 電子發燒友App
電子發燒友App


?? ?作者 陳巍 博士:存算一體/GPU架構和AI專家,高級職稱。中關村云計算產業聯盟,中國光學工程學會專家,國際計算機學會(ACM)會員,中國計算機學會(CCF)專業會員。
作者 耿云川 博士:資深SoC設計專家,軟硬件協同設計專家,擅長人工智能加速芯片設計。
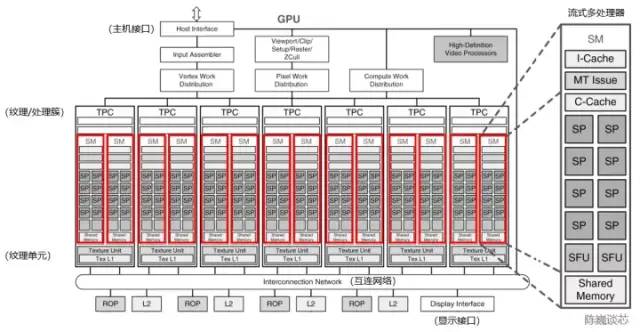
流式多處理器(Stream Multi-processor,SM)是構建整個 GPU的核心模塊(執行整個 Kernel Grid),一個流式多處理器上一般同時運行多個線程塊。每個流式多處理器可以視為具有較小結構的CPU,支持指令并行(多發射)。流式多處理器是線程塊的運行載體,但一般不支持亂序執行。每個流式多處理器上的單個Warp以SIMD方式執行相同指令。
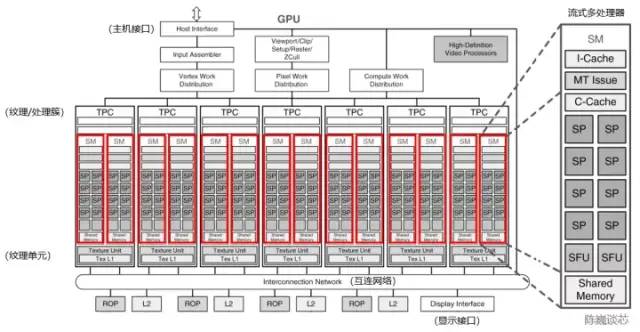
圖 3-1 流式多處理器在GPU架構中的位置(以NVIDIA Tesla架構為例,修改自NVIDIA)
3.1 整體微架構
圖 3-3是流式多處理器(SM,AMD稱之為計算單元)微架構(根據公開文獻和專利信息綜合獲得)。
流式多處理器按照流水線可以分為SIMT前端和SIMD后端。整個流水線處理劃分為六個階段,包括取指、譯碼、發射、操作數傳送、執行與寫回。
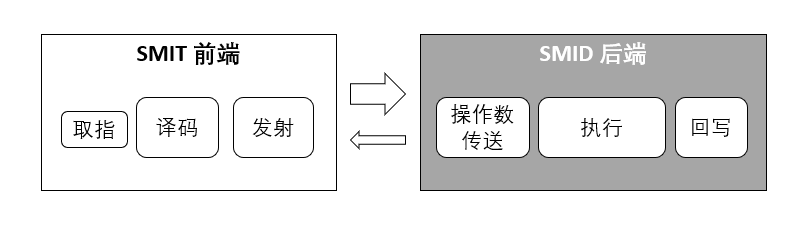
圖 3-2 GPGPU的流式多處理器結構劃分
SIMD即單指令多數據,采用一個控制器來控制多組計算單元(或處理器),同時對一組數據(向量)中的每一個數據分別執行相同的操作從而實現空間并行性計算的技術。
SIMT即單指令多線程,多個線程對不同的數據集執行相同指令。SIMT的的優勢在于無須把數據整理為合適的矢量長度,并且SIMT允許每個線程有不同的邏輯分支。
按照軟件級別,SIMT層面,流式多處理器由線程塊組成,每個線程塊由多個線程束組成;SIMD層面,每個線程束內部在同一時間執行相同指令,對應不同數據,由統一的線程束調度器(Warp scheduler)調度。
一般意義上的CUDA核,對應于流處理器(SP),以計算單元和分發端口為主組成。
線程塊調度程序將線程塊分派給 SIMT 前端,線程在流式多處理器上以Warp為單位并行執行。
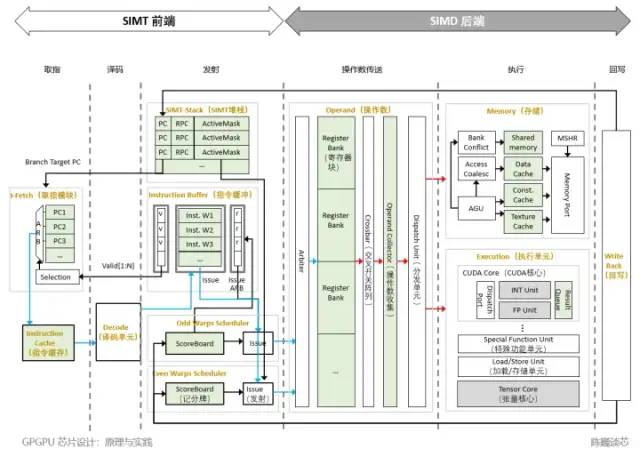
圖 3-3 GPGPU的流式多處理器微架構
流式多處理器中的主要模塊包括:
取指單元(I-Fetch):負責將指令請求發送到指令緩存。并將程序計數器 (PC)指向下一條指令。
指令緩存(I-Cache):如來自取指單元的請求在指令緩存中被命中,則將指令傳送給譯碼單元,否則把請求保存在未命中狀態保持寄存器(MSHR)中。
譯碼單元(Decode):將指令解碼并轉發至I-Buffer。該單元還將源和目標寄存器信息轉發到記分牌,并將指令類型、目標地址(用于分支)和其他控制流相關信息轉發到 SIMT 堆棧。
SIMT 堆棧(SIMT Stack):SIMT堆棧負責管理控制流相關的指令和提供下一程序計數器相關的信息。
記分牌(Scoreboard):用于支持指令級并行。并行執行多條獨立指令時,由記分牌跟蹤掛起的寄存器寫入狀態避免重復寫入。
指令緩沖(I-Buffer):保存所有Warp中解碼后的指令信息。Warp 的循環調度策略決定了指令發射到執行和寫回階段的順序。
后端執行單元:后端執行單元包括CUDA核心(相當于ALU)、特殊功能函數、LD/ST單元、張量核心(Tensor core)。特殊功能單元的數量通常比較少,計算相對復雜且執行速度較慢。(例如,正弦、余弦、倒數、平方根)。
共享存儲:除了寄存器文件,流式多處理器也有共享存儲,用于保存線程塊不同線程經常使用的公共數據,以減少對全局內存的訪問頻率。
3.2 取指與譯碼
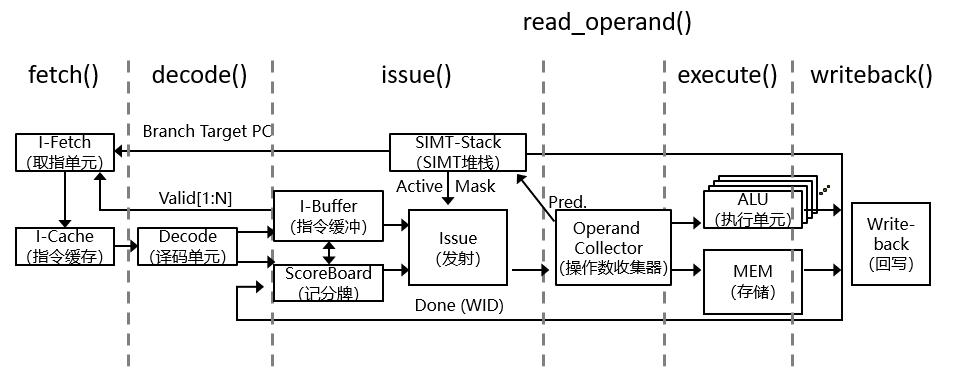
圖 3-4 GPU執行流程(修改自 GPGPU-Sim)
取指-譯碼-執行,是處理器運行指令所遵循的一般周期性操作。
取指一般是指按照當前存儲在程序計數器(Program Counter,PC)中的存儲地址,取出下一條指令,并存儲到指令寄存器中的過程。在取指操作結束時,PC 指向將在下一個周期讀取的下一條指令。
譯碼一般是指將存儲在指令寄存器中的指令解釋為傳輸給執行單元的一系列控制信號。
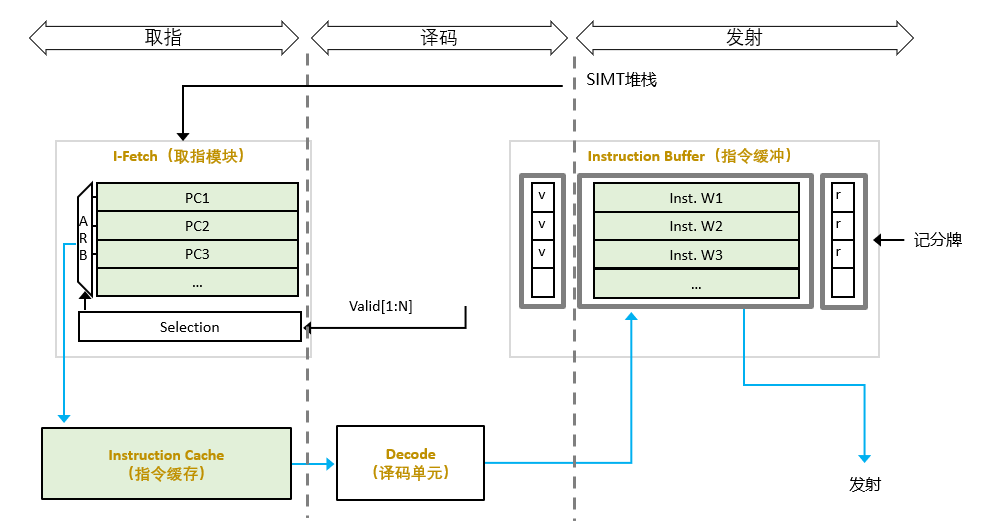
圖 3-5 取指譯碼結構
在GPGPU中,譯碼之后要對指令進行調度,以保證后繼執行單元的充分利用。這一調度通過線程束調度器(Warp Scheduler)實現。
線程束是為了提高效率打包的線程集合(NVIDIA稱之為Warps,AMD稱為Wavefronts)。在每一個循環中的調度單位是Warp,同一個Warp內每個線程在同一時刻執行相同命令。
取指與譯碼操作過程如下:
取指模塊(I-Fetch)根據PC指向的指令,從內存中獲取到相應的指令塊。需要注意的是,在GPGPU中,一般沒有CPU中常見的亂序執行。
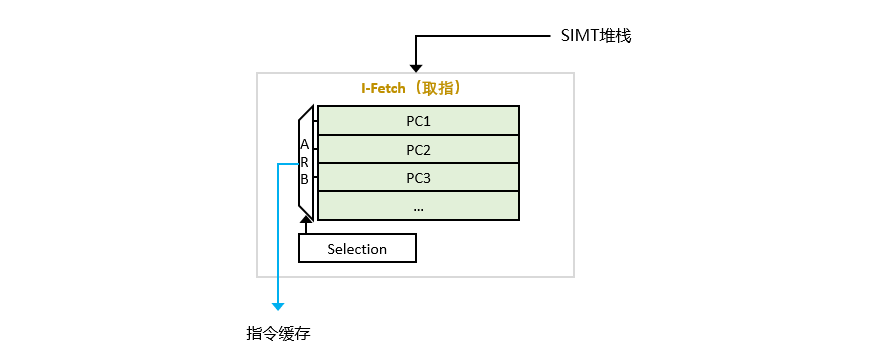
圖 3-5 取指模塊
指令緩存(I-Cache)讀取固定數量的字節(對齊),并將指令位存儲到寄存器中。
對I-Cache的請求會導致命中、未命中或保留失敗(Reservation fail)。保留失敗發生于未命中保持寄存器 (MSHR) 已滿或指令緩存中沒有可替換的區塊。不管命中或者未命中,循環取指都會移向下一Warp。
在命中的情況下,獲取的指令被發送到譯碼階段。在未命中的情況下,指令緩存將生成請求。當接收到未命中響應時,新的指令塊被加載到指令緩存中,然后Warp再次訪問指令緩存。
指令緩沖(I-Buffer)用于從I-Cache中獲取指令后對譯碼后的指令進行緩沖。最近獲取的指令被譯碼器譯碼并存儲在 I-Buffer 中的相應條目中,等待發射。
每個 Warp 都至少對應兩個 I-Buffer。每個 I-Buffer 條目都有一個有效位(Valid)、就緒位(Ready)和一個存于此 Warp 的已解碼的指令。有效位表示在 I-Buffer 中的該已解碼的指令還未發射,而就緒位則表示該Warp的已解碼的指令已準備好發射到執行流水線。
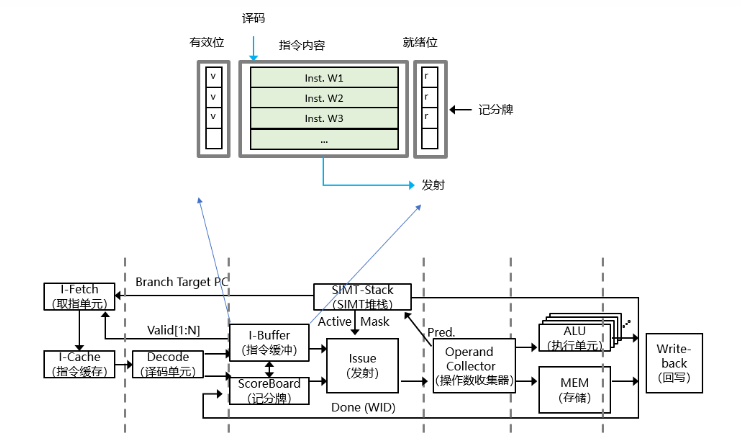
圖 3-4 指令緩沖
當Warp內的I-Buffer 為空時,Warp以循環順序訪問指令緩存。(默認情況下,會獲取兩條連續的指令)這時對應指令在I-Buffer中的有效位被激活,直到該Warp的所有提取的指令都被發送到執行流水線。
當所有線程都已執行,且沒有任何未完成的存儲或對本地寄存器的掛起寫入,則 Warp 完成執行且不再取指。當線程塊中的所有Warp都執行完成且沒有掛起的操作,標記線程塊完成。所有線程塊完成標記為內核已完成。
相對于CPU,GPU的前端一般沒有亂序發射,每個核心的尺寸就可以更小,算力更密集。
3.3 發射
發射是指令就緒后,從指令緩沖進入到執行單元的過程。
在(譯碼后的)指令發射階段,指令循環仲裁選擇一個Warp,將I-Buffer中的發射到流水線的后級,且每個周期可從同一Warp發射多條指令。
所發射的有效指令應符合以下條件:
在Warp里未被設置為屏障等待狀態;
在I-Buffer中已被設置為有效指令(有效位被置為1);
已通過計分板(Scoreboard)檢查;
指令流水線的操作數訪問階段處于有效狀態。
在GPU中,不同的線程束的不同指令,經由SIMT堆棧和線程束調度,選擇合適的就緒的指令發射。
在發射階段,存儲相關指令(Load、Store等)被發送至存儲流水線進行相關存儲操作。其他指令被發送至后級SP(流處理器)進行相關計算。
3.3.1 SIMT堆棧
SIMT堆棧用于在Warp前處理SIMT架構的分支分化的執行。一般采用后支配堆棧重收斂機制來減少分支分化對計算效率的負面影響。
SIMT 堆棧的條目代表不同的分化級別,每個條目存儲新分支的目標 PC、后繼的直接主要再收斂 PC 和分布到該分支的線程的活動掩碼。在每個新的分化分支,一個新條目被推到棧頂;而當 Warp 到達其再收斂點時,棧頂條目則被彈出。每個 Warp 的 SIMT 堆棧在該 Warp 的每個指令發出后更新。
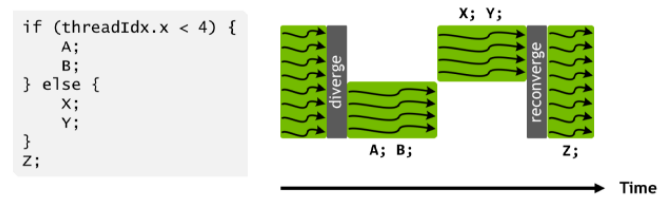
線程束分化
從功能角度來看,雖然SIMT架構下每個線程獨立執行,但在實際的計算過程中會遇到一些分支的處理,即有些線程執行一個分支,而另外的線程則執行其他分支。如果在同一個Warp內不同的線程執行不同的分支,就會造成線程束分化,導致后繼SIMD計算的效率降低。因此應盡量避免線程束的分化。
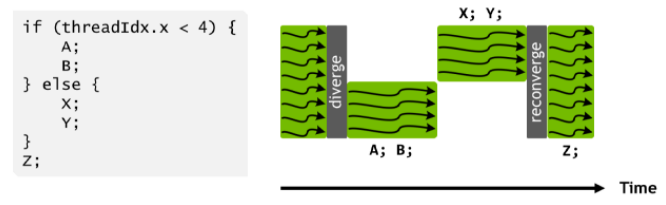
圖 3-6 線程束分化與重聚合
SIMT堆棧功能
SIMT堆棧模塊可有效改善線程束分化引起的GPGPU執行單元利用率下降的問題。
SIMT堆棧重點解決:
控制流嵌套問題(Nested Control Flow)
在控制流嵌套中,一個分支嚴重地依賴另一個分支,這極大影響了線程的獨立性。
如何跳過計算過程(Skip Computation)
由于線程束分支的存在,導致同一個Warp內的有些線程并不必要執行某些計算指令。
3) SIMT掩碼
SIMT堆棧中使用了SIMT掩碼(SIMT Mask)來處理線程束分化問題,以下例來說明掩碼如何控制整個Warp的執行。
4)?SIMT 掩碼引起的死鎖問題
SIMT 掩碼可以解決Warp內分支執行問題,通過串行執行完畢分支之后,線程在Reconverge Point(重合點)又重新聚合在一起以便最大提高其并行能力。
但對于一個程序來說,如果出現分支就表明每個分支的指令和處理是不一致的,容易使一些共享數據失去一致性。如果在同一個Warp內如果存在分支,則線程之間可能不能夠交互或者進行數據交換,在一些實際算法中可能使用鎖定(Lock)機制來進行數據交換。但掩碼恰恰可能因為調度失衡,造成鎖定一直不能被解除,造成死鎖問題。
5) GPGPU解決死鎖的方法
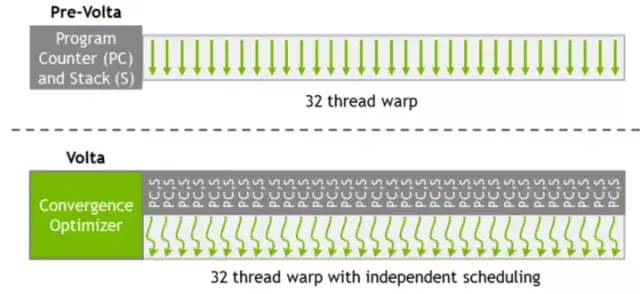
圖 3-8 V100 Warp調度對比圖[2]
解決死鎖的方法如下:
NVIDIA為V100 中Warp內的每個線程都分配了一個PC指針和堆棧,將PC指針的顆粒度細化到每一個線程中去,保障數據交換避免死鎖。(圖3-5)
為避免細粒度的PC指針和堆棧與GPU的SIMT執行模型產生沖突,硬件仍以Warp為單位來進行線程調度。
使用了Schedule Optimizer(調度優化器)硬件模塊來決定哪些線程可以在一個Warp內進行調度,將相同的指令重新進行組織排布到一個Warp內,并執行SIMD模型,以保證利用效率最大化[2]。
3.3.2 線程束調度與記分牌
進行線程束(Warp)調度的目的是充分利用內存等待時間,選擇合適的線程束來發射,提升執行單元計算效率。
在理想的計算情況下,GPU內每個Warp內的線程訪問內存延遲都相等,那么可以通過在Warp內不斷切換線程來隱藏內存訪問的延遲。
GPU將不同類型的指令分配給不同的單元執行,LD/ST硬件單元用于讀取內存,而執行計算指令可能使用INT32或者FP32硬件單元,且不同硬件單元的執行周期數一般不同。這樣,在同一個Warp內,執行的內存讀取指令可以采用異步執行的方式,即在讀取內存等待期間,下一刻切換線程其他指令做并行執行,使得GPU可以一邊進行讀取內存指令,一邊執行計算指令動作,通過循環調用(Round Robin)隱藏內存延遲問題,提升計算效率。
在理想狀態下,可以通過這種循環調用方式完全隱藏掉內存延遲。但在實際計算流程中,內存延遲還取決于內核訪問的內存位置,以及每個線程對內存的訪問數量。
內存延遲問題影響著Warp調度,需要通過合理的Warp調度來隱藏掉內存延遲問題。
1) 指令順序調整的原因
在同一個Warp的單個線程中,調整發送到ALU將要執行的指令順序,可以隱藏掉一部分內存延遲問題。例如讀取指令和加法指令使用的是不同的硬件單元,在第一個時鐘周期執行內存讀取指令之后,下一個時鐘周期不必等待讀取內存指令,而是可以直接執行加法指令,從而實現一邊計算一邊讀取,來提高整個運行效率。
但在實際情況中,后一個指令有可能是依賴于前一個指令的讀取結果。要解決該問題就需要GPU提前對指令之間的依賴關系進行預測,解析出指令之間的獨立性和依賴關系。
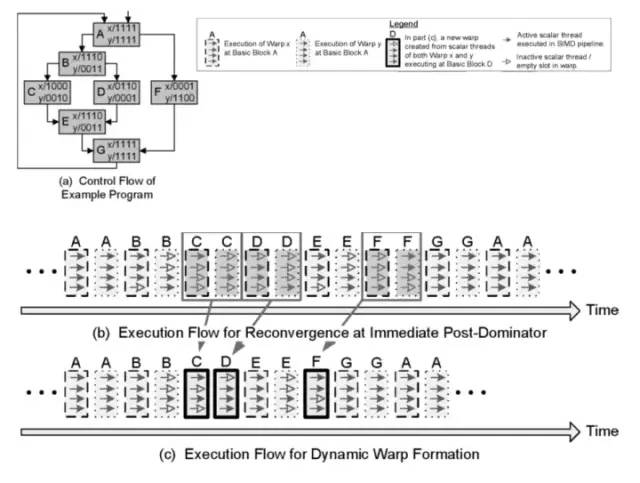
圖 3-11動態線程束示例(來源:WILSON W. L. FUNG等)
2) 記分牌與指令順序調整的方法
GPU在這里參考了CPU設計,為了解析指令之間的獨立性,采用順序記分牌(In-Order Scoreboard)。
對于單線程束情況,
每個寄存器在記分牌中都對應一個標志位,用于表示該寄存器是否已被寫入數據,如果置1則表示該寄存器已經被寫入。
此時如果另外一個指令想要讀或者寫該寄存器,則會處于一直等待狀態,一直到該寄存器的標志位被清零(表明之前寫寄存器操作完成)。這樣就可以阻止Read-After-Write和Write-After-Write的問題。
當順序記分牌和順序指令(In-Order Instruction)結合時,能避免Write-After-Read的問題。
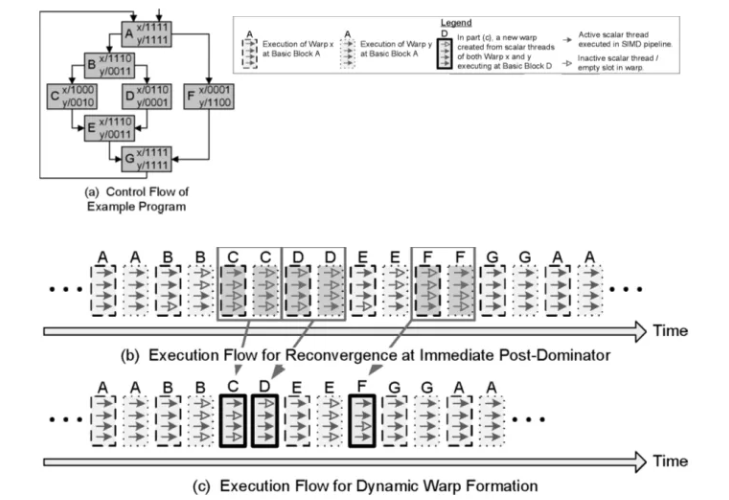
圖 3-11數據沖突與流水線結構相關
對于多線程束情況,將上述方法應用到GPU時,還需要解決兩個問題:
由于有大量寄存器GPU,在每組寄存器中增加一個標志位將需要占用更多額外的寄存器。
在GPU中,一般會有很多個線程同時執行同一指令,一旦其執行的指令被打斷,會有很多線程同時訪問Scoreboard造成讀取阻塞。
對于多線程束情況,可通過動態記分牌解決上面的兩個問題:
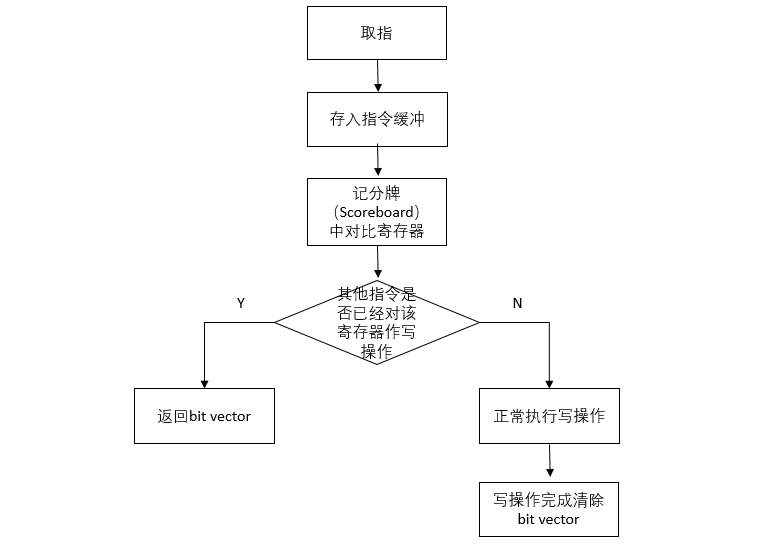
圖 3-9 記分牌Entry流程
為每個Warp創建幾個入口(Entry),每個入口與一個即將被寫但操作尚未完成的寄存器相對應。記分牌在指令進入指令緩沖區(Instruction buffer,I-Buffer)和寫操作完成結果存入Register File時能被訪問(圖3-6)
當一個指令從內存中讀取出來放入到I-Buffer時,將該指令中的源寄存器和目的寄存器與Entry做比較,看是否有其他指令集已經對該寄存器在做寫操作,如果有則返回一個bit Vector,與該寄存器一起寫入到I-Buffer中。如果該指令集的寫操作完成了,將會刷新I-Buffer中的該指令集寄存器的bit Vector,將bit Vector清除掉。
如果一個指令做寫操作,并需要將該寄存器放入Entry中,但是此Entry已經滿了,那么該指令將會一直等待,或者被丟棄過一定時鐘周期后被重新獲取再次查看Entry是否滿[3]。
編輯:黃飛
?










 工商網監
工商網監
評論