 電子發燒友App
電子發燒友App


我們在文章《萬字詳解AMD ZEN 4架構》中深入介紹了 Zen 4 的核心架構。而在本文中,我們將專注于我們沒有設法做到的任何事情。其中一些細節可能特定于我們擁有的特定 CPU 樣本,其中許多細節不會對應用程序性能產生重大影響。
Boost clock行為
AMD宣傳 Ryzen 7950X 的加速時鐘為 5.7 GHz。我們聽說 CPU 的最大頻率應該是 5.85 GHz,但我們無法達到該時鐘速度。在這里,我們將展示測試數據并討論 7950X 設計的其他方面。請記住,此處看到的行為可能是特定于樣本的。
首先,我們一一檢查了 7950X 的所有內核,并確定了它們提升到的時鐘速度。為了測量時鐘速度,我們測量了寄存器到寄存器整數加法指令的延遲。與之前的 16 核 AMD 臺式機部件一樣,并非所有內核都會提升到 CPU 的最大時鐘。在我們的 7950X 樣本上,我們看到內核 0、3 和 4 的最高時鐘頻率。所有這三個內核都位于第一個 CCD 上。
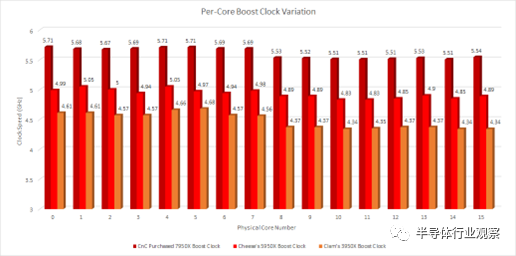
注意——沒有從 0 開始軸以使時鐘速度差異更明顯。
第二個 CCD 上的所有內核的時鐘頻率都低于第一個 CCD 上的內核。它們的范圍從 5.54 GHz 到 5.51 GHz,比我們在第一個 CCD 上看到的低 100-200 MHz。奇怪的是,前幾代人表現出完全相同的模式。
Cheese 的 5950X 在核心 1 和 4 上達到了最高時鐘。兩者都位于第一個 CCD 上。我的 3950X 在核心 4 和 5 上的時鐘頻率最高。兩者也在第一個 CCD 上。這是一個奇怪的模式。也許 AMD 只是binning一個 CCD 以達到 16 個核心部件的最大升壓時鐘。
我們的 Zen 4 和 Zen 3 芯片的時鐘速度變化也小于我們的 Zen 2 芯片。

如果您的操作系統的調度程序沒有優先安排最佳內核上的低線程任務,則 3950X 的性能可能會出現相當大的變化。Ryzen 5950X 和 7950X 在這方面要好得多。雖然時鐘速度差異是可以測量的,但感受 3-4% 的性能差異要比感受 7-8% 的性能差異要困難得多。
持續時間短的Boost行為
我還想知道 Zen 4 是否會暫時達到更高的時鐘速度,然后在之前測試的測量間隔內回落。該測試通常需要幾秒鐘來確定時鐘速度,以便為任何測試的 CPU 提供合理的時間來斜坡時鐘。為了查看時鐘是否以非常精細的粒度變化,我使用了時鐘斜坡測試,每個樣本有更多的迭代。該測試使用 RDTSC 以優于毫秒的精度采集樣本。增加每個樣本的迭代次數可以讓測試覆蓋更長的持續時間以捕獲快速的時鐘速度變化,但不會創建一個巨大的厄運電子表格。我還在每個核心上運行了測試。結果在同一個核心上是一致的,但在不同核心上卻不一致。
讓我們一次處理一個 CCD,因為有很多數據。根據內核的不同,我們在 700 毫秒的時間窗口內看到了略高于 5.71 GHz 的時鐘。然而,結果千差萬別。一些內核,如內核 0 和 2,在不到 50 毫秒的時間內提升至 5.74 GHz,然后降至 5.71 GHz。Core 2 保持 5.74 GHz 將近半秒,然后表現出不穩定的行為。
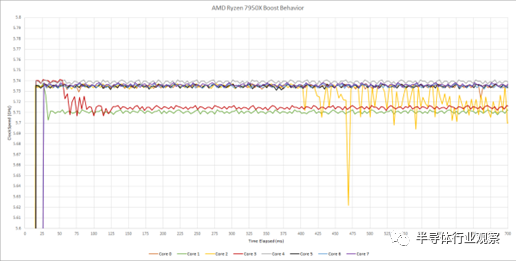
測試還使用整數加法延遲來測量時鐘速度。
第二個 CCD 顯示出相似的特征。然而,該 CCD 上的核心實際上開始接近 5.6 GHz。他們在很短的時間間隔內保持該速度,然后稍微降低速度。
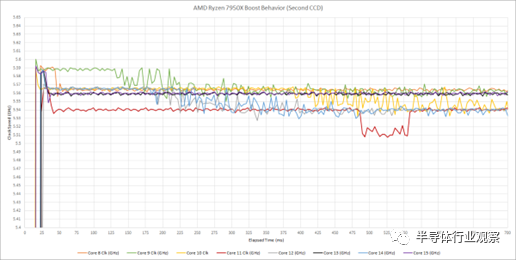
這是一個有趣的行為,盡管與大多數用戶無關。短期和長期升壓時鐘的差異很少超過 50 MHz。如果您回到過去并運行 266 MHz Pentium II,那么 50 MHz 就很重要了。今天,50 MHz 的差異小得可笑。在 Zen 4 運行的時鐘速度下,50 MHz 僅占不到 1% 的差異。該測試的最大收獲是 Zen 4 在非常小的時間片內調整時鐘速度,用戶不應期望時鐘速度非常穩定。
Not So Infinite Fabric?
與 Zen 2 和 Zen 3 一樣,每個 Zen 4 核心復合體都有一個 32B/cycle
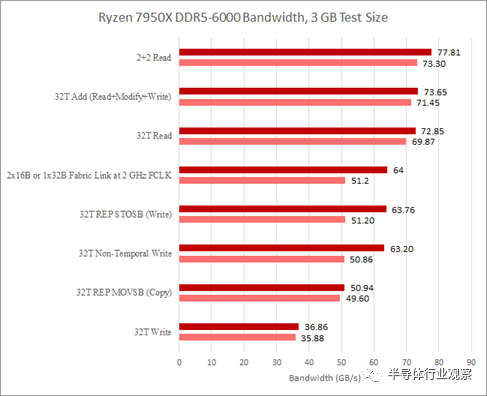
的結構讀取鏈接和一個 16B/cycle的寫入鏈接。在上一篇文章中,我們注意到 DDR5-6000 的寫入帶寬可能受到來自兩個 CCD 的 16B/周期鏈接的限制。我們從一個 CCD 看到了類似的讀取帶寬限制。我們使用 3 GB 測試大小和縮放線程數運行內存帶寬測試以命中所有物理內核。CCX 和 CCD 一個接一個地裝滿。在 3950X 上,這意味著首先在 CCD 上填充兩個 CCX。從結果中,我們可以清楚地看到單個 7950X CCD 受到其與結構的 32B/cycle鏈接的限制。
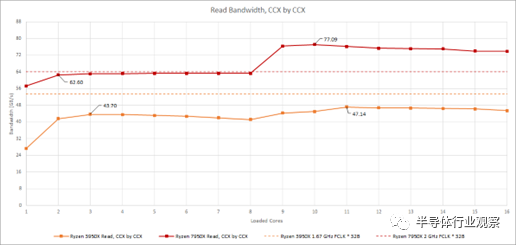
在 Zen 2 和 Zen 3 上,Infinity Fabric 互連通常可以在 DDR 時鐘或 DDR 傳輸速率的一半下運行。因此,單個 CCD 可用的結構帶寬不是問題。在匹配的時鐘下,單個 32 字節/周期或 256 位鏈路提供與 16 字節/周期或 128 位 DDR 設置相同的理論帶寬。當第二個 CCD 激活時,Zen 2 確實看到測得的內存帶寬略有增加,但差異非常小。對于 Zen 4,這提出了一個有趣的問題,即快速 DDR5 是否值得用于具有單個 CCD 的設計。技嘉黑客泄露的 Genoa(Zen 4 服務器變體)處理器編程參考手冊建議每個 CCD 可以有兩個結構鏈接。根據它們的配置方式,將快速 DDR5 與單個 CCD 部件配對可能不值得,尤其是當主要目標是提高內存帶寬受限應用程序的性能時。
在 Ryzen 3950X 上,每個 CCD 的較窄寫入鏈路意味著單個 CCD 寫入帶寬限制可能會在人為測試下出現。但是,在寫入時,兩個 CCD 加在一起幾乎可以使 DDR4 設置飽和。正如我們 Zen 4 報道的第 2 部分所述,7950X 的寫入帶寬似乎受到從 CCD 到 Infinity Fabric 互連的 16 字節/周期鏈接的限制。如果我們用非時間寫入重復上面的測試,我們可以清楚地看到當單個 CCD 處于活動狀態時類似的帶寬限制。
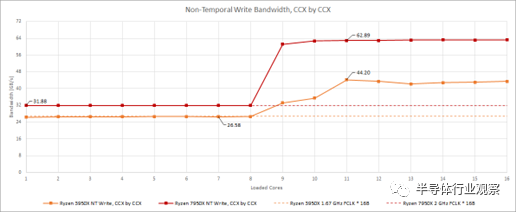
奇怪的是,這兩個測試以及兩個被測試的 CPU 都表明我們可以通過不加載所有內核來實現更高的帶寬。
更少的線程,更多的帶寬?
當我們測試內存帶寬時,每個線程都有自己的數組,所有線程的總數據加起來就是測試大小。該策略可防止內存控制器機會性地組合來自不同線程的訪問。然后,我們生成與硬件線程一樣多的軟件線程。帶寬如何隨著線程數的增加而擴展是一個有趣的話題,但我并不總是有時間和精力來解決這個問題。正如您在上面看到的,這個案例非常值得一試。

以 2000 MHz FCLK 運行。內存帶寬兔子洞有多深?
通過進一步測試,我獲得了最高的內存帶寬和四個線程,固定到每個 CCD 的兩個內核。進一步調查顯示 3950X 有類似的行為。我還檢查了 CCX 到 Infinity Fabric 請求的性能計數器、內存帶寬和 L3 命中率,以確保寫入組合或緩存惡作劇沒有發揮作用。
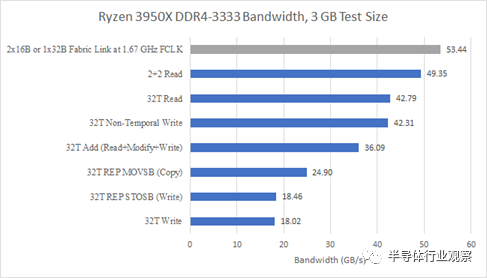
32B/周期結構鏈路帶寬等于可用的 DDR4 帶寬
對此行為的一種解釋是 32 線程工作負載對內存控制器的要求比 4 線程工作負載更苛刻。如果使訪問模式更加分散,那么公開更多的并行性并不是一件好事。內存控制器將更難嘗試安排訪問以最大化頁面命中率,同時又不會停止任何訪問足夠長的時間以使某些隊列備份。
我們還可以根據內存控制器如何有效地利用理論帶寬來查看相同的數據。顯然,越高越好,即使我們從未期望達到理論帶寬。頁未命中、讀寫周轉和刷新將導致內存總線周期丟失,并且沒有辦法避免這種情況。
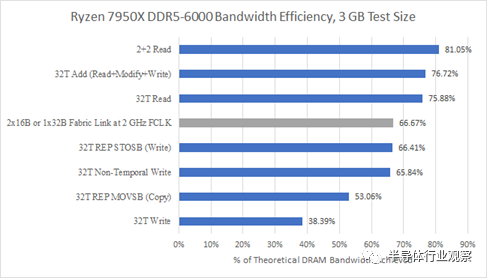
每個 CCD 有兩個線程,帶寬效率相當不錯。81%的理論一點都不差。AMD 較舊的 DDR4 控制器在利用可用帶寬方面仍然更好:
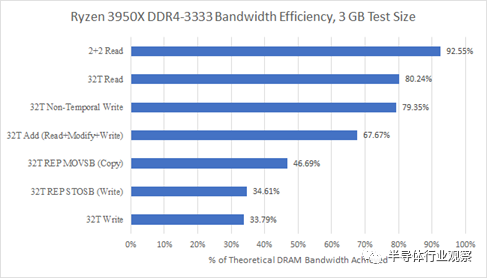
但這并不能說明全部。如果我們看看其他訪問模式,Zen 4 在最大可實現帶寬之外的領域也取得了進步。Zen 2 不知道如何在 REP STOSB 情況下避免讀取所有權訪問,但 Zen 4 知道。Zen 4 的 DDR5 控制器還可以更好地處理讀取-修改-寫入訪問模式,這可能表明它在混合讀取和寫入時受到的損失較小。通過純 AVX 寫入和加載所有線程,Zen 4 還實現了更好的帶寬效率。從絕對意義上講,Zen 4 的 DDR5 控制器還提供比舊款 DDR4 控制器高得多的帶寬。
FCLK效應?
我們還使用較低的 1.6 GHz Infinity Fabric 時鐘或 FCLK 進行了測試。結果進一步證明寫入帶寬受 Infinity Fabric 帶寬限制。具體來說,我們看到寫入帶寬急劇減少。如果我們受到每周期兩個 16 字節 CCD 到 IO 芯片鏈接的限制,這種減少與我們期望看到的帶寬損失非常吻合。
讀取帶寬顯然不受 Infinity Fabric 帶寬的限制。我們在 FCLK 的每個周期遠遠超過 32 個字節。此外,帶寬的下降并不對應于 FCLK 的下降。具體來說,20% 的 FCLK 降低只會使最大讀取帶寬降低 5.8%。然而,有趣的是,我們在較低的 FCLK 下讀取帶寬出現了可測量的下降。
集成顯卡
AMD 的桌面 Zen 4 平臺 Raphael 是最近內存中第一個集成 GPU 的高性能 AMD 平臺。在前幾代產品中,AMD 的產品線是分裂的。桌面芯片提供了最高性能的 CPU 配置,比移動芯片具有更多的緩存、更多的內核和更高的時鐘。另一方面,“APU”提供了一個相對強大的集成 GPU,能夠進行輕度游戲。他們還繼續使用單片芯片來節省電力,即使他們的臺式機同行轉而使用小芯片設置以以合理的成本提供更多的核心數。
但是 Zen 4 的 IO die 轉向了 TSMC 6 nm 工藝,與之前 IO die 使用的 GlobalFoundries 12nm 工藝相比,它提供了很大的密度提升。IO 接口通常不能隨著工藝節點的縮小而很好地擴展,但以前的 IO die的芯片照片顯示,IO 控制器邏輯和支持 SRAM 占用了大量區域。這些塊可能確實可以通過縮小芯片來很好地擴展,從而為 AMD 提供添加小型 iGPU 的空間。
Raphael 的集成 GPU 沒有 AMD APU 的性能雄心,并且似乎打算在沒有可用的專用 GPU 時驅動顯示器。它采用 AMD 的現代 RDNA2 圖形架構,但僅使用一個 WGP 以盡可能小的配置實現它。由于我們一直在談論內存和結構帶寬,讓我們從帶寬測試開始。畢竟,Raphael iGPU 確實為我們提供了一種額外的方式來使用 DDR5 控制器。
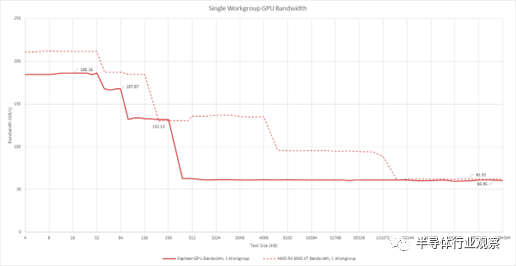
不幸的是,測試帶寬并沒有告訴我們任何可能的結構限制。我們從 DRAM 大小的區域獲得超過 60 GB/s 的速度。來自另一個 RDNA2 實施的數據表明,無論如何,單個 WGP 不能從 DRAM 中提取超過 60 GB/s 的數據。如果 iGPU 具有 32 字節/周期的結構鏈接,則 2 GHz 結構時鐘將提供 64 GB/s 的帶寬。這足以養活一個 WGP。
帶寬測試還表明我們正在處理非常小的緩存配置。之前,我們查看了幾款 iGPU,注意到 AMD Renoir 的 iGPU 使用相對較大的 1 MB L2 緩存,以補償與 CPU 共享帶寬相對較低的 DDR4 總線。Raphael 的 iGPU 甚至沒有與低端顯卡競爭的愿望,L2 大小降至 256 KB。有趣的是,AMD 還將 L1 緩存大小降至 64 KB。到目前為止,我們看到的所有 RDNA(2) 實現都使用了 128 KB L1 緩存。但看起來 RDNA2 的 L1 可以配置為該大小的一半。與離散的 RDNA2 GPU 不同,Raphael 的 iGPU 沒有 Infinity Cache。L2 未命中直接進入內存。
我們可以通過延遲測試來確認緩存設置細節。最近,我們發現我們的簡單延遲測試實現正在影響 AMD 在 GCN 和 RDNA GPU 上的標量數據路徑。查看編譯后的程序集表明生成了 s_load_dword 指令,因為編譯器意識到加載的值在波前是統一的。
s_load_dword 訪問標量緩存而不是向量緩存,并且這些緩存在 GCN 和 RDNA 上是分開的。應用 hack 來阻止編譯器確定加載的值是否統一會導致 global_load_dword 指令和更高的測量延遲。在最近的 Nvidia 和 Intel 架構上,這種 hack 沒有效果,因為即使整個 wavefront 或 warp 正在加載相同的值,也會使用相同的緩存。這使 GPU 基準測試變得復雜,因為展望未來,我們必須為現代 AMD GPU 提供兩組延遲結果。讓我們從標量端的延遲開始。
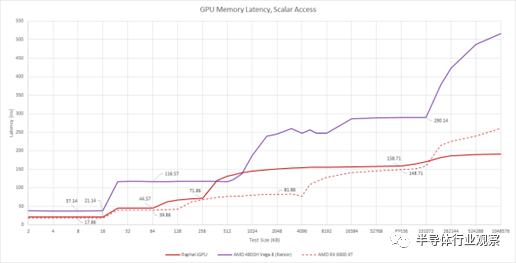
我們看到確認 Raphael 的 iGPU 有一個 64 KB L1,由一個 256 KB L2 支持。它的時鐘似乎略低于桌面 RDNA2,導致更高的 L1 標量和共享 L1 延遲。然而,Raphael 的微型 L2 比 6900 XT 的延遲更好。與其桌面對應物一樣,Raphael 的 iGPU 享有比Renoir 使用的舊 GCN 架構更低的標量加載延遲。然而,Renoir 有一個更大的 L2 緩存,以幫助 iGPU 免受內存帶寬瓶頸的影響。
Raphael 的 iGPU 也享有比Renoir 更好的 DRAM 訪問延遲。此處測試的 Ryzen 4800H 確實存在更高的內存延遲,在 1 GB 測試大小下達到 84.7 ns,而 7950X 為 73.35 ns。然而,這個相對較小的差距并不能解釋 GPU 端 DRAM 延遲的巨大差異。超過 L2 容量后延遲的跳躍表明測試正在溢出 GCN 的 TLB 級別。在 128 MB 之后,我們可能會看到完全 TLB misses。
Raphael 的 iGPU 上的 DRAM 訪問延遲也與桌面 RDNA2 的訪問延遲相當。Desktop RDNA2 的 DRAM 訪問延遲超過 250 ns,而 Raphael 的 iGPU 可以在 191 ns 多一點的時間內訪問 DRAM。該優勢可能是因為 iGPU 非常小,這意味著它在通往 DRAM 的途中不必經過非常復雜的互連和大型緩存。iGPU 也位于 IO 裸片上,IO 裸片也有內存控制器。
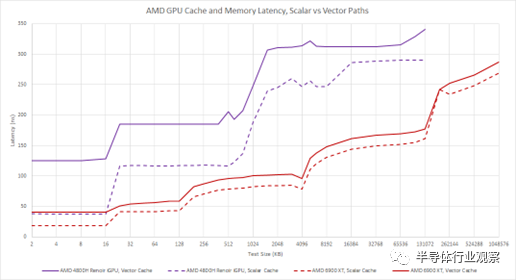
當我們使用矢量加載路徑時,AMD 會遭受很多額外的延遲。AMD 可能在優化標量高速緩存的延遲方面付出了很多努力,并期望延遲敏感的操作發生在那里。矢量路徑針對帶寬而非延遲進行了更多優化,并且延遲懲罰在 GCN 上尤為明顯。RDNA2 是一個顯著的改進。不幸的是,我們沒有在 Raphael 上測試向量緩存延遲,但這里可以預覽 GCN 和 RDNA2 之間的區別:
雖然 iGPU 通常比它們的獨立表親更小并且可以訪問更少的內存帶寬,但它們確實享受與主機 CPU 更快的通信。在某些情況下,通過將相同的物理內存映射到 CPU 和 GPU 的頁表,數據可以在 CPU 和 GPU 之間移動而無需實際復制。在這里,我們正在測試如果需要復制會發生什么。
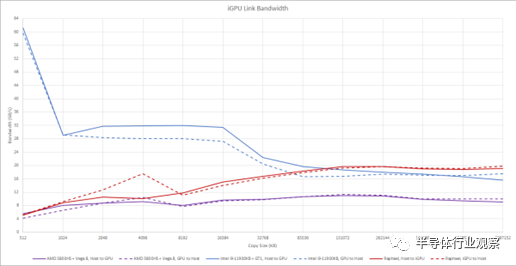
英特爾在 CPU 和 GPU 之間共享一個 L3 緩存,允許在 GPU 和主機之間進行非常快速的復制。AMD 沒有這個,但 AMD iGPU 仍然受益于共享 DDR 總線。DDR4 或 DDR5 可能無法提供 GDDR 設置的帶寬,但通過 DDR 總線復制數據仍然比通過 PCIe 更快。在英特爾的 L3 緩存無濟于事的較大副本大小下,Raphael 更高帶寬的 DDR5 設置開始發揮作用,并讓 Raphael iGPU 超越 Tiger Lake。
Raphael 的 iGPU 是一個非常有趣的外觀,它是一個非常小的 RDNA2 實現。它展示了 RDNA2 如何通過減少 L1 緩存大小來縮小到非常小的設置,同時保留較大 RDNA2 實現的低延遲緩存行為。
編輯:黃飛
?

















 工商網監
工商網監
評論