 電子發(fā)燒友App
電子發(fā)燒友App


CPU的內(nèi)部結(jié)構(gòu)
ALU(算術(shù)邏輯單元)、控制單元、寄存器、Cache(緩存)
存儲(chǔ)器
易失性存儲(chǔ)器:
一般用作計(jì)算機(jī)內(nèi)部存儲(chǔ)所以被稱為內(nèi)存
特點(diǎn):1,支持隨機(jī)訪問;2,掉電數(shù)據(jù)會(huì)丟失
非易失性存儲(chǔ)器:
磁盤、flash等
一般用作計(jì)算機(jī)外部存儲(chǔ)所以被稱為外存
特點(diǎn):1,不支持隨機(jī)訪問;2,掉電數(shù)據(jù)不丟失;3,讀寫速度不如內(nèi)存。
計(jì)算機(jī)系統(tǒng)一般會(huì)采用內(nèi)存+外存的存儲(chǔ)結(jié)構(gòu):程序指令保存外存,當(dāng)程序運(yùn)行時(shí),相應(yīng)的程序會(huì)首先加載到內(nèi)存,然后CPU從內(nèi)存一條一條取指令、翻譯指令和運(yùn)行指令。
計(jì)算機(jī)架構(gòu)
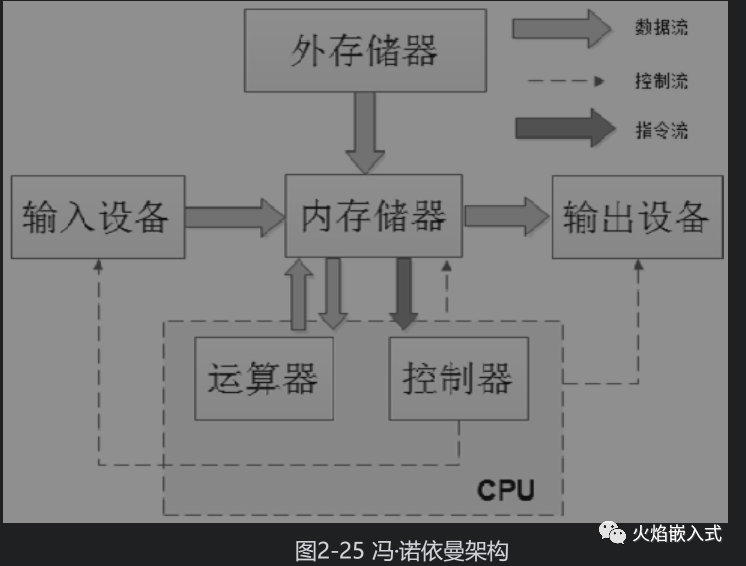
馮.諾伊曼架構(gòu)
指令和數(shù)據(jù)存放到同一個(gè)存儲(chǔ)器的不同的物理地址上。結(jié)構(gòu)簡(jiǎn)單,工程容易實(shí)現(xiàn)。
典型:x86、ARM7、MIPS等
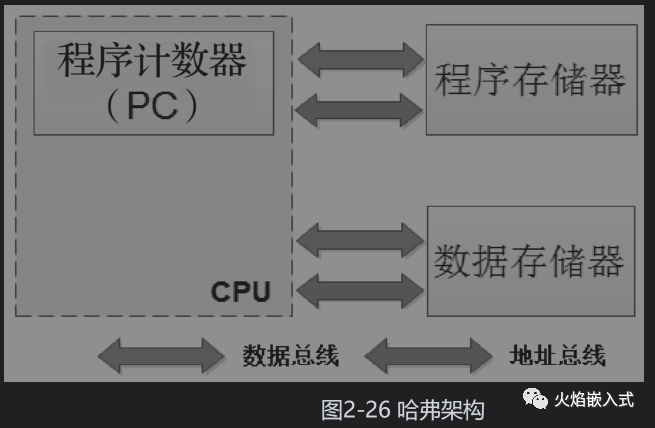
哈弗架構(gòu)
指令和數(shù)據(jù)被分開獨(dú)立存儲(chǔ),它們分別被存放到程序存儲(chǔ)器和數(shù)據(jù)存儲(chǔ)器。每個(gè)存儲(chǔ)器都獨(dú)立編址,獨(dú)立訪問,而且指令和數(shù)據(jù)可以在一個(gè)時(shí)鐘周期內(nèi)并行訪問。使用哈弗架構(gòu)的處理器運(yùn)行效率更高,但缺點(diǎn)是CPU實(shí)現(xiàn)會(huì)更加復(fù)雜。
典型:8051系列的單片機(jī)
混合架構(gòu)
CPU工作頻率越來越高RAM跟不上CPU運(yùn)行速度,為提高計(jì)算機(jī)的整體效率引入Cache機(jī)制:指令Cache和數(shù)據(jù)Cache。
RAM一次將向Cache傳送一批數(shù)據(jù),CPU到Cache中取指令和數(shù)據(jù),如果cpu發(fā)現(xiàn)Cache中沒有在去RAM中讀取。
CPU寫數(shù)據(jù)時(shí)會(huì)先寫入Cache中,等待時(shí)機(jī)將Cache中數(shù)據(jù)刷新到RAM中。
CPU性能提升:Cache
Cache本質(zhì)是SRAM。Cache運(yùn)行速度介于CPU和DRAM之間,插入在CPU和內(nèi)存之間,用于解決兩者速度不匹配問題。
Cahce存儲(chǔ)的內(nèi)存地址,一般經(jīng)過地址映射轉(zhuǎn)化為已存儲(chǔ)和檢索的形式。
CPU為進(jìn)一步提高性能大多數(shù)采取多級(jí)Cache:一級(jí)Cache、二級(jí)Cache、甚至三級(jí)Cache。
為何有些處理器沒有Cache?
C51、Corttex-M0等MCU的處理器沒有Cache。
原因:
1,處理器是低功耗、低成本。增加cache會(huì)增加功耗和成本。
2,處理器自身的工作頻率不高。
3,Cache無法保證實(shí)時(shí)性。嵌入式實(shí)時(shí)控制場(chǎng)景無法接受。
CPU性能提升:流水線
一條指令執(zhí)行分為三個(gè)步驟:取指令、翻譯指令、執(zhí)行指令
CPU內(nèi)部三個(gè)單元:取指單元、譯碼單元、執(zhí)行單元
流水線:
第一個(gè)時(shí)鐘周期取指單元工作,取指令1,其余空閑狀態(tài)。
第二個(gè)時(shí)鐘周期取指單元工作取指令2,譯碼單元也開始工作,開始翻譯指令1。
第三個(gè)時(shí)鐘周期取值單元工作取指令3,譯碼單元開始工作,翻譯指令2,執(zhí)行單元開始執(zhí)行指令1.
超流水線技術(shù)
五級(jí)以上的流水線被稱為超流水線。高性能處理器一般采用這種流水線。
Intel的i7處理器采用16級(jí)流水線,AMD的速龍64采用20級(jí)流水線,Intel的第三代奔騰四處理器有31級(jí),被稱為史上最長(zhǎng)的流水線。
執(zhí)行的程序指令如果是順序結(jié)構(gòu)的,沒有中斷或跳轉(zhuǎn),流水線確實(shí)可以提高執(zhí)行效率。但是當(dāng)程序指令中存在跳轉(zhuǎn)、分支結(jié)構(gòu)時(shí),下面預(yù)取的指令可能就要全部丟掉了,需要到跳轉(zhuǎn)的地方重新取指令執(zhí)行。
流水線冒險(xiǎn)
流水線越深,一旦預(yù)取指令失敗,浪費(fèi)和損失就會(huì)越嚴(yán)重,因?yàn)榱魉€中預(yù)取的幾十條指令可能都要丟棄掉,此時(shí)流水線就發(fā)生了停頓,無法按照預(yù)期繼續(xù)執(zhí)行,這種情況我們一般稱為流水線冒險(xiǎn)(hazard)。
結(jié)構(gòu)冒險(xiǎn):所需要的硬件正在為前面的指令工作。
數(shù)據(jù)冒險(xiǎn):當(dāng)前指令需要前面指令的運(yùn)算數(shù)據(jù)才能執(zhí)行。
控制冒險(xiǎn):需根據(jù)之前指令的執(zhí)行結(jié)果決定下一步的行為。
多核CPU
單核的瓶頸:
在相同的半導(dǎo)體工藝制程下,芯片的面積越大,芯片的良品率就越低,芯片的成本就會(huì)越高,功耗也會(huì)越大。CPU性能提升受限。
單核處理器主頻每升1GHz,平均就要增加25W的功率。通過增加處理器核數(shù),將大量繁重的計(jì)算任務(wù)分配到更多的Core上,可以提高處理器的整體性能。而根據(jù)阿姆達(dá)爾定律,程序中并行代碼的比例又決定了增加處理器核數(shù)所能帶來的性能提升上限,CPU的核數(shù)不一定越多越好,任務(wù)分配不當(dāng)就可能造成“一核有難,八核圍觀”的尷尬場(chǎng)面
異構(gòu)計(jì)算機(jī)
異構(gòu)計(jì)算機(jī):在SoC芯片內(nèi)部集成不同的架構(gòu)Core,如DSP、GPU、NPU、TPU等不同的架構(gòu)處理單元。
GPU(Graphic Process Unit,圖形處理單元)主要用來處理圖像數(shù)據(jù)。
GPU在浮點(diǎn)運(yùn)算、大數(shù)據(jù)處理、密碼破解、人工智能等領(lǐng)域都是一把好手,比CPU更適合做大規(guī)模并行的數(shù)據(jù)運(yùn)算
DSP(Digital Signal Processing,數(shù)字信號(hào)處理器),主要用在音頻信號(hào)處理和通信領(lǐng)域。如手機(jī)的基帶信號(hào)處理
FPGA(Field Programmable Gate Array,現(xiàn)場(chǎng)可編程門陣列)在專用集成電路(Application Specific Integrated Circuit,ASIC)領(lǐng)域中是以一種半定制電路的形式出現(xiàn)的。FPGA與DSP相比,開發(fā)更具有靈活性,但成本也隨之上升,上手也比較難,因此主要用在一些軍事設(shè)備、高端電子設(shè)備、高速信號(hào)采集和圖像處理領(lǐng)域。
TPU(Tensor Processing Unit,張量處理器)是Google公司為提高深層網(wǎng)絡(luò)的運(yùn)算能力而專門研發(fā)的一款A(yù)SIC芯片。
NPU(Neural Network Processing Unit,神經(jīng)網(wǎng)絡(luò)處理器)是面向人工智能領(lǐng)域,基于神經(jīng)網(wǎng)絡(luò)算法,進(jìn)行硬件加速的處理器統(tǒng)稱。NPU使用電路來模擬人類的神經(jīng)元和突觸結(jié)構(gòu),用自己指令集中的專有指令直接處理大規(guī)模的神經(jīng)元和突觸。
地址與總線
地址的本質(zhì)其實(shí)就是由CPU管腳發(fā)出的一組地址控制信號(hào)。因?yàn)檫@些信號(hào)是由CPU管腳直接發(fā)出的,因此也被稱為物理地址。地址信號(hào)線的位數(shù)決定了尋址空間的大小,32位計(jì)算機(jī)尋址空間是4G。
總線
總線是各種數(shù)字信號(hào)的集合,包括地址信號(hào)、數(shù)據(jù)信號(hào)、控制信號(hào)等。CPU通過總線與內(nèi)存RAM、外部設(shè)備相連。
總線編址方式
計(jì)算機(jī)如何給設(shè)備分配地址的?
兩種編址方式:
統(tǒng)一編址:內(nèi)存RAM和外部設(shè)備共享CPU的尋址空間。ARM、MIPS架構(gòu)采用這種方式編址。
獨(dú)立編址:內(nèi)存RAM和外部設(shè)備分別占用不同的地址空間。例如,X86架構(gòu)CPU。
指令集與微架構(gòu)
圖靈原型機(jī)基本思想:任何復(fù)雜的運(yùn)算都可以分解為有限個(gè)基本指令的組合來完成。
不同架構(gòu)的處理器支持的指令類型不同,CPU支持的有限個(gè)指令的集合我們稱之為指令集。
指令集作為CPU和編譯器的設(shè)計(jì)規(guī)范和參考標(biāo)準(zhǔn),主要用來定義指令的格式、操作數(shù)的類型、寄存器的分配、地址的格式等,指令集主要由以下內(nèi)容組成。
指令的分發(fā)、預(yù)取、解碼、執(zhí)行、寫回。
操作數(shù)的類型、存儲(chǔ)、存取、旁路轉(zhuǎn)移。
Load/Store架構(gòu)。
寄存器。
地址的格式、大端模式、小端模式。
字節(jié)對(duì)齊、邊界對(duì)齊等。
微架構(gòu)
微架構(gòu),對(duì)應(yīng)的英文是Microarchitecture,也就是處理器架構(gòu)。集成電路工程師在設(shè)計(jì)處理器時(shí),會(huì)按照指令集規(guī)定的指令,設(shè)計(jì)具體的譯碼和運(yùn)算電路來支持這些指令的運(yùn)行;指令集在CPU處理器內(nèi)部的具體硬件電路的實(shí)現(xiàn),我們就稱為微架構(gòu)。
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論