 電子發燒友App
電子發燒友App


近段時間以來,以ChatGPT為首的生成式AI席卷全球,技術升級帶來的生產力巨大提升,也正在對各個產業帶來革命性改變,甚至產業邏輯也需要被重估。
而AI浪潮背后的“賣鏟人”,英偉達一舉邁入了萬億美元市值俱樂部。
英偉達最近一個財季的業績數據同樣令人吃驚。財報數據顯示,英偉達第二財季收入為135.07億美元,創下紀錄新高,這使分析師給出的110.4億美元預期顯得極為保守。
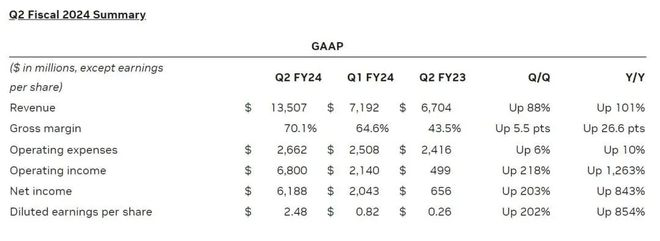
英偉達2023財年Q2營收數據
整體來看,英偉達的業務規模基本達到去年同期的兩倍,這幾乎完全要歸功于市場對其AI芯片的旺盛需求,無論是初創企業,還是打造生成式AI服務的科技巨頭們都在瘋狂搶購這些AI芯片。
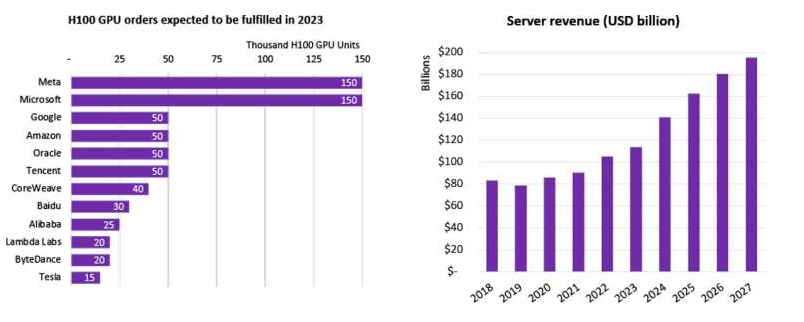
市場研究公司Omdia近日發布報告稱,預計英偉達二季度用于AI和高性能計算應用的H100 GPU的出貨量超過了900噸。并且預計其在未來幾個季度的GPU銷量將大致相同,因此英偉達今年將銷售約3600?噸重的H100 GPU。
并且還不止這些,還有H800,以及上一代的A100、A800等GPU產品。因此,可以預計,隨著英偉達從生成式AI熱潮中獲利,未來一年的出貨量將會加快。
據行業內部消息透露,2023年英偉達H100的產量早已銷售一空,現在交錢訂購,至少要到2024年中才能拿到貨。
誰將獲得多少A100、H100 GPU,以及何時獲得,都是硅谷當前最熱門的話題。
英偉達最大的客戶們似乎也認可這一點。微軟、亞馬遜、谷歌和Meta等國際巨頭最近發布截至6月的財季的財報時都暗示,它們有強烈意向繼續在生成式AI能力上投入資金,盡管在其他領域的資本投資放緩。
AI教父Sam Altman就曾自曝,GPU已經告急,希望用ChatGPT的用戶能少一點。Sam表示,受GPU限制,OpenAI已經推遲了多項短期計劃。
據消息人士透露,中國的科技巨頭百度、騰訊、阿里巴巴以及字節跳動公司今年向英偉達下達的交付訂單金額已超過10億美元,總共采購約10萬張A800和H800芯片;明年交付的AI芯片價值更是達到40億美元。
不光是科技公司在排隊購買H100,沙特阿拉伯、阿聯酋等中東國家也勢頭強勁,一次性就買了幾千塊H100 GPU。其中,阿聯酋阿布扎比技術創新研究所開發的“獵鷹40B”模型是近期開源社區中炙手可熱的商用大模型,反映阿聯酋在增強基礎算力方面不遺余力。
在一篇業內熱轉的《Nvidia H100 GPU:供需》文章中,作者也深度剖析了當前科技公司們對GPU的使用情況和需求。文章推測,小型和大型云提供商的大規模H100集群容量即將耗盡,H100的需求趨勢至少會持續到2024年底。
正如英偉達CEO黃仁勛說:“我們目前的出貨量遠遠不能滿足需求。”
英偉達GPU芯片不光不愁賣,利潤率還高得嚇人。業內專家曾表示,英偉達H100的利潤率接近1000%。消息公布后,迅速引發了芯片戰場上的熱議。
美國金融機構Raymond James在近期的一份報告中透露,H100芯片成本僅約3320美元,但英偉達對其客戶的批量價格仍然高達2.5萬-3萬美元,高達1000%的利潤率導致H100幾乎成為了有史以來“最賺錢”的一款芯片。
這一點從季度財報中也能得到充分印證,英偉達Q2財季凈利潤高達61.8億美元,同比上升843%。據悉,英偉達最近一個財季的調整后營業利潤率達到了58%,這是至少十年來的最高水平,并且較其之前八個財季平均39%的營業利潤率有大幅躍升。
英偉達井噴式的業績增長和長期展望表明,AI需求并非曇花一現。巨大的市場空間,以及超乎想象的前景,吸引諸多廠商參與其中,將進一步刺激行業競爭。
在此趨勢下,AI芯片的戰役正愈演愈烈。
AMD、Intel、IBM等科技巨頭以及新晉企業正陸續推出新的AI芯片,試圖與英偉達AI芯片抗衡;谷歌、微軟、亞馬遜、阿里、百度等公司也紛紛布局自研芯片,以減少對外部供應商的依賴。
AMD:GPU市場的“二號玩家”
當前的AI芯片市場可以說是英偉達的天下,每一位挑戰者想要動搖其根基都并非易事。AMD作為英偉達的老對手,自然不會放任其獨攬如此龐大且增速超快的市場。
對于這位GPU市場的“二號玩家”,大家都期待其能拿出撼動英偉達“算力霸主”地位的“終極武器”。
今年6月,備受業界矚目的AMD發布了Instinct MI300系列產品。Instinct MI300系列產品主要包括MI300A、MI300X兩個版本,以及集合了8個MI300X的Instinct Platform。
針對MI300A,AMD CEO蘇姿豐聲稱,這是全球首個為AI和HPC打造的APU加速卡,采用了“CPU+GPU+內存”的一體化組合形式,擁有13個小芯片,總共包含1460億個晶體管,24個Zen 4 CPU核心,1個CDNA 3圖形引擎和128GB HBM3內存。
Instinct MI300X是一款直接對標英偉達H100芯片,專門面向生成式AI推出的加速器。該產品采用了8個GPU Chiplet加4個I/O內存Chiplet的設計,總共12個5nm Chiplet封裝在一起,使其集成的晶體管數量達到了1530億,高于英偉達H100的800億晶體管,是AMD投產以來最大的芯片,可以加速ChatGPT等大模型應用。
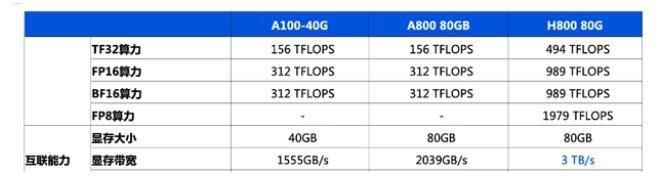
與英偉達的H100芯片相比,AMD Instinct MI 300X的HBM密度是前者的2.4倍,帶寬則為前者的1.6倍,理論上可以運行比H100更大的模型。
此外,AMD還發布了“AMD Instinct Platform”,集合了8個MI300X,可提供總計1.5TB的HBM3內存。
蘇姿豐表示,隨著模型參數規模越來越大,就需要更多的GPU來運行。而隨著AMD芯片內存的增加,開發人員將不再需要那么多數量的GPU,能夠為用戶節省成本。此外,她還透露,MI300X將于今年第三季度向一些客戶提供樣品,并于第四季度量產。
那么,性能優異的MI300X能否與H100一較高下呢?
有業內專家表示,雖然本次AMD的MI300X采用了更大的192GB HBM3,但英偉達的產品也在迭代,等未來MI300X正式發售時,英偉達可能已經推出了參數更強的產品。而且由于AMD未公布新品價格,采用192GB HBM3的MI300X成本可能與H100相比可能不會有顯著的價格優勢。
其次,MI300X沒有H100所擁有的用于加速Transformer大模型的引擎,這也意味著用同樣數量的MI300X將花費更長的訓練時間。當前,用于AI訓練的GPU供不應求,價格水漲船高,MI300X的推出無疑將利于市場的良性競爭,但短期來看,AMD的MI300X可能更多是作為客戶買不到H100的“替代品”。
至頂智庫首席分析也表示,盡管從AMD本次公開的性能參數來看,MI300X在很多方面都優于英偉達的H100,但并不是性能越高,就越多人用,這不是一個正向關系。英偉達深耕GPU領域多年,所擁有的市場認可度和產品穩定性都是AMD所不具備的。另外在軟件生態的建立和開發方面,英偉達的CUDA經過十幾年積累已構建其他競爭對手短時間難以逾越的護城河。
雖然AMD目前也已經擁有了一套完整的庫和工具ROCm,也能完全兼容CUDA,為AMD提供了說服客戶遷移的條件和理由,但兼容只屬權宜之計,只有進一步完善自己的生態才能形成競爭優勢。未來,ROCm需支持更多的操作系統,在AI領域開拓更廣泛的框架,以此吸引更多的開發者,相較于硬件參數,軟件方面的門檻和壁壘更高,AMD需要較長的時間來完善。
Cambrian-AI Research LLC首席分析師Karl Freund在《福布斯》雜志的最新報道中也指出,與英偉達的H100相比,MI300X面臨著一些挑戰。
一方面,英偉達H100已滿載出貨,而MI300X尚處于“襁褓之中”;其次,在AI產業里,英偉達具有最大的軟件生態系統和最多的研究人員,而AMD的軟件生態沒有那么完善。并且,AMD還未公開任何基準測試,而訓練和運行AI大模型不僅僅取決于GPU性能,系統設計也尤為重要。
至于MI300X在內存上的優勢,Karl Freund認為,英偉達也將提供具備相同內存規格的產品,因此這不會成為絕對優勢。
綜合來看,AMD想要撼動如日中天的英偉達,并非易事。
不過,不可否認的是,雖然短期內英偉達的“AI王座”難以撼動,但MI300X依舊是英偉達H100的有力競爭者,MI300X將成為除了英偉達H100以外的“第二選擇”。
從長遠來看,對于英偉達而言,AMD也是值得警惕的競爭對手。
Intel:爭奪AI算力市場寶座
眾所周知,目前GPU資源緊缺,英偉達的100系列在國內禁售,而百模大戰之下算力的需求還在飆升。對于中國市場而言,當前急需AI芯片“解渴”,對于英特爾而言,眼下正值算力緊缺的窗口期,也是進攻的絕佳時機。
今年7月,英特爾面向中國市場推出了AI芯片Habana Gaudi 2,直接對標英偉達GPU的100系列,欲爭奪AI算力市場的寶座。
在發布會現場,英特爾直接將Gaudi 2和英偉達的A100進行比較,其野心可見一斑。根據英特爾公布的數據,Gaudi 2芯片是專為訓練大語言模型而構建,采用7nm制程,有24個張量處理器核心。從計算機視覺模型訓練到1760億參數的BLOOMZ推理,Gaudi 2每瓦性能約A100的2倍,模型訓練和部署的功耗降低約一半。
英特爾執行副總裁、數據中心與人工智能事業部總經理Sandra Rivera表示,在性能上,根據機器學習與人工智能開放產業聯盟ML Commons在6月底公布的AI性能基準測試MLPerf Training 3.0結果顯示,Gaudi 2是除了英偉達產品外,唯一能把MLPerf GPT 3.0模型跑起來的芯片。
隨著大模型的日新月異,英特爾在近幾個月內圍繞著Gaudi 2繼續進行優化。
據介紹,相比A100,Gaudi 2價格更有競爭力,且性能更高。接下來采用FP8軟件的Gaudi 2預計能夠提供比H100更高的性價比。
事實上,去年英特爾就已經在海外發布了Gaudi 2,此次在中國推出的是“中國特供版”。
英特爾強調,目前在中國市場上,英特爾已經和浪潮信息、新華三、超聚變等國內主要的服務器廠商合作。Sandra Rivera表示:“中國市場對人工智能解決方案的需求非常強勁,我們正在與幾乎所有傳統客戶洽談。云服務提供商、通信服務提供商都是企業客戶,因此對人工智能解決方案有著強烈的需求。”
另一方面,在產品路線上,英特爾近年一直強調XPU,即多樣化、多組合的異構計算。在AI相關的產品線上,既有集成AI加速器的CPU處理器、有GPU產品,以及Habana Gaudi系列代表的ASIC類型AI芯片。
大模型的火熱還在持續拉動AI芯片的需求。
據了解,英特爾的Gaudi 2處理器自7月份推出以來銷量一直強勁,英特爾首席財務官David Zinsner在早些時候的一次會議上表示,已經看到越來越多的客戶尋求其Gaudi芯片作為供應短缺的處理器的替代品。
Gaudi是一個人工智能加速的專屬產品。在英特爾產品里,Gaudi是針對大模型工作負載中性能最佳、最優的一個產品。據Sandra Rivera表示:“明年我們還會有下一代產品Gaudi 3發布。在2025年的時候,我們會把Gaudi的AI芯片跟GPU路線圖合二為一,推出一個更整合的GPU的產品。”
日前,英特爾在舊金山舉行的“Intel Innovation”盛會上透露,下一代使用5nm工藝打造的Gaudi 3將在性能方面大幅提升。其中,BF16下的性能提升了四倍、計算能力提升了2倍、網絡帶寬的1.5倍以及HBM容量的提升1.5倍。
展望未來,在Gaudi 3之后, 英特爾計劃推出一個代號為Falcon Shores 的繼任者。
關于Falcon Shores,英特爾沒有披露太多細節。但按照其最初規劃,英特爾會于2024 年推出Falcon Shores芯片、原計劃為“XPU”設計,即集成CPU和GPU。但在上個月的財報會上,英特爾調整了Falcon Shores的計劃,并隨后將其重新定位為獨立GPU,并將于2025年發布。
整體來看,Gaudi系列作為英特爾AI的一艘旗艦,外界也拭目以待Gaudi 2在實際應用中的性能表現和算力實力。從硬件迭代到軟件生態,AI芯片的競爭故事還將繼續。
IBM:模擬AI芯片,引領行業趨勢
人工智能的未來需要能源效率方面的新創新,從模型的設計方式到運行模型的硬件。
IBM最近公布了一款新的模擬AI芯片,據稱其能效比當前業界領先的英偉達H100高出14倍,這款新芯片旨在解決生成式人工智能的主要問題之一:高能耗。這意味著在相同的能量消耗下,它能夠完成更多的計算任務。
這對于大型模型的運行來說尤為重要,因為這些大型模型通常需要更多的能量來運行。IBM的這款新芯片有望緩解生成式AI平臺企業的壓力,并可能在未來取代英偉達成為生成式AI平臺的主導力量。
這是由于模擬芯片的構建方式造成的。這些組件與數字芯片的不同之處在于,數字芯片可以操縱模擬信號并理解0和1之間的灰度。數字芯片在當今時代應用最廣泛,但它們只能處理不同的二進制信號,在功能、信號處理和應用領域也存在差異。
IBM聲稱其14nm模擬AI芯片每個組件可以編碼3500萬個相變存儲設備,可以建模多達1700萬個參數。同時,該芯片模仿了人腦的運作方式,微芯片直接在內存中執行計算,適用于節能語音識別和轉錄。
IBM在多個實驗中展示了使用這種芯片的優點,其中一個系統能夠以非常接近數字硬件設置的準確度轉錄人們說話的音頻。此外,語音識別速度也得到了顯著提升,提高了7倍。這對于許多需要實時響應的應用場景,如語音助手和智能音箱等,將帶來更加順暢的用戶體驗。
IBM這款模擬AI芯片的發布,標志著模擬芯片成為人工智能領域的新趨勢。通過集成大量的相變存儲單元,該芯片能夠實現更高效的計算和能效。隨著技術的不斷發展,預計未來模擬芯片有望成為人工智能領域的新趨勢,成為推動人工智能技術發展的核心驅動力。
總之,IBM的新型模擬AI芯片有望為生成式AI領域帶來重大突破。英偉達GPU芯片是為當今許多生成式AI平臺提供動力的組件。如果IBM迭代該原型并為大眾市場做好準備,它很可能有一天會取代英偉達的芯片成為當前的中流砥柱。
SambaNova:新型AI芯片,挑戰英偉達
高端GPU持續缺貨之下,一家要挑戰英偉達的芯片初創公司成為行業熱議焦點。
這家獨角獸企業SambaNova剛發布的新型AI芯片SN40L,該芯片由臺積電5nm工藝制造,包含1020億晶體管,峰值速度638TeraFLOPS,高達1.5T的內存,支持25.6萬個token的序列長度。

與主要競品相比,英偉達H100最高擁有80GB HBM3內存,AMD MI300擁有192GB HBM3內存。SN40L的高帶寬HBM3內存實際比前兩者小,更多依靠大容量DRAM。
SambaNova?CEO?Rodrigo Liang表示,雖然DRAM速度更慢,但專用的軟件編譯器可以智能地分配三個內存層之間的負載,還允許編譯器將8個芯片視為單個系統。
除了硬件指標,SN40L針對大模型做的優化還有同時提供密集和稀疏計算加速。
Gartner分析師認為,SN40L的一個可能優勢在于多模態AI。GPU的架構非常嚴格,面對圖像、視頻、文本等多樣數據時可能不夠靈活,而SambaNova可以調整硬件來滿足工作負載的要求。
相比其他芯片供應商,SambaNova業務模式也比較特別,芯片不單賣,而是出售其定制技術堆棧,從芯片到服務器系統,甚至包括部署大模型。
Rodrigo Liang指出,當前行業標準做法下運行萬億參數大模型需要數百枚芯片,我們的方法使總擁有成本只有標準方法的1/25。
根據Rodrigo Liang的說法,8個SN40L組成的集群總共可處理5萬億參數,相當于70個700億參數大模型。全球2000強的企業只需購買兩個這樣的8芯片集群,就能滿足所有大模型需求。
目前,SambaNova的芯片和系統已獲得不少大型客戶,包括世界排名前列的超算實驗室,日本富岳、美國阿貢國家實驗室、勞倫斯國家實驗室,以及咨詢公司埃森哲等。
云服務商自研AI芯片,擺脫英偉達
當下,英偉達還是當之無愧的“AI算力王者”,A100、H100系列芯片占據金字塔頂尖位置,是ChatGPT這樣的大型語言模型背后的動力來源。
然而,不管是為了降低成本,還是減少對英偉達的依賴、提高議價能力,包括谷歌、亞馬遜、微軟、特斯拉、Meta、百度、阿里等在內的科技巨頭們也都紛紛下場自研AI芯片。
以微軟、谷歌、亞馬遜三巨頭為例來看,據不完全統計,這3家公司已經推出或計劃發布了8款服務器和AI芯片。
在這場AI芯片競賽中,亞馬遜似乎占據了先機,已擁有兩款AI專用芯片——訓練芯片Trainium和推理芯片Inferentia。2023年初,專為人工智能打造的Inferentia 2發布,將計算性能提高了三倍,加速器總內存提高了四分之一,吞吐量提高了四分之一,延遲提高了十分之一。Inf2實例最多可支持1750億個參數,這使其成為大規模模型推理的有力競爭者。
而早在2013年,谷歌就已秘密研發一款專注于AI機器學習算法的芯片,并將其用在內部的云計算數據中心中,以取代英偉達的GPU。2016年5月,這款自研芯片公諸于世,即TPU。
2020年,谷歌實際上已在其數據中心部署了人工智能芯片TPU v4。不過直到今年4月4日,谷歌才首次公開了技術細節:相比TPU v3,TPU v4性能提升2.1倍。基于TPU v4的超級計算機擁有4096塊芯片,整體速度提高了約10倍。谷歌稱,對于類似大小的系統,谷歌能做到比Graphcore IPU Bow快4.3-4.5倍,比英偉達A100快1.2-1.7倍,功耗低1.3-1.9倍。
目前,谷歌已將負責AI芯片的工程團隊轉移到了谷歌云,旨在提高谷歌云出售AI芯片給租用其服務器的公司的能力,從而與更大的競爭對手微軟和亞馬遜云科技相抗衡。雖然英偉達提供的GPU算力優勢在前,但引爆本次AI的兩位“大拿”OpenAI、Midjourney的算力系統采購的并非英偉達的GPU,而是用了谷歌的方案。
相比之下,微軟在更大程度上依賴于英偉達、AMD和英特爾等芯片制造商的現成或定制硬件。
不過,據The Information報道,微軟也正在計劃推出自己的人工智能芯片。
了解該項目的知情人士稱,微軟早在2019年就開始在內部開發代號為“雅典娜”的芯片,這些芯片已經提供給一小批微軟和OpenAI員工,他們已經在測試這項技術。微軟希望這款芯片的性能比其斥資數億美元從其他供應商側購置的芯片性能更優,這樣就可以為價值高昂的人工智能工作節省成本。
據悉,這些芯片是為訓練大語言模型等軟件而設計,同時可支持推理,能為ChatGPT背后的所有AI軟件提供動力。另據一位知情人士透露,微軟的AI芯片規劃中囊括了雅典娜芯片的未來幾代產品,最初的雅典娜芯片都將基于5nm工藝生產,可能在明年進入大規模生產階段。
今年5月,微軟還發布了一系列芯片相關招聘信息,正在為AISoC(人工智能芯片及解決方案)團隊尋找一名首席設計工程師。據稱,該團隊正在研究“能夠以極其高效的方式執行復雜和高性能功能的尖端人工智能設計”。換句話說,微軟某種程度上已把自己的未來寄托在人工智能開發機構OpenAI的一系列技術上,想要制造出比現成的GPU和相關加速器更高效的芯片來運行這些模型。
與此同時,Meta公司披露其正在構建首款專門用于運行AI模型的定制芯片——MTIA芯片,使用名為RISC-V的開源芯片架構,預計于2025年問世。
另一邊,隨著美國對高性能芯片出口限制措施不斷加強,英偉達A100、H100被限售,A800、H800嚴重缺貨,國產AI芯片肩負起填補市場空缺的重要使命。
目前,包括華為、阿里、百度昆侖芯、壁仞科技、寒武紀、天數智芯、瀚博半導體等也在GPU賽道發力,取得一定成績。不過需要重視的是,盡管國產GPU在價格方面有一定優勢,但在算力和生態方面,仍然與英偉達存在差距。
整體來看,當英偉達的一些主要客戶開始自己開發AI芯片,無疑會讓英偉達面臨更為激烈的競爭。
根據TrendForce集邦咨詢數據顯示,目前主要由搭載英偉達 A100、H100、AMD MI300,以及大型CSP業者如Google、AWS等自主研發ASIC的AI服務器成長需求較為強勁,2023年AI服務器出貨量出貨量預估近120萬臺,年增率近38%,AI芯片出貨量同步看漲,可望成長突破五成。
在市場的巨大需求下,上述一眾廠商的謀劃明顯是奔著跟英偉達搶生意而來。而面對行業“圍剿”的同時,摩根士丹利分析師也給英偉達貼上了“泡沫”的標簽。
很多人或許認為,英偉達借力AI熱潮過得風生水起是個新現象,但實際上這醞釀已久。英偉達在ChatGPT面世十年前就定下了AI戰略,據標普全球市場財智匯編的記錄,英偉達早在2006年就開始向投資者宣傳旗下為AI開發人員所用的CUDA編程語言。
英偉達的AI戰略具有長期性和前瞻性,只是如今隨著AI技術的崛起,那顆在十幾年前射出的子彈,在今天擊中英偉達眉心。
當然,在市場中眾多企業的追趕下,英偉達也并沒有停下自己的腳步。今年8月,在洛杉磯的SIGGRAPH大會上,英偉達拿出了最新一代依托于搭載首款HBM3e處理器的GH200 Grace Hopper超級芯片平臺,證明這股AI熱并非搖搖欲墜的空中樓閣。
與當前一代產品相比,最新版本的GH200超級芯片內存容量增加了3.5倍,帶寬增加了3倍;相比最熱門的H100芯片,其內存增加1.7倍,傳輸頻寬增加1.5倍。
可見,除了現有A100、H100等熱門產品出貨持續維持增長以外,英偉達也在持續發布多項用于AI和數據中心的新產品,以進一步鞏固自身在AI領域的話語權和統治力。
雖然隨著時間的推移,英偉達可能會面臨比現在更激烈的競爭。
但從當前進程來看,英偉達和黃仁勛讓算力=GPU=英偉達的“理念”植入人心,而這么廣闊的市場,竟然真的幾乎只有英偉達一家公司一家獨大,英偉達的業績一路狂飆、英偉達在芯片領域的統治力,目前尚看不到盡頭。
雖然這種狂飆不太可能永遠持續下去,但英偉達給出的信號強烈暗示,其進程遠未結束,AI狂飆才剛開始。
編輯:黃飛

























 工商網監
工商網監
評論