 電子發燒友App
電子發燒友App


一、引言
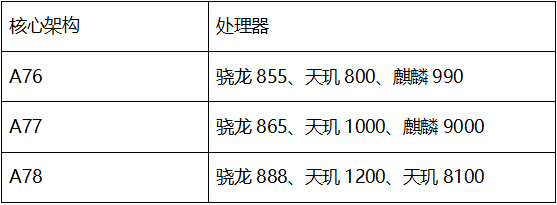
伴隨智能手機的高速發展,移動處理器架構設計廠商ARM公司幾乎每年都更新CPU的核心架構。從2018至2020年,ARM公司基于ARMv8架構推出了三代Cortex-A76、Cortex-A77、Cortex-A78經典CPU核心架構。基于這幾代CPU架構,芯片設計廠商也設計了多款性能優秀的處理器產品。本文從A76微架構開始學習,通過對比每一代的變化,讓讀者了解處理器微架構關鍵知識。下表給出了一些基于這三代ARM處理器架構的典型處理器產品。
二、從A76開始了解ARM微架構
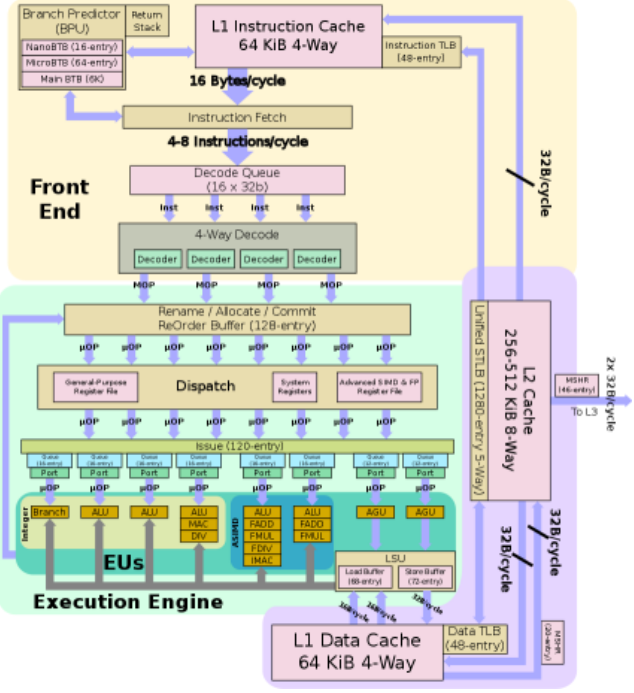
從ARM的A76開始,網絡上可以查詢到較多資料,例如我們可以從wikichip網站(en.wikichip.org)獲取到A76的完整微架構框圖。
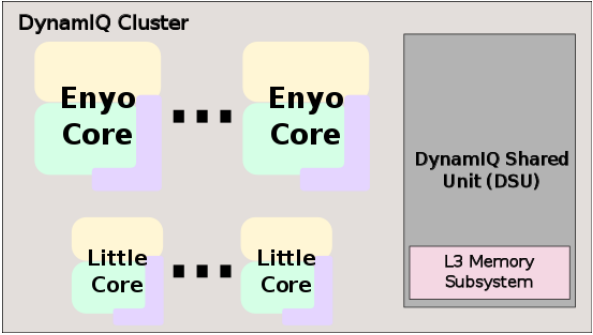
1. DSU(DynamIQ Shared Unit)
從A75開始,ARM提出了一個新的多核心管理系統單元,叫做DSU。通過DSU模塊,CPU設計者可以隨意擺放不同架構的核心并共享L3緩存,減少不同架構核心直接傳遞數據損耗。在DSU架構之前,每個Cluster需要擺放同架構CPU,如將4個A73處理器放在一個Cluster中,將4個A53放在另外一個Cluster中,這兩個Cluster的數據相互訪問會有一定的連接損耗。
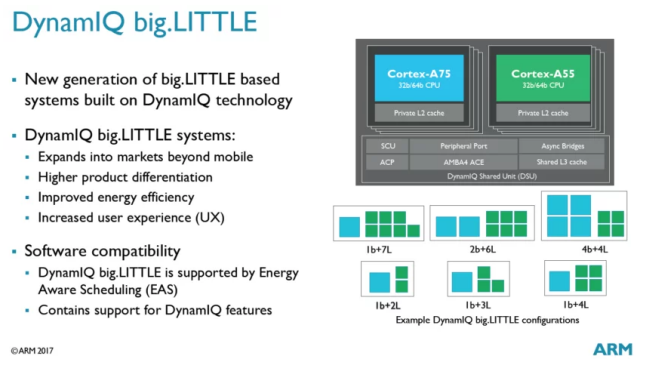
利用DSU模塊,開發者可以隨意設計CPU的組合,例如圖中1大+7小,2大+6小,4大+4小,1大+2小,1大+3小,1大+4小等等組合。
2.?性能功耗優化
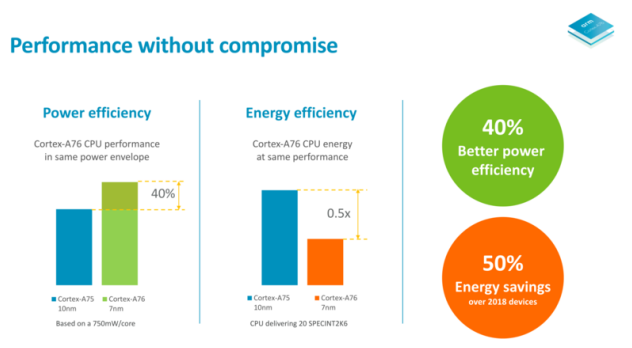
架構和工藝具有一定的關聯性,如A76架構設計可采用7nm工藝,根據ARM數據,基于7nm的A76比基于10nm工藝的A75,性能可提升40%,或同性能下能耗降低50%。可見A76相比上一代的A75的提升較大,后面我們會詳細了解架構上差異點。
3. 三級緩存設計
A76采用三級緩存機制,其中:
L1是核心獨有緩存,具有獨立的64KB指令Cache(ICache)和64KB數據Cache(DCache);
L2是核心獨有緩存,可以配置成256KB或者512KB(加錢);
L3是核間共享緩存,在DSU內部,可以配置成2MB或者4MB。
4.?分支預測單元(BPU)
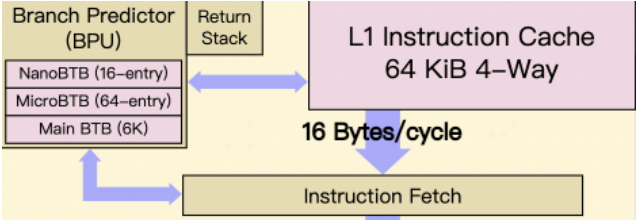
多級流水線系統中,在執行分支判斷指令時,系統如果不知道下面走哪一條分支,需要等到分支執行出結果才可以再獲取正確的指令。為了提升流水線性能,現代處理器中提供了一個分支預測單元(BPU),用來預測常用路徑,并提前進行指令預取,確保流水線被填充完整。
A76的BPU和指令Fetch單元獨立,BPU可以同時和Fetch單元工作,提前推測并獲取分支后指令,降低分支預測的延遲。
5. 前端設計(Front-end)
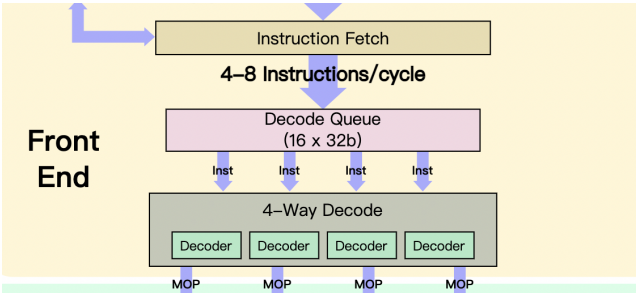
指令預取后進入一個解碼隊列,A76提供了4路decoder,相比A75增加了一路decoder單元,這是性能提升的一個要素。
6. ROB模塊設計
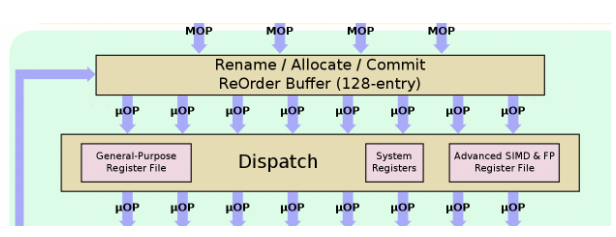
經過譯碼的指令叫做MOP(Macro-Operation),MOP不是實際執行的指令,最終送到執行單元的指令叫做uOP(Micro-Operation)。MOP比uOP稍微復雜一些,可能是多條uOP的組合指令,通過后端單元的拆解,可以把MOP分解成處理器可以執行的最基礎指令uOP,uOP的指令數量約比MOP多20%。
ROB(ReOrder-Buffer)模塊提供了128個entry,用來將指令進行重新排序,盡可能填充流水線,這里可以看到A76設計的輸入是4路MOP,輸出是8路uOP。
7. 執行單元 (Execution Engine)
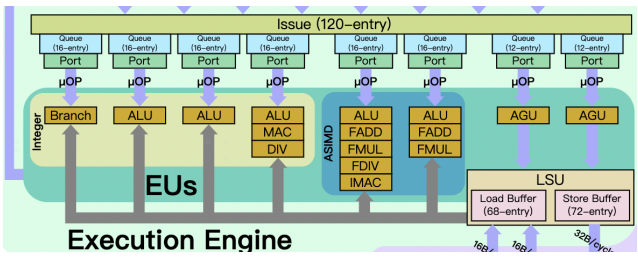
Dispatch單元將uOP指令發射到執行單元(Issue),執行單元提供了120個entry,分成三類:整型、浮點和讀寫,整型部分包括了1個分支單元,2個基礎ALU單元,1個復合ALU單元;浮點部分提供了2個128bit的高級SIMD指令單元;讀寫部分則提供了2個AGU(Adress Generation Unit)地址單元。
8. LSU(Load Store Unit)設計
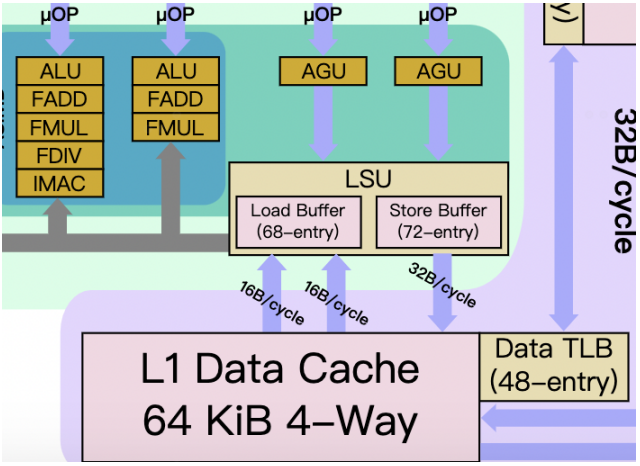
LSU模塊和執行單元的2個AGU相連接,同時連接64KB的L1數據緩存(DCache),并提供2個16B/cycle的load端口和1個32B/cycle的store端口。
9. 小結
至此,我們從取指、譯碼、指令分派、指令發射、指令執行到數據讀寫,簡略了解了A76處理器的微架構,下一節我們通過對比A77和A76架構的差異,進一步了解ARM微架構設計的步伐。
三、A77微架構和A76對比
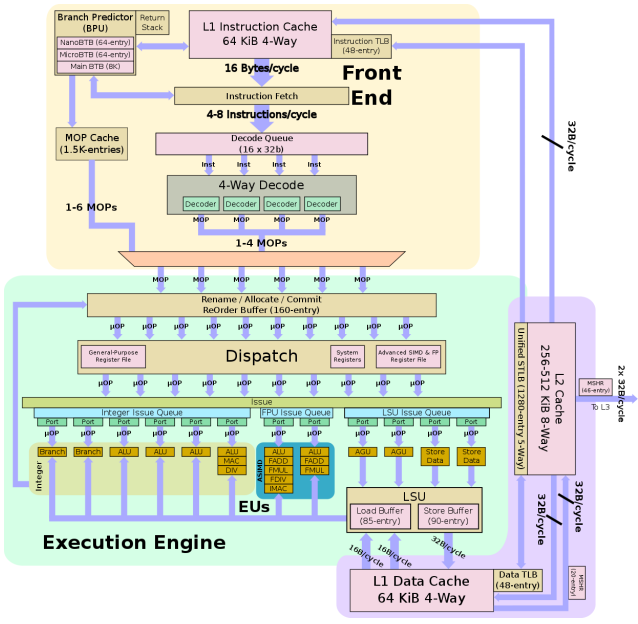
A77微架構圖,大家且看且珍惜,因為自A77之后的產品在網絡上很難找到完整的微架構圖了。
1. 性能提升
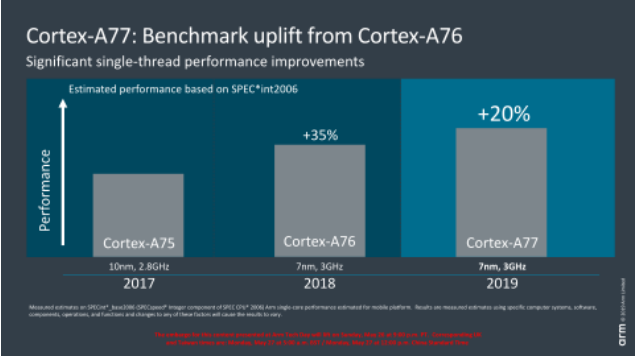
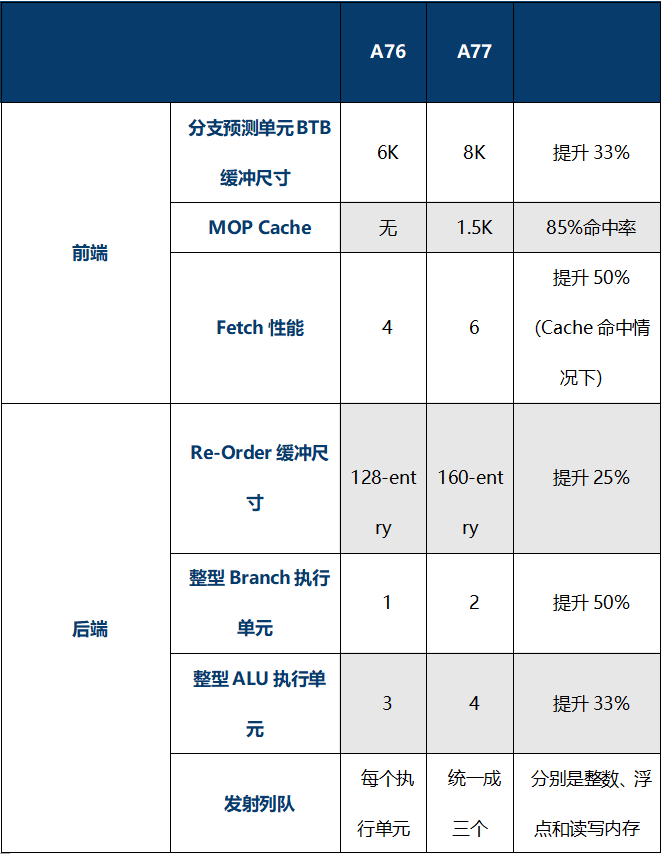
ARM資料顯示同樣是7nm工藝3GHz的條件下,A77的性能可以比A76提升20%,注意這里面標注是單線程性能提升,后面我們可以從架構升級中推測性能提升的原因。 ? ?
2. L0緩存(MOP Cache)
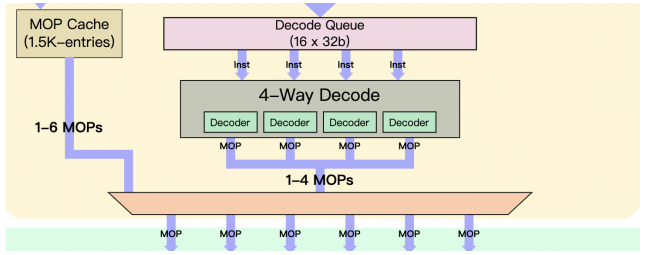
A77新引入了MOP Cache模塊,這個模塊并不是ARM的創新設計,在PC處理器上已經有了,例如Intel在早期的酷睿Sandy Bridge處理器中就加入了uOP Cache模塊。
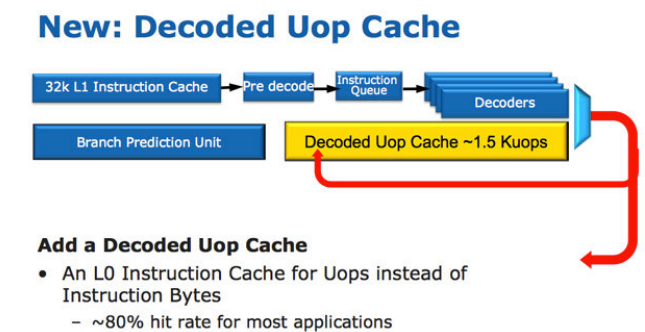
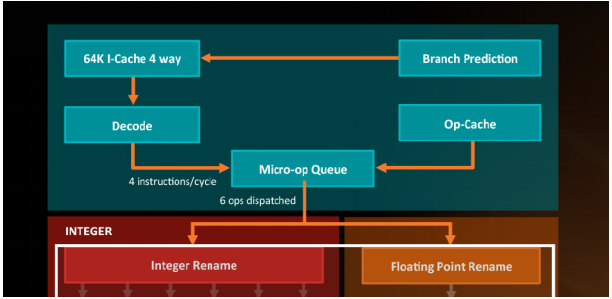
此外AMD的Zen架構也有MOP緩存模塊。
MOP Cache主要用做L0級別緩存,存儲譯碼過的MOP指令。MOP Cache的好處是如果在里面找到需要的指令,前面的電路模塊都可以暫時由MOP Cache來替代,可以節省功耗提升性能。ARM數據顯示這個MOP Cache的命中率有85%,可見是A77的一個非常大的改進。
繼續看下MOP Cache的尺寸,ARM給的尺寸數據是1.5K而不是1.5KB,單位不是Byte而是條,考慮到ARM常規decoded出的機器碼是32位寬(Aarch64也是32位寬,當然也有個別64位寬指令),推測這個L0 Cache的大小應該是6KB左右(和Intel的sandy bridge時一樣)。
移動處理器領域引入L0,ARM并不是首家,早在高通的Snapdragon S4時代就在Krait核心中引入了L0 cache。根據數據顯示1.5K的Cache就可以達到80-85%的命中率,再增加Cache,提升命中率的邊際效應會越來越明顯。
3. 前端設計(Front-End)
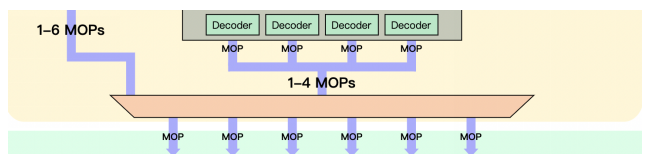
A77相對于A76的另一個重要變化是產生MOP指令的能力從原來的每周期4個提升到最多6個,但是decode的能力還是保持4個沒有變化。可以對比下整體上fetch和decode的基本架構和A76沒有太大變化,MOP提升的主要原因是新加入的MOP Cache提供的。如果MOP Cache命中,可以繞過decode模塊最多一次取6條MOP指令,如果不命中回到decode模塊還是一次4條,L0 Cache和Decode進行了很好的補充,讓一周期可以提供更多的MOP指令。
4. ROB模塊設計

A77相對A76在執行單元上提升了重排序緩沖的大小(ReOrder-Buffer),還記得A76是128-entry,A77提升了25%到160-entry。
另外可以看到輸入是6條MOP,輸出提升到了10條uOP,對比A76則是8條。據說其他廠商基于ARM定制內核時會修改這個部分,隨著ARM內核逐步吸收這些優秀的設計,定制ARM內核的空間和收益會越來越小 。
5. 執行單元
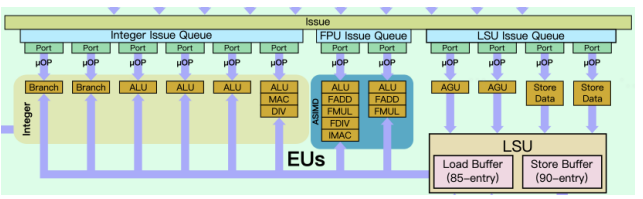
A77相比A76在執行單元也有比較大的改變:新增加了一路分支單元,將分支預測的帶寬提升了一倍;新增了第四個基礎整型ALU單元,這個單元可以用一個周期執行簡單的算術運算或二個周期執行更復雜運算。A77一共4個整型ALU,其中3個是基礎整型ALU單元,還有一個是復雜整型ALU單元,可以執行更復雜的計算(例如MAC乘加,DIV除法),A76也有這個復雜ALU單元。在整型執行單元上,A77相對A76提升是比較大的,從4個提升到6個,有50%的提升。
此外,還A76的每個執行單元都有獨立的發射列隊,A77則進行了一定程度的優化,將發射列隊(issue queue)統一成三個,整型、浮點和讀寫發射列隊,由于A77的執行單元多,將發射列隊統一進行管理和分配,可以進一步提升執行效率。
6. LSU設計
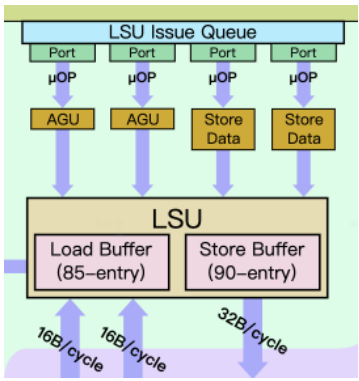
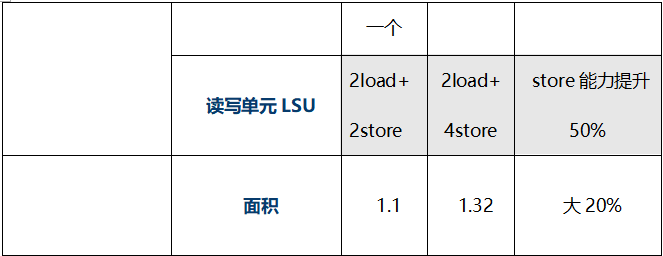
A77在LoadStore單元上有兩個獨立的地址生成單元AGU,這和A76是一樣的。不同的地方是A77額外增加了兩路Store端口,等于將Store的帶寬增加了一倍。同時這四路LSU單元也共享一個發射隊列,ARM宣稱這樣可以提升25%的內存并發讀寫性能。
再來看一下LSU單元,更寬的執行單元需要有更寬的LSU支持,A77增大了LSU的load和store buffer,同時可以支持85級深度load 操作和90級深度store操作,總共支持同時175個內存操作,稍高于指令操作的寬度160,相比A76的LSU深度140,提升了25%。
7. 小結
最后整理了一個更詳細的表格來對比A77和A76,A77是ARMv8系列中非常成功的一代,基于A77,產生了如麒麟9000、驍龍865這樣經典的產品。
四、A78微架構和A77對比
1. 性能功耗優化
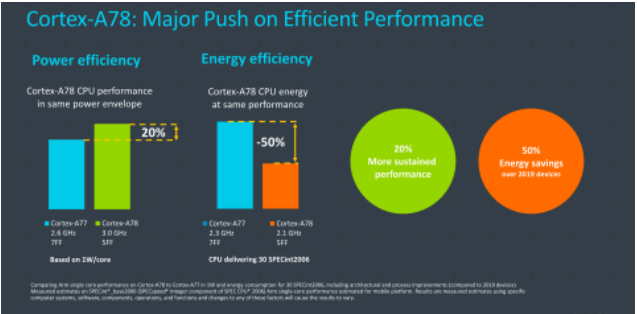
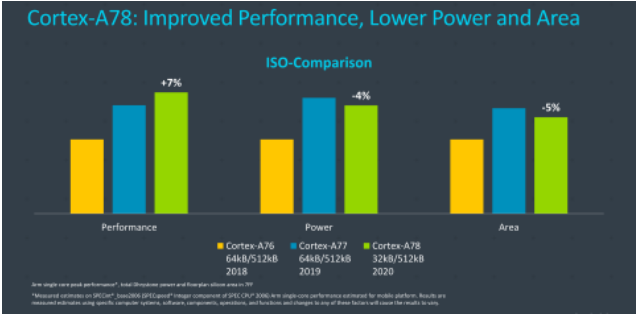
2020年,ARM更新了代號Hercules的A78新架構,也是ARMv8體系中最后一代中核架構。ARM宣傳這一代是“持續的性能功耗領先”,圖中看到性能提升了20%,工藝從7nm提升到5nm,注意性能提升包含了頻率的15%提升,架構的性能提升ARM估計在7%左右。得益于工藝進化到5nm,同樣性能,功耗可以比A77降低50%(2.1GHz相當于A77的2.3GHz)。從第二張圖可以看出,A78這一代的主要設計目標是小幅度提升性能,提升能效并減少芯片面積。
2. A78微架構的一些特點
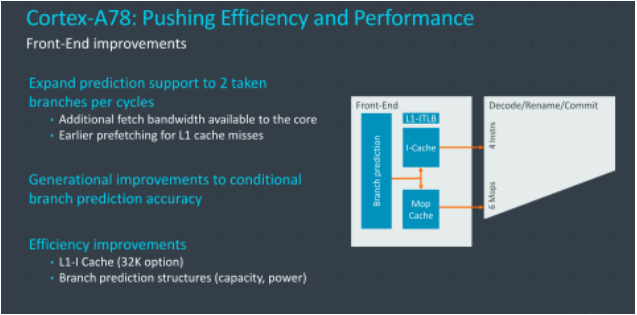
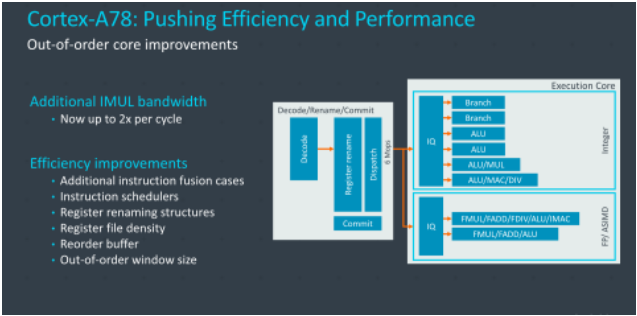

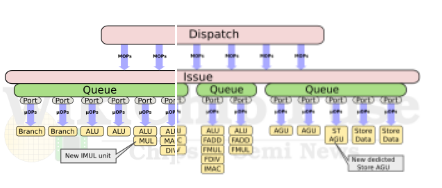
1、L1緩存:ARM提供了32KB緩存的選擇,讓一些注重成本和芯片面積的廠商可以選擇更低的數據和指令緩存,默認是64KB。
2、分支預測:分支預測的帶寬相對A77提升了1倍。
3、執行單元:增加了一個MUL單元,允許一個周期進行2個整型的乘法運算(A77是一周期1個)。增加了一個用于Store的AGU單元,Store的能力從16B/cycle提升到32B/cycle。
A78是ARMv8架構最后一代產品,主要是對前面幾代微架構的優化,可謂ARMv8架構的守門員了。
五、總結
A78是ARMv8架構的最后一代產品,智能手機依然在高速發展并快速更新產品,ARM處理器的架構也在持續迭代和更新。2020年,ARM公司提出了對廠商定制高性能核心的計劃,并推出了面積更大性能更強的Cortex-X系列核心。2021年,ARM公司推出了全新的ARMv9架構,目前已經有A710、A715等產品接替A78的路線。限于篇幅限制,后續我會和大家一起繼續學習X系列和ARMv9架構的相關內容。
審核編輯:劉清









 工商網監
工商網監
評論