 電子發(fā)燒友App
電子發(fā)燒友App


Nvidia 今天宣布,已向最新版本的 MLPerf 提交了其 Grace Hopper CPU+GPU Superchip 及其 L4 GPU 加速器的首個(gè)基準(zhǔn)測試結(jié)果,MLPerf 是一項(xiàng)行業(yè)標(biāo)準(zhǔn) AI 基準(zhǔn)測試,旨在為衡量人工智能性能提供一個(gè)公平的競爭環(huán)境。不同的工作負(fù)載。今天的基準(zhǔn)測試結(jié)果標(biāo)志著 MLPerf 基準(zhǔn)測試的兩個(gè)值得注意的新第一:添加了新的大型語言模型 (LLM) GPT-J 推理基準(zhǔn)測試和改進(jìn)的推薦模型。Nvidia 聲稱,在 GPT-J 基準(zhǔn)測試中,Grace Hopper Superchip 的推理性能比其市場領(lǐng)先的 H100 GPU 之一高出 17%,并且其 L4 GPU 的性能高達(dá)英特爾 Xeon CPU 的 6 倍。
隨著該行業(yè)迅速發(fā)展到更新的人工智能模型和更強(qiáng)大的實(shí)施,該行業(yè)正在以驚人的速度發(fā)展。同樣,由 MLCommons 機(jī)構(gòu)管理的 MLPerf 基準(zhǔn)也在不斷發(fā)展,以通過新的 v3.1 修訂版更好地反映人工智能領(lǐng)域不斷變化的性質(zhì)。
GPT-J 6B 是自 2021 年以來在現(xiàn)實(shí)工作負(fù)載中使用的文本摘要模型,現(xiàn)已在 MLPerf 套件中用作衡量推理性能的基準(zhǔn)。與一些更先進(jìn)的人工智能模型(例如 1750 億參數(shù)的 GPT-3)相比,GPT-J 60 億參數(shù)的 LLM 相當(dāng)輕量,但它非常適合推理基準(zhǔn)的角色。該模型總結(jié)了文本塊,并在對延遲敏感的在線模式和吞吐量密集型的離線模式下運(yùn)行。MLPerf 套件現(xiàn)在還采用了更大的 DLRM-DCNv2 推薦模型(參數(shù)數(shù)量增加了一倍)、更大的多熱點(diǎn)數(shù)據(jù)集以及能夠更好地表示真實(shí)環(huán)境的跨層算法。
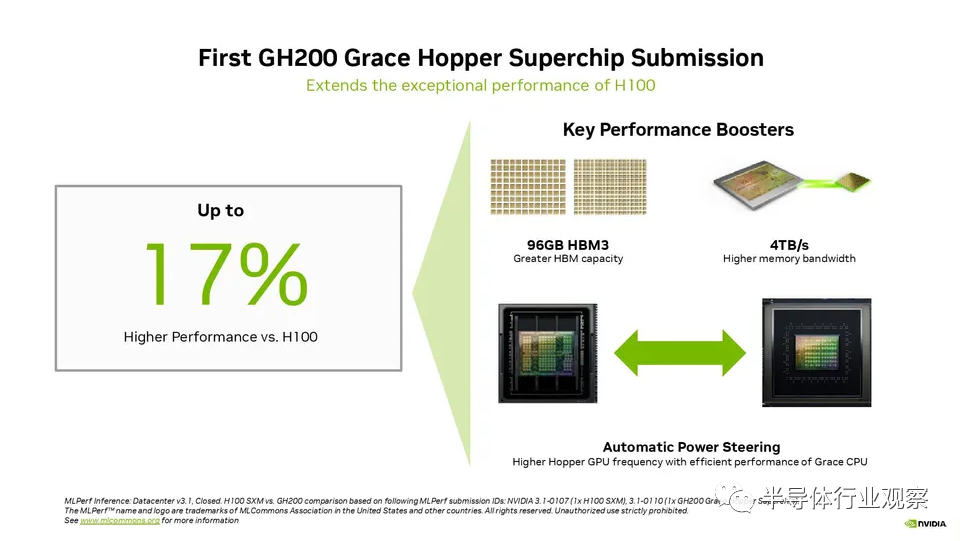
有了這個(gè)背景,我們可以在這里看到 Nvidia 的一些性能聲明。請注意,Nvidia 本身將這些基準(zhǔn)提交給 MLCommons,因此它們可能代表高度調(diào)整的最佳情況。
Nvidia 還喜歡指出,它是唯一一家為 MLPerf 套件中使用的每個(gè) AI 模型提交基準(zhǔn)的公司,這是一個(gè)客觀真實(shí)的聲明。有些公司完全缺席,比如 AMD,或者只提交了一些選定的基準(zhǔn)測試,比如英特爾的 Habana 和谷歌的 TPU。缺乏提交的原因因公司而異,但看到更多競爭對手加入 MLPerf 圈就太好了。
Nvidia 提交了第一個(gè) GH200 Grace Hopper Superchip MLPerf 結(jié)果,強(qiáng)調(diào) CPU+GPU 組合的性能比單個(gè) H100 GPU 高出 17%。從表面上看,這令人驚訝,因?yàn)?GH200 使用與 H100 CPU 相同的芯片,但我們將在下面解釋原因。自然,配備 8 個(gè) H100 的 Nvidia 系統(tǒng)的性能優(yōu)于 Grace Hopper Superchip,在每項(xiàng)推理測試中都處于領(lǐng)先地位。
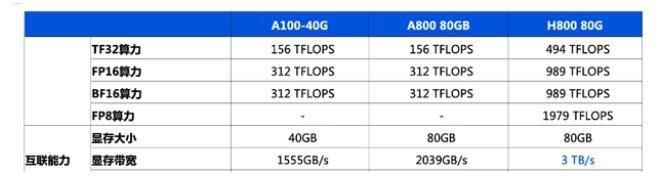
提醒一下,Grace Hopper Superchip 在同一塊板上結(jié)合了 Hopper GPU 和 Grace CPU,在兩個(gè)單元之間提供了具有 900GB/s 吞吐量的C2C 鏈路,從而提供了典型 PCIe 帶寬的 7 倍CPU 到 GPU 數(shù)據(jù)傳輸?shù)倪B接,提高了 GH200 的可訪問內(nèi)存帶寬,并通過包含 96GB HBM3 內(nèi)存和 4TB/s GPU 內(nèi)存帶寬的連貫內(nèi)存池進(jìn)行了增強(qiáng)。相比之下,在 HGX 中測試的對比 H100 僅具有 80GB 的 HBM3 (下一代 Grace Hopper 型號將在 2024 年第二季度擁有 144GB 的 HBM3e,速度快 1.7 倍)。
Nvidia 還推出了一種名為“ Automatic Power Steering”的動(dòng)態(tài)動(dòng)力轉(zhuǎn)移技術(shù),該技術(shù)可以動(dòng)態(tài)平衡 CPU 和 GPU 之間的功率預(yù)算,將溢出預(yù)算轉(zhuǎn)向負(fù)載最大的單元。這項(xiàng)技術(shù)被用于許多競爭性的現(xiàn)代 CPU+GPU 組合中,因此它并不新鮮,但它確實(shí)允許 Grace Hopper Superchip 上的 GPU 享受比 HGX 更高的電力傳輸預(yù)算,因?yàn)殡娏腉race CPU——這在標(biāo)準(zhǔn)服務(wù)器中是不可能的。完整的 CPU+GPU 系統(tǒng)以 1000W TDP 運(yùn)行。
大多數(shù)推理繼續(xù)在 CPU 上執(zhí)行,隨著更大的模型變得越來越普遍,這種情況在未來可能會(huì)發(fā)生變化;對于 Nvidia 來說,用 L4 等小型低功耗 GPU 取代用于這些工作負(fù)載的 CPU 至關(guān)重要,因?yàn)檫@將推動(dòng)大批量銷售。本輪 MLPerf 提交還包括 Nvidia L4 GPU 的第一批結(jié)果,該推理優(yōu)化卡在 GPT-J 推理基準(zhǔn)測試中的性能是單個(gè) Xeon 9480 的 6 倍,盡管在超薄外形卡中功耗僅為 72W,不需要輔助電源連接。
Nvidia 還聲稱,通過測量 8 個(gè) L4 GPU 與兩個(gè)上一代 Xeon 8380s CPU 的性能,視頻+AI 解碼-推理-編碼工作負(fù)載的 CPU 性能提高了 120 倍,這有點(diǎn)不平衡。這可能是為了直接比較單個(gè)機(jī)箱中可以容納的計(jì)算能力。盡管如此,值得注意的是,盡管四路服務(wù)器不是最適合這項(xiàng)工作,但仍然可以使用,而且較新的至強(qiáng)芯片在本次測試中可能會(huì)表現(xiàn)得更好一些。測試配置位于幻燈片底部的小字中,因此請務(wù)必注意這些細(xì)節(jié)。
最后,Nvidia 還提交了 Jetson Orin 機(jī)器人芯片的基準(zhǔn)測試,顯示推理吞吐量提高了 84%,這主要是由軟件改進(jìn)推動(dòng)的。
重要的是要記住,在現(xiàn)實(shí)世界中,每個(gè)人工智能模型都作為較長系列模型的一部分運(yùn)行,這些模型在人工智能管道中執(zhí)行以完成特定的工作或任務(wù)。Nvidia 的上面的插圖很好地體現(xiàn)了這一點(diǎn),在完成之前對一個(gè)查詢執(zhí)行八種不同的 AI 模型 - 并且這些類型的 AI 管道擴(kuò)展至 15 個(gè)網(wǎng)絡(luò)來滿足單個(gè)查詢并不是聞所未聞的。這是重要的背景,因?yàn)樯厦娴拿嫦蛲掏铝康幕鶞?zhǔn)往往側(cè)重于以高利用率運(yùn)行單個(gè) AI 模型,而不是現(xiàn)實(shí)世界的管道,需要更多的多功能性,多個(gè) AI 模型串行運(yùn)行才能完成給定的任務(wù)任務(wù)。
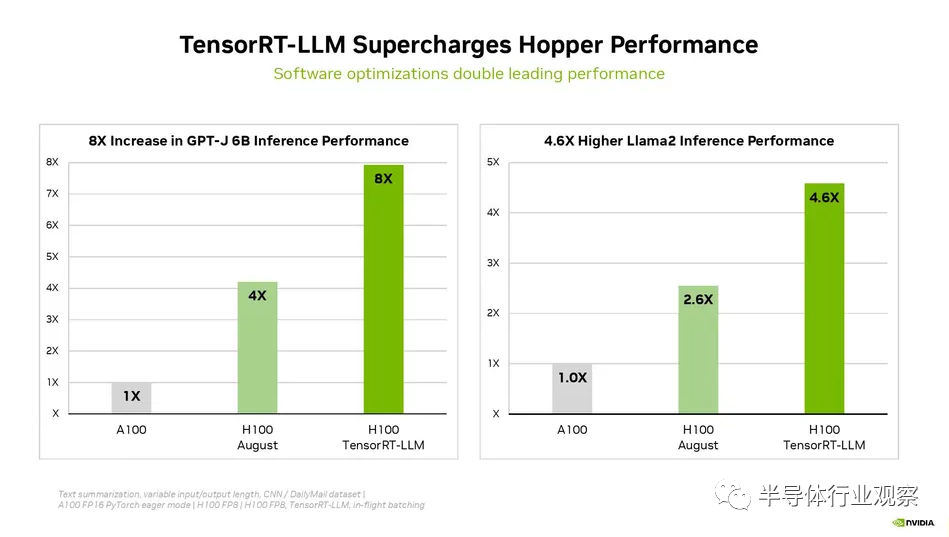
Nvidia 上周還宣布,其用于生成 AI 工作負(fù)載的 TensorRT-LLM 軟件可在推理工作負(fù)載中提供優(yōu)化的性能,在 H100 GPU 上使用時(shí)總體性能提高一倍以上,且無需增加成本。Nvidia 最近提供了有關(guān)該軟件的詳細(xì)信息,并指出它還沒有為這一輪結(jié)果準(zhǔn)備好這種推理增強(qiáng)軟件;MLCommons 要求 MLPerf 提交需要 30 天的準(zhǔn)備時(shí)間,而 TensorRT-LLM 當(dāng)時(shí)不可用。這意味著 Nvidia 的首輪 MLPerf 基準(zhǔn)測試應(yīng)該會(huì)在下一輪提交中看到巨大的改進(jìn)。
Nvidia Grace Hopper CPU的設(shè)計(jì)詳解
正如我們在之前的報(bào)道中指出,Nvidia 的 Grace CPU 是該公司第一款專為數(shù)據(jù)中心設(shè)計(jì)的純 CPU Arm 芯片,一塊主板上有兩個(gè)芯片,總共 144 個(gè)核心,而 Grace Hopper Superchip 則在主板上結(jié)合了 Hopper GPU 和 Grace CPU。
根據(jù)Nvidia之前透露,Grace CPU采用臺(tái)積電4N工藝。臺(tái)積電將“N4”4nm工藝列入其5nm節(jié)點(diǎn)家族之下,將其描述為5nm節(jié)點(diǎn)的增強(qiáng)版。Nvidia 使用該節(jié)點(diǎn)的一種特殊變體,稱為“4N”,專門針對其 GPU 和 CPU 進(jìn)行了優(yōu)化。
隨著摩爾定律的衰落,這些類型的專用節(jié)點(diǎn)變得越來越普遍,并且隨著每個(gè)新節(jié)點(diǎn)的出現(xiàn),縮小晶體管變得更加困難和昂貴。為了實(shí)現(xiàn) Nvidia 4N 等定制工藝節(jié)點(diǎn),芯片設(shè)計(jì)人員和代工廠攜手合作,使用設(shè)計(jì)技術(shù)協(xié)同優(yōu)化 (DTCO) 為其特定產(chǎn)品調(diào)整定制功耗、性能和面積 (PPA) 特性。
Nvidia 此前曾透露,其 Grace CPU 使用現(xiàn)成的 Arm Neoverse 內(nèi)核,但該公司仍未具體說明使用哪個(gè)具體版本。不過,Nvidia透露Grace采用Arm v9內(nèi)核,支持SVE2、Neoverse N2平臺(tái)是 Arm 第一個(gè)支持 Arm v9 和 SVE2 等擴(kuò)展的 IP。N2 Perseus 平臺(tái)采用 5nm 設(shè)計(jì)(請記住,N4 屬于臺(tái)積電的 5nm 系列),支持 PCIe Gen 5.0、DDR5、HBM3、CCIX 2.0 和 CXL 2.0。Perseus 設(shè)計(jì)針對每功率(瓦特)性能和每面積性能進(jìn)行了優(yōu)化。Arm 表示,其下一代核心 Poseidon 直到 2024 年才會(huì)上市,考慮到 Grace 的發(fā)布日期為 2023 年初,這些核心的可能性較小。
Nvidia 的新 Nvidia 可擴(kuò)展一致性結(jié)構(gòu) (SCF:Nvidia Scalable Coherency Fabric ) 是一種網(wǎng)狀互連,看起來與與 Arm Neoverse 核心一起使用的標(biāo)準(zhǔn)CMN-700 相干網(wǎng)狀網(wǎng)絡(luò)非常相似。
Nvidia SCF 在各種 Grace 芯片單元(如 CPU 內(nèi)核、內(nèi)存和 I/O)之間提供 3.2 TB/s 的對分帶寬,更不用說將芯片與其他單元連接起來的 NVLink-C2C 接口了。無論是另一個(gè) Grace CPU 還是 Hopper GPU。
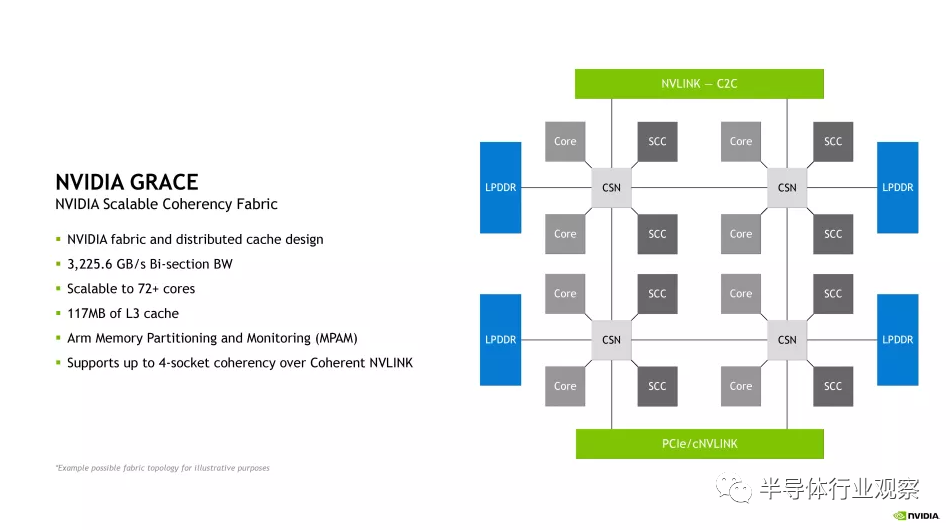
該網(wǎng)格支持 72 個(gè)以上核心,每個(gè) CPU 總 L3 緩存為 117MB。Nvidia 表示,上面專輯中的第一個(gè)框圖是“用于說明目的的可能拓?fù)洹保鋵R方式與第二個(gè)圖并不完全一致。
該圖顯示了具有八個(gè) SCF 緩存分區(qū) (SCC:SCF Cache partitions ) 的芯片,這些分區(qū)似乎是 L3 緩存片(我們將在演示中了解更多詳細(xì)信息)以及八個(gè) CPU 單元(這些似乎是核心集群)。SCC 和內(nèi)核以兩個(gè)為一組連接到緩存交換節(jié)點(diǎn) (CSN),然后 CSN 駐留在 SCF 網(wǎng)狀結(jié)構(gòu)上,以提供 CPU 內(nèi)核和內(nèi)存與芯片其余部分之間的接口。SCF 還通過 Coherent NVLink 支持最多四個(gè)插槽的一致性。
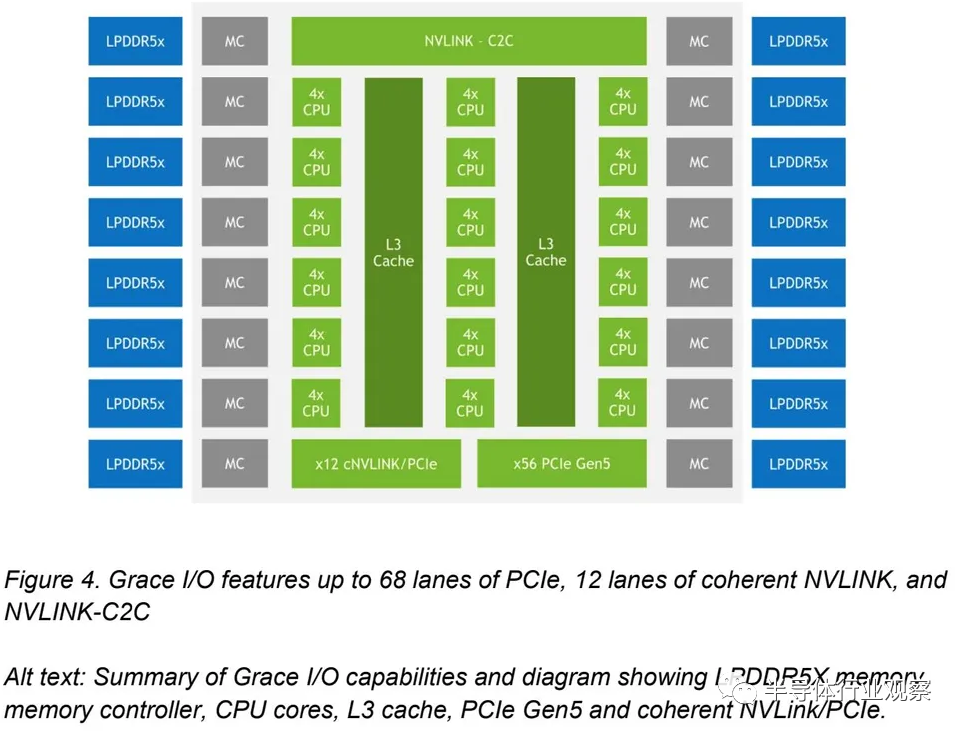
Nvidia 還分享了這張圖,顯示每個(gè) Grace CPU 支持最多 68 個(gè) PCIe 通道和最多 4 個(gè) PCIe 5.0 x16 連接。每個(gè) x16 連接支持高達(dá) 128 GB/s 的雙向吞吐量(x16 鏈路可以分為兩個(gè) x8 鏈路)。我們還看到了 16 個(gè)雙通道 LPDDR5X 內(nèi)存控制器 (MC)。
然而,此圖與第一個(gè)圖不同,它將 L3 緩存顯示為連接到四核 CPU 集群的兩個(gè)連續(xù)塊,這比之前的圖更有意義,并且芯片中總共有 72 個(gè)核心。但是,我們在第一個(gè)圖中沒有看到單獨(dú)的 SCF 分區(qū)或 CSN 節(jié)點(diǎn),這造成了一些混亂。我們將在演示期間解決這個(gè)問題,并根據(jù)需要進(jìn)行更新。
Nvidia 告訴我們,可擴(kuò)展一致性結(jié)構(gòu) (SCF) 是其專有設(shè)計(jì),但 Arm 允許其合作伙伴通過調(diào)整核心數(shù)量、緩存大小以及使用不同類型的內(nèi)存(例如 DDR5 和 HBM)來定制 CMN-700 網(wǎng)格,以及選擇各種接口,例如 PCIe 5.0、CXL 和 CCIX。這意味著 Nvidia 可能會(huì)為片上結(jié)構(gòu)使用高度定制的 CMN-700 實(shí)現(xiàn)。
GPU 喜歡內(nèi)存吞吐量,因此 Nvidia 自然而然地將目光轉(zhuǎn)向提高內(nèi)存吞吐量,不僅限于芯片內(nèi)部,還包括 CPU 和 GPU 之間的內(nèi)存吞吐量。Grace CPU 具有 16 個(gè)雙通道 LPDDR5X 內(nèi)存控制器,最多可支持 32 個(gè)通道,支持高達(dá) 512 GB 的內(nèi)存和高達(dá) 546 GB/s 的吞吐量。Nvidia 表示,由于容量和成本等多種因素,它選擇了 LPDDR5X 而不是 HBM2e。同時(shí),與標(biāo)準(zhǔn) DDR5 內(nèi)存相比,LPDDR5X 的帶寬增加了 53%,每 GB 功耗降低了 1/8,使其成為更好的整體選擇。
Nvidia 還推出了擴(kuò)展 GPU 內(nèi)存 (EGM),它允許 NVLink 網(wǎng)絡(luò)上的任何 Hopper GPU 訪問網(wǎng)絡(luò)上任何 Grace CPU 的 LPDDR5X 內(nèi)存,但保持本機(jī) NVLink 性能。
Nvidia的目標(biāo)是提供一個(gè)可以在CPU和GPU之間共享的統(tǒng)一內(nèi)存池,從而提供更高的性能,同時(shí)簡化編程模型。Grace Hopper CPU+GPU 芯片支持具有共享頁表的統(tǒng)一內(nèi)存,這意味著芯片可以與 CUDA 應(yīng)用程序共享地址空間和頁表,并允許使用系統(tǒng)分配器來分配 GPU 內(nèi)存。它還支持 CPU 和 GPU 之間的native atomics。
CPU 核心是計(jì)算引擎,但互連是定義計(jì)算未來的戰(zhàn)場。移動(dòng)數(shù)據(jù)比實(shí)際計(jì)算數(shù)據(jù)消耗更多的電量,因此更快、更有效地移動(dòng)數(shù)據(jù),甚至避免數(shù)據(jù)傳輸,是一個(gè)關(guān)鍵目標(biāo)。
Nvidia 的Grace CPU在一塊板上由兩個(gè) CPU 組成,而 Grace Hopper Superchip 在同一塊板上由一個(gè) Grace CPU 和一個(gè) Hopper GPU 組成,旨在通過專有的 NVLink 芯片最大限度地提高單元之間的數(shù)據(jù)傳輸。芯片間 (C2C) 互連并提供內(nèi)存一致性,以減少或消除數(shù)據(jù)傳輸。

Nvidia 分享了有關(guān)其 NVLink-C2C 互連的新細(xì)節(jié)。提醒一下,這是一種芯片到芯片和芯片到芯片互連,支持內(nèi)存一致性,可提供高達(dá) 900 GB/s 的吞吐量(是 PCIe 5.0 x16 鏈路帶寬的 7 倍)。該接口使用 NVLink 協(xié)議,Nvidia 使用其 SERDES 和 LINK 設(shè)計(jì)技術(shù)設(shè)計(jì)了該接口,重點(diǎn)關(guān)注能源和面積效率。物理 C2C 接口跨標(biāo)準(zhǔn) PCB 運(yùn)行,因此不使用專門的中介層。
NVLink-C2C 還支持行業(yè)標(biāo)準(zhǔn)協(xié)議,例如 CXL 和 Arm 的 AMBA 相干集線器接口(CHI — Neoverse CMN-700 網(wǎng)格的關(guān)鍵)。它還支持多種類型的連接,從基于 PCB 的互連到硅中介層和晶圓級實(shí)現(xiàn)。
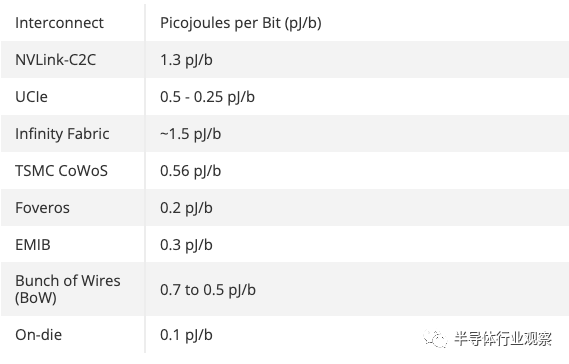
電源效率是所有數(shù)據(jù)結(jié)構(gòu)的一個(gè)關(guān)鍵指標(biāo),今天 Nvidia 表示,傳輸?shù)臄?shù)據(jù)每比特 (pJ/b) 鏈路消耗 1.3 皮焦耳 (pJ/b)。這是 PCIe 5.0 接口效率的 5 倍,但它的功率是未來將上市的 UCIe 互連的兩倍多(0.5 至 0.25 pJ/b)。封裝類型各不相同,C2C 鏈路為 Nvidia 的特定用例提供了性能和效率的堅(jiān)實(shí)結(jié)合,但正如您在上表中看到的,更高級的選項(xiàng)可提供更高水平的功效。
Nvidia 將H100 推理性能提高一倍的秘訣
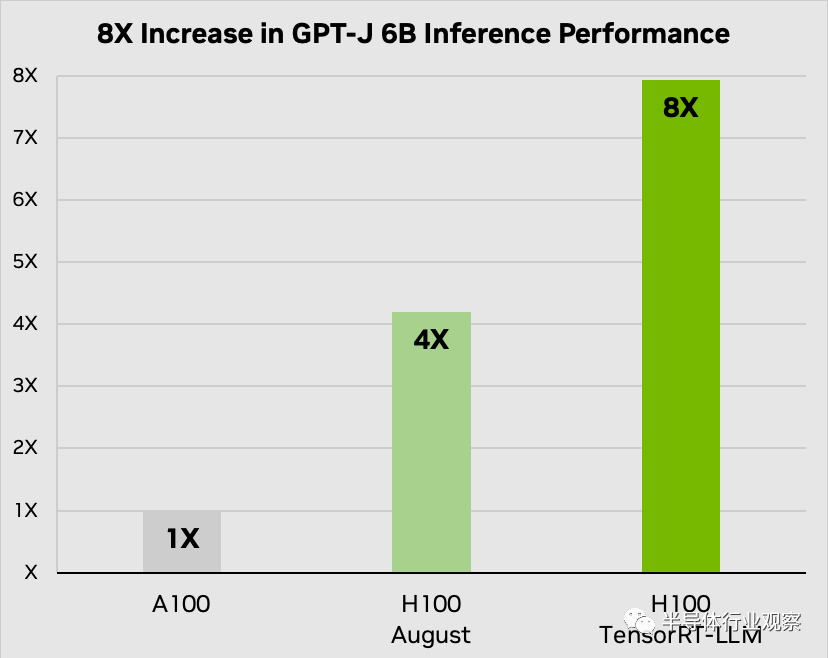
Nvidia 表示,其新的 TensorRT -LL開源軟件可以顯著提高 GPU 上大型語言模型 (LLM) 的性能。據(jù)該公司稱,Nvidia TensorRT-LL 的功能使其 H100 計(jì)算 GPU 在具有 60 億個(gè)參數(shù)的 GPT-J LLM 中的性能提高了兩倍。重要的是,該軟件可以實(shí)現(xiàn)這種性能改進(jìn),而無需重新訓(xùn)練模型。
Nvidia 專門開發(fā)了 TensorRT-LLM,以提高 LLM 推理的性能,Nvidia 提供的性能圖形確實(shí)顯示,由于適當(dāng)?shù)能浖?yōu)化,其 H100 的速度提升了 2 倍。Nvidia TensorRT-LLM 的一個(gè)特別突出的功能是其創(chuàng)新的動(dòng)態(tài)批處理技術(shù)。該方法解決了LLM動(dòng)態(tài)且多樣化的工作負(fù)載,這些工作負(fù)載的計(jì)算需求可能存在很大差異。
動(dòng)態(tài)批處理優(yōu)化了這些工作負(fù)載的調(diào)度,確保 GPU 資源得到最大程度的利用。因此,H100 Tensor Core GPU 上的實(shí)際 LLM 請求吞吐量翻倍,從而實(shí)現(xiàn)更快、更高效的 AI 推理過程。
Nvidia 表示,其 TensorRT-LLM 將深度學(xué)習(xí)編譯器與優(yōu)化的內(nèi)核、預(yù)處理和后處理步驟以及多 GPU/多節(jié)點(diǎn)通信原語集成在一起,確保它們在 GPU 上更高效地運(yùn)行。這種集成得到了模塊化 Python API 的進(jìn)一步補(bǔ)充,它提供了一個(gè)開發(fā)人員友好的界面,可以進(jìn)一步增強(qiáng)軟件和硬件的功能,而無需深入研究復(fù)雜的編程語言。例如,MosaicML 在 TensorRT-LLM 之上無縫添加了所需的特定功能,并將它們集成到其推理服務(wù)中。
Databricks 工程副總裁 Naveen Rao 表示:“TensorRT-LLM 易于使用,功能齊全,包括令牌流、動(dòng)態(tài)批處理、分頁注意力、量化等,而且效率很高。” “它為使用 NVIDIA GPU 的LLM服務(wù)提供了最先進(jìn)的性能,并使我們能夠?qū)⒐?jié)省的成本回饋給我們的客戶。”
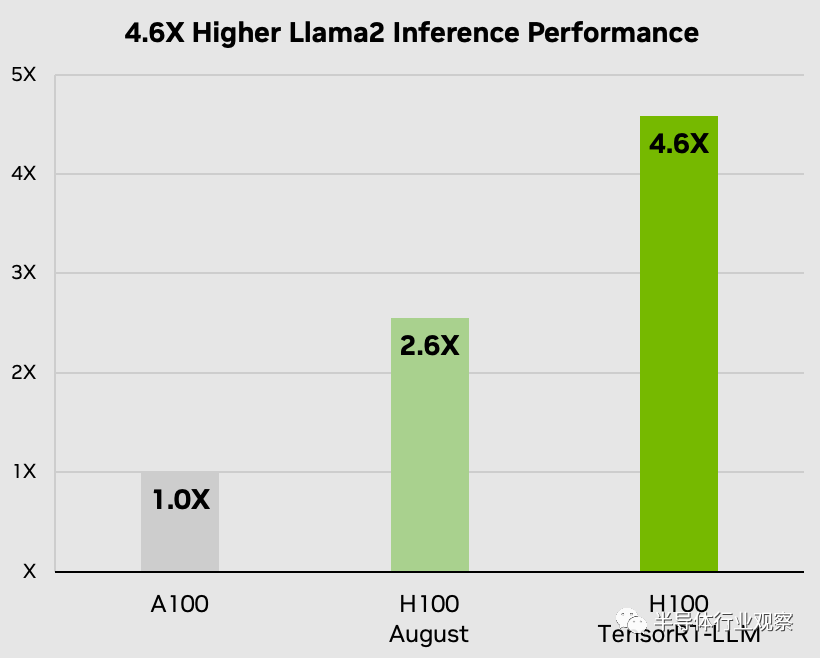
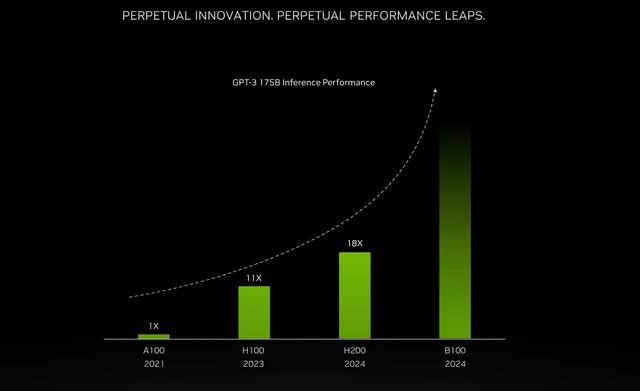
Nvidia H100 與 TensorRT-LLM 結(jié)合使用時(shí)的性能令人印象深刻。在 NVIDIA 的 Hopper 架構(gòu)上,H100 GPU 與 TensorRT-LLM 配合使用時(shí),性能是 A100 GPU 的八倍。此外,在測試 Meta 開發(fā)的 Llama 2 模型時(shí),TensorRT-LLM 的推理性能比 A100 GPU 提高了 4.6 倍。這些數(shù)字強(qiáng)調(diào)了該軟件在人工智能和機(jī)器學(xué)習(xí)領(lǐng)域的變革潛力。
最后,H100 GPU 與 TensorRT-LLM 結(jié)合使用時(shí)支持 FP8 格式。此功能可以減少內(nèi)存消耗,而不會(huì)損失模型準(zhǔn)確性,這對于預(yù)算和/或數(shù)據(jù)中心空間有限且無法安裝足夠數(shù)量的服務(wù)器來調(diào)整其 LLM 的企業(yè)來說是有益的。
編輯:黃飛
?




























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論