 電子發燒友App
電子發燒友App


AMD RDNA的4年:又一個Zen還是新的Bulldozer? ? 2019年,AMD推出了一款新的GPU架構,這是該公司七年來首次推出主要的圖形芯片設計。自首次亮相以來,該架構經歷了兩次修訂,強調了chiplet和緩存在渲染領域的重要性。鑒于這些發展,評估AMD憑借其工程能力所取得的成就并考慮每次更新的影響是有意義的。
我們將探索這項技術,評估其在游戲中的表現,并研究其對AMD的財務影響。
RDNA是否像Zen一樣取得了巨大的成功?或者,各種各樣的修改是否會給AMD帶來另一個“Bulldozer”時刻?讓我們來看看。
為什么GCN需要改變
目前AMD的GPU 分為兩個截然不同的產品領域,一個是針對游戲的,另一個是用于超級計算機、大數據分析和機器學習系統的。
然而,它們都有著相同的傳統——一種被稱為Graphics Core Next(GCN)的架構。它首次出現于2012年,盡管在此過程中進行了一些重大修改,但仍使用了近10年。GCN是對其前身TeraScale的徹底改革,從一開始,它就被設計為具有高度可擴展性,在圖形和通用計算(GPGPU)應用中同樣適用。
縮放是處理單元組合在一起的方式。從GCN的最初版本到最終版本,GPU的基礎由4個計算單元(CU)組成。
每個處理器都包含4個SIMD(單指令,多數據)矢量單元,在16個數據點上執行數學運算,大小為32位,還有一個標量單元用于基于整數的邏輯運算。
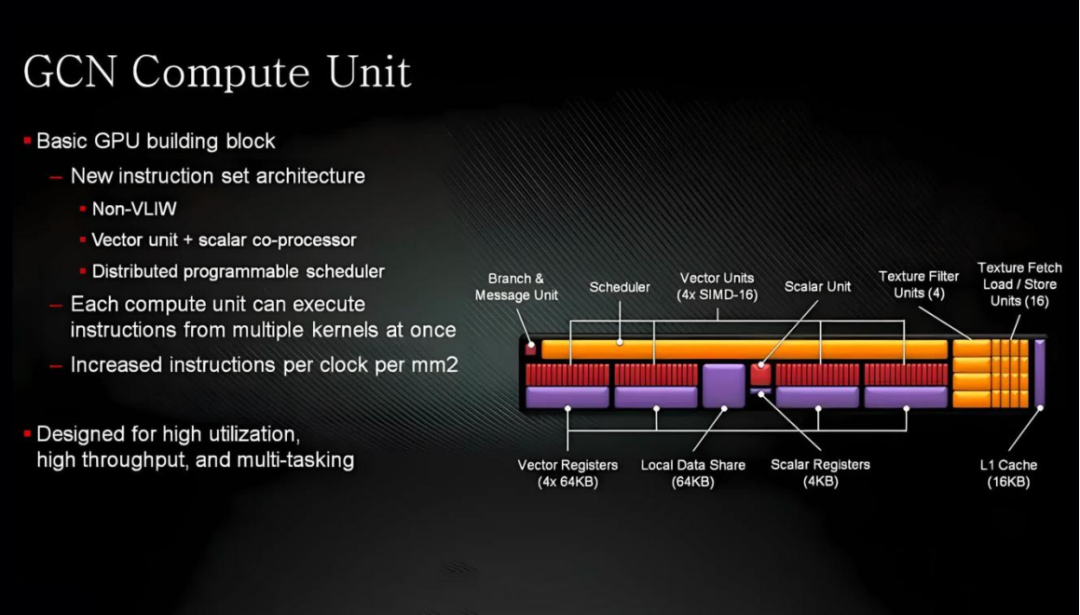
每個矢量SIMD都有一個64 kB的寄存器文件,所有四個單元共享一個64 kB的暫存塊(稱為本地數據共享,LDS),所有處理單元共享一個16 kB的L1數據緩存。四組CU共享一個16 kB的標量緩存和一個32 kB的指令緩存,所有這些緩存都鏈接到一個GPU級的L2緩存。
到2018年GCN 5.1發布時,這些都沒有太大變化,盡管對緩存層次結構的操作方式進行了多次改進。然而,對于游戲世界來說,GCN有一些明顯的缺點,但可以總結為,對于開發者來說,從芯片中獲得處理吞吐量和帶寬利用率方面的最佳性能是一個挑戰。
例如,GPU以64個線程為一組(每個線程稱為一個波或波前)進行調度,每個SIMD單元可以使用不同的波發出,最多排隊10個深度。然而,指令的發布率是每4個周期1次,因此為了確保單元保持繁忙,需要調度大量線程——這在計算世界中是可以實現的,而在游戲中則不然。
GCN的第一個版本擁有稱為異步計算引擎(ACE)的硬件結構。當涉及到在3D游戲中的渲染幀時,GPU會由排在長隊列中的系統發出命令。然而,它們并不都需要按照嚴格的線性順序完成,這就是ACE發揮作用的地方。
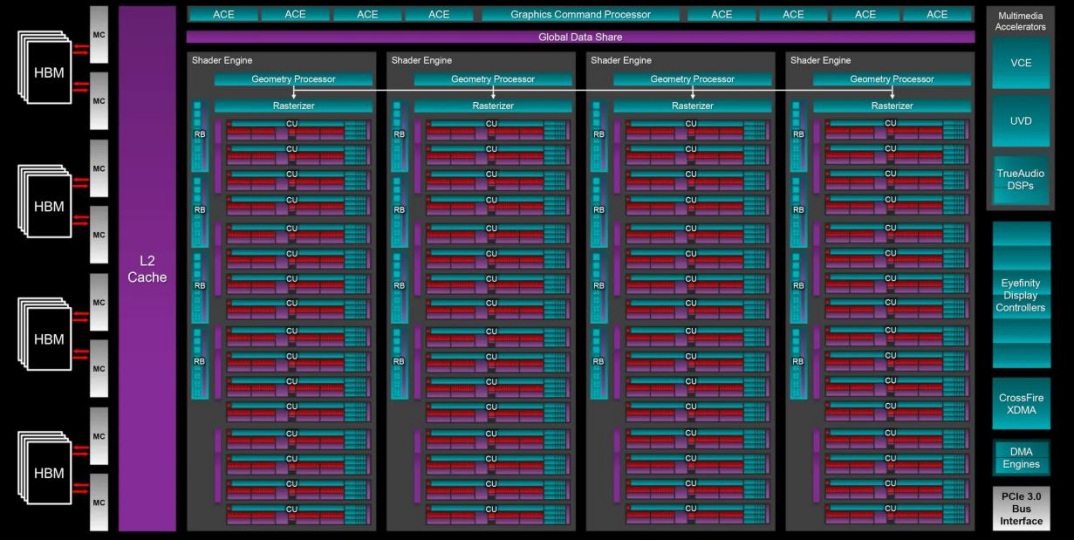
基于GCN的GPU基本上可以將隊列分成三種不同的類型(分別用于圖形命令、計算工作和數據事務),然后相應地對它們進行調度。然而,當時Direct3D API對該系統沒有太多支持,盡管2015年Direct3D 12發布后,異步著色就風靡一時。AMD利用了這一點,使GCN更加專注于計算。
這一點從AMD在高端游戲顯卡市場推出的最新產品——售價700美元的Radeon VII(見下圖)中可以明顯看出。它在4096位寬總線上擁有60個cu(完整芯片有64個cu)和16gb HBM2內存,絕對是一個GPU怪物。
與同樣售價700美元的GeForce RTX 2080相比,它在某些游戲中可能會更快,但大多數基準測試結果表明,該架構并不適合現代3D游戲世界。
GCN 5.1主要用于專業工作站卡,Radeon VII本質上只不過是一款權宜之計的產品,專為游戲愛好者而設計,而下一代GPU正準備亮相。
僅僅四個月后,AMD發布了長期運行的GPU架構的繼任者RDNA。通過這一新設計,AMD成功解決了GCN的大部分故障,第一款采用這種架構的顯卡Radeon RX 5700 XT清楚地突顯了它比GCN更適合游戲。
GPU的“一小步”
2017年推出Ryzen系列CPU時,采用了新的Zen設計,買家得到了全新的架構,從頭開始重新構建。RDNA的情況并非如此,因為基本概念在本質上仍然類似于GCN。然而,幾乎所有內部的東西都經過了調整,使游戲開發者更容易從GPU中獲得最大可能的性能。?

每個CU的SIMD計數從4個切換到2個,每個CU現在處理32個數據點,而不是16個。調度單元現在可以以32或64的批處理線程,在前者的情況下,SIMD單元現在可以被發出,并在每個周期處理一條指令。
僅這兩個變化就使開發人員更容易讓GPU保持忙碌,盡管這確實意味著編譯器在選擇正確的波大小進行處理時需要做更多的工作。AMD為計算和幾何著色器選擇了32,為像素著色器選擇了64,盡管這并不是一成不變的。
CU現在是成對分組的(稱為工作組處理器,WGP),而不是四元組,雖然指令和標量緩存仍然是共享的,但它們現在只需要為兩個CU提供服務。最初的16kB L1緩存被調整并重新標記為L0,而新的128kB L1現在為四個WGP提供服務——兩個WGP都具有128字節大小的緩存線(有助于提高內部帶寬利用率)。
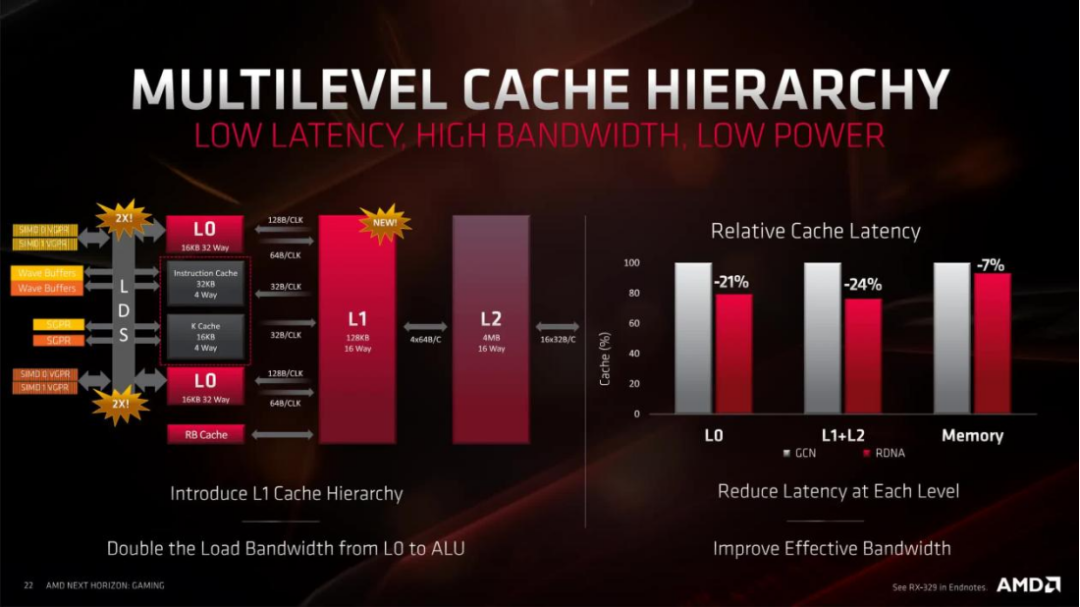
現在,GPU的每個部分都使用了無損數據壓縮,全面降低了延遲,甚至更新了紋理尋址單元。所有這些更改都有助于減少移動數據、刷新緩存等所浪費的時間。
但也許RDNA第一個版本最令人驚訝的方面不是架構上的變化,而是它的第一次迭代是在中端、中等價位的顯卡上。Radeon RX 5700 XT中的Navi 10芯片并不是一塊巨大的硅片,里面裝有計算單元,而是只有251平方毫米的大小和40個CU。它與Radeon VII中的Vega 20 GPU在同一臺積電N7工藝節點上制造,體積小24%,這對晶圓產量來說非常好。
然而,它的CU也減少了38%,盡管就晶體管數量而言,人們不可能指望所有額外的更新和緩存都是免費的。但在游戲中測試時,它的平均速度僅比Radeon VII慢9%,最重要的是,它便宜了300美元。
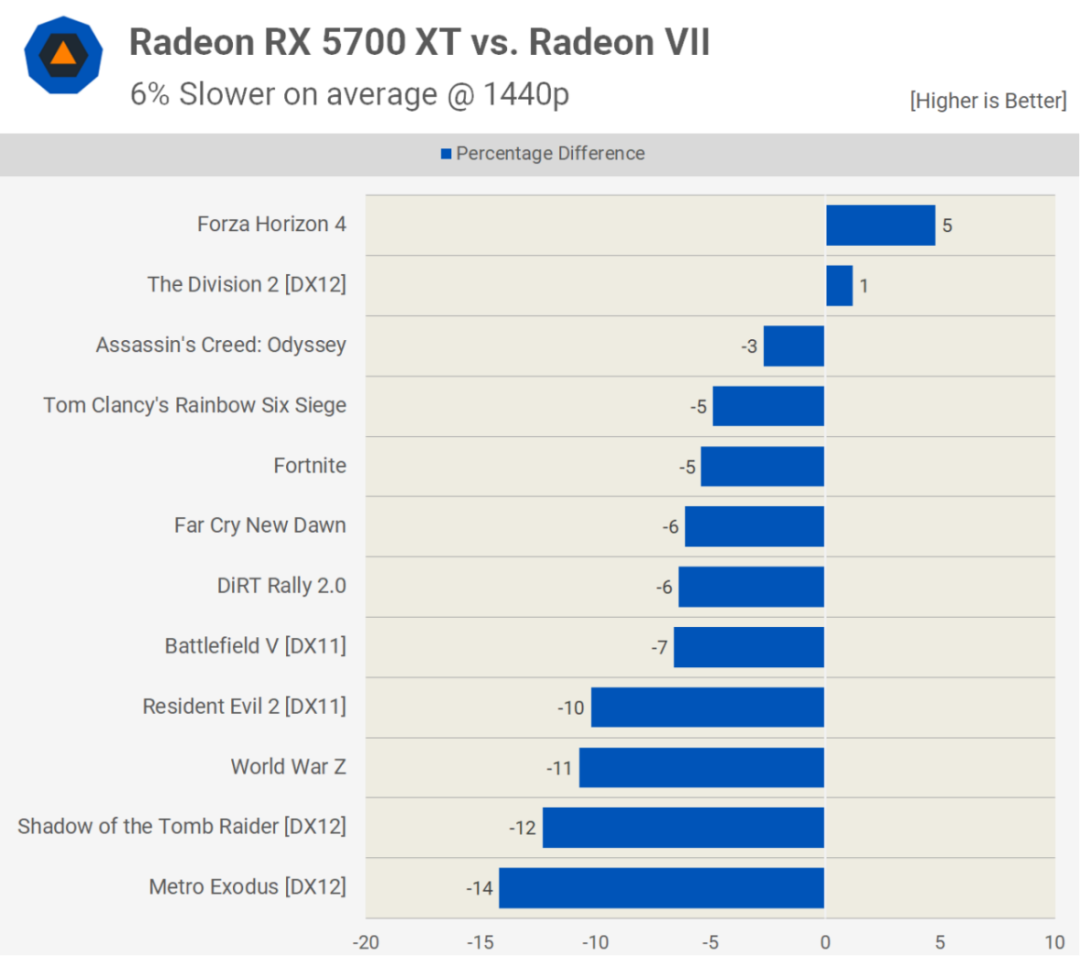
總的來說,它是新架構的一個有希望的入口,因為RDNA是朝著正確方向邁出的一步,盡管有點小。由于其性能介于Radeon RX Vega 56和Radeon VII之間,它在速度、功耗和零售價格之間取得了良好的平衡。
不過,新GPU的推出并非沒有問題,盡管RDNA在近30種不同的產品中找到了歸宿(通過三種芯片設計變體),但一些人對AMD沒有更強大的產品可供銷售感到失望。
幸運的是,他們不用等太久這一問題就能被解決。
RDNA第二輪
Radeon RX 5700 XT發布一年多后,當世界正在與全球疫情作斗爭時,AMD發布了RDNA 2。從表面上看,除了兩個新的東西之外,幾乎沒有什么變化——紋理單元被升級,以便它們可以執行光線三角形相交測試,并且添加了額外的最后一級緩存(LLC)。
前者是一個具有成本效益的補充,使GPU能夠以最少的額外晶體管數量處理光線跟蹤,但后者并不是零碎的產品,因為它遠不止幾MB。在GPU歷史上,6MB的LLC被認為是“大”的,所以當AMD在第一個RDNA 2芯片Navi 21中硬塞進128MB時,它不僅震驚了GPU愛好者,而且永遠改變了圖形處理器的發展方向。

雖然由于芯片制造方法的改進,處理器變得越來越快,能力也越來越強,但DRAM卻很難跟上。要使數十億個微小的電容器收縮而不出現問題要困難得多。不幸的是,GPU越強大,就需要越多的內存帶寬來保持數據。
英偉達選擇采用美光的GDDR6X技術,并在GPU上添加大量內存接口來解決這個問題。然而,這種RAM比標準GDDR6更貴,額外的接口只會使芯片尺寸更大。AMD的方法是利用其CPU部門的緩存技術,并在其RDNA2芯片中注入大量LLC。
通過這樣做,對容納快速RAM的寬內存總線的需求顯著減少,所有這些都有助于控制GPU芯片尺寸和顯卡價格。芯片尺寸在這里很重要,因為Navi 21本質上是兩個Navi 10(總共80個CU),都被一堵緩存墻包圍。
后者由103億個晶體管組成,而新芯片容納了這個數字的兩倍多——268億個。額外的62億美元主要用于所謂的無限緩存,盡管還有其他變化。AMD對整個架構進行了重新調整和精簡,使RDNA 2芯片能夠以比其前身更高的時鐘速率運行。
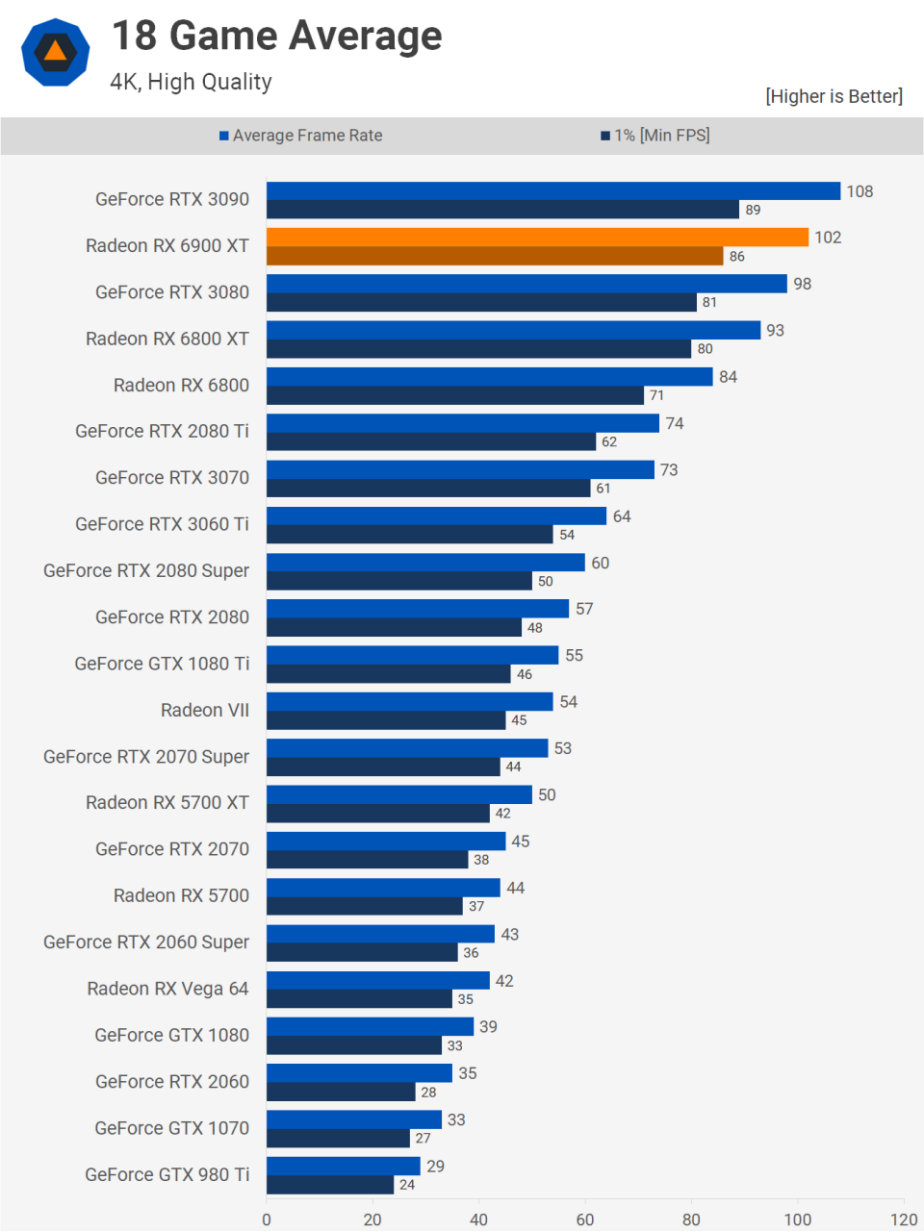
當然,如果最終產品不好,這些都無關緊要。盡管Radeon RX 6900 XT的售價為1000美元,但它提供了GeForce RTX 3090級別的性能,價格比它低500美元。它并不總是處于平均水平,根據所使用的游戲和分辨率,700美元的GeForce RTX 3080也一樣快。
在這個價位,AMD的Radeon RX 6800 XT和RX 6800分別比RTX 3080低50美元和120美元。6800和RTX 3090的性能相差近30%,但價格相差63%。AMD可能沒有贏得性能桂冠,但不可否認,在GPU價格無處不在的時候,這些產品仍然非常強大,物有所值。
但與此相反的是光線追蹤性能。簡言之,它遠不如英偉達的Ampere GPU所實現的好,盡管考慮到這是AMD首次涉足物理正確光建模領域,其功能并不令人驚訝。

英偉達選擇設計和實現兩個大型定制ASIC(專用集成電路),用于處理射線三角形相交和BVH(邊界體積層次結構)遍歷計算,AMD選擇了一種更溫和的方法。對于后者,將沒有專門的硬件,通過計算單元處理例程。
這個決定是基于保持模具尺寸盡可能小。Navi 21芯片相當大,面積為521平方毫米,雖然英偉達很樂意提供更大的處理器(RTX 3090中的GA102面積為628平方毫米),但增加定制單元會使該領域更加突出。

同年11月,微軟和索尼發布了他們的新Xbox和PlayStation游戲機,這兩款游戲機都采用了定制的AMD GPU(CPU和GPU在同一個芯片中),它使用RDNA 2來處理圖形方面的問題,不包括Infinity Cache。由于需要保持這些芯片盡可能小,AMD選擇這一特定路線的原因變得非常清楚。
這一切都是為了改善其圖形部門的財務狀況。
資金和利潤很重要
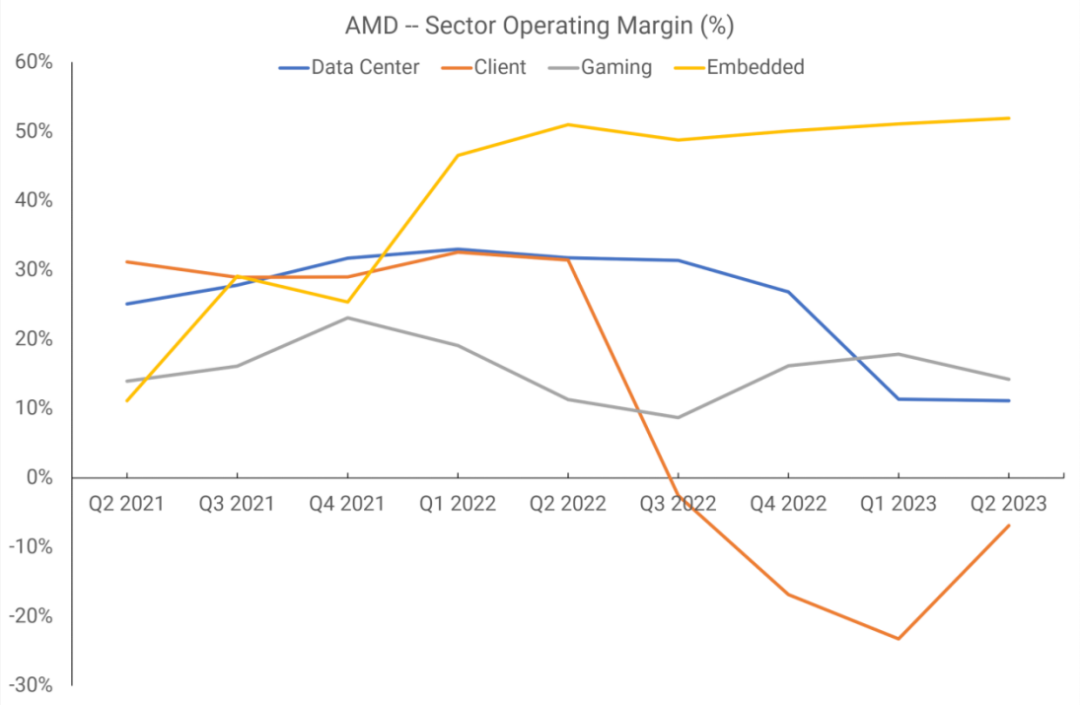
在2021年下半年之前,AMD僅將其收入和營業收入數據分為兩個部門:處理器和顯卡,以及企業、嵌入式和半定制。筆記本電腦中顯卡和獨立GPU的銷售收入流入前者,而Xbox和PlayStation主機的APU銷售收入流入后者。
下圖是2018年第一季度到2021年第一季度的營業利潤率情況。
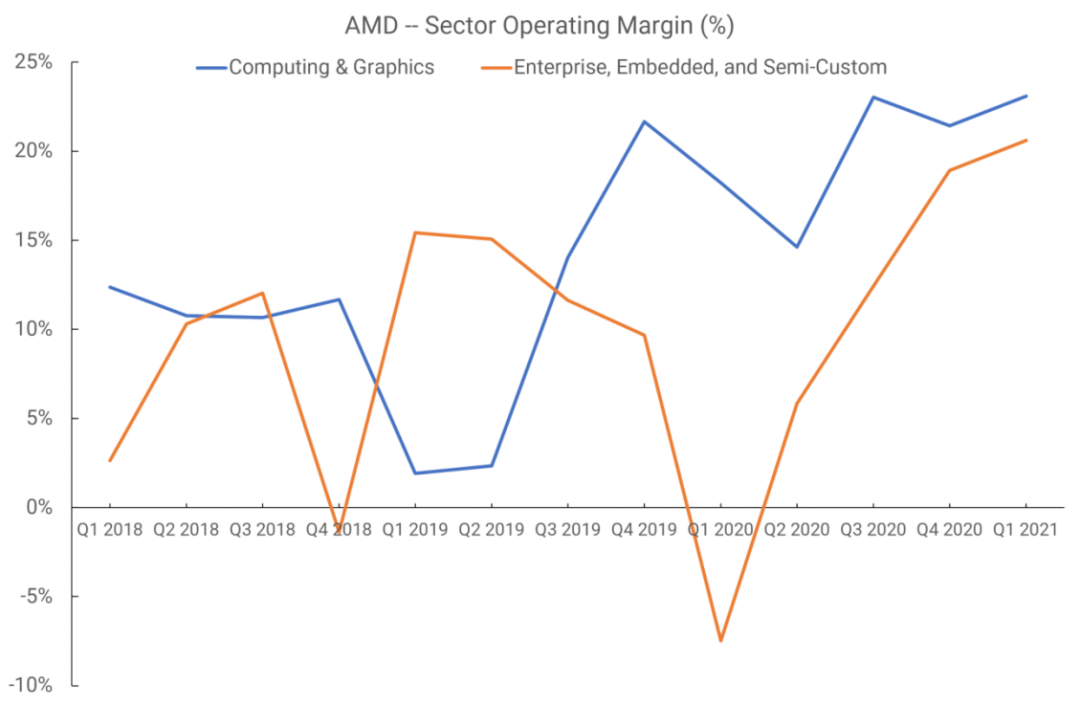
RDNA于2019年第二季度推出,但這種銷售的收入要到下個季度才會真正開始顯現,因為只有兩種型號的顯卡安裝了這種新芯片。我們無法判斷運營利潤率的增長是否得益于GPU架構,因為這些數據還包括CPU銷售。
然而,從2021年第二季度開始,AMD將報告部門重新劃分為四個部門:數據中心、客戶端、游戲和嵌入式。第三個部門涵蓋了所有與GPU相關的內容,包括最終出現在主機中的APU,并且畫面更加清晰。
現在可以看到,AMD的顯卡部門的利潤是四個部門中最弱的。AMD曾表示,在2022財年,僅一家客戶就貢獻了該公司全部收入的六分之一,其他人猜測這家客戶就是索尼。如果情況確實如此,那么PlayStation 5 APU的銷售額就占了游戲行業收入的50%以上。?
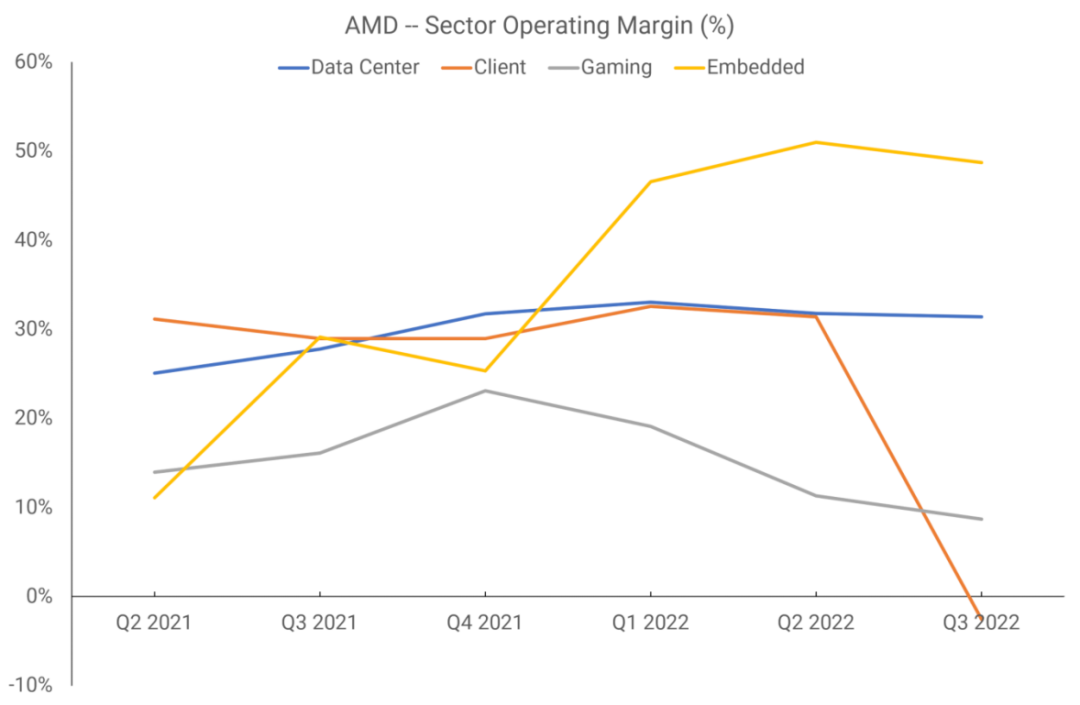
在那個財政年度,獨立顯卡的發貨量急劇下降,毫無疑問,該部門的運營利潤率是由游戲機銷售保持的。AMD使用臺積電制造絕大部分芯片,但訂單必須提前幾個月下——如果處理器在制造后沒有很快售出,它們必須留在配送中心,這損害了這段時間的利潤率。
目前還沒有足夠的信息來判斷AMD在RDNA上的投資是否盈利,因為不可能將對Zen的投資與數據中心和游戲的利潤分開。但收入數據顯示,在以上6個季度中,平均16億美元的收入導致了平均15%的營業利潤率——只有客戶端部門低于這個數字,這主要是由于個人電腦銷售的下滑。
與此同時,在同一時期,英偉達的圖形部門(包括臺式機、筆記本電腦、工作站和汽車等的圖形處理器)平均每季度收入約為36億美元,平均營業利潤率為43%。這家綠色巨頭在獨立GPU市場上的市場份額比AMD大,所以更高的收入數字并不令人驚訝,但營業利潤率卻令人大開眼界。?

大部分PS5的APU是一個RDNA2 GPU。來源:Fritzchen Fritz
但值得考慮的是,AMD賣給微軟和索尼的APU不會有很大的利潤,因為如果他們有,你就不可能花400美元買到一臺最新的游戲機了。一體機芯片的大規模生產有利于增加收入,但對直接利潤的影響不大。
如果去掉主機芯片帶來的收入,假設它們產生10%的利潤,這就意味著RDNA產生了相當多的利潤——運營利潤率可能高達20%。雖然比不上英偉達,但我們都知道為什么這家公司的利潤率如此之高。
Chiplets與計算
對于AMD來說,RDNA 2無疑是一個工程上的成功,該設計在近50種不同的產品中得到了應用。然而,從財務角度來看,與其他領域相比,GPU一直處于次優地位。與此同時,AMD發布了對RDNA的首次更新,該公司還宣布了一種新的僅用于計算的架構,稱為CDNA。
這是GCN的哥斯拉,第一個使用該設計的芯片(Arcturus)擁有128個CU,在750 mm2的芯片中。計算單元已經升級為專用矩陣單元(類似于英偉達的Tensor),在接下來的一年里,AMD將兩個巨大的處理器裝進了一個724平方毫米的芯片中。它的代號為Alderbaran(下圖),很快成為許多超級計算機項目的首選GPU。
回到游戲圖形領域,AMD希望更多地利用其CPU專長。RDNA 2中的無限緩存是由于為其Zen處理器開發高密度L3緩存和無限Fabric互連系統而產生的。
因此,對于RDNA 3來說,很自然地,它將使用另一個CPU成功:chiplets。
但是怎么做呢?在中央處理器中物理分離內核要容易得多,因為它們完全獨立運行。在絕大多數AMD的臺式PC、工作站和服務器cpu中,你會發現至少有兩個所謂的chiplets:一個容納核心(核心復雜芯片,CCD),另一個容納所有輸入/輸出結構(IOD)。它們之間的主要區別是CCD的數量。?
在GPU中做這樣的事情是一項艱巨得多的任務。Navi 21 GPU是一個由四個獨立處理器組成的大塊,每個處理器包含10個WGP、光柵化器、渲染后端和L1緩存。有人可能會認為這些將是分離成離散chiplets的理想選擇,但是大量數據事務所需的互連系統將抵消任何成本節約,并增加了許多不必要的復雜性和功耗。
對于RDNA 3, AMD采取了一種更慎重的方法,一種產生于越來越小的工藝節點所面臨的限制。當臺積電等公司宣布一種新的制造工藝時,通常會提出更高的性能、更低的功耗和更高的晶體管密度。
然而,后者是一個整體數字——晶體管和其他與邏輯和處理相關的電路當然在繼續縮小,但與信號和存儲器有關的任何東西都沒有縮小。SRAM使用一組晶體管作為易失性存儲器的一種形式,但這種排列不能像邏輯那樣被壓縮。?
隨著USB、DRAM等的信號傳輸速度不斷提高,將這些電路更緊密地封裝在一起會導致各種干擾問題。臺積電的N5工藝節點的邏輯密度可能比N7高20%,但SRAM和IO電路只好幾個百分點。
這就是為什么AMD選擇將VRAM接口和L3無限緩存推到一個芯片中,而將GPU的其余部分推到另一個芯片中。前者可以用更便宜、更不先進的工藝制造,而后者可以利用更好的東西。
2022年11月,AMD以Navi 31 GPU的形式推出了RDNA 3。主芯片(稱為圖形計算芯片,GCD)是在臺積電的N5工藝節點上制造的,包含96個計算單元,芯片面積僅為150平方毫米。圍繞它的是6個內存緩存芯片(MCD),每個芯片只有31mm2的硅,包括16MB的無限緩存,兩個32位GDDR6接口和一個無限鏈接系統。
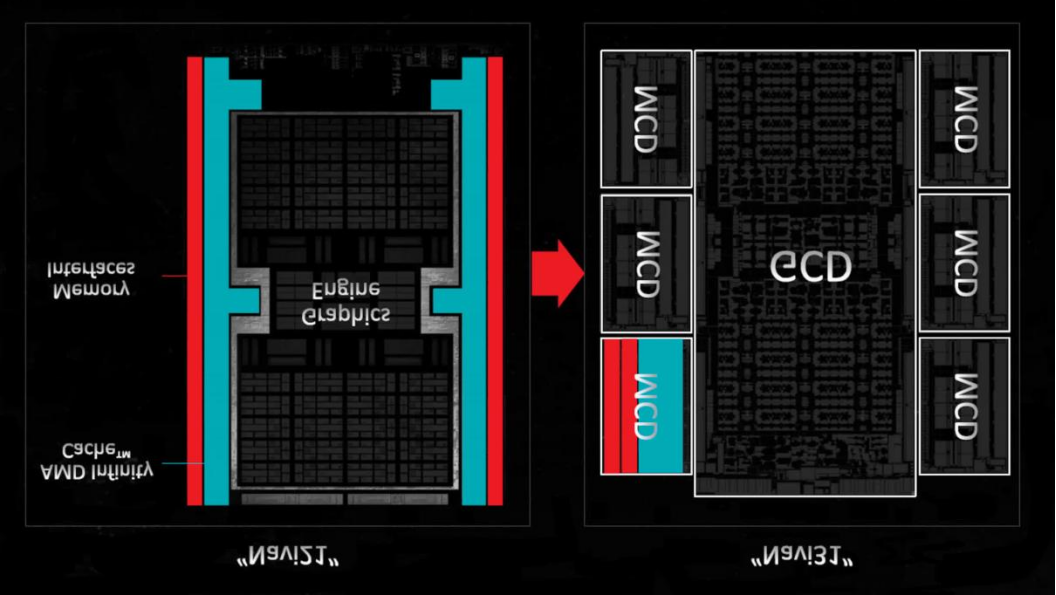
如果AMD在Navi 31上堅持采用單片方法,那么整個芯片的尺寸可能只有500到540平方毫米左右,并且不需要在所有chiplets之間建立復雜的連接網絡,那么將它們全部封裝起來也會更便宜。
AMD已經為這一切計劃了很多年,所以它顯然在盈利方面做得很好。這一切都源于晶圓產量和芯片制造成本的增加。讓我們用一些估計的價格來強調這一點——用于制造MCD的單個N6晶圓可能是12,000美元,但它可以產生超過1,500個這樣的芯片(每個芯片8美元)。一塊1.6萬美元的N5晶圓可能生產150塊GCD,每個晶圓的價格為107美元。
將一張GCD與6張MCD組合在一起,在你需要將它們包裝在一起的成本加進去之前,你需要花費154美元左右。另一方面,來自N5晶圓的單個540 mm2芯片的成本可能在250美元左右,因此使用chiplets的成本效益是顯而易見的。
前沿與保守變革
與RDNA 3小片段的使用一樣大膽,其余的更新則更為保守。寄存器文件以及L0、L1和L2緩存的大小都增加了,但是L3無限緩存的大小減小了。每個SIMD單元擴展到同時處理64個數據點,因此wave64處理現在是單周期的。
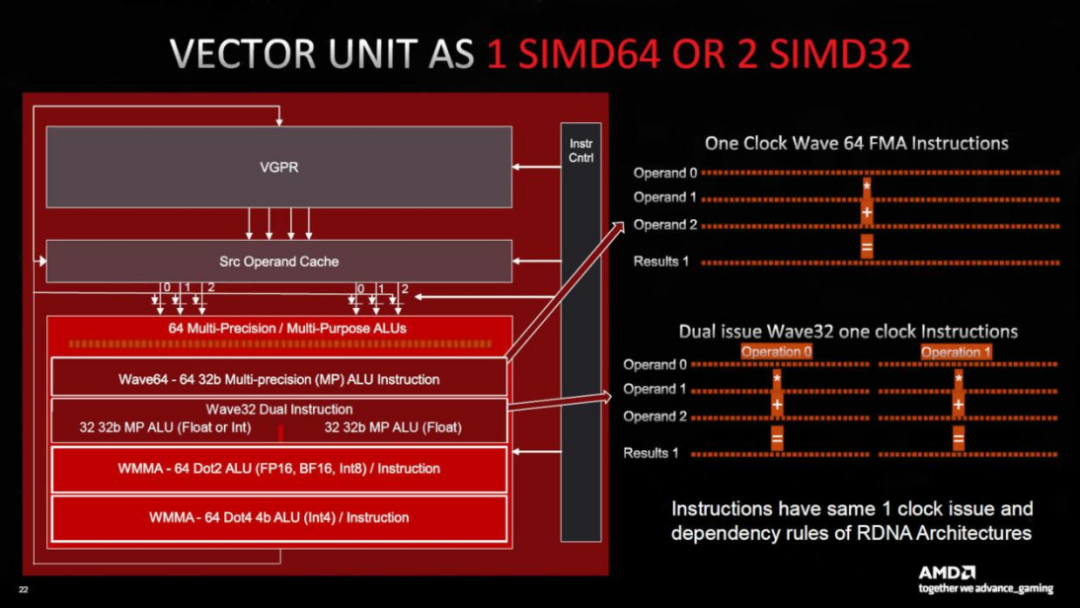
光線追蹤性能得到了適度的提升,通過調整單元來提高光線三角形相交的吞吐量,但在這方面沒有其他專門的硬件。CDNA的矩陣單元也沒有被復制到RDNA上——這樣的操作仍然由計算單元處理,盡管RDNA 3確實有一個“人工智能加速器”(AMD對這個單元的功能幾乎沒有說)。 ?
新設計的處理性能引起了相當大的轟動,“雙重問題”一詞被廣為流傳。當使用時,它允許SIMD單元同時評估兩條指令,AMD的營銷部門通過聲明RDNA 2的峰值FP32吞吐量加倍來證明這一點。
唯一的問題是,執行雙重指令的能力嚴重依賴于編譯器(將程序代碼轉換為GPU操作的驅動程序中的程序)能夠發現何時可能發生這種情況。編譯器在這方面做得并不好,通常需要訓練有素的人眼輸入才能獲得最佳結果。
搭載RNDA 3芯片的最強大顯卡是Radeon RX 7900 XTX,它一上市就受到了好評,價格為1000美元。雖然通常不如英偉達的GeForce RTX 4090快,但它肯定可以與RTX 4080相媲美,從那以后的幾個月里,AMD的降價使它成為一個更好的選擇。
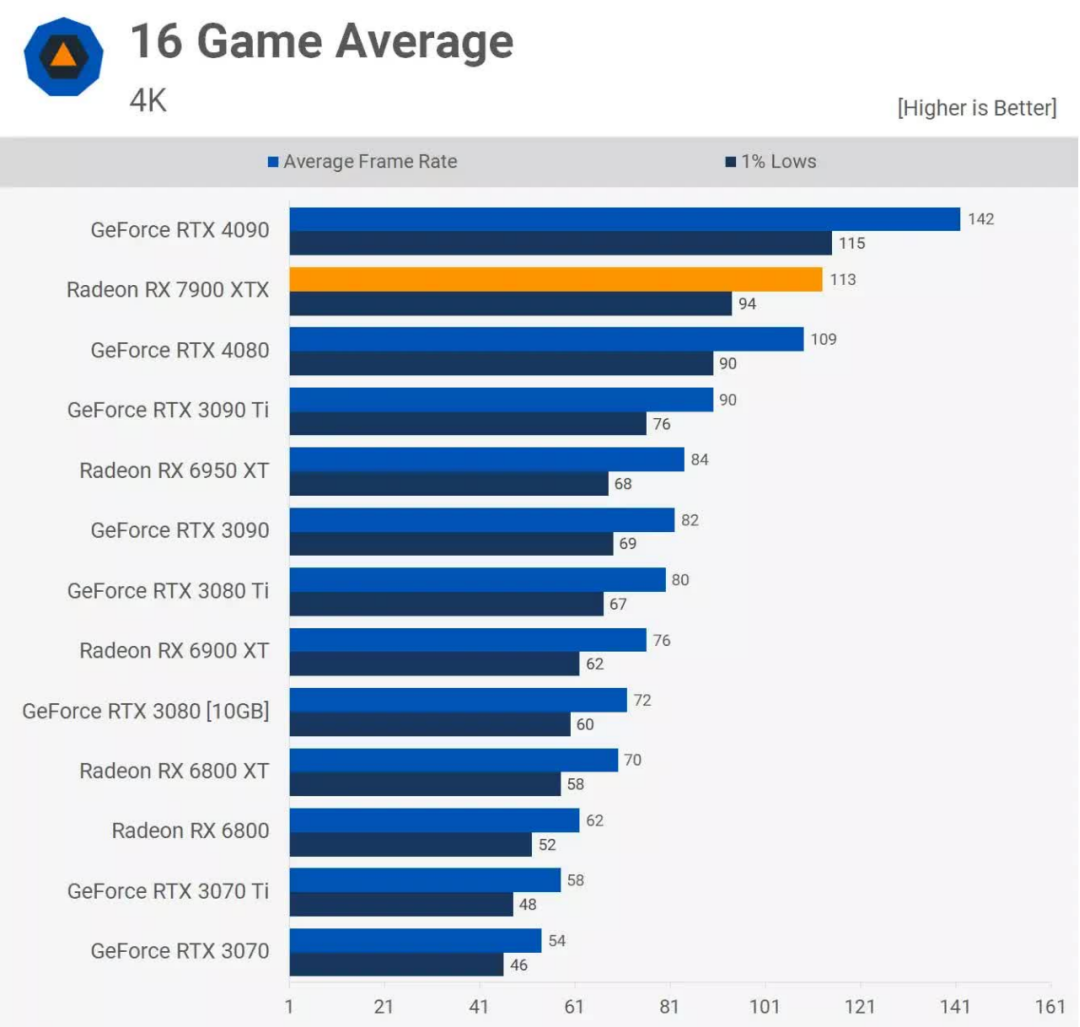
光線追蹤再一次不是一個優勢,盡管聲稱提高了電源效率,但許多人對Navi 31所需的電量感到驚訝,尤其是在空閑時。雖然它確實比以前的Navi 21需要更少的功率,但對Infinity Link系統的需求部分抵消了使用更好的處理節點所帶來的好處。
與RDNA 2相比,另一個不足之處是產品范圍的廣度。在撰寫本文時,RDNA 3可以在18個不同的產品中找到,盡管市場狀況可能迫使AMD在這件事上采取行動。
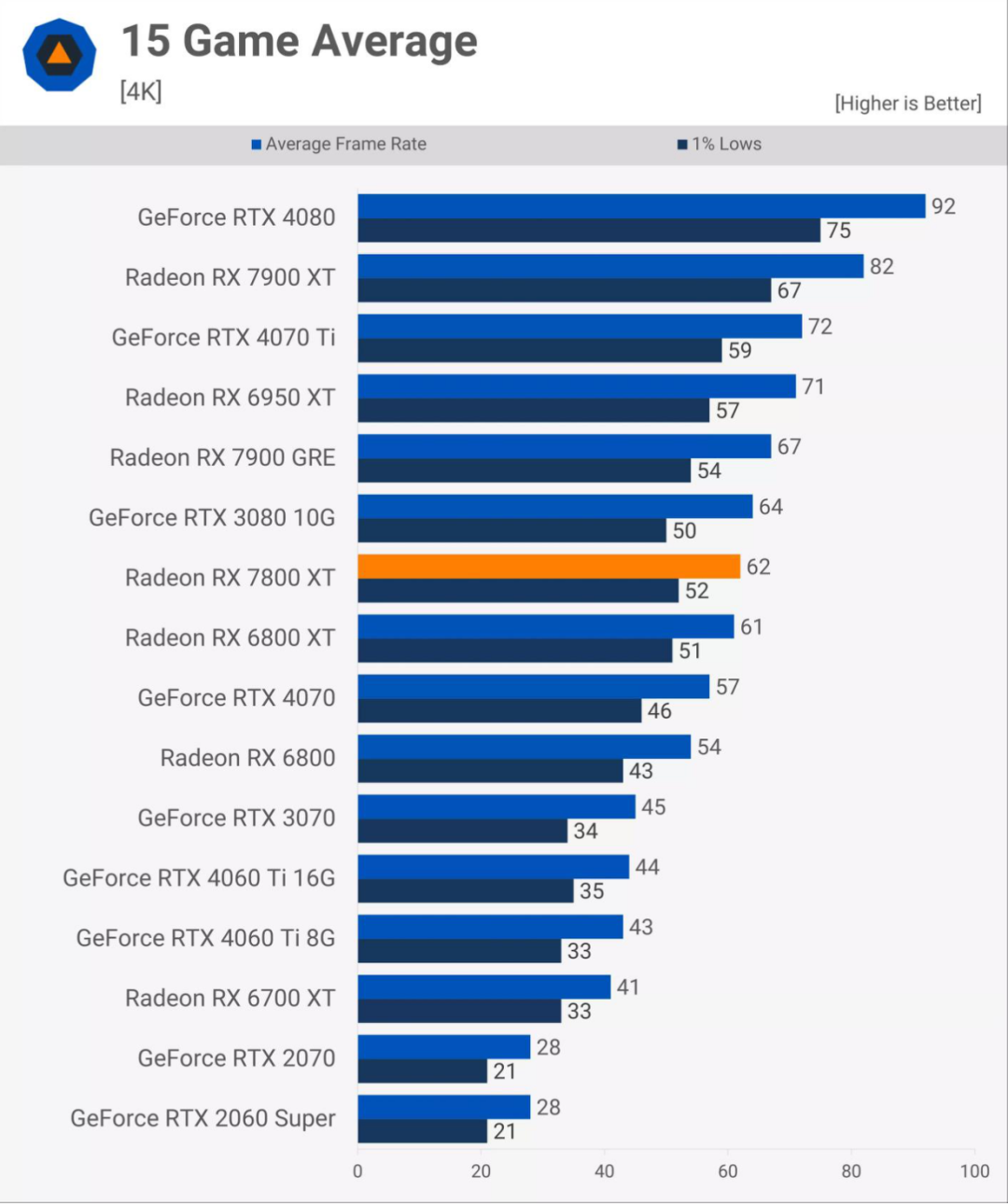
對一些人來說,更糟糕的是,當中低端RDNA 3顯卡最終出現時,它們相對于舊設計的性能改進有些被低估了——以Radeon RX 7800 XT為例,它只比即將推出的RX 6800 XT快了幾個百分點。
chiplets的使用似乎并沒有給AMD的營業利潤率帶來多少好處。在RDNA 3出現后的三個季度中,游戲部門的收入和利潤率基本保持不變。當然,新的GPU實際上有可能有所改善,因為如果控制臺APU銷量下降,那么財務狀況保持不變的唯一途徑似乎是GPU變得更有利可圖。
然而,AMD不再只向微軟和索尼銷售APU。掌上電腦,如Valve的Steam Deck,越來越受歡迎,由于所有這些電腦都配備了AMD芯片,這些銷售額將為游戲部門的銀行余額做出貢獻。
RDNA的未來
如果盤點一下AMD在四年時間里通過RDNA所取得的成就,并評估這些變化的總體成功,最終結果將從Bulldozer和Zen之間得出。前者最初對該公司來說是一場近乎災難性的產品,但多年來因制造成本低廉而挽回了自己。另一方面,Zen從一開始就表現出色,并迫使整個CPU市場發生了翻天覆地的變化。
在這段時間里,AMD在獨立GPU領域的市場份額略有波動,有時會超過英偉達,有時會失去,但總的來說,它保持不變。?
自成立以來,游戲部門已經獲得了少量但穩定的利潤,盡管利潤率目前似乎在下降,但沒有跡象表明厄運即將來臨。事實上,僅就利潤率而言,這是AMD第二好的部門。即使不是這樣,AMD從嵌入式業務中賺取的現金(多虧了收購賽靈思)也綽綽有余,足以避免任何短期的整體虧損。
但AMD接下來將走向何方?
只有三種前進的道路:第一種是保持目前的小架構更新進程,繼續積累微薄的利潤,并保持整個GPU市場的一小部分。第二種是放棄高端桌面GPU領域,完全專注于主導預算和低端市場,專注于進一步縮chiplet尺寸和提高晶圓產量的技術。
第三條路線與第二條截然相反——忘記“物有所值”和擁有一個可以擴展到所有可能級別的架構,并盡一切努力確保它是Radeon顯卡,而不是GeForce顯卡,在每個性能圖表中都名列前茅。
英偉達在RTX 4090上實現了這一點,因為它使用了臺積電最好的工藝節點,就著色單元而言,它是能買到的最大的消費級GPU。沒有什么花哨的把戲——這是一種蠻力的方法,而且效果很好。RTX 4080中的整個AD103芯片僅比Navi 31中的GCD大20%,并且具有相當相似的性能。
然而,RDNA一直致力于最大限度地利用現有的處理能力。RDNA 2/3中緩存系統的復雜性證明了這一點,因為英特爾和英偉達在他們的GPU中使用了更簡單的結構。
說到緩存,決定將大量的最后一級緩存插入RDNA GPU以抵消對超高速VRAM的需求,并提高光線追蹤性能,幾乎可以肯定是英偉達在Ada Lovelace架構上做同樣事情的靈感。
現在正處于GPU發展的一個階段,不同廠商設計圖形處理器的差異相對較小,僅從架構設計就能看到性能的巨大改進的日子已經一去不復返了。
未來的RDNA GPU會像英特爾的Ponte Vecchio一樣多的芯片嗎?
如果AMD想要獨占鰲頭,它就需要推出一款擁有比我們目前看到的更多計算單元的RDNA GPU。或者只是更有能力的—RDNA 3中SIMD單元的變化可能是一個信號,表明在下一個版本中,我們可能會看到CU使用四個SIMD而不是兩個,以消除所有的雙重發行限制。
但即便如此,AMD仍需要擁有更多的CU,而實現這一目標的唯一途徑是擁有更大的GCD,這意味著接受更低的產量或將芯片轉移到更好的工藝節點上。當然,這兩項都會影響利潤率,而且與英偉達不同,AMD似乎不愿將GPU價格推高。
它也不太可能采取第二條路線,因為一旦完成了這一點,就幾乎沒有機會回來了。GPU的歷史上有很多公司嘗試過,失敗過,一旦他們停止了在高端市場的競爭,就永遠消失了。
這就剩下了一個選擇——繼續當前的行動方針。在架構方面,英偉達已經對其著色器內核進行了多年的重制,只有過去兩代才顯示出許多相似之處。它還在開發和營銷機器學習和光線追蹤功能方面投入了大量資源,前者與GeForce品牌有著獨特的聯系。
AMD多年來開發了許多技術,但在RDNA時代,它們都沒有特別要求Radeon顯卡來使用它們。憑借其Zen架構和其他CPU發明,AMD將計算世界帶入了未來,迫使英特爾提高其游戲水平。它為大眾帶來了高能效的多線程處理——不是通過成為英特爾的廉價替代品,而是通過競爭。勝利,迎頭而上。
不可否認,RDNA是一個成功的設計,因為它的使用是如此廣泛,但它肯定不是Zen。如果游戲行業想要發展的話,僅僅做到物有所值或者以開源方式獲得社區的喜愛是不夠的。AMD似乎擁有實現這一目標的所有工程技術和訣竅;他們是否會冒險完全是另一回事。
俗話說,幸運眷顧勇者。
編輯:黃飛















 工商網監
工商網監
評論