 電子發燒友App
電子發燒友App


一、SIMD
ARM NEON 是適用于 ARM Cortex-A 和 Cortex-R 系列處理器的一種SIMD(Single Instruction Multiple Data)擴展架構。 ? SIMD?采用一個控制器來控制多個處理器,同時對一組數據(又稱“數據向量”)中的每個數據分別執行相同操作,從而實現并行技術。 ? SIMD?特別適用于一些常見的任務,如音頻圖像處理。大部分現代 CPU 設計都包含了 SIMD 指令,來提高多媒體使用的性能。 ?
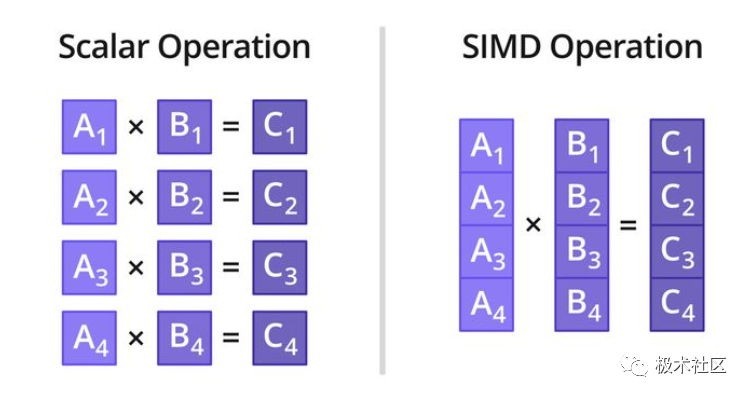
SIMD 操作示意圖 ? 如上圖所示,標量運算時一次只能對一對數據執行乘法操作,而采用 SIMD 乘法指令,則一次可以對四對數據同時執行乘法操作。 ?
A. 指令流與數據流
費林分類法根據指令流(Instruction)和數據流(Data)的處理方式進行分類,可分成四種計算機類型: ?
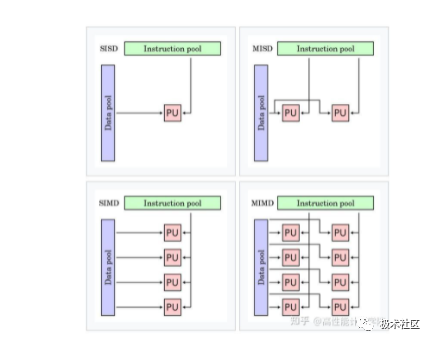
費林分類示意圖
1. SISD(Single Instruction Single Data)
機器的硬件不支持任何形式的并行計算,所有的指令都是串行執行。單個核心執行單個指令流 , 操作存儲在單個內存中的數據 , 每次一個操作。早期的計算機都是SISD機器,如馮諾.依曼架構,IBM PC機等。 ?
2. MISD(Multiple Instruction Single Data)
是采用多個指令流來處理單個數據流。由于實際情況中,采用多指令流處理多數據流才是更有效的方法,因此MISD只是作為理論模型出現,沒有投入到實際應用之中。
3. MIMD(Mutiple Instruction Mutiple Data)
計算機具有多個異步和獨立工作的處理器。在任何時鐘周期內,不同的處理器可以在不同的數據片段上執行不同的指令,也即是同時執行多個指令流,而這些指令流分別對不同數據流進行操作。MIMD架構可以用于諸如計算機輔助設計、計算機輔助制造、仿真、建模、通信交換機的多個應用領域。 ? 除了以上模型外,由NVIDIA公司生產的GPU引入SIMT體系結構:
4. SIMT(Single Instruction Multiple Threads)
類似 CPU 上的多線程,所有的核心各有各的執行單元,數據不同,執行的命令是相同的。多個線程各有各的處理單元,和 SIMD 共用一個 ALU 不同。 ?
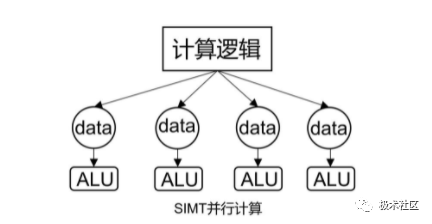
SIMT 示意圖
B. SIMD 特點及發展趨勢
1. SIMD 優勢與不足

2. SIMD發展趨勢
以ARM架構下的下一代 SIMD 指令集SVE(Scalable Vector Extension,可擴展矢量指令)為例,其是_針對高性能計算(HPC)和機器學習等領域開發的一套全新的矢量指令集_。 ? SVE 指令集中有很多概念與 NEON 指令集類似,例如矢量、通道、數據元素等。 ? SVE指令集也提出了一個全新的概念:可變矢量長度編程模型。
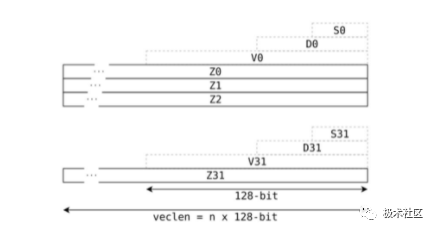
? SVE 可擴展模型 ? 傳統的 SIMD 指令集采用固定大小的向量寄存器,例如 NEON 指令集采用固定的 64/128 位長度的矢量寄存器。 ? 而支持 VLA 編程模型的 SVE 指令集則支持可變長度的矢量寄存器。因此允許芯片設計者根據負載和成本來選擇一個合適的矢量長度。 ? SVE指令集的矢量寄存器的長度最小支持 128 位,最大可以支持 2048 位,以 128 位為增量。SVE 設計確保同一個應用程序可以在支持不同矢量長度的 SVE 指令機器上運行,而不需要重新編譯代碼。 ? ARM 在 2019 年便推出了 SVE2,以最新的 Armv9 為基礎,擴充了更多的運算類型以全面替代 NEON,同時增加了矩陣相關運算的支持。 ?
二、 ARM 的 SIMD 指令集
1. ARM 處理器的 SIMD 支持 - NEON
ARM NEON 單元默認包含在 Cortex-A7 和 Cortex-A15 處理器中,但在其他 ARMv7 Cortex-A 系列處理器中是可選的,某些實現 ARMv7–A 或 ARMv7–R 架構配置文件的Cortex-A 系列處理器可能不包含NEON單元。 ? 符合 ARMv7 的內核的可能組合有以下四種: ?
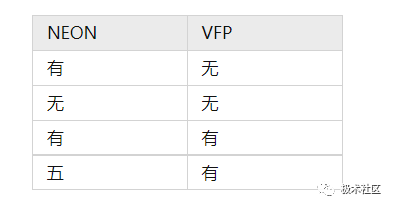
? ? 因此必須首先確認處理器是否支持 NEON 和 VFP。可以在編譯和運行的時候進行檢查。 ?
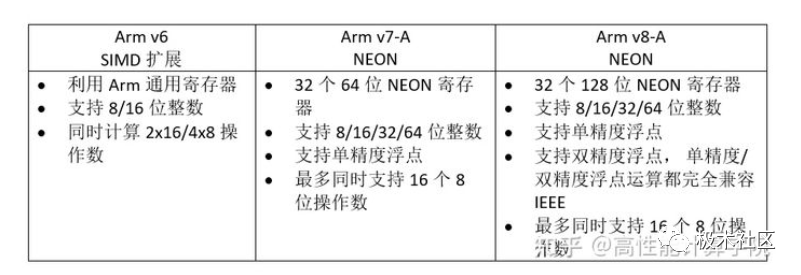
? NEON 發展史
2. ARM 處理器的 SIMD 支持檢查
2.1 編譯階段檢查
檢測 NEON單元是否存在的最簡單方法。在 ARM 編譯器工具鏈(armcc)v4.0 及更高版本或 GCC 中,檢查預定義宏?ARM_NEON?或者?__arm_neon?是否開啟。 armasm?等效的預定義宏是?TARGET_FEATURE_NEON。
2.2 運行階段檢查
在運行時檢測 NEON 單元需要操作系統的幫助。ARM 架構有意不向用戶模式應用程序公開處理器功能。在Linux下,/proc/cpuinfo?以可讀的形式包含此信息,比如:
在Tegra(帶有FPU的雙核Cortex-A9處理器)??
$ /proc/cpuinfo swp half thumb fastmult vfp edsp thumbee vfpv3 vfpv3d16
帶有 NEON 單元的 ARM Cortex-A9 處理器
$ /proc/cpuinfo swp half thumb fastmult vfp edsp thumbee neon vfpv3? ? ? 由于/proc/cpuinfo?輸出是基于文本的,因此通常首選查看輔助向量?/proc/self/auxv,其包含二進制格式的內核?hwcap,可以輕松地在?/proc/self/auxv?文件中搜索?AT_HWCAP?記錄,以檢查?HWCAP_NEON?位(4096)。 ? 某些 Linux 發行版ld.so?鏈接器腳本被修改為通過 glibc 讀取?hwcap?,并為啟用 NEON 的共享庫添加額外的搜索路徑。??
3. 指令集關系
在ARMv7中,NEON 與 VFP 指令集具有以下關系:
具有 NEON 單元但沒有VFP單元的處理器無法在硬件中執行浮點運算。
由于 NEON SIMD 操作更有效地執行向量計算,因此從 ARMv7 的引入開始,VFP 單元中的向量模式操作已被棄用。因此,VFP 單元有時也稱為浮點單元(FPU)。
VFP 可以提供完全兼容 IEEE-754 的浮點運算,_ARMv7 NEON 單元中的單精度運算不完全符合 IEEE-754_。
NEON不能取代 VFP。VFP 提供了一些在 NEON 指令集中沒有等效實現的專用指令。
半精度指令僅適用于包含半精度擴展的 NEON 和 VFP 系統。
在ARMv8中,VFP已被NEON取代,以上問題如 NEON 并不完全符合 IEEE 754 標準,并且有一些指令 VFP 支持而 NEON 不支持的問題已在 ARMv8 中得到解決。
三、NEON
NEON 是適用于 ARM Cortex-A 系列處理器的一種128位 SIMD 擴展結構,每個處理器核心均有一個 NEON 單元,因此可以實現多線程并行的加速效果。 ?
1. NEON基本原理
1.1 NEON 指令執行流程

? 上圖為 NEON 單元完成加速計算的流程圖。其中向量寄存器中的每個元素同步執行計算,以此來加速計算過程。 ?
1.2 NEON 計算資源
NEON 與 ARM 處理器資源關系
- NEON 單元作為 ARM指令集的擴展,使用獨立于 ARM 原有寄存器的 64位 或 128 位寄存器進行 SIMD 處理,在 64位 寄存器的寄存器文件上運行。- NEON 和 VFP 單元完全集成到了處理器中,并共享處理器資源以進行整數運算、循環控制和緩存。與硬件加速器相比,這顯著降低了面積和功耗成本。并且其還使用更簡單的編程模型,因為NEON 單元使用與應用程序相同的地址空間。 ?
NEON 與 VFP 資源關系
NEON 寄存器與 VFP 寄存器重疊,ARMv7 有 32 個 NEON D 寄存器,如下圖所示。 ?
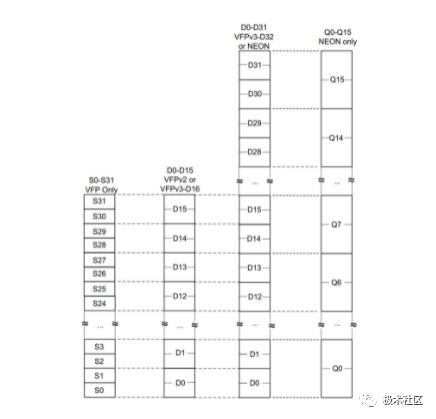
NEON 寄存器
2. NEON指令
2.1 自動矢量化
向量化編譯器可以使用 C 或 C++ 源代碼,以一種能夠有效使用 NEO N硬件的方式對其進行矢量化。這意味著可以通過編寫可移植的 C 代碼,同時仍然可以獲得 NEON 指令所帶來的性能水平。 ? 為了幫助矢量化,將循環迭代次數設為矢量長度的倍數。GCC 和 ARM 編譯器工具鏈都具有為 NEON 技術啟用自動矢量化的選項。
2.2 NEON匯編
對于性能要求特別高的程序,手工編寫匯編代碼是更適合的方式。 ? GNU 匯編器(gas) 和 ARM Compile r工具鏈匯編器(armasm)都支持 NEON 指令的匯編。 ? 編寫匯編函數時,需要了解ARM EABI,其定義了如何使用寄存器。ARM嵌入式應用程序二進制接口(EABI)指定哪些寄存器用于傳遞參數、返回結果或必須保留,指定了除ARM內核寄存器之外的32個D寄存器的使用。下圖對寄存器功能進行了總結。 ?

? 寄存器功能
2.3 NEON Intrinsics
NEON intrinsic 函數提供了一種編寫 NEON 代碼的方法,該方法比匯編代碼更易于維護,同時仍然可以控制生成的 NEON 指令。 ? 內部函數使用與 D 和 Q NEON 寄存器對應的新數據類型。數據類型支持創建直接映射到NEON 寄存器的 C 變量。 ? NEON intrinsic 函數的編寫類似于使用這些變量作為參數或返回值的函數調用。編譯器做了一些通常與編寫匯編語言相關的繁重工作,例如: 寄存器分配代碼調度或重新排序指令。 ?
intrinsic 缺點
無法讓編譯器準確輸出想要的代碼,因此在轉向NEON匯編代碼時仍有一些改進的可能性。 ?
NEON 指令簡類型
NEON 數據處理指令可以分為正常指令、長指令、寬指令、窄指令和飽和指令。以 Intrinsic 的長指令為例?int16x8_t vaddl_s8(int8x8_t __a, int8x8_t __b);- 上面的函數將兩個64位的 D 寄存器向量(每個向量包含8個8位數字)相加,生成一個包含8個16位數字的向量(存儲在128位的Q寄存器中),從而避免相加的結果溢出。
四、其他 SIMD 技術
1. 其他平臺上的 SIMD 技術
SIMD 處理不是 ARM 獨有的,下圖將其與 x86 和 Altivec 進行了比較。 ?
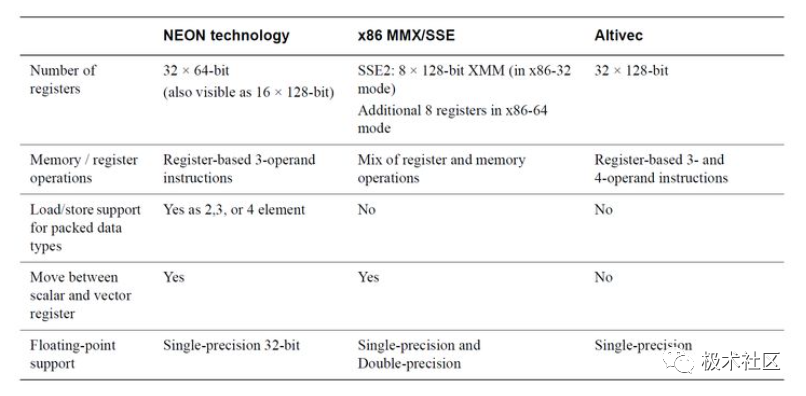
? SIMD 對比
2. 與專用 DSP 對比
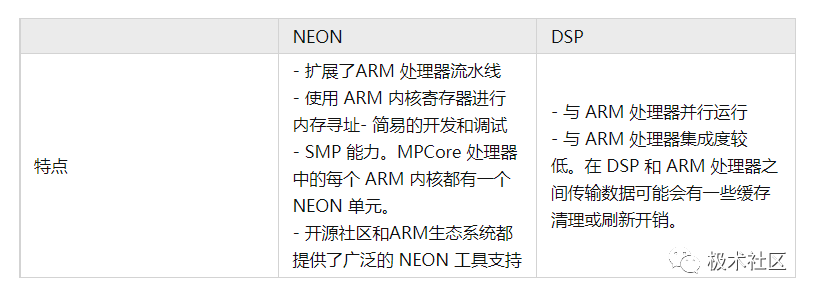
許多基于 ARM 的 SOC 中還包含 DSP 等協處理硬件,因此可以同時包含 NEON 單元和DSP。相對于 DSP,NEON 的特點有:
四、總結
本節主要介紹基本 SIMD 及其他的指令流與數據流的處理方式,NEON 的基本原理、指令以及與其他平臺及硬件的對比。 ?
編輯:黃飛
?










 工商網監
工商網監
評論