 電子發燒友App
電子發燒友App


流行的GPU/TPU集群網絡組網,包括:NVLink、InfiniBand、ROCE以太網Fabric、DDC網絡方案等,深入了解它們之間的連接方式以及如何在LLM訓練中發揮作用。為了獲得良好的訓練性能,GPU網絡需要滿足以下條件:
1、端到端延遲:由于GPU間通信頻繁,降低節點間數據傳輸的總體延遲有助于縮短整體訓練時間。
2、無丟包傳輸:對于AI訓練至關重要,因為任何梯度或中間結果的丟失都會導致訓練回退到內存中存儲的前一個檢查點并重新開始,嚴重影響訓練性能。
3、有效的端到端擁塞控制機制:在樹形拓撲中,當多個節點向單個節點傳輸數據時,瞬態擁塞不可避免。持久性擁塞會增加系統尾延遲。由于GPU之間存在順序依賴關系,即使一個GPU的梯度更新受到網絡延遲影響,也可能導致多個GPU停運。一個慢速鏈路就足以降低訓練性能。
除了以上因素,還需要綜合考慮系統的總成本、功耗和冷卻成本等方面。在這些前提下,我們將探討不同的GPU架構設計選擇及其優缺點。
一、NVLink 交換系統
用于連接 GPU 服務器中的 8 個 GPU 的 NVLink 交換機也可以用于構建連接 GPU 服務器之間的交換網絡。Nvidia 在 2022 年的 Hot Chips 大會上展示了使用 NVswitch 架構連接 32 個節點(或 256 個 GPU)的拓撲結構。由于 NVLink 是專門設計為連接 GPU 的高速點對點鏈路,所以它具有比傳統網絡更高的性能和更低的開銷。
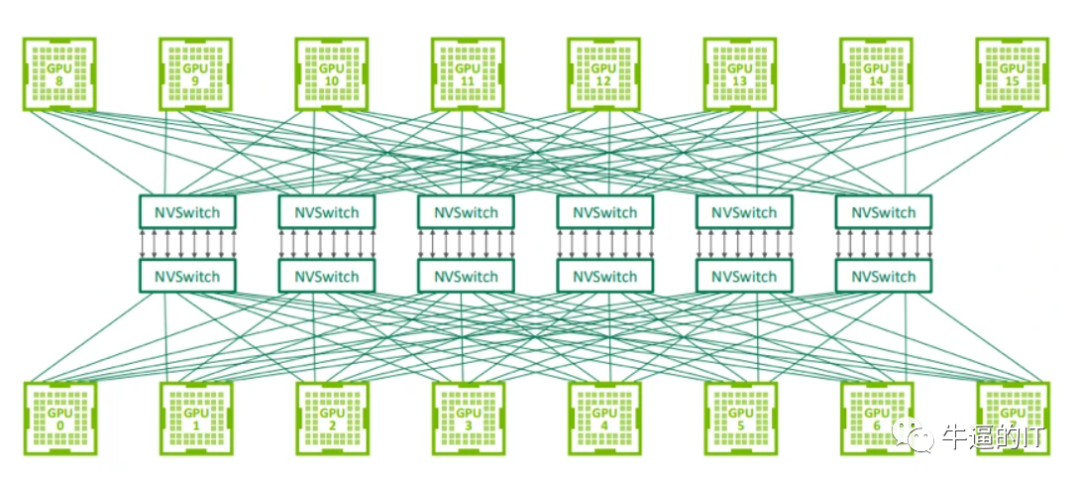
第三代 NVswitch 配備 64 個 NVLink 端口,提供高達 12.8Tbps 的交換容量,同時支持多播和網絡內聚合功能。網絡內聚合能夠在 NVswitches 內部匯集所有工作 GPU 生成的梯度,并將更新后的梯度反饋給 GPU,以便進行下一次迭代。這一特點有助于減少訓練迭代過程中 GPU 之間的數據傳輸量。
據 Nvidia 介紹,在訓練 GPT-3 模型時,NVswitch 架構的速度是 InfiniBand 交換網絡的 2 倍,展現出了令人矚目的性能。然而,值得注意的是,這款交換機的帶寬相較于高端交換機供應商提供的 51.2Tbps 交換機來說,要少 4 倍。
若嘗試使用 NVswitches 構建包含超過 1000 個 GPU 的大規模系統,不僅成本上不可行,還可能受到協議本身的限制,從而無法支持更大規模的系統。此外,Nvidia 不單獨銷售 NVswitches,這意味著如果數據中心希望通過混合搭配不同供應商的 GPU 來擴展現有集群,他們將無法使用 NVswitches,因為其他供應商的 GPU 不支持這些接口。
二、InfiniBand 網絡
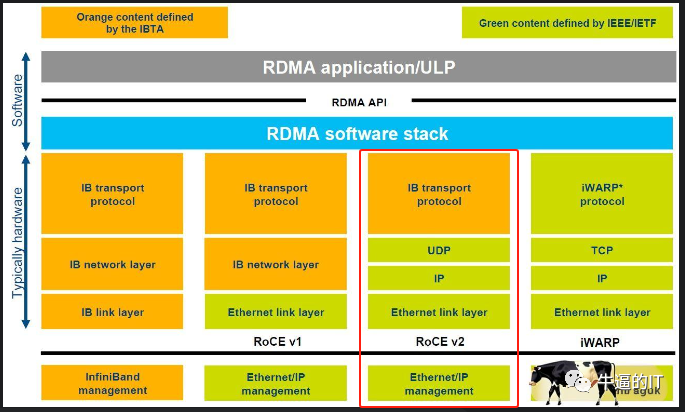
InfiniBand(簡稱IB),這項技術自1999年推出以來,一直作為高速替代方案,有效替代了PCI和PCI-X總線技術,廣泛應用于連接服務器、存儲和網絡。雖然由于經濟因素,其最初的宏大設想有所縮減,但InfiniBand仍在高性能計算、人工智能/機器學習集群和數據中心等領域得到了廣泛應用。這主要歸功于其卓越的速度、低延遲、無丟失傳輸以及遠程直接內存訪問(RDMA)功能。
更多InfiniBand技術,請參考文章“英偉達Quantum-2 Infiniband技術A&Q”,“InfiniBand高性能網絡設計概述”,“關于InfiniBand和RDMA網絡配置實踐”,“高性能計算:RoCE v2 vs. InfiniBand網絡該怎么選?”,“收藏:InfiniBand與Omni-Path架構淺析”,“InfiniBand網絡設計和研究(電子書更新)”,“200G HDR InfiniBand有啥不同?”,“Infiniband架構和技術實戰(第二版)”,“關于InfiniBand架構和知識點漫談”等等。
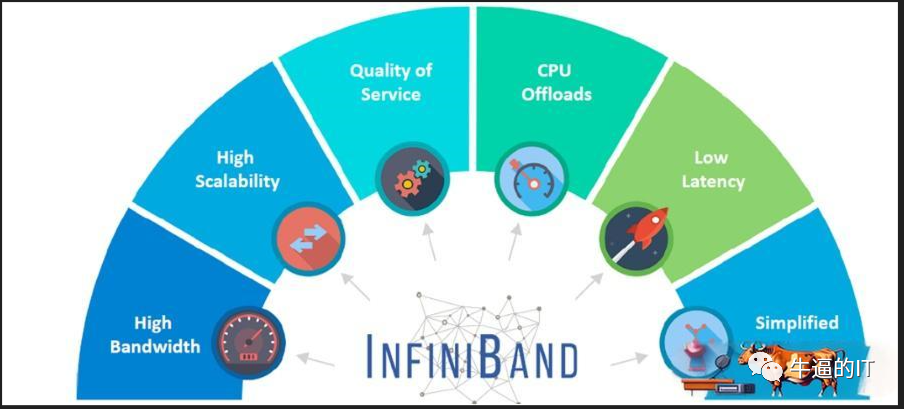
InfiniBand(IB)協議旨在實現高效且輕量化的設計,有效避免了以太網協議中常見的開銷。它支持基于通道和基于內存的通信,可以高效處理各種數據傳輸場景。
通過發/收設備之間的基于信用的流量控制,IB實現了無丟包傳輸(隊列或虛擬通道級別)。這種逐跳的流量控制確保不會由于緩沖區溢出而造成數據丟失。此外,它還支持端點之間的擁塞通知(類似于 TCP/IP 協議棧中的 ECN)。IB提供卓越的服務質量,允許優先處理某些類型的流量以降低延遲和防止丟包。
值得一提的是,所有的IB交換機都支持RDMA協議,這使得數據可以直接從一個GPU的內存傳輸到另一個GPU的內存,無需CPU操作系統的介入。這種直接傳輸方式提高了吞吐量,并顯著降低了端到端的延遲。
然而,盡管具有諸多優點,InfiniBand交換系統并不像以太網交換系統那樣流行。這是因為InfiniBand交換系統在配置、維護和擴展方面相對困難。InfiniBand的控制平面通常通過一個單一的子網管理器進行集中控制。雖然在小型集群中可以運行良好,但對于擁有32K或更多GPU的網絡,其擴展性可能會成為一項挑戰。此外,IB網絡還需要專門的硬件,如主機通道適配器和InfiniBand電纜,這使得其擴展成本比以太網網絡更高。
目前,Nvidia是唯一一家提供高端IB交換機供HPC和AI GPU集群使用的供應商。例如,OpenAI在Microsoft Azure云中使用了10,000個Nvidia A100 GPU和IB交換網絡來訓練他們的GPT-3模型。而Meta最近構建了一個包含16K GPU的集群,該集群使用Nvidia A100 GPU服務器和Quantum-2 IB交換機(英偉達GTC 2021大會上發布全新的InfiniBand網絡平臺,具有25.6Tbps的交換容量和400Gbps端口)。這個集群被用于訓練他們的生成式人工智能模型,包括LLaMA。值得注意的是,當連接10,000個以上的GPU時,服務器內部GPU之間的切換是通過服務器內的NVswitches完成的,而IB/以太網網絡則負責將服務器連接在一起。
為了應對更大參數量的訓練需求,超大規模云服務提供商正在尋求構建具有32K甚至64K GPU的GPU集群。在這種規模上,從經濟角度來看,使用以太網網絡可能更有意義。這是因為以太網已經在許多硅/系統和光模塊供應商中形成了強大的生態系統,并且以開放標準為目標,實現了供應商之間的互操作性。
三、ROCE無損以太網
以太網的應用廣泛,從數據中心到骨干網絡都有其身影,速度范圍從1Gbps到800Gbps,未來甚至有望達到1.6Tbps。與Infiniband相比,以太網在互連端口速度和總交換容量上更勝一籌。此外,以太網交換機的價格相對較低,每單位帶寬的成本更具競爭力,這主要歸功于高端網絡芯片供應商之間的激烈競爭,推動了廠商將更多帶寬集成到ASIC中,從而降低了每千兆位的成本。
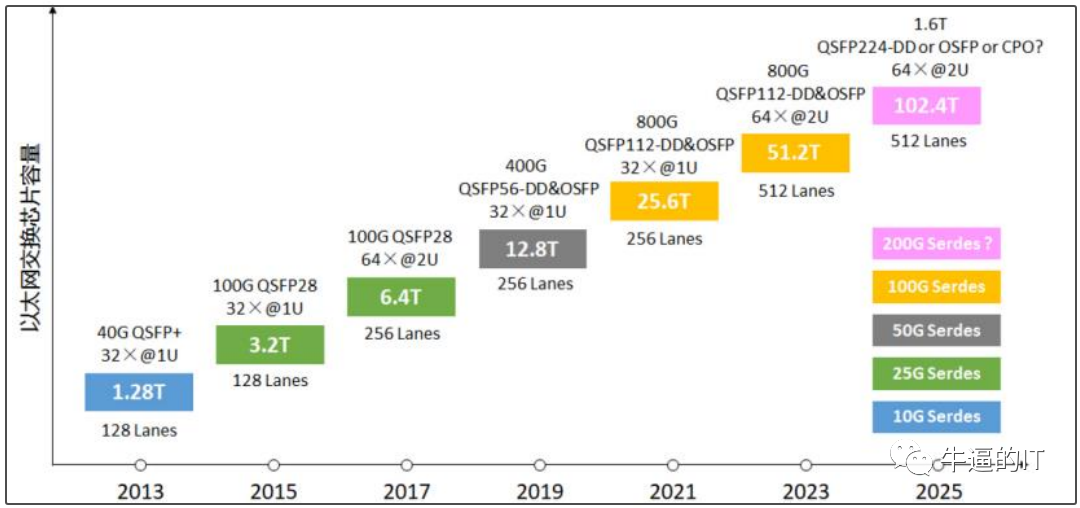
高端以太網交換機ASIC的主要供應商可以提供高達51.2Tbps的交換容量,配備800Gbps端口,其性能是Quantum-2((英偉達GTC 2021大會上發布全新的InfiniBand網絡平臺,具有25.6Tbps的交換容量和400Gbps端口))的兩倍。這意味著,如果交換機的吞吐量翻倍,構建GPU網絡所需的交換機數量可以減少一半。
以太網還能提供無丟包傳輸服務,通過優先流量控制(PFC)實現。PFC支持8個服務類別,每個類別都可以進行流量控制,其中一些類別可以指定為無丟包類別。在處理和通過交換機時,無丟包流量的優先級高于有丟包流量。在發生網絡擁塞時,交換機或網卡可以通過流量控制來管理上游設備,而不是簡單地丟棄數據包。
更多ROCE技術細節,請參考文章“RoCE、IB和TCP等網絡知識及差異對比”,“關于RoCE技術3種實現及應用”,“高性能計算:RoCE技術分析及應用”,“高性能計算:RoCE v2 vs. InfiniBand網絡該怎么選?”,“RoCE技術在HPC中的應用分析”,“面向數據中心無損網絡技術(IP、RDMA、IB、RoCE、AI Fabric)”,“超算網絡演變:從TCP到RDMA,從IB到RoCE”等等。
此外,以太網還支持RDMA(遠程直接內存訪問)通過RoCEv2(RDMA over Converged Ethernet)實現,其中RDMA幀被封裝在IP/UDP內。當RoCEv2數據包到達GPU服務器中的網絡適配器(NIC)時,NIC可以直接將RDMA數據傳輸到GPU的內存中,無需CPU介入。同時,可以部署如DCQCN等強大的端到端擁塞控制方案,以降低RDMA的端到端擁塞和丟包。
在負載均衡方面,路由協議如BGP使用等價路徑多路徑路由(ECMP)來在多條具有相等“代價”的路徑上分發數據包。當數據包到達具有多條到達目標的等價路徑的交換機時,交換機使用哈希函數來決定數據包的發送路徑。然而,哈希不總是完美的,可能會導致某些鏈路負載不均,造成網絡擁塞。
為了解決這個問題,可以采用一些策略,例如預留輕微過量的帶寬,或者實現自適應負載均衡,當某條路徑擁塞時,交換機可以將新流的數據包路由到其他端口。許多交換機已經支持此功能。此外,RoCEv2的數據包級負載均衡可以將數據包均勻地分散在所有可用鏈路上,以保持鏈路平衡。但這可能導致數據包無序到達目的地,需要網卡支持在RoCE傳輸層上處理這些無序數據,確保GPU接收到的數據是有序的。這需要網卡和以太網交換機的額外硬件支持。
另外部分廠商的ROCE以太網交換機,也可以在交換機內部聚合來自GPU的梯度,有助于減少訓練過程中的GPU間流量,如Nvidia的高端以太網交換機等。
總的來說,高端太網交換機和網卡具備強大的擁塞控制、負載均衡功能和RDMA支持,可以擴展到比IB交換機更大的設計。一些云服務提供商和大規模集群的公司已經開始使用基于以太網的GPU網絡,以連接超過32K的GPU。
四、DDC全調度網絡
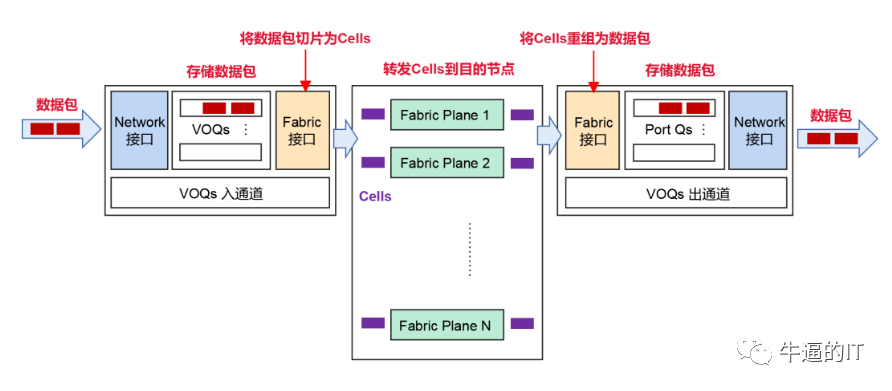
近期,數家交換機/路由器芯片供應商宣布推出支持全調度Fabric或AI Fabric的芯片。這種全調度網絡實際上已經應用于許多模塊化機箱設計中十多年,其中包括Juniper的PTX系列路由器,它們采用了虛擬出口隊列(VOQ)網絡。
在VOQ架構中,數據包僅在入口葉子交換機中進行一次緩沖,存放在與最終出口葉子交換機/WAN端口/輸出隊列相對應的隊列中。這些隊列在入口交換機中被稱為虛擬輸出隊列(Virtual Output Queues, VOQs)。因此,每個入口葉子交換機為整個系統中的每個輸出隊列提供緩沖空間。該緩沖區的大小通常足以容納每個VOQ在40-70微秒內遇到擁塞時的數據包。當VOQ的數據量較少時,它保留在片上緩沖區中;當隊列開始增長時,數據會轉移到外部存儲器中的深度緩沖區。
當入口葉子交換機上的某個VOQ累積了多個數據包后,它會向出口交換機發送請求,要求在網絡中傳輸這些數據包。這些請求通過網絡傳送到出口葉子交換機。
出口葉子交換機中的調度器根據嚴格的調度層次以及其淺輸出緩沖區中的可用空間來批準這些請求。這些批準的速率受到限制,以避免過度訂閱交換機鏈路(超出隊列緩存接受范圍)。
一旦批準到達入口葉子交換機,它就會將所收到批準的一組數據包發送到出口,并通過所有可用的上行鏈路進行傳輸。
發送到特定VOQ的數據包可以均勻地分散在所有可用的輸出鏈路上,以實現完美的負載均衡。這可能導致數據包的重新排序。然而,出口交換機具有邏輯功能,可以將這些數據包按順序重新排列,然后將它們傳輸到GPU節點。
由于出口調度器在數據進入交換機之前就對已批準的數據進行了控制,從而避免了鏈路帶寬的超額使用,因此消除了以太網數據面中99%由incast引起的擁塞問題(當多個端口嘗試向單個輸出端口發送流量時),并且完全消除了頭阻塞(HOL blocking)。需要指出的是,在這種架構中,數據(包括請求和批準)仍然是通過以太網進行傳輸的。
頭阻塞(HOL blocking)是指在網絡傳輸中,一列數據包中的第一個數據包如果遇到阻礙,會導致后面所有的數據包也被阻塞,無法繼續傳輸,即使后面的數據包的目標輸出端口是空閑的。這種現象會嚴重影響網絡的傳輸效率和性能。
一些架構,如Juniper的Express和Broadcom的Jericho系列,通過其專有的分段化(cellified)數據面實現了虛擬輸出隊列(VOQ)。
在這種方法中,葉子交換機將數據包分割為固定大小的分段,并在所有可用的輸出鏈路上均勻分布它們。與在數據包級別進行均勻分布相比,這可以提高鏈路利用率,因為混合使用大型和小型數據包很難充分利用所有鏈路。通過分段轉發,我們還避免了輸出鏈路上的另一個存儲/轉發延遲(出口以太網接口)。在分段數據面中,用于轉發分段的spine交換機被定制交換機所替代,這些定制交換機能夠高效地進行分段轉發。這些分段數據面交換機在功耗和延遲方面優于以太網交換機,因為它們不需要支持L2交換的開銷。因此,基于分段的數據面不僅可以提高鏈路利用率,還可以減少VOQ數據面的總體延遲。
VOQ架構確實存在一些局限性:
每個葉子交換機的入口端應具有合理的緩沖區,以供系統中所有VOQ在擁塞期間緩沖數據包。緩沖區大小與GPU數量及每個GPU的優先級隊列數量成正比。GPU規模較大直接導致更大的入口緩沖區需求。
出口隊列緩沖區應具備足夠的空間,以覆蓋通過數據面的往返延遲,以防在請求-批準握手期間這些緩沖區耗盡。在較大的GPU集群中,使用3級數據面時,由于光纜延遲和額外交換機的存在,此往返延遲可能會增加。如果出口隊列緩沖區未適當調整以適應增加的往返延遲,輸出鏈路將無法達到100%的利用率,從而降低系統的性能。
盡管VOQ系統通過出口調度減少了由于頭阻塞引起的尾延遲,但由于入口葉交換機必須在傳輸數據包之前進行請求-批準握手,因此一個數據包的最小延遲會增加額外的往返延遲。
盡管存在這些限制,全調度的VOQ(fabric)在減少尾延遲方面的性能要明顯優于典型的以太網流量。如果通過增加緩沖區而使鏈路利用率提高到90%以上,則在GPU規模擴大時帶來的額外開銷可能是值得投資的。
此外,供應商鎖定是VOQ(fabric)面臨的一個問題。因為每個供應商都使用自己的專有協議,所以在同一fabric中混合使用和匹配交換機變得非常困難。
總結:主流GPU集群組網技術應用情況
NVLink交換系統雖然為GPU間通信提供了有效解決方案,但其支持的GPU規模相對有限,主要應用于服務器內部的GPU通信以及小規模跨服務器節點間的數據傳輸。
InfiniBand網絡作為一種原生的RDMA網絡,在無擁塞和低延遲環境下表現卓越。然而,由于其架構相對封閉且成本較高,它更適用于中小規模且對有線連接有需求的客戶群體。
ROCE無損以太網則憑借其依托成熟的以太網生態、最低的組網成本以及最快的帶寬迭代速度,在中大型訓練GPU集群的場景中展現出更高的適用性。
至于DDC全調度網絡,它結合了信元交換和虛擬輸出隊列(VOQ)技術,因此在解決以太網擁塞問題方面有著顯著的優勢。作為一種新興技術,目前業界各家仍處于研究階段,以評估其長期潛力和應用前景。
更多GPU技術細節,請參考文章“最新版:GPU顯卡天梯圖(2023年11月)”,“全球GPU呈現“一超一強”競爭格局”,“2023年GPU顯卡詞條報告”,“HBM崛起:從GPU到CPU”,“英偉達GPU龍頭穩固,國內逐步追趕(2023)”,“英偉達L40S GPU架構及A100、H100對比”,“AI芯片第一極:GPU性能、技術全面分析”,“主流國產GPU產品及規格概述(2023)”,“新型GPU云桌面發展白皮書”,“國內外GPU現狀:海外龍頭領跑,國產差距明顯”,“GPGPU流式多處理器架構及原理”等等。
審核編輯:黃飛
?
















 工商網監
工商網監
評論