 電子發燒友App
電子發燒友App


首先,我們來了解一下什么是近存處理器。下圖展示了幾種主要的近存和存內處理芯片設計方案的基本概念。
- Traditional:傳統的處理器系統,運算和存儲是2個不同的die,通過片外走線連接。
- 2D CIM:存儲和運算在同一個die中,混合分布。
- 2D PNM:存儲和運算在同一個die中,分成兩個獨立的部分。
- 2.5D PNM:存儲和運算在2個不同的die上,通過interposer連接。
- 3D HB-PNM:存儲和運算2個die臉對臉通過銅-銅互連(本論文的方案)。
- 3D TSV-PNM:存儲和運算stack的方式通過TSV連接。
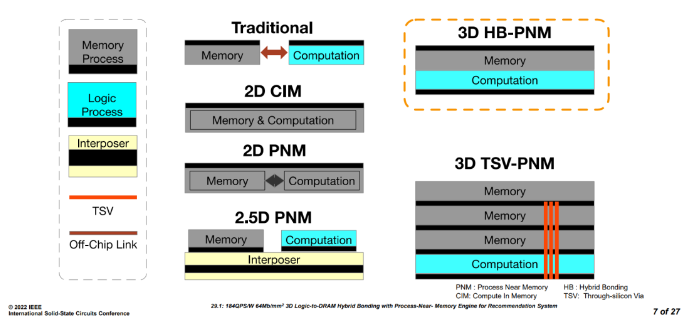
Figure1 近存存內處理器結構介紹[1]
推薦系統工作流程
?
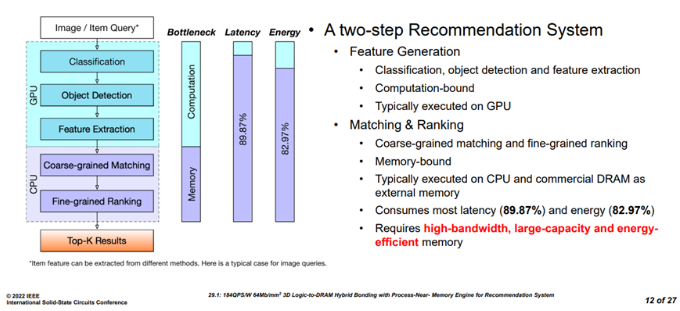
Figure2 推薦系統任務流程[1]
推薦系統的工作流程主要包含特征生成和召回排序兩個階段。其中,特征生成主要在GPU上運行,具體的任務包括分類,目標檢測,特征提取,通常是運算密集型任務。而召回排序包括粗粒度召回和細粒度排序兩個階段,占據了整個推薦任務89.7%的延遲和82.97%的能量消耗,因此,該階段需要大容量,高帶寬,低能耗的存儲系統。
?
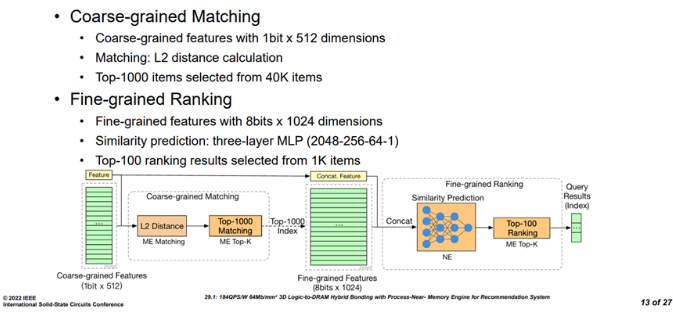
Figure3 召回和精排任務流程[1]?在該芯片設計面對的推薦任務中,粗粒度召回包含L2 distance和Top-k兩個階段,輸入為1個1bitx512維度的特征,首先進入ME(matching engine)單元進行L2距離計算,然后從40k的項目中選出排名靠前的1000個子項,得到一個8bits x 1024的特征,這些特征和之前的特征連接合并,進入細力度排序階段。細力度排序包括相似度預測和top-k兩個階段,相似度預測由一個三層的MLP進行操作(2048-256-64-1),主要利用NE(neural engine)進行,最后MLP的輸出會再次返回ME進行top-k操作, 從之前的1000個子項中選擇100個子項,然后返回查詢結果。
近存處理器架構
整體架構
?
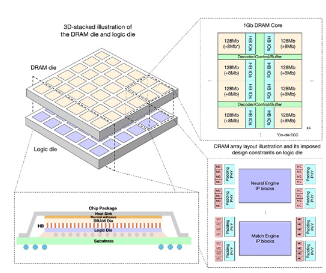
Figure4 3D stack芯片整體結構[1]?整體邏輯die wafer和DRAM die wafer通過臉對臉對貼,銅-銅互連,邏輯和DRAM die 有同樣的大小,都是25.24 x 23.86 mm2,DRAM 由6x6個同等大小的block組成,每個block是4x4 mm2,有1Gb的容量大小。這1Gbit的DRAM 有8個bank,支持ECC, 每個bank有128 bits的IO。每個邏輯block都可以訪問自己對應的DRAM block,此外,也可以通過片上總線訪問其它的DRAM block。每4個DRAM block的大小是64mm2,DRAM die工作在150Mhz,1.1V, 功耗為300mW/1Gb,36個DRAM總的帶寬為1.38TB/s。
?
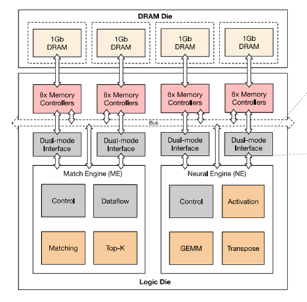
Figure5 近存處理器的整體架構[1] ? ??
每4個DRAM block對應一套處理引擎,即ME(
match?
engine)和NE(neural engine)。其中match engine中主要有top-k和matching 2個DSA處理模塊,而neuralengine中由activation函數處理,GEMM運算和transpose操作等引擎構成。NE的大小為5.9mm,ME的大小為7.02mm,邏輯die工作在300Mhz 1.2V,功耗為977mW。ME和NE分別連接了2個dual-mode interface,每個dual-mode interface和8個memory controller連接。這8個MC可以同時給ME提供數據或者只有其中一個MC給ME提供數據。
Matching engine
?
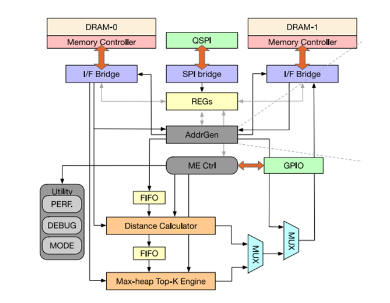
Figure6 matching engine微架構[1]
如前面介紹所說,matching 引擎負責召回階段的top-k和L2 距離計算以及精排階段的top-k,因此,該模塊最主要的功能模塊就是distance calculator和max-heap top-k engine。
地址生成器
?
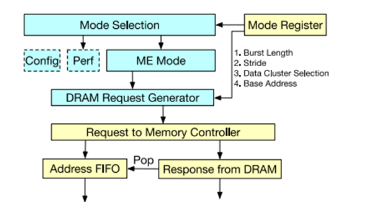
Figure7 地址生成邏輯[1]
地址生成器的主要功能是生成DRAM的訪存請求,其地址生成可以通過寄存器配置,包括不同的brust length和stride,數據cluster、基地址等。
距離計算邏輯
?
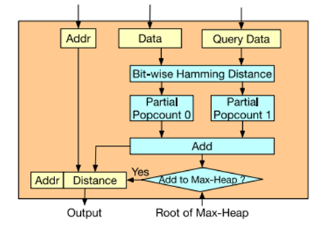
Figure8 距離計算[1]?Bit-wise的漢明距離計算比較簡單,為查詢值和DRAM中的數據值進行按bit異或操作,異或后得到的值里面1的個數即漢明距離。
Top-K引擎
?
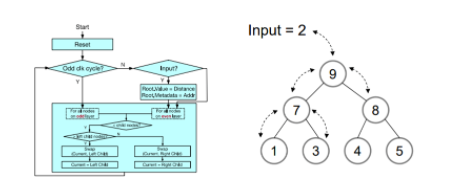
Figure9 max-heap硬件模塊[1]
Top-k引擎又稱排序引擎,基本邏輯結構為一個2叉樹的max-heap硬件模塊,其中由1000個節點組成,對應召回階段最短的1000距離值。堆棧模塊每2個周期從頂部即root節點輸入一個漢明距離數據。當奇數cycle時,對奇數層的節點進行操作,偶數cycle時,對偶數層的節點進行操作。每個node由node 索引和距離值構成,通過不斷的比較和交換當前節點和子節點的值,得到最終的top-1000的結果。同時,由于Top-K引擎只有處理速度的一半,在輸入端有一個比較邏輯用于初步過濾數據,因為棧頂總是當前大頂堆中最大的數據,當最新的計算距離小于當前堆頂的值才能替換當前root節點進入堆區域。Max-heap堆排序top-k算法規則如下:
- 當reset時,所有node的distance都設置成max值。
-
當父節點大于所有子節點的值時,不操作,否則進行下面的操作:
- 當前節點小于左子節點,則交換當前節點和左子節點的值。
- 當前節點大于左子節點,則交換當前節點和右子節點的值。
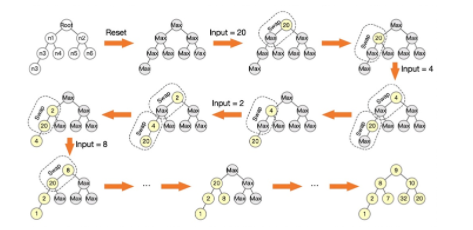
Figure10 max-heap算法舉例說明[1]
不難看出,該算法排序按經過若干次迭代操作后,最終拿到了我們想要的從樹底層左邊最小開始的top-1000樹形排列結果。
Neural engine
?
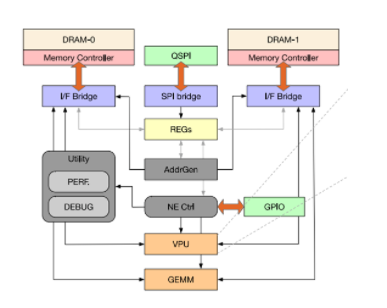
Figure11 Neural引擎[1]
Neural engine更像是一個傳統NN processor的方案,包含了VPU(vector process unit)和GEMM(general engine for matrix and multiply)。其中vector引擎包含了一個基于LUT的激活函數處理模塊,支持硬件GeLU和Exponential函數運算,另外vector還有一個轉置模塊,使用2D register file實現,使用乒乓的方式進行16x16的矩陣轉置,支持行寫入列寫出。
?
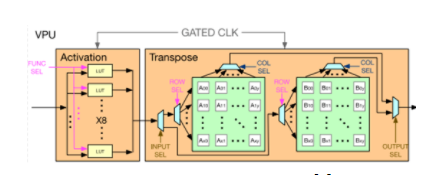
Figure12 vector process unit[1]
GEMM模塊在傳統NN處理器中用于計算矩陣乘法,這里主要用于MLP的運算流程。運算部分包含了32x32 int8的systolic array和int32的部分積累加器,分別有兩個輸入和一個輸出FIFO用于數據流水,使用weight station的策略,通過頂層的GEMM controller控制。運行在300Mhz時,總的算力為600Gops。
?
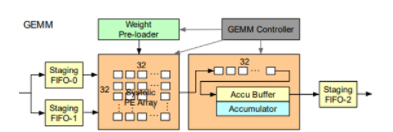
Figure13 GEMM[1]
實驗對比
?
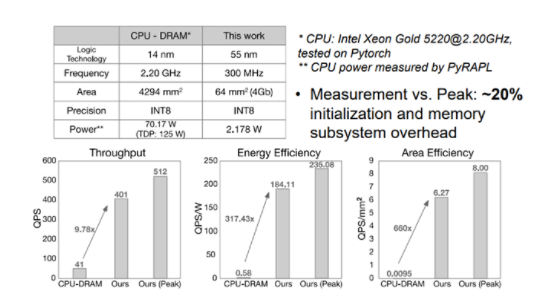
Figure14 性能功耗表現(vs CPU-DRAM)[1]?文章首先和CPU+DRAM組成的系統相比,該近存處理系統有9.7 倍的吞吐率QPS優勢,317倍的能效優勢QPS/W,660倍的面積優勢QPS/mm2。
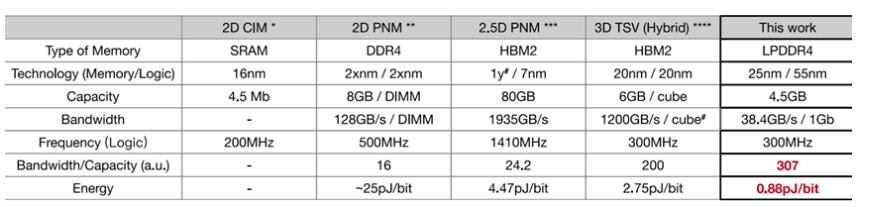
Figure15 性能功耗表現 vs CIM/PNM[1]?同時,文章還和最好的CIM/PNM處理器進行了對比,該設計在單位容量帶寬上,單位帶寬能耗上也保持很大的優勢。
?
總結
PNM和CIM架構可以很大程度上提高內存受限的應用的性能和功耗表現,本設計中的3D邏輯-DRAM Hybird bonding chip有以下幾個特點:
- 使用3D Hybrid bonding技術,為整個系統提供了具有高帶寬和能效的存儲系統。
- 使用了高吞吐率的流處理加速設計來進行粗召回和精排系統優化操作。
- 該設計達到了2.4GB/s/mm帶寬密度,0.87pJ/bit的能耗指標。
- 對于傳統的CPU+DRAM系統,該設計有300倍的能效提升和10倍的性能提升。
參考文獻
[1] Austin Derrow-Pinion, Jennifer She, David Wong, et al. ETA Predictionwith Graph Neural Networks in Google Maps.?2021
[1] 184QPS/W 64Mb/mm2 3D Logic-to-DRAM Hybrid Bonding with Process-Near-Memory Engine for Recommendation System DiminNiu, Shuangchen Li, Yuhao Wang, Wei Han, Zhe Zhang,Yijin Guan, Tianchan Guan, FeiSun, Fei Xue, Lide Duan, Yuanwei Fang, Hongzhong Zheng, Xiping Jiang, SongWang, Fengguo Zuo, Yubing Wang, Bing Yu, Qiwei Ren, Yuan Xie















 工商網監
工商網監
評論