼圖像素的結果進行測試后,使三角形形成2D圖像,這樣便知道其覆蓋的屏幕區域。
消除隱藏面
消除隱藏面才意味著GPU開始真正地節約效率。貼圖操作把屏幕分成很多適宜于GPU的小字節,這樣,既可將數據儲存在GPU上,又可以在運行數據時避免過多消耗且保證內存訪問時功率充足。但我們還可以做到更極致。

在進行像素柵格化時,對其在深度緩沖區中的深度(在圖表中用Z表示)進行了測試。如果深度測試(通常是“是否比深度緩沖區像素位置最后的值更接近屏幕?”)通過,則用最新的像素值更新深度緩沖區,且將數據“此三角形中的此像素形成了貼圖”進行存儲。
可以想象,這一處理的結果是一組貼圖數據,且僅對通過了深度測試的可見像素進行編碼。這里再重點強調一遍。處理的結果是一組貼圖數據,且僅有通過深度測試的可見像素才進行編碼。
處理過程中節約效率尤為重要。我們可以在GPU工作之前預先捕獲給定渲染的繪制調用。在其他GPU中,驅動器將發送命令到GPU,使之盡快在應用程序中完成繪制調用。它不會在乎前一個或接下來的繪制是什么。但在命令較多的時候,知曉前后繪制調用的內容便可以大量節省功率。嘗試及避免在其他架構上工作的傳統方式類似于這種情況,即在像素渲染前便已完成深度測試。但是測試往往不如我們測試像素這般精準。
在給GPU輸送命令之前,我們啟用所有影響給定緩沖區的繪制調用。這個過程可以讓我們獲取影響緩沖區渲染的所有幾何對象,使我們可以完成貼圖和HSR,盡可能避免多余的工作。
對于非透明的幾何對象,這種方式非常有效,文末將對此進行簡要介紹。
透明度
顯然,當透明物體被擋后,ISP需要克服障礙。我們處理透明度的方法相當簡單,即節省效率。當透明的物體從先前的區塊中進入ISP時,我們可以有效地停止操作,直接沖刷所有通過深度測試的像素進入著色器內核。為何?因為我們可以在頂點對透明物進行混合,我們所需了解的是混合值。
所以,我們清空ISP進入USC(或SGX中的USSE),對所有阻擋物體的可見非透明阻擋物進行渲染,并使用最終像素值更新緩沖區,這樣我們便可以在頂點混合。到這一步先稍安勿躁,先看看接下來進入ISP的對象是什么,因為我們需要維持API提交順序,以滿足所有當前的API規范。
如果一個透明物進入后,再次進入另一個透明物,我們需再次沖刷以確保正確的渲染。不管非透明對象如何覆蓋所有透明對象,只要通過深度測試,便不影響繼續操作。
因此要確定沖刷對效率的損失有多少,取決于何種渲染物以何種順序完成渲染。立即模式渲染值得一提:它們從不在意渲染的類型,并一直在消耗帶寬的情況下進行混合。但我們的架構旨在盡可能節省成本,我們要做的是一個權衡了原始性能的產品。
所以你還未曾見過我們的開發人員推薦文件,但最后會要求開發人員公開相關文件。
并行性
這里我要講一點有關并行性的內容。由于我們操作貼圖,而貼圖通常是獨立儲存,可以想象要在硬件層進行并行處理理論上來說是非常瑣碎的事情。而Rogue配置了兩個前端。我們讓一個在列表中分配貼圖的前端控制器處于并行工作狀態,然后再同時關閉,完成上述描述的整個流程。
節省了什么?
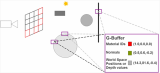
總結一句,HSR部分是我們在架構中節省效率最大的一部分。但保存至芯片且僅處理可見像素到底節省了什么?首先,所有的紋理和目標在像素渲染過程中要渲染緩沖出入口帶寬,渲染這些像素時會引起消耗。像素渲染將紋理作為輸入,并需要在最后編寫最終值。而對于延遲渲染,我們可以創建和使用芯片上的整個G-buffer區 (如果它適合每個像素空間)且沒有外部內存訪問。

我們還保留了所有在ISP中舍棄的像素的渲染運算操作:現代著色器有數以百計的周期,USC是設計中消費功率的最大部分。最重要的是,USC在運行著色程序時,還需要在最后一個值寫入貼圖內存之前讀寫其內部寄存器來存儲中間值。而注冊訪問則消耗內部寄存器文件的帶寬和大量的功率。
因此,潛在成百上千的ALU操作和寄存器讀寫,而這些本是不必要的。為像素點亮USC才形成最終看到的畫面。相比同類產品,我們最大的優勢很大程度上是由于這種由ISP驅動的機制及運用各層級管道來實現的。
在我們使用GPU的產品中,功率優勢對于您使用手機、電腦或智能手表時的體驗尤為重要。實際上,任何設備均需要強大有效且可以最佳利用電池的GPU。

















 工商網監
工商網監
評論