學習訓練上,它比一臺普通的Xeon E5 2697 v3的雙CPU服務器快75倍,整體性能相當于250臺普通x86服務器。單臺DGX-1的售價是12.9萬美金。
2016-11-04 11:33:33 1852
1852 服務器外觀的重要性一臺服務器在性能方面的主要特點,但這些性能對于一個剛剛接觸服務器的讀者朋友來說也只能是囫圇吞棗,根本還摸不清是怎么回事。這并不奇怪,因為服務器這個計算機網絡中技術最為復雜的網絡產品
2011-09-28 13:54:03
Web服務器是網站搭建的必備,有了Web服務器,網站的頁面才能夠讓全世界各地的用戶瀏覽訪問到。據業內數據統計了解,大約有90%的用戶選擇租用服務器,主要是為了搭建和部署自己的網站。用戶想要搭建
2020-04-29 14:46:27
服務器技術基礎1.1 什么是服務器1.1.1 服務器的發展歷史1.1.2 X86服務器的發展歷史1.1.3 服務器的發展趨勢1.2 服務器分類1.3 服務器評價體系1.4 服務器強制認證標準1.5
2010-09-12 22:55:19
可以從這幾個方面來衡量服務器是否達到了其設計目的;R:Reliability可靠性;A:Availability可用性;S:Scalability可擴展性;U:Usability易用性;M
2014-08-02 10:42:26
voltage DCpower supply system高壓直流供電系統能夠替代目前的交流UPS供電系統而為數據服務器供電。1.服務器電源的基本原理現在IDC機房的服務器內部一般使用可靠性較高的高...
2021-11-15 09:08:25
。 IP: masquerading:可以將內部網絡的計算機送出去的封包,通過防火墻服務器直接傳遞給遠端的計算機,而遠端的計算機看到的就是接收到的防火墻服務器送過來的封包,而不是從內部的計算機送過來
2011-08-15 14:15:09
SmartQ(概念就是它在實踐中獲取的最新成果,對抗服務器同質化的利器)。因為在質量標準方面,百聯豐服務器除了嚴格遵守國家的ISO9001和ISO14001標準,還設置了在很多方面高于國家標準的內部質量管理
2011-10-26 11:55:46
服務器是一種高性能計算機,作為網絡的節點,存儲、處理網絡上80%的數據、信息,因此也被稱為網絡的靈魂。做一個形象的比喻:服務器就像是郵局的交換機,而微機、筆記本、PDA、手機等固定或移動的網絡終端
2011-08-12 13:43:52
,如果要進行香港服務器測試就要針對你放置網站的每個細節和功能全面的操作測試,根據每個功能操作下的不同性能來測試。2、多線路測試在對香港服務器速度及穩定性進行測試之時,不能為測試而測試,應采用多路線的形式
2022-09-20 09:56:44
服務器維護技巧一:從基本做起,及時安裝系統補丁——不論是Windows還是Linux,任何操作系統都有漏洞,及時的打上補丁避免漏洞被蓄意攻擊利用,是服務器安全最重要的保證之一。 服務器維護技巧二
2013-09-09 15:22:33
運營商。
2.服務器網絡問題
解決辦法:通過路由圖來確定是哪里的線路出現丟包,聯系服務器商切換線路。
二、服務器問題
服務器帶寬跑滿、服務器死機、黑屏或者藍屏
解決辦法:重啟服務器,并檢查報錯日志,排查
2024-02-27 16:21:28
,電源采用七盟、臺達等名牌。因為服務器不是奢侈品,而是生產工具。服務器選購時需要遵循的原則是:見菜吃飯、量體裁衣。因此,配置服務器時一定要做好的事情是分析好應用需求,并且根據應用需求來實際選擇服務器
2011-07-21 18:25:12
,英偉達在數據中心領域的成功與否,都與能否實現數據中心的規模化運算有關,從發展自研的DGX系列服務器到整合Mellanox的技術,再到借助ARM生態發展全新的數據中心計算架構,都是為轉型數據中心業務所作
2022-03-29 14:42:53
英偉達不斷推出GPU卡,并且實現多卡互聯NVLink,實際整個系統會累積到一個較大的公差,而目前市面上已有的連接器只能吸收較少的公差,這個是怎么做到匹配的呢?
2022-03-05 16:17:06
`世界最大的顯卡和圖形芯片制造商英偉達正式宣布退出加密貨幣業務。公司首席財務官Colette Kress在聲明中表示:“我們認為公司已經進入一個正常時期,公司在預期的未來內并沒有加密貨幣業務。我們在
2018-08-24 10:11:50
英偉達TX2數據手冊,喜歡請關注
2018-01-07 22:08:07
我下載的2019LABVIEW為什么沒有IO服務器
2019-11-20 19:17:51
這里主要討論的是OPC Data Access 2.0服務器的開發,在掌握了這個最常用的OPC服務器開發之后,對其它類型的OPC服務器,如A&E、HDA等就可以觸類旁通了。一個OPC服務器
2021-07-02 08:29:24
PC端訪問服務器并讀取服務器端的數據 怎么寫啊? 需要訪問數據庫嗎?聽說還要服務器那邊的用戶名和密碼才能訪問數據庫不需要兩臺pc機的通信的程序 求大神。。。。。
2016-07-27 09:00:06
RISC服務器在過去的幾年,Unix服務器市場一直呈下降趨勢,去年Unix服務器的下降趨勢一度有所減緩,然而大勢好像難以扭轉。不過,Unix服務器目前仍然是規模最大的一個服務器市場,每年仍有210億
2009-11-13 22:02:04
TCP服務器模式配置流程是什么?如何去實現TCP服務器通信呢?
2022-01-14 06:02:15
簡介簡介Tomcat服務器是一個開放源碼的輕量級Web應用服務器,非常適合搭建微服務應用。Embedded Tomcat嵌入式Tomcat服務器則無需部署外置tomcat,開發者只需引入嵌入式tomcat依賴,編寫少量啟動代碼即可運行Web應用,是搭建微服務應用的首選方式之一。
2021-12-16 08:24:33
(虛擬專用服務器)("Virtual Private Server",或簡稱 "VPS")是利用虛擬服務器軟件(如微軟的Virtual Server
2014-08-01 10:30:49
labview利用web服務器發布網頁時,想在瀏覽器中預覽時無法啟動web服務器。
2017-04-12 07:59:22
Linux服務器和Windows服務器是目前應用最廣泛的兩種服務器操作系統。兩者各有優劣,也適用于不同的應用場景。本文將
對Linux服務器和Windows服務器進行比較,并介紹它們各自的特點
2024-02-22 15:46:15
stm32服務器是如何工作的?stm32服務器的通信過程是怎樣的?
2021-10-20 06:27:27
我在f407上開了一個tcp_server,可以用客戶端連接上,但是用tcp_close關閉后,還能鏈接上服務器。是什么原因。 或者如何把這個服務器關閉了。
2020-03-30 03:27:09
【NVIDIA社招】英偉達上海熱招ASIC驗證工程師一.公司簡介 NVIDIA (英偉達?)公司(納斯達克代碼:NVDA)是全球視覺計算技術的行業領袖及GPU(圖形處理器)的發明者。作為高性能處理器
2016-11-11 17:38:35
【NVIDIA社招】英偉達上海熱招ASIC驗證工程師一.公司簡介 NVIDIA (英偉達?)公司(納斯達克代碼:NVDA)是全球視覺計算技術的行業領袖及GPU(圖形處理器)的發明者。作為高性能處理器
2016-09-26 10:14:45
嵌入式WEB服務器及遠程測控應用詳解
2014-03-24 23:34:58
上海回收聯想二手服務器,服務器存儲回收,服務器主板回收誠源公司回收***(微信同號)魯先生 qq:673399979上海誠源廢舊物資回收有限公司專業服務器回收、交換機回收、電腦回收、筆記本
2021-12-09 16:21:58
云計算服務器(又稱云服務器或云主機,簡稱ECS),是云計算服務體系中的一項主機產品,該產品有效的解決了傳統物理租機與VPS服務中,存在的管理難度大,業務擴展性弱的缺陷。物理服務器是指獨立服務器,也就
2021-12-09 09:56:38
`現如今,隨著云計算技術的發展,現在很多企業都紛紛選擇云服務器,正是因為這種方式可以有效降低企業的成本,而且從性能上來說,也是遠遠超于傳統服務器的,使用也十分的方便。然而,還有一些朋友擔心云服務器
2021-03-27 14:31:18
大多數的企業、機構逐步轉向云服務器,IT基礎上不再采用傳統服務器。只有一些傳統企業沒有上云,他們也在加快信息化進程,把業務送上云端。有研究機構調查顯示,只有5%組織用戶單純依賴于傳統服務器,95
2018-07-31 18:35:28
什么時候使用DNS服務器合適?在 ap 模式下使用 esp8266 作為強制門戶時,我只使用了 dns 服務器。還有其他情況需要使用dns服務器嗎?謝謝。
2023-02-24 08:22:24
大數據_02【大數據基礎知識】01 什么是服務器02 服務器類型03 存儲磁盤(硬盤)01 什么是服務器服務器: 也稱伺服器,是一種高性能計算機,提供計算服務的設備。服務器的構成包括處理器、硬盤
2021-07-16 07:35:04
500報錯:被稱為http500服務器內部錯誤,從名稱上可以理解為服務器問題導致的錯誤。一般給站長展現出的問題分為兩種情況,一是服務器環境或者不支持的組件等原因導致的500錯誤,這種情況下即使建立一
2022-07-08 09:38:31
嵌入式web服務器Boa的移植什么是Boa服務器BOA 服務器是一個小巧高效的web服務器,是一個運行于unix或linux下的,支持CGI的、適合于嵌入式系統的單任務的http服務器,源代碼開放
2021-12-14 07:21:52
服務器有很多種類,比如我們常見的有游戲服務器,游戲服務器可以為游戲開發商提供平臺,開發游戲并運營,也有有視頻服務器,網站服務器,甚至還有下載服務器,這些普通的網站可能都可以用到,等等。本文主要
2021-06-30 09:28:12
是模擬信號。但計算機內部處理的信息是數字信號,所以計算機生成的是數字信號,能識別的也是數字信號。所以計算機服務器中需要安裝在計算機與電話線之間進行信號轉換的裝置,該裝置就是傳真板卡。傳真板卡的作用就是
2015-01-16 14:19:42
嗨,我需要了解更多關于UDP服務器機制。以下是我的問題:1。我可以說UDP服務器每次只能服務一個連接嗎?之所以這樣說是因為當我使用TCPIP_UDP_ArrayPut()時,服務器會自動知道目的地
2020-05-05 10:38:50
刀片式服務器是一種 HAHD(高可用高密度)的低成本服務器平臺,是專門為特殊應用行 業和高密度計算機環境設計的,其中每一塊“刀片”實際上就是一塊系統母板,類似于一個 個獨立的服務器。
2020-03-12 09:02:00
如圖所示,按照教程,把主機設置成服務器,將BIN文件夾設為了主文件夾,但是通過MObaxterm進行數據下載的時候卻如下所示,說服務器的地址不對?
2019-03-25 07:45:01
經常在IT行業,我們會對不同的專業術語都有了解,即使是不同領域的,也會耳濡目染。單線服務器以及我們經常會用到的雙線服務器,即使是做互聯網推廣工作的朋友也會有所了解。那對于這種單線,雙線服務器我們到底
2021-07-01 10:10:40
要租用一個什么樣的服務器對很多人來說是一個艱難的選擇,它需要專業知識用來比對、選擇,但是現在各種品牌的服務器又讓人看得眼花繚亂,不知該如何選擇。總有客戶在對比服務器的時候有些疑問,為什么同是一個地區
2019-08-15 10:42:14
回收服務器內存條 收購服務器內存條高價收購服務器內存條,服務器內存條優勢回收,【趙先生 ***】長年回收各類服務器內存條A聯系電話:135 3012 2202 (同步微信)BQQ
2021-01-07 17:43:17
了整個網絡視頻監控系統的框架,包括視頻服務器、網絡傳輸鏈路及客戶監控端。本設計采用 MPEG4視頻編碼標準,由DM355內部的MPEG/JPEG協處理器完成。實驗表明,在帶寬充足的條件下,可實現實時監控。
2019-07-19 06:19:32
大家好,我想使用tcp連接自己搭建的服務器 這個服務器不是本地local的IP4而是有域名的,類似espslr.*****.com,端口是8591 我使用examples\protocols
2023-03-07 06:58:00
你好,有人已經實現了SSH(2版)服務器嗎?你好嗎?SSH只是帶有SSL的telnet,還是有其他的東西有一個基本的SSH服務器?如何實施SFTP?感謝
2020-03-24 10:14:18
如何建立AT指令服務器?
2022-01-24 07:32:29
如何搭建DHCP服務器?
2021-10-25 08:01:51
BearSSL_Validation 示例顯示來自服務器的證書部分通過確認證書的驗證日期與 NTP 服務器驗證的時間一致來驗證。但是我們如何驗證 NTP 服務器本身呢?難道一個假的 NTP 服務器不能給我們一個無效的日期,這樣過期的證書對我們來說就不會顯得過期了嗎?
2023-02-24 07:13:11
嵌入式WEB服務器及遠程測控應用詳解
2013-11-18 15:58:16
怎么搭建MQTT服務器?
2018-06-01 15:04:47
常規的 NTP 請求并獲得時間。所以我想要一個專用的 ESP8266 作為系統的 NTP 服務器。我想使用 GPS,但也可以考慮使用實時時鐘。那只是一個細節。我不熟悉的部分是如何實現 NTP 服務器。
2023-02-24 07:48:07
2013年6月26日,歐盟正式發布了關于計算機和計算機服務器的ErP 指令實施條例(EU) No 617/2013。該實施措施于2013年7月17日起正式生效,并在未來幾年內分三個階段實施:生效日
2016-03-31 18:14:57
Tomcat服務器是一個免費的開放源代碼的Web應用服務器。因為Tomcat技術先進、性能穩定且免費,所以深受Java愛好者的喜愛并得到了部分軟件開發商的認可,成為目前比較流行的Web應用服務器。
2019-07-16 06:23:19
首先我們先了解物理機是由什么部分組成:主板、內存、硬盤、陣列卡、電源、網卡、風扇。tg@CDNJSFY另外物理機服務器有幾種類型,我們主要用的到機柜式服務器。機柜式服務器內部組成是比較復雜的,內部
2022-06-22 10:16:40
大家好,
我剛收到新的 esp 板,我發現有了新固件,我無法使用 AT 命令
AT+GMR 啟動 UDP 服務器,給我的是:
代碼:全選AT version:0.21.0.0
SDK version
2023-05-15 07:27:52
求助大神,為什么我現在用GPRS的UDP協議跟服務器通信的時候,發送數據正常,服務器那邊也能收到,但是服務器發送的數據我為什么會收不到?急求...
2019-04-16 06:36:01
我們是做定制化服務器的,也就是組裝服務器,最近好多客戶問品牌的服務器。想問一下大家對于這兩者有什么看法! 鄭州一方服務器,您身邊的服務器專家 華碩 服務器主板 Intel服務器產品河南省總代理網吧、網站、數據庫服務器,圖形工作站... ...麗臺顯卡、硬盤、內存、CPU、機箱電源配件齊全
2017-05-25 10:01:21
荷蘭服務器的十大優勢 1、荷蘭機房眾多,例如荷蘭的阿姆斯特丹機房、萊茵河畔機房等,都是荷蘭乃至歐洲最優質的機房。有需要請聯系TG:@TW_001 2、荷蘭IP眾多,一臺服務器最高可以添加253個IP
2021-12-16 10:26:55
大家好,最近在做sim808芯片的gprs與服務器通信,用的是阿里云的服務器,請問一下服務器端的程序改怎么寫?用VB嗎?有沒有相關的教程可以推薦一下,謝謝。
2019-04-17 23:22:47
導讀:關于VR,有人唱衰,有人認為前景無限。在本周的VRX大會上,英偉達總經理格林斯特恩則認為VR在明年將實現爆發。
據外媒報道,要說VR市場今年的大贏家,絕對非索尼莫屬。憑借399
2016-12-13 14:32:48
myBOX——一站式VPN路由器/SCADA服務器 myBOX為您提供了全面的監控解決方案,擁有myBOX,您就擁有了高性能HMI/SCADA服務器,以及先進且易于配置的VPN
2021-12-15 14:11:45
/Glonass衛星信號輸入,作為IEEE1588服務器的信號源,具有兩路IEEE1588高精度時間輸出。當外部參考源丟失時,內部自動進入守時狀態,設備仍可輸出高精度
2022-08-11 17:01:37
ntp時鐘同步服務器是一款基于ARM架構開發的高性能大容量NTP時間服務器。可廣泛適用于企業、教育、政府、、郵政、鐵路、金融等行業用戶各種規模的網絡校時應用。ntp時鐘同步服務器產品特點:1U 19
2024-01-11 13:01:55
服務器集群系統實現方案詳解
一、集群的基本概念
有一種常見的方法可以大幅提高服務器的安全性,這就是集
2010-01-27 17:03:17640 NVIDIA今天發布了升級版的GPU計算服務器“DGX-2H”,和上代DGX-2一樣配備多達16顆Tesla V100 GPU,但熱設計功耗從350W開放到450W,性能更上一層樓。
2018-11-21 15:13:243934 今年早些時候,NVIDIA首席執行官黃仁勛發布了NVIDIA? DGX-2?服務器,并稱其為“全球最大GPU”。
2018-10-25 15:07:0616510 英偉達DGX軟件棧為最大限度地提高GPU加速訓練性能而設計,包括加速數據科學工作流程的新式RAPIDS框架。新人工智能框架的應用經過了容器模型的簡化,并由英偉達的GPU優化應用程序NGC容器存儲庫所支持。
2018-12-20 15:47:582615 用戶無法訪問內部服務器故障處理,該怎么辦? 日常工作中為滿足業務需要,企業會在內網部署內部服務器為用戶提供相關服務,例如Web服務、FTP服務等等。用戶訪問內部服務器常見配置場景有兩種:一種是外網
2021-06-30 17:48:072615 GPU和Grace Hopper超級芯片。 GTC 2023上,英偉達發布NVIDIA DGX Cloud人工智能云服務。NVIDIA DGX Cloud是一項人工智能超級計算服務,它可以讓企業快速訪問
2023-03-22 19:16:443117 
DGX GH200人工智能超級計算機則集成了英偉達最先進加速計算和網絡技術。
2023-05-30 16:20:282229 據臺灣《大眾經濟日報》報道,最近外資業界有傳聞稱,由于緯創因AI服務器生產能力不足,大客戶英偉達將部分訂單轉交給鴻海集團旗下的工業富聯集團(fii)。供貨商表示,英偉達實際上已經將英偉達a100基板的部分訂單轉移到工業集團。
2023-08-04 11:03:23459 AI 服務器我們瞄準英偉達 DGX A100 和 DGX H100 兩款具有標桿性產品力的產品進行分析,鑒于 H100 發布時間較短、資料詳盡度不夠,我們首先從 DGX A100 出發來觀測具有產品力的 AI 服務器的基本架構。
2023-08-11 09:24:593163 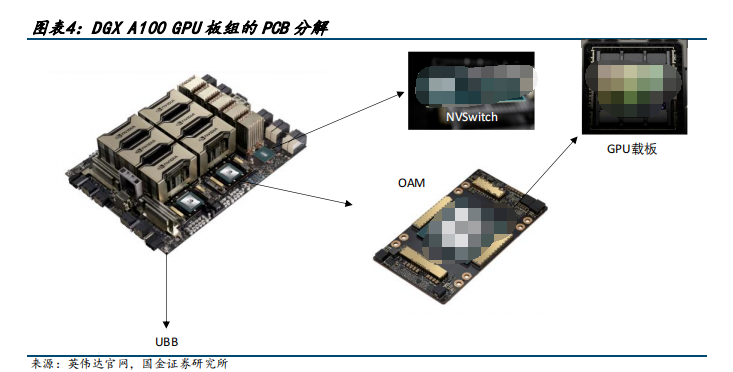
2023年3月,英偉達正式上線云計算服務DGX Cloud。事實證明,經過英偉達工程師的優化后,DGX Cloud在訓練大模型時表現得的確更好;在此基礎上,英偉達還破例允許短期租賃。僅僅半年時間,英偉達就拿下了軟件公司ServiceNow等大客戶。
2023-10-18 15:33:00427 
據悉,AI服務器所需的CCL用量大約是普通服務器的八倍,而當英偉達的AI服務器計劃在2024年下半年升級至更先進的B100方案時,其需求將會進一步加大。
2023-12-13 15:37:18603 該合作進一步加深,公開資料顯示,OpenAI成立之初,英偉達CEO黃仁勛曾向特斯拉創始人馬斯克贈送一臺AI服務器,并在其上簽注,這正是工業富聯與英偉達共同打造的首代AI服務器的見證。
2024-01-04 10:04:32601 在人工智能領域,英偉達作為行業領軍者,推出了兩種主要的GPU版本供AI服務器選擇——NVLink版(實為SXM版)與PCIe版。這兩者有何本質區別?又該如何根據應用場景做出最佳選擇呢?讓我們深入探討一下。
2024-03-19 11:21:04420 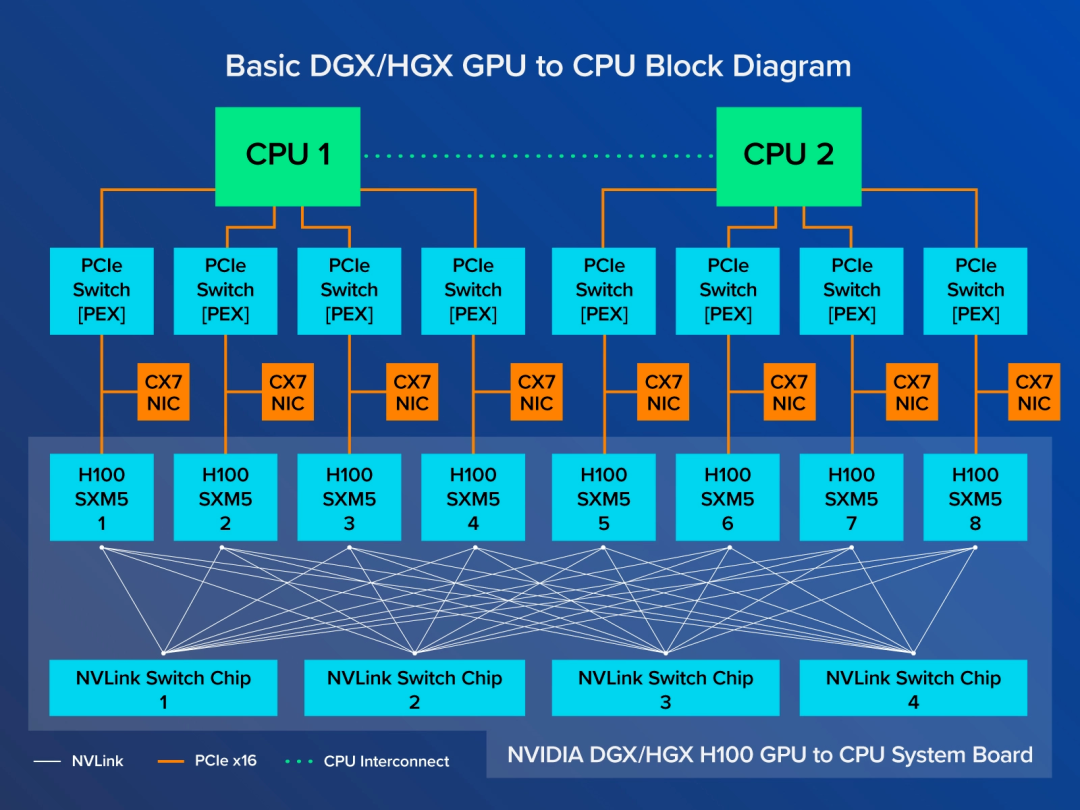
據悉,新型DGX SuperPOD采用全新的高效水冷機架式設計,搭載英偉達DGX GB200系統,FP4精度下具備11.5 exaflops的人工智能超級計算力以及240 terabytes的高速內存。用戶可以通過加裝機架進行持續擴充。
2024-03-19 14:35:31232
正在加载...
 電子發燒友App
電子發燒友App




















 工商網監
工商網監
評論