 電子發(fā)燒友App
電子發(fā)燒友App


前言:這次是酷睿Ultra 不是14代酷睿
8月底去了趟馬來西亞,一方面參觀了Intel位于馬來西亞檳城、居林的封測(cè)工廠、實(shí)驗(yàn)室,另一方面參加了Meteor Lake技術(shù)分享,全面了解了第一代酷睿Ultra處理器的架構(gòu)設(shè)計(jì)、技術(shù)特性。
現(xiàn)在,終于可以和大家分享了!
首先再“科普”一下1代酷睿Ultra、14代酷睿的關(guān)系,因?yàn)镮ntel這次的產(chǎn)品和命名體系確實(shí)有點(diǎn)混亂,別說普通玩家,很多業(yè)內(nèi)人士也一直分不清……
今年6月15日,Intel正式公布了全新的酷睿Ultra品牌,第一代產(chǎn)品代號(hào)Meteor Lake,采用全新的Intel 4制造工藝和封裝技術(shù)、全新的分離式模塊化架構(gòu)、全新的CPU架構(gòu)與3D高性能混合架構(gòu)、全新的銳炫GPU核顯、全新的NPU AI引擎,可以說是Intel第一顆微處理器4004 1971年誕生以來,變革最大的一代。
不過比較可惜,Intel 4工藝第一次登場(chǎng)和之前的14nm、10nm有些類似,性能上還未達(dá)到足夠高的水準(zhǔn),所以只能用于筆記本移動(dòng)平臺(tái)的主流H系列、低功耗P系列,分為酷睿Ultra 9/7/5三個(gè)子系列。
對(duì)于桌面S系列、頂級(jí)游戲本HX系列,將在原有Raptor Lake 13代酷睿的基礎(chǔ)上進(jìn)行升級(jí),包括增加E核并擴(kuò)大緩存、提升頻率、加速內(nèi)存等,也就是Raptor Lake Refresh 14代酷睿,繼續(xù)使用LGA1700接口,繼續(xù)兼容600/700系列主板,分為酷睿i9/i7/i5/i3四個(gè)子系列。
此外,超低功耗的U系列也會(huì)是13代酷睿升級(jí)版,但命名為一代酷睿(注意沒有任何后綴),分為酷睿7/5/3三個(gè)子系列。
今天的主角,就是Meteor Lake酷睿Ultra,但這一次,我們只講它的架構(gòu)設(shè)計(jì)、制造和封裝工藝、技術(shù)特性。
具體的型號(hào)命名、規(guī)格參數(shù)、性能跑分,將在12月14日正式發(fā)布的時(shí)候公開。
14代酷睿預(yù)計(jì)還是分為兩步走,其中高端的K/KF系列下個(gè)月首先登場(chǎng),主流和低功耗系列大概率也要到CES 2024。
總體架構(gòu)設(shè)計(jì):極具創(chuàng)意、極高效率的分離式模塊


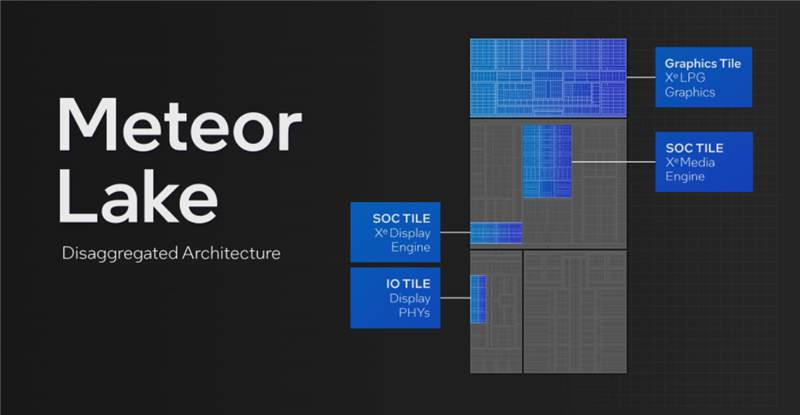
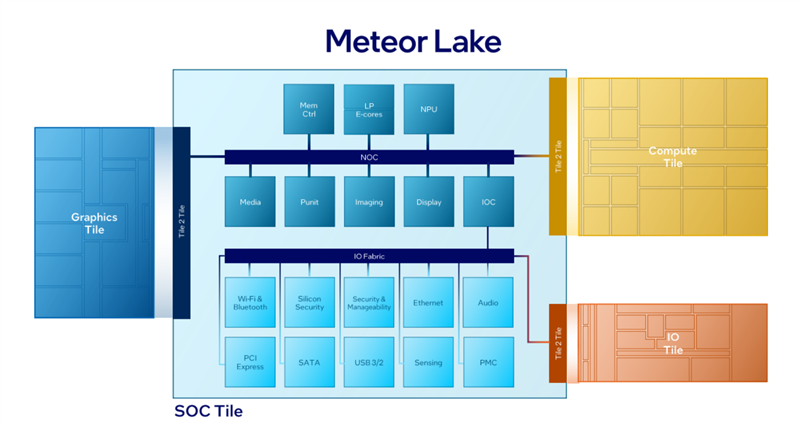
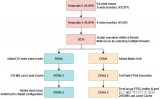
酷睿Ultra處理器是Intel在消費(fèi)級(jí)市場(chǎng)上第一次采用分離式模塊化架構(gòu),將傳統(tǒng)的單芯片一分為四,分別叫做計(jì)算模塊(Compute Tile)、SoC模塊(SoC Tile)、圖形模塊(GPU Tile)、IO模塊(IO Tile),如同搭積木一般。
這其實(shí)就是我們已經(jīng)見過很多次的Chiplet(小芯片/芯粒),Intel Sapphire Rapids第四代可擴(kuò)展至強(qiáng)處理器、Ponte Vecchio GPU加速器就都是這種設(shè)計(jì),AMD更是銳龍、霄龍、Radeon、Instinct全線都在用。
酷睿Ultra當(dāng)然不是簡(jiǎn)單粗暴地將整個(gè)芯片分開,而是精心地進(jìn)行了各種優(yōu)化設(shè)計(jì),比如重組計(jì)算密集型IP、增加低功耗AI核心、重建電源管理模塊、提升IO帶寬與擴(kuò)展性等等,再結(jié)合不同的先進(jìn)制造工藝、封裝技術(shù),實(shí)現(xiàn)了性能、能效的飛躍。

計(jì)算模塊,就是CPU核心與緩存,包括最多6個(gè)全新Redwood Cove架構(gòu)的P核(性能核)、最多8個(gè)全新Crestmont架構(gòu)的E核(能效核)。
它首次采用了Intel最先進(jìn)的Intel 4制造工藝,也是酷睿Ultra四大模塊中唯一使用該工藝的。
其他三個(gè)模塊的具體情況暫未公開,目測(cè)大概率是臺(tái)積電的5-7nm,甚至不排除IO模塊使用更成熟的12nm。

圖形模塊就是核顯,升級(jí)到了全新的Xe LPG架構(gòu),和桌面上的銳炫Arc A系列的Xe HPG架構(gòu)同宗同源,并針對(duì)低功耗做了優(yōu)化,性能和能效都有了飛躍。
但是,這里只有GPU圖形渲染相關(guān)單元,以前在一起的媒體引擎、顯示引擎都搬到了SoC模塊,顯示物理層則搬到了IO模塊。
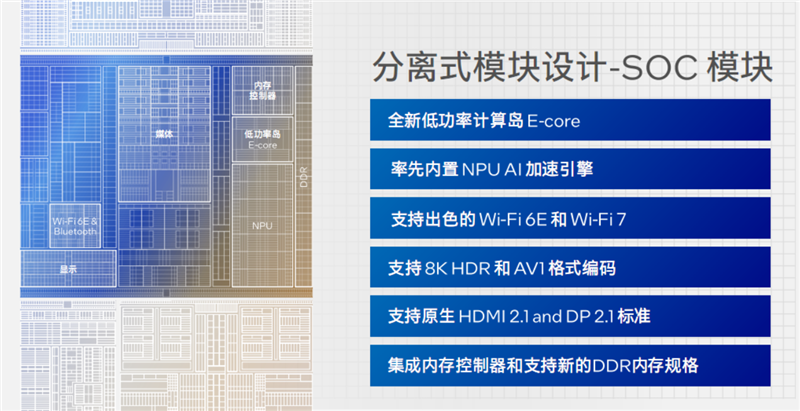

SoC模塊不是傳統(tǒng)意義上的System on Chip,但同樣集成了眾多功能模塊,包括低功耗E核(LPE)、NPU AI獨(dú)立引擎、內(nèi)存控制器、無線控制器、媒體引擎、顯示引擎、安全引擎、圖像信號(hào)處理器、電源管理單元、系統(tǒng)代理、IO緩存(IOC)等等。
尤其是其中的兩個(gè)低功耗E核,也就是LPE核,和計(jì)算模塊的P核、E核聯(lián)合構(gòu)成了全新的3D高性能混合架構(gòu)。
這也是Intel 12代酷睿首次引入混合架構(gòu)之后,最為重大的一次變革。

IO模塊當(dāng)然就是負(fù)責(zé)輸入輸出連接了,包括雷電4控制器、PCIe 5.0控制器,但不僅于此。
如前所述,Chiplet設(shè)計(jì)不是簡(jiǎn)單地把一顆大芯片拆成多顆小芯片那么簡(jiǎn)單,需要在多個(gè)層面進(jìn)行新的思考與優(yōu)化。
首先就是不同芯片、不同功能單元之間的通信如何才能達(dá)到最高效率,不能出現(xiàn)“交通擁堵”反而造成通信效率的下降,直接拖累性能。
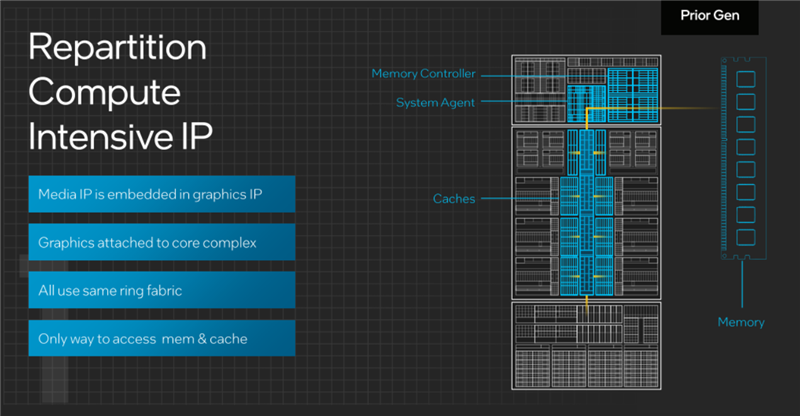
比如在以往的設(shè)計(jì)中,媒體引擎、顯示引擎一直都和圖形引擎同時(shí)集成于圖形模塊之中,以至于我們一直默認(rèn)它們就是一個(gè)整體,而且通過同一條環(huán)形交叉總線和CPU核心、緩存、內(nèi)存相連,仿佛“華山一條道”。
但其實(shí),它們都是在不同場(chǎng)景下執(zhí)行不同的工作,并不需要同時(shí)開啟,比如看視頻和玩游戲就是完全不一樣的。
同時(shí),無論圖形引擎還是媒體引擎,但它們需要訪問內(nèi)存的時(shí)候,CPU核心就不得不都陪著保持開啟狀態(tài)。
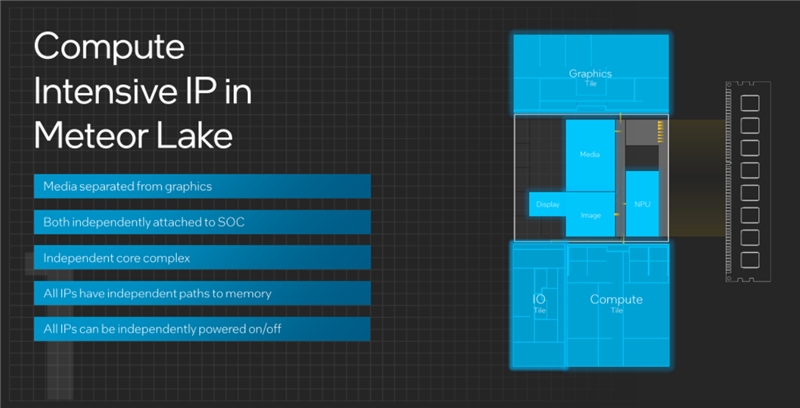
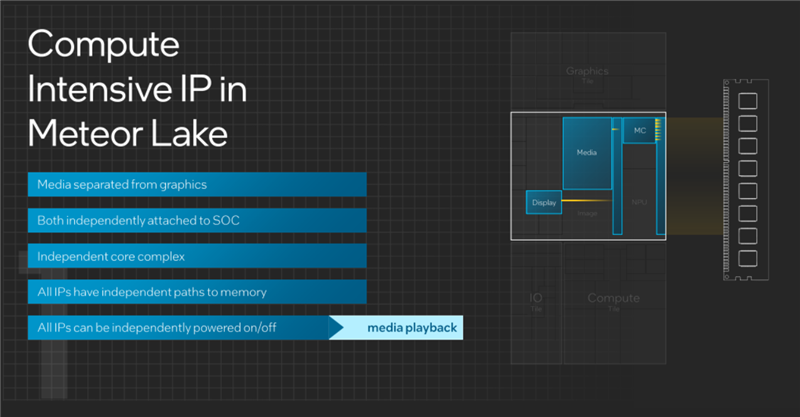
酷睿Ultra將媒體引擎、顯示引擎都轉(zhuǎn)移到了SoC模塊中,而且彼此是獨(dú)立的,也不再依賴于CPU核心即計(jì)算模塊。
如此一來,所有的IP都可以通過單獨(dú)的路徑分別訪問內(nèi)存,也都可以獨(dú)立開啟或者關(guān)閉。
比如看視頻的時(shí)候,只需要開啟顯示引擎、媒體解碼,其他部分就都可以關(guān)掉。
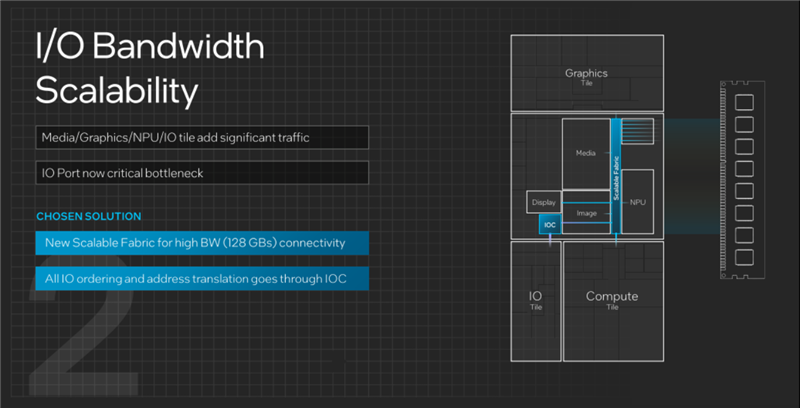
隨著芯片規(guī)模的增大、功能的豐富,無論是單芯片設(shè)計(jì)還是多芯片設(shè)計(jì),都面臨同樣的IO通信帶寬與效率問題,稍有不慎就容易成為瓶頸。
酷睿Ultra這樣的分離式模塊架構(gòu)上,隨著媒體與顯示引擎分離、低功耗E核加入、NPU AI單元加入,依次連接不同單元的的傳統(tǒng)單一直連總線顯然已經(jīng)無法滿足如此眾多、多樣的通信需求。
一種解決方法是為每個(gè)IP單元加入相應(yīng)的通信通道,但這一方面會(huì)大大增加設(shè)計(jì)的復(fù)雜度,另一方面也不夠靈活,未來如果要調(diào)整或加入更多單元又得重新設(shè)計(jì)。
Intel的解決方案分為兩部分,一是帶寬高達(dá)128GB/s的全新可擴(kuò)展交叉總線,以其為中心直連各個(gè)單元模塊,二是單獨(dú)設(shè)計(jì)的IO緩存(IOC),統(tǒng)一管理所有的IO排序與尋址轉(zhuǎn)換。
這種設(shè)計(jì)不僅可以解決傳輸帶寬與延遲問題,而且是非常彈性的,未來有更高的需求,可以輕松提升帶寬、增加緩存。
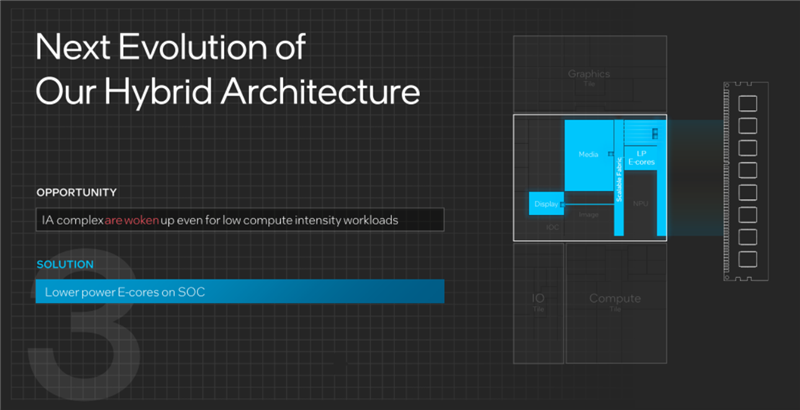
12代酷睿引入的混合架構(gòu),提高了不用負(fù)載計(jì)算的靈活性,但也存在一個(gè)問題,那就是哪怕輕量級(jí)負(fù)載,也得讓整個(gè)CPU計(jì)算部分保持開啟狀態(tài),造成極大的浪費(fèi),這也是12/13代酷睿筆記本續(xù)航普遍不佳的一個(gè)關(guān)鍵原因。
酷睿Ultra的解決方法是在SoC模塊中,引入了一個(gè)低功耗計(jì)算島,包括2個(gè)低功耗E核,它的架構(gòu)和常規(guī)E核相同,只是頻率和功耗更低,專門負(fù)責(zé)單獨(dú)處理一些連常規(guī)E核都用不到的特別輕的負(fù)載任務(wù)。
比如看視頻的時(shí)候,有了低功耗E核的掌控,不但SoC模塊里的其他單元可以休息,媒體模塊、計(jì)算模塊、IO模塊更是可以全部關(guān)掉,從而節(jié)省非常可觀的功耗,極大地延長(zhǎng)續(xù)航。
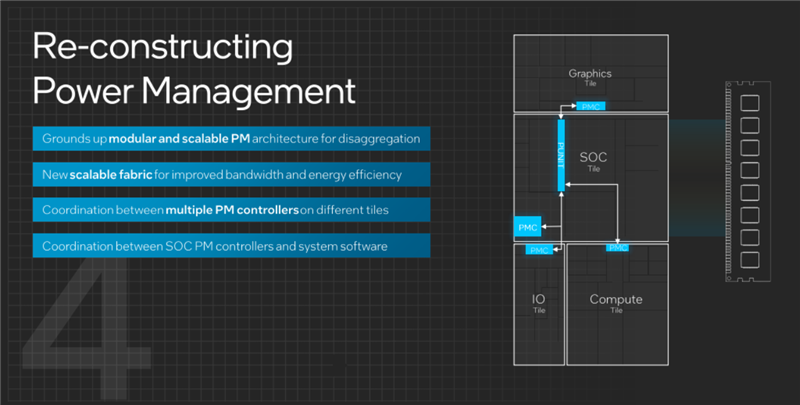
然后是電源管理部分,進(jìn)行了徹底的重組,隨著不同芯片的分離而分離,在四大模塊中都有單獨(dú)的電源管理單元。
其中,SoC模塊上的處于核心地位,不但管理所在的SoC模塊,還通過新的高帶寬、低延遲、可擴(kuò)展交叉總線,與其他模塊上的電源管理單元聯(lián)系在一起,起到協(xié)調(diào)溝通的作用,保證集體行動(dòng)的一致性。
另外,SoC上的電源管理單元還負(fù)責(zé)與系統(tǒng)、軟件層面的聯(lián)絡(luò),實(shí)現(xiàn)軟硬件的協(xié)調(diào)一致和高效率。
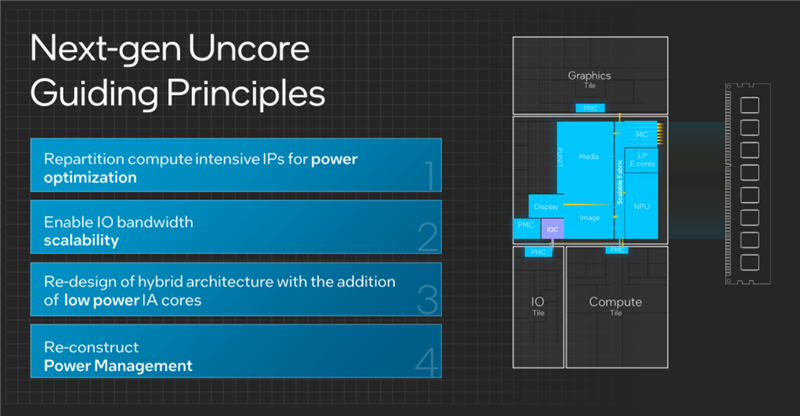
總的來說,酷睿Ultra在非核心部分做了大量的改進(jìn)工作,成就了有史以來最高效的設(shè)計(jì),尤其是在架構(gòu)、電源管理方面做了多方面的大膽嘗試,也為未來發(fā)展奠定了基礎(chǔ)。
接下來,我們?cè)偕钊敫鱾€(gè)不同的模塊,看看它們都是怎么設(shè)計(jì)和工作的。
三種CPU核心:3D混合架構(gòu) 關(guān)鍵在于調(diào)度
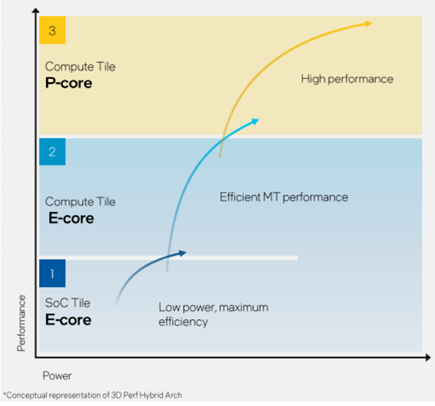
其實(shí),單純的計(jì)算模塊沒什么好講的(緩存容量都暫未公開),最大的變化來自于SoC模塊中新增的兩個(gè)低功耗E核(LPE),專門用于處理器輕負(fù)載任務(wù),能夠讓整個(gè)計(jì)算模塊可以按需關(guān)閉,節(jié)省功耗。
這兩個(gè)LPE核心,加上內(nèi)存子系統(tǒng)、媒體引擎、顯示引擎、IPU單元、NPU單元、可擴(kuò)展交叉總線等,共同構(gòu)成了所謂的低功耗島(Low Power Island)。
Intel稱之為3D性能混合架構(gòu)。
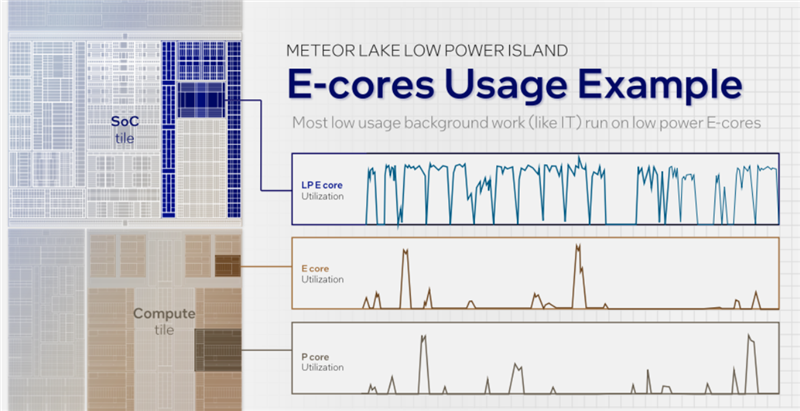
兩個(gè)LPE核與E核、P核雖然位置不同,但地位是相等的,對(duì)于系統(tǒng)也都是透明的,所以會(huì)在Windows任務(wù)管理器中會(huì)看到三種核心及其各自的使用率。
目前已知酷睿Ultra的最高規(guī)格是6+8+2核心,也就是6個(gè)P核、8個(gè)E核、2個(gè)LPE核,組成16核心22線程。
當(dāng)然,這種更復(fù)雜的混合架構(gòu),非常依賴軟硬件兩個(gè)層面的調(diào)度優(yōu)化,比如操作系統(tǒng)當(dāng)時(shí)最好使用最新版的Windows 11。
與此同時(shí),Intel對(duì)線程調(diào)度器做了大幅的革新,比如增強(qiáng)的系統(tǒng)反饋機(jī)制、增強(qiáng)的模塊間能效分配、動(dòng)態(tài)的IP間功耗分配、基于SoC運(yùn)行時(shí)能力的更新、基于系統(tǒng)運(yùn)行模式與硬件特性的指導(dǎo),等等。
需要強(qiáng)調(diào)的是,線程調(diào)度器并不是直接調(diào)度線程的,不會(huì)直接把某個(gè)線程分配到某個(gè)核心上,嚴(yán)格來說是介于處理器硬件、Windows系統(tǒng)軟件中間的一層機(jī)制,基于P核、E核、LPE核的實(shí)時(shí)狀態(tài)與能力,向操作系統(tǒng)進(jìn)行反饋、推薦,由操作系統(tǒng)最終決定線程的分配。
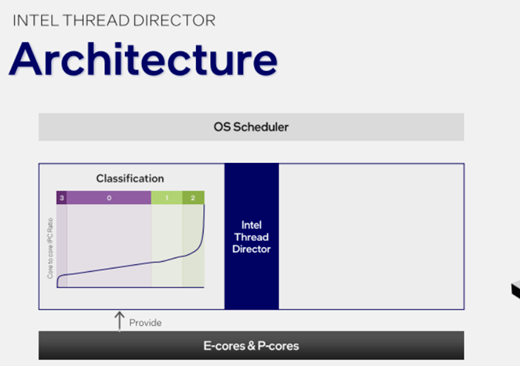
如上圖,Intel和微軟聯(lián)合對(duì)不同的線程負(fù)載進(jìn)行了分類,其中Class 0代表在P核、E核上執(zhí)行時(shí)的每時(shí)鐘周期指令數(shù)基本一致,也就是讓誰跑都無所謂,就看誰閑著。
Class 1代表P核執(zhí)行效率高于E核,比如大部分浮點(diǎn)運(yùn)算,會(huì)優(yōu)先分配給P核,如果P核不夠用了也可以分一些給E核。
Class 2則代表P核執(zhí)行效率遠(yuǎn)大于E核,比如AI運(yùn)算,就必須讓P核來做。
Class 3是新增的,代表那些在LPE核上的執(zhí)行效率與能效反而更高。
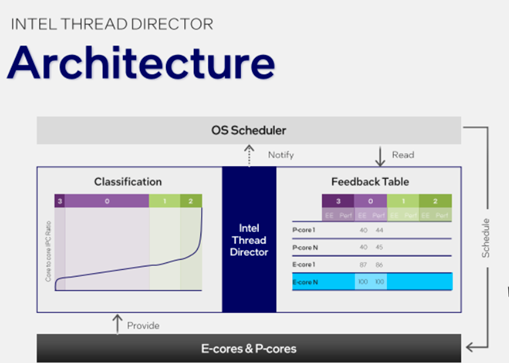
線程調(diào)度器會(huì)隨時(shí)將這樣的指令/線程分類反饋給系統(tǒng)調(diào)度器,然后共同形成一份“表格”,對(duì)線程負(fù)載進(jìn)行打分,在多大程度上追求高性能(Perf)還是追求高能效(EE),再結(jié)合每個(gè)核心當(dāng)前的實(shí)時(shí)能力,決定讓哪個(gè)核心執(zhí)行哪個(gè)指令。
這樣的反饋和推薦機(jī)制是實(shí)時(shí)的,還會(huì)根據(jù)當(dāng)下的功耗情況,甚至某個(gè)核心是不是剛剛執(zhí)行完一條指令,動(dòng)態(tài)報(bào)告給操作系統(tǒng)。
就是這樣一套機(jī)制,可以盡可能保證在正確的時(shí)間,讓正確的核心運(yùn)行正確的線程,保證硬件效率的最大化。
舉個(gè)例子:一個(gè)前端應(yīng)用需要高性能,它有四個(gè)線程分配給P核,然后有兩個(gè)輕負(fù)載的線程分配給E核。
之后經(jīng)過一段時(shí)間,P核上的四個(gè)線程執(zhí)行完畢,E核上的兩個(gè)線程還在執(zhí)行。
此時(shí),線程調(diào)度器很可能就會(huì)建議系統(tǒng)將這兩個(gè)線程轉(zhuǎn)移到LPE核上,然后關(guān)掉整個(gè)計(jì)算模塊。
再比如,有兩個(gè)線程正運(yùn)行在LPE核上,此時(shí)SoC模塊開啟、計(jì)算模塊關(guān)閉,然后來了四個(gè)要求高性能的線程,于是計(jì)算模塊打開,它們被分配到P核上。
這個(gè)時(shí)候,線程調(diào)度器就會(huì)提出建議,將LPE核上的兩個(gè)核心轉(zhuǎn)移到E核上繼續(xù)執(zhí)行,同時(shí)就可以關(guān)閉SoC模塊上的LPE核以及相應(yīng)的內(nèi)部總線。
酷睿Ultra的這種設(shè)計(jì)無疑是為了進(jìn)一步提高能效,使用最合適的核心運(yùn)行最合適的負(fù)載。
同時(shí)它還加入了專門的NPU AI引擎,可以非常高效地持續(xù)執(zhí)行一些AI推理任務(wù)負(fù)載,無需動(dòng)用CPU核心,可以讓后者隨時(shí)關(guān)閉。
正是這些設(shè)計(jì),使得Intel喊出了酷睿Ultra是其史上能效最高的消費(fèi)級(jí)處理器,讓我們對(duì)酷睿Ultra筆記本的續(xù)航充滿了期待。
圖形與媒體:全新架構(gòu)2倍性能 第二家支持光追
酷睿Ultra整體上采用了分離式模塊架構(gòu),CPU、GPU也各自都進(jìn)行了分離,前者就是剛才說的SoC模塊上的LPE核。
GPU部分的分離更加徹底,甚至可以說GPU這個(gè)概念都模糊了:
獨(dú)立的圖形模塊部分,現(xiàn)在是純粹的圖形渲染單元,而媒體引擎、顯示引擎轉(zhuǎn)移到了SoC模塊,顯示物理層則轉(zhuǎn)移到了IO模塊,彼此再進(jìn)行高效互連。
這樣一來,不同的功能模塊在不同的地方各司其職,方便按需開關(guān)。
酷睿Ultra GPU架構(gòu)來自于獨(dú)立顯卡Arc A系列使用的Xe HPG,同樣支持最新的DX12 Ultimate,同時(shí)針對(duì)低功耗整合做了調(diào)整和優(yōu)化,命名為Xe LPG,可以做稱之為兼具低功耗和高性能的Xe架構(gòu)。
Intel聲稱,它的能效相比12/13代酷睿上使用的Xe LP低功耗架構(gòu)的銳炬Xe核心,提升了足足兩倍。
事實(shí)上,近些年每次核顯架構(gòu)換代,都能帶來能效的翻倍——不是性能翻倍。


酷睿Ultra的核顯最多有8個(gè)Xe核心,也就是128個(gè)適量引擎,可以粗略地理解為128個(gè)執(zhí)行單元,比現(xiàn)在的96個(gè)增加了1/3。
這已經(jīng)超越了入門級(jí)獨(dú)立顯卡Arc A310 6個(gè)Xe核心的規(guī)模,達(dá)到了Arc A380相同的水平,當(dāng)然受制于頻率、功耗,性能會(huì)低于Arc A380。
同時(shí),它還有2條幾何流水線、8個(gè)采樣器、4個(gè)像素后端、8個(gè)光追加速器——是的,它有光追!
這也是AMD銳龍6000系列上的Radeon 680M之后,第二家支持硬件光追的核顯。
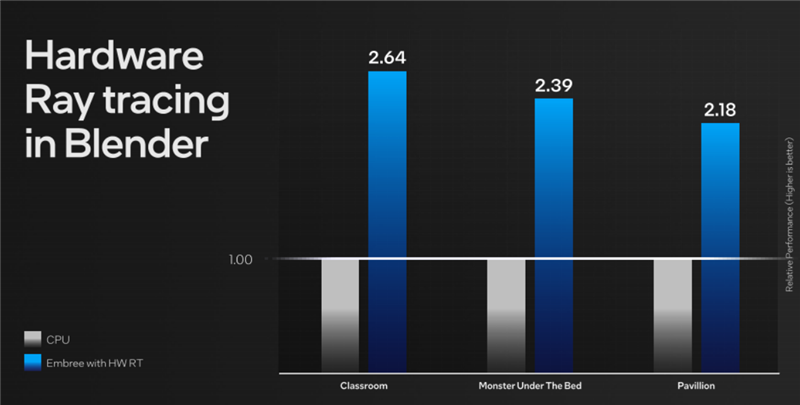
當(dāng)然,這種級(jí)別的核顯不能指望流暢運(yùn)行光追游戲,哪怕有XeSS的加持也不行,但做一些光追加速渲染創(chuàng)作還是很有效率的。
按照Intel的說法,酷睿Ultra核顯利用硬件光追運(yùn)行Blender,性能相比純CPU要快上2倍多。
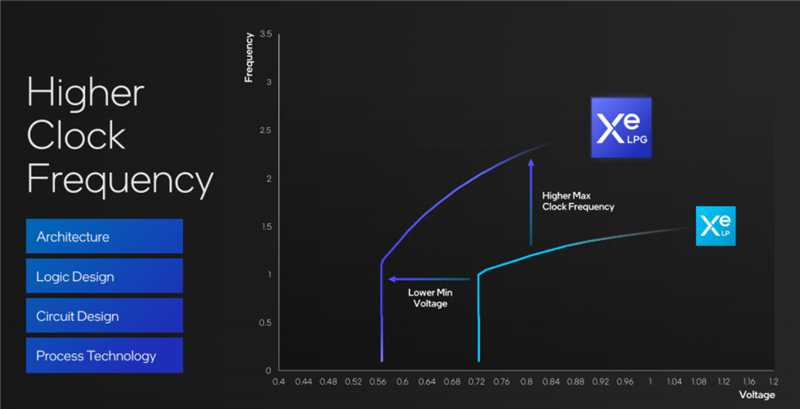
此外,Xe LPG架構(gòu)的頻率/電壓曲線相比上代Xe LP更加高效,比如同樣達(dá)成1GHz頻率,所需最低電壓僅為0.55V左右,降低了接近四分之一。
比如同樣的0.8V左右電壓下,Xe LPG的運(yùn)行頻率可以大大超過2GHz。

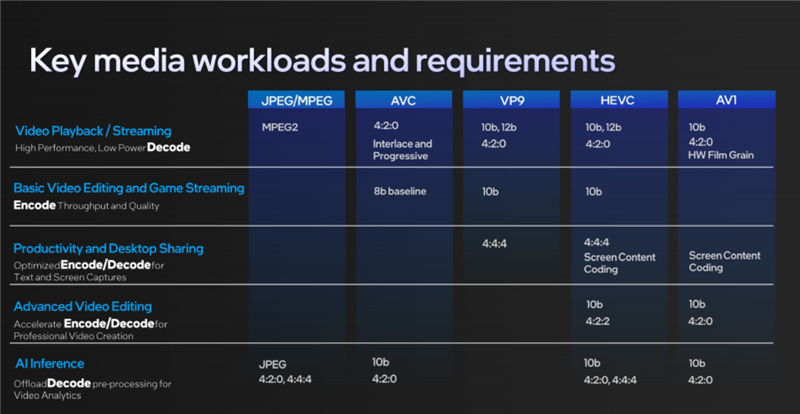
媒體引擎部分和Xe HPG架構(gòu)同樣強(qiáng)大,最高支持8K60 10-bit HDR解碼、8K 10-bit HDR編碼,視頻格式支持VP9、AVC、HEVC(H.265)、AV1等等。
針對(duì)基本視頻播放與流媒體、基本視頻編輯與云游戲、生產(chǎn)力創(chuàng)作與桌面捕捉共享、高級(jí)視頻編輯、AI推理等不同場(chǎng)景,也支持不同級(jí)別的編解碼格式。

顯示輸出部分也不遑多讓,支持最新的HDMI 2.1、DP 2.1 20Gbps、eDP 1.4等輸出格式,最高分辨率可達(dá)單屏8K60 HDR、四屏4K60 HDR、慢動(dòng)作1080p360/2K360。
可以說,無論圖形渲染,還是視頻編解碼、輸出顯示,酷睿Ultra的核顯都達(dá)到了一個(gè)新的高端,真正可以全面媲美入門級(jí)獨(dú)立顯卡。
NPU AI引擎:專業(yè)的人高效做專業(yè)的事
這是一個(gè)AI無處不在的時(shí)代,Intel一貫以來的XPU戰(zhàn)略,更是水到渠成地在從軟到硬全線推進(jìn)AI。
與此同時(shí),AI的使用場(chǎng)景也在迅速?gòu)脑苽?cè)向邊緣和端側(cè)延伸,AI PC的應(yīng)用場(chǎng)景和需求突飛猛進(jìn),包括智能語音降噪、視頻背景模糊、超分辨率、游戲精彩時(shí)刻智能截取、大語言模型對(duì)話,以及文生圖、圖生圖、文生視頻等等AIGC場(chǎng)景。
酷睿Ulra首次引入了神經(jīng)網(wǎng)絡(luò)單元NPU,所有型號(hào)都有,可以從CPU、GPU接手持續(xù)的、低負(fù)載的AI工作,通過專門功能硬件高效運(yùn)行,而且功耗極低。
酷睿Ultra NPU單元既可以執(zhí)行固定功能任務(wù),也可以做可編程計(jì)算,就看實(shí)際需求了,同時(shí)也支持混合精度數(shù)據(jù),并提供標(biāo)準(zhǔn)化的編程接口。
同時(shí),快速響應(yīng)、低延遲的CPU,高性能、高吞吐量的GPU,也都會(huì)閑著,同樣擔(dān)負(fù)部分AI算力需求,比如CPU適合輕量級(jí)的單次推理,GPU適合多媒體、3D渲染,三者合作共同推進(jìn)AI PC。
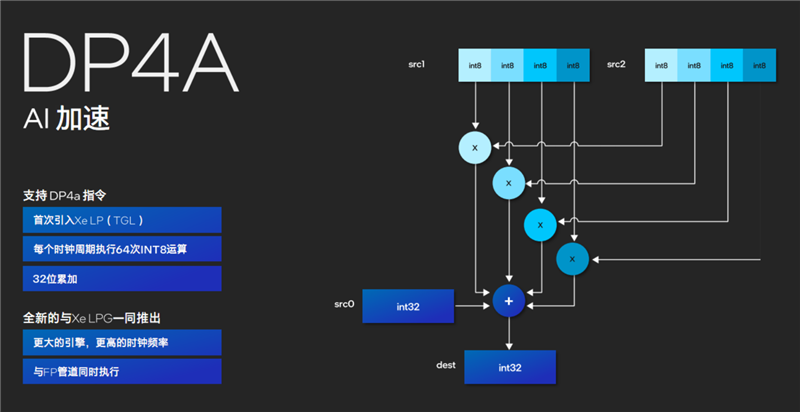
尤其是Xe LPG架構(gòu)的新一代核顯,與銳炫顯卡一樣支持DP4a指令,同樣可用于AI加速。
它面向整數(shù)類型處理,可以與浮點(diǎn)流水線并行,在每個(gè)時(shí)鐘周期內(nèi)可以執(zhí)行多達(dá)64次INT8整數(shù)運(yùn)算,并支持32位累加,也就是融合成INT32整數(shù)類型,再加上更高的頻率,執(zhí)行效率得以大大提升。
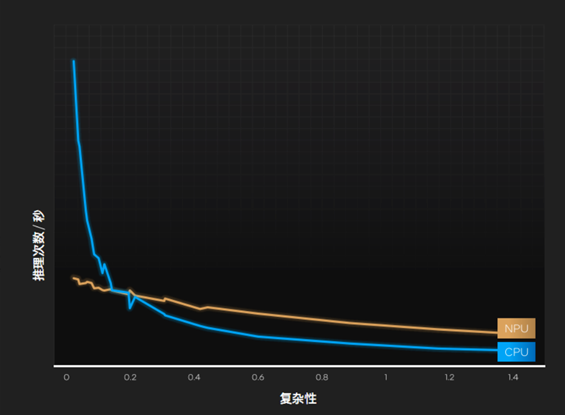
比如輕量級(jí)的神經(jīng)網(wǎng)絡(luò)模型MobileNet v2,在非常低的復(fù)雜度下,CPU的效率是極高的。
但是,隨著復(fù)雜度的增加,CPU很快就跟不上了,這個(gè)時(shí)候就要看NPU的發(fā)揮,在高復(fù)雜度下的效率遠(yuǎn)超CPU,而且非常穩(wěn)定。
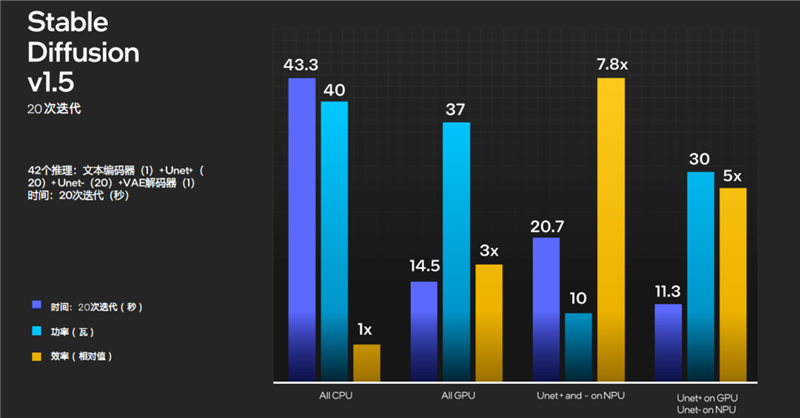
Stable Diffusion這樣的典型文生圖AI應(yīng)用,NPU執(zhí)行起來更是得心應(yīng)手,效率可以全面遠(yuǎn)遠(yuǎn)超越CPU、GPU。
Intel官方實(shí)測(cè),完全使用NPU進(jìn)行推理,所需時(shí)間不到CPU的一半,會(huì)略長(zhǎng)于GPU,但所需功耗比它倆都低得多,相對(duì)效率可以達(dá)到CPU的幾乎8倍、GPU的2倍多。
NPU還可以和CPU、GPU配合,各自承擔(dān)不同的任務(wù),綜合起來大大節(jié)省所需時(shí)間和功耗,效率可以做到CPU的多達(dá)5倍、GPU的接近2倍。

在硬件架構(gòu)上,NPU最關(guān)鍵的就是兩路神經(jīng)計(jì)算引擎和推理流水線,包括MAC陣列、可編程DSP、激活函數(shù)、數(shù)據(jù)轉(zhuǎn)換、存儲(chǔ)與載入等單元,同時(shí)搭配DMA引擎、暫用內(nèi)存單元,構(gòu)成一個(gè)完整的神經(jīng)神經(jīng)網(wǎng)絡(luò)引擎,可以支持多種神經(jīng)網(wǎng)絡(luò)模型。
其中,MAC陣列可以高效靈活地執(zhí)行矩陣乘法和卷積運(yùn)算,每周期多達(dá)2048,支持INT8、FP16數(shù)據(jù)類型。
通俗地講,NPU就是通過專用硬件單元,讓專業(yè)的“人”做專業(yè)的“事”,效率自然高得多,當(dāng)然專用性也意味著一方面缺乏通用性,另一方面需要專門適配。

換言之,AI硬件是容易做的,真正難的是軟件和場(chǎng)景適配、優(yōu)化,如何充分釋放硬件潛力。
在這方面,Intel的影響力和號(hào)召力就體現(xiàn)得淋漓盡致了,一方面與微軟深度合作,全面導(dǎo)入Office、Windows Studio Effects、Teams、DirectML,另一方面整個(gè)行業(yè)都在積極跟進(jìn)。
不但有Adobe、Zoom、Webex、Blender、CyberLink、杜比、虛幻引擎這樣的國(guó)際大牌,也有字節(jié)跳動(dòng)、騰訊、虎牙直播、愛奇藝這樣的國(guó)內(nèi)巨頭。
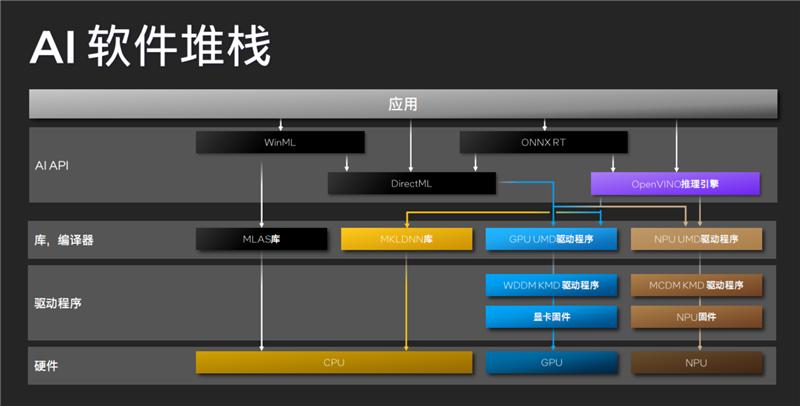
這也得益于Intel全面、成熟、易用的配套軟件開發(fā)平臺(tái),從驅(qū)動(dòng)程序到庫(kù)、編譯器再到OpenVINO這樣的頂層API,都全面針對(duì)CPU、GPU、NPU AI應(yīng)用提供支持,大大簡(jiǎn)化和加速開發(fā),開發(fā)者也可以根據(jù)自己的應(yīng)用和場(chǎng)景需求,靈活選擇最合適、最高效的執(zhí)行途徑。
比如Microsoft Teams/Studio Effects就借助從NPU硬件到OpenVINO引擎的體系來優(yōu)化音頻、視頻的AI加速,Adobe CC通過DirectML API發(fā)揮GPU的能力,視頻分析工作則可以同時(shí)借助NPU、GPU的力量。
Intel 4制造工藝:感受下EUV的力量

再好的硬件設(shè)計(jì),沒有及時(shí)、成熟的制造工藝,只能停留在紙面上。
早些年,Intel走的是Tick-Tock策略,逐年交替升級(jí)工藝和架構(gòu),后來大家都知道,逐漸慢了下來。
而今在基辛格的領(lǐng)導(dǎo)下,Intel正在近乎瘋狂地提速,要在四年內(nèi)實(shí)現(xiàn)五個(gè)制程節(jié)點(diǎn),而且靈活地開放外包與代工,除了用自己工藝造自家產(chǎn)品,還會(huì)引入合適的外部工藝制造部分產(chǎn)品或模塊,并為其他客戶制造產(chǎn)品。
Intel 4已經(jīng)在酷睿Ultra上投入量產(chǎn)并在提升產(chǎn)能。
Intel 3將在Intel 4的基礎(chǔ)上,進(jìn)一步提升設(shè)計(jì)庫(kù)密度,更多地應(yīng)用EUV極紫外光刻技術(shù),增加驅(qū)動(dòng)電流的晶體管并降低通孔電阻。
現(xiàn)已做好生產(chǎn)準(zhǔn)備,將用于明年的Sierra Forest、Granite Rapids兩大至強(qiáng)產(chǎn)品線,前者最多288個(gè)E核。
Intel 20A將進(jìn)入埃米時(shí)代,首發(fā)PowerVia背部供電技術(shù)、RibbonFET全環(huán)繞柵極晶體管技術(shù),用于未來兩代酷睿Arrow Lake、Lunar Lake,將按計(jì)劃在2024年做好投產(chǎn)準(zhǔn)備。
Intel 18A就是20A的升級(jí)版,能效繼續(xù)提升10%,奪回Intel在制程工藝方面的領(lǐng)導(dǎo)地位。
它既會(huì)用于自家的消費(fèi)級(jí)Panther Lake、服務(wù)器級(jí)Clearwater Forest,外部代工也已拿下Arm、愛立信等客,預(yù)計(jì)2025年投產(chǎn)。
再往后,Intel將會(huì)用上ASML的下一代高NA EUV***。
一臺(tái)典型的EUV***價(jià)格超過16億元,重達(dá)180噸,需要4架波音747飛機(jī)和35輛卡車才能運(yùn)輸,還需要加固的地板和更高的天花板才能安裝固定,目前只有荷蘭ASML才能制造。
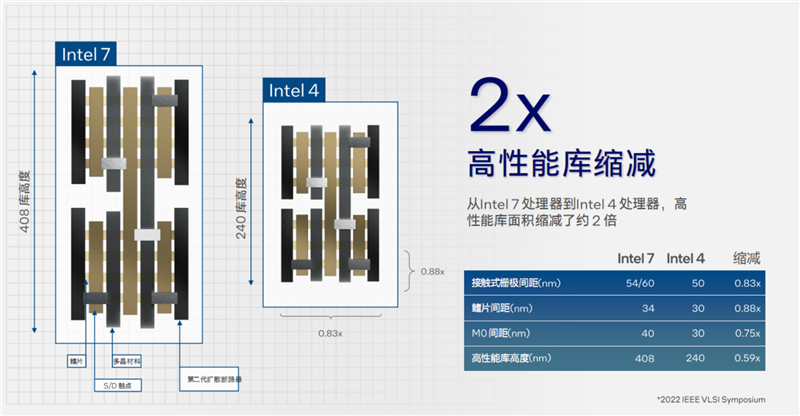
Intel 4工藝的技術(shù)細(xì)節(jié)非常豐富,但因?yàn)閷I(yè)性太強(qiáng),我們不會(huì)過于深入,只講一些比較直觀的變化。
Intel 4工藝的高性能邏輯庫(kù)高度僅為240nm,接觸柵極間距收窄到50nm,M0底層金屬層間距、鰭片間距都做到了30nm,相比于Intel 7分別縮小了41%、17%、12%、25%,整個(gè)庫(kù)的面積只有原來的大約一半。

金屬層堆疊到了多達(dá)18層,密度相當(dāng)高,并針對(duì)高性能計(jì)算進(jìn)行了優(yōu)化,包括5個(gè)增強(qiáng)型銅層、13個(gè)銅互連層,其中多個(gè)層都使用了EUV極紫外光刻,搭配四重曝光技術(shù)。
此外,縮小到30nm的金屬層間距,為布線提供了良好的技術(shù)支持。
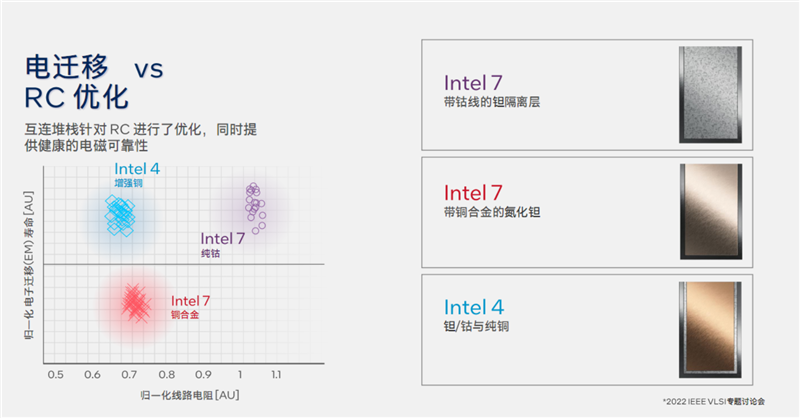
開發(fā)新的制程工藝時(shí),既要在縮小間距的同時(shí)提升導(dǎo)電性、降低電阻,還要保證電子遷移的長(zhǎng)壽命。
Intel 7工藝上使用了不同材料的特殊金屬層,包括帶鈷的鉭隔離層、帶銅合金的氧化碳,但效果不能百分百令人滿意,前者可延長(zhǎng)電子遷移壽命,但電阻變大了,后者可降低電阻,但電子遷移壽命變短了。
Intel 4工藝使用了新的增強(qiáng)銅技術(shù)工藝,結(jié)合了鉭、鈷與純銅材料,結(jié)果非常好地平衡了電子遷移壽命和電阻。

EUV極紫外光刻的引入,不僅可以提升晶體管密度、縮小了整體面積,還大大簡(jiǎn)化了整個(gè)工藝流程。
比如在Intel 7工藝下,沒有EUV,就需要更多的光刻和掩膜環(huán)節(jié),以及更多的分層,而在Intel 4工藝搭配EUV之后,只需單個(gè)層就夠了,在這里的生產(chǎn)步驟減少了多達(dá)3-5倍。
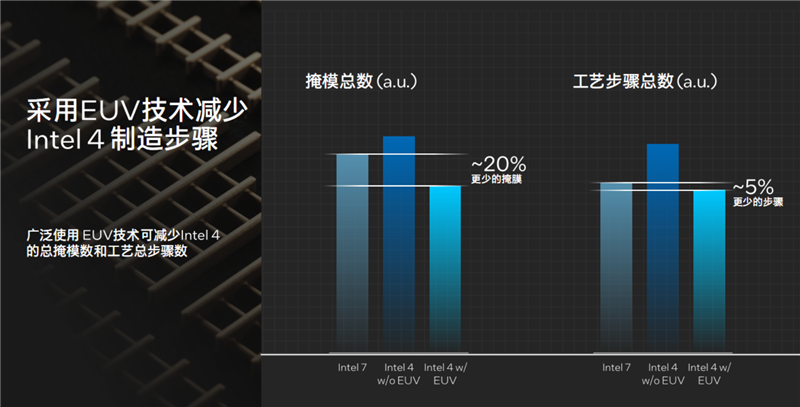
根據(jù)估算,Intel 4工藝如果沒有EUV,無論掩膜總數(shù)還是工藝步驟總數(shù),其實(shí)都是要比Intel 7明顯增加的,從而導(dǎo)致更高的復(fù)雜度和成本,也很容易影響良品率。
EUV的加入,使得掩膜總數(shù)比Intel 7工藝減少了20%,生產(chǎn)步驟總數(shù)也減少了5%。

此外,EUV可以讓連接結(jié)構(gòu)變得非常標(biāo)準(zhǔn)化,Intel 7工藝上的一些非標(biāo)準(zhǔn)連接已經(jīng)不見了,這樣在布局走線方面就可以實(shí)現(xiàn)更加高效的自動(dòng)化。
打個(gè)比方就像是堆積木,Intel 4 EUV的標(biāo)準(zhǔn)連接結(jié)構(gòu)就顯示所有積木都是標(biāo)準(zhǔn)接口,拿過來就能對(duì)接,非常整齊。

這一套組合拳下來,Intel 4的良品率就做得非常好,第一代就超越了14nm、10nm經(jīng)過多代優(yōu)化的水平。
這對(duì)于后續(xù)的Intel 3/20A/18A也奠定了很好的基礎(chǔ),是實(shí)現(xiàn)四年五代制程節(jié)點(diǎn)的一個(gè)關(guān)鍵點(diǎn)。
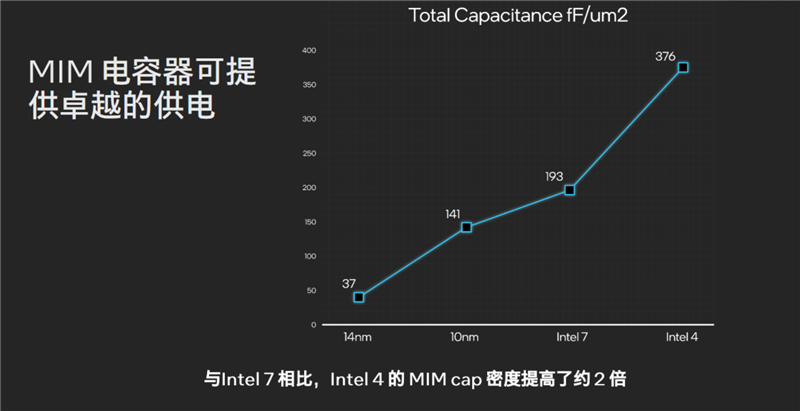
此外,Intel 4工藝下的MIM(金屬-絕緣體-金屬)電容的密度也得到了加大,對(duì)比Intel 7工藝下提高了約2倍,能讓處理器實(shí)現(xiàn)更高效的供電。
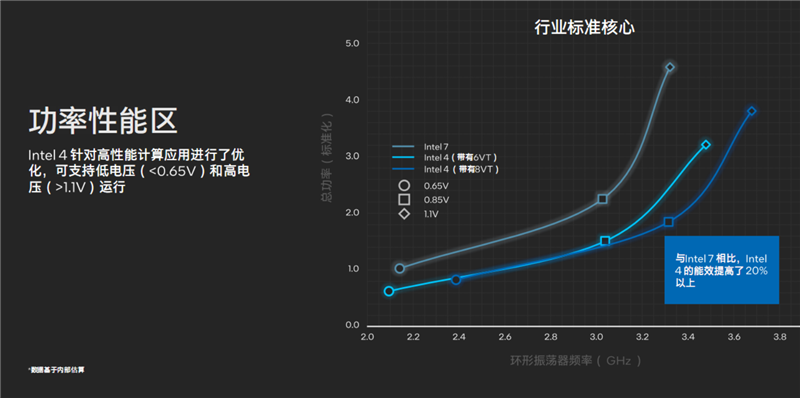
Intel 4工藝搭配6VT或者8VT,可以大大改善能效,可以在0.65V以下低電壓、1.1V以上高電壓運(yùn)行,綜合能效比Intel 7工藝提升了超過20%,再結(jié)合全新的架構(gòu)設(shè)計(jì),這才使得酷睿Ultra成為史上能效最高的一代。
總的來說,Intel 4工藝搭配EUV實(shí)現(xiàn)了一次技術(shù)和效率層面的飛躍,良品率也非常理想。雖然現(xiàn)在做不到足夠高的頻率,以至于無法應(yīng)用于頂級(jí)游戲本和桌面市場(chǎng),而且只會(huì)用這一代,不像14nm、10nm那樣會(huì)多次迭代挖掘潛力,但也為后續(xù)的Intel 3/20A/18A開了一個(gè)好頭。
相信隨著工藝技術(shù)的不斷推進(jìn)與成熟,尤其是隨著EUV的不斷深入與完善,后邊幾代制程工藝會(huì)有更好的表現(xiàn)。
封裝技術(shù)與組裝流程:一分為四、合四為一的魔術(shù)

所謂封裝(package),就是把做好的芯片包裝起來,安裝在主板上,用于主板和芯片之間的供電、信號(hào)傳輸,也可以保護(hù)芯片。
早期的封裝都比較簡(jiǎn)單,作用也很單一,而隨著制造技術(shù)的復(fù)雜度、成本急劇增加,加之應(yīng)用需求的多樣化,各種先進(jìn)封裝技術(shù)應(yīng)運(yùn)而生。

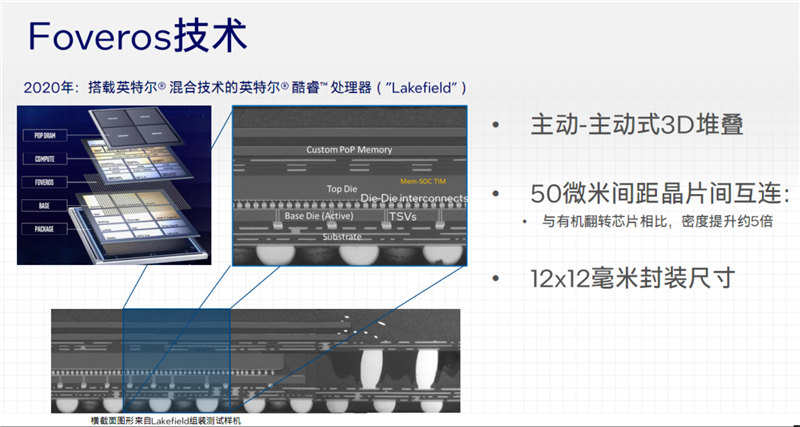

其實(shí)早在1965年,Intel創(chuàng)始人之一、半導(dǎo)體行業(yè)傳奇戈登·摩就預(yù)言過,在構(gòu)建大型芯片系統(tǒng)時(shí),將其分解為單獨(dú)封裝并互相連接的較小的功能模塊,可能更具經(jīng)濟(jì)性。——這就是眼光!
目前,Intel已經(jīng)在多個(gè)產(chǎn)品上使用了不同的先進(jìn)封裝技術(shù),比如2017年的Straix 10首次時(shí)候用EMIB(嵌入式多芯片互連橋接),2023年的Sapphire Rapids第四代至強(qiáng)也用了它。
2020年的Lakefiel處理器嘗試主動(dòng)式3堆疊技術(shù)Foveros,2022年的Ponte Vecchio GPU加速器則綜合了Foveros、EMIB封裝,也叫作Co-EMIB。
同時(shí),Intel還準(zhǔn)備了Foveros Omni、Foveros Direct等新的封裝技術(shù)。

酷睿Ultra則是首個(gè)應(yīng)用Foveros封裝技術(shù)的消費(fèi)級(jí)處理器,四個(gè)不同Tile模塊利用它組裝在一起,可以實(shí)現(xiàn)極低功耗、極高密度的芯片間互聯(lián),可以為每個(gè)模塊選擇不同的最合適的制造工藝,可以靈活定制不同模塊組合實(shí)現(xiàn)不同SKU型號(hào),可以提高晶圓使用率和良品率。

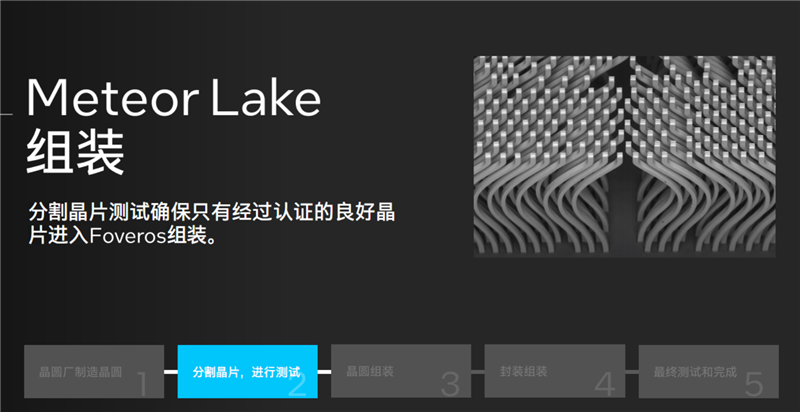
因?yàn)椴捎昧巳碌姆蛛x式模塊化架構(gòu)和先進(jìn)的Foveros封裝工藝,酷睿Ultra的制造、組裝、測(cè)試流程也與以往的處理器截然不同。
它需要使用不用工藝、在不同工廠制造各個(gè)模塊,預(yù)計(jì)作為基底的基礎(chǔ)中介層,各自進(jìn)行切割、測(cè)試,合格的才能組合在一起,統(tǒng)一封裝為復(fù)合體,再進(jìn)行整體性測(cè)試驗(yàn)證,才能得到最終的成品,成為我們看到的一顆顆酷睿Ultra。
對(duì)于處理器封測(cè)具體流程感興趣的,可以參考我們之前的Intel馬來西亞工廠游記,酷睿Ultra就正在那里量產(chǎn)。

到這里,我們的酷睿Ultra Meteor Lake架構(gòu)設(shè)計(jì)、技術(shù)特性、工藝封裝之旅就結(jié)束了,等到12月14日就可以看到具體的型號(hào)、規(guī)格、性能表面,明年初就可以買到全新的AI筆記本。
酷睿Ultra Meteor Lake并不完美,尤其是性能未能達(dá)到預(yù)期,無法應(yīng)用在所有市場(chǎng)領(lǐng)域,但作為Intel 40年來最具革命性的處理器,它在你能想到的幾乎每個(gè)地方都有了飛躍式的變化,是一次極為大膽、激進(jìn)的嘗試,也是對(duì)這個(gè)AI時(shí)代的強(qiáng)力回音,更為后續(xù)發(fā)展奠定了堅(jiān)實(shí)的基礎(chǔ)。
Intel也多次坦然承認(rèn),自己在很多方面都處于追趕的地位,為此正在以前所未有的廣度、深度、速度跑步前進(jìn),而這種變化對(duì)于一家雄踞半導(dǎo)體行業(yè)半個(gè)多世紀(jì)的巨頭來說是相當(dāng)不易的,也是最讓我們欣喜的地方。
期待Intel重返巔峰的那一天!期待你追我趕的激烈競(jìng)爭(zhēng)給我們帶來越來越精彩的技術(shù)和產(chǎn)品!
編輯:黃飛
?





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論