 電子發燒友App
電子發燒友App


隨著 10Gb 以太網發展趨于成熟,且業界甚至已開始期待 40GbE 和 100GbE 以太網的出現,新一代網絡基礎架構方興未艾。融合型網絡在流量處理方面向可擴展開放式平臺提出了全新的挑戰。新一代融合型基礎設施底板通常由高性能兆兆位 (TB) 交換結構和可編程內容處理器構成,能夠在復雜性不斷增長且層出不窮的各類應用中處理應用層高達數 10 Gb 的流量。CloudShield 已創建了一系列全新的可編程包處理器,能夠對包進行檢測、分類、修改以及復制,融合與應用層的動態交互。
我們的流程加速子系統 (FAST) 采用 Xilinx? Virtex?-class FPGA 來完成為 CloudShield 深度包處理與修改 (CloudShield Deep Packet Processing and ModificaTIon) 刀片的包預處理。這些 FPGA 包含 10Gb 以太網 MAC,并為每個端口配備了用于分類及密鑰提取的入口處理器 (ingress Processor)、用于包修改的出口處理器 (egress processor)、使用四倍數據速率 (QDR) SRAM的包隊列、基于賽靈思 Aurora 的消息傳輸通道以及基于三態內容可尋址存儲器 (TCAM) 的搜索引擎。我們的 FPGA 芯片組能夠以最少的 CPU 參與來完成包的高速緩存及處理,可實現每秒高達 40Gb 的高性能處理能力。其采用 2 至 7 層字段查詢法,能夠根據動態可重配置規則在線速條件下以靈活和可確定的方式進行包修改。
FAST 包處理器的核心功能
我們當前部署的深度包處理刀片采用兩個刀片存取控制器 FPGA 和一個包交換 FPGA,所有這些都通過 LX110T Virtex-5 FPGA 來實施。每個刀片存取控制器都具備使用兩個賽靈思10GbE MAC/PHY 內核實現的數據層連接功能、基于賽靈思 ChipSyncTM 技術的芯片間接口以及使用賽靈思 IP 核的包處理功能。包交換 PFGA 使用標準的賽靈思 SPI-4.2 IP 核來實現與我們的網絡處理器 (NPU) 及我們的 IP 核搜索引擎接口相連。
為了將片上系統的設計重點集中在包處理功能上,我們盡可能使用標準的賽靈思 IP 核。我們選用賽靈思 10Gb 以太網 MAC 內核配合雙 GTP 收發器來實施 4 x 3.125-Gbps 的 XAUI 物理層接口。針對 NPU 接口,我們使用了帶動態相位對準與 ChipSync 技術且支持每 LVDS 差分對高達 1Gbps 速率的賽靈思 SPI-4 Phase 2 內核。我們主要的包處理 IP 核如下:
? FAST 包處理器:FPP 的入口包處理器 (FIPP) 負責第一層包解析、密鑰與數據流 ID 的散列生成以及按端口進行的第 3 層至第 4 層校驗和驗證。FPP 的出口包處理器 (FEPP) 可執行出口包修改并重新計算第 3 層至第 4 層的校驗和。
? FAST 搜索引擎:我們 FSE 在 TCAM 和 QDR SRAM 中維護著一個流數據庫,可用于決定需要在入口包上執行的處理任務。該 FSE 可從每個端口的 FIPP 處接受密鑰消息,決定針對該包需要執行的處理任務,然后將結果消息返還給原始發出消息的隊列。
? FAST 數據隊列:我們的數據隊列 (FDQ) 可在“無序”保持緩沖器中存儲傳送進來的包。當入口包被寫入到 QDR SRAM 時,該隊列將密鑰消息從 FIPP 發送至 FAST 搜索引擎。該 FSE 將使用這一密鑰來決定如何處理此包,然后將結果消息返還給 FDQ。根據該結果消息,隊列可對每個緩沖的包進行轉發、復制或丟棄處理。此外,該隊列還可對已轉發或已復制的包獨立進行包修改。
數據流的輸入與輸出
圖 1 顯示了流經我們流量加速子系統的數據流。核心 FPGA 功能以綠色表示,包數據流為黃色,控制消息為藍色,外部器件則為灰色。
首先,我們可從 10GbE 網絡端口所接收到的包來識別客戶數據流的開始。每個端口上的包都會進入 FAST 入口包處理器進行包解析與分析(圖中的 1 號)。在對協議和封包進行分類之后,FIPP 可定位第 2、3 以及 4 層的報頭偏移量。接下來是數據流散列與密鑰抽取(數據流選擇查找規則,如使用源 IP 地址、目的地 IP 地址、源和目的地端口和協議的五元組法 (5-tuple))。
此時,我們的隊列管理器緩沖器負責接收包,以釋放外部 QDR SRAM 的存儲器頁面。在此階段接收到的包都被認為是無序的。在等待 FAST 調度的同時,我們將它們置于外部 QDR SRAM 中。FAST 數據隊列(圖中的 2 號)分配包 ID,并向 FAST 搜索引擎(圖中的 3 號)分派密鑰消息。FAST 搜索引擎使用該密鑰來識別數據流。外部 TCAM 中匹配的數據流條目可在關聯的 SRAM 中向數據流任務表 (Flow Action Table) 提供索引。匹配的數據流任務根據客戶配置的應用訂閱進行確定。
FAST 搜索引擎向 FDQ(圖中的 4 號)發送結果消息進行回復,然后由任務調度程序根據其指定的任務將包分配給某個輸出隊列。然后我們從包隊列中將包解至專用的目的地輸出端口(圖中的 5 號),其中我們的 FAST 出口包處理器(圖中的 6 號)可根據指定任務的要求按數據流修改表 (Flow ModificaTIon Table) 中的規則處理包修改。
如果我們的 FAST 搜索引擎能夠與客戶數據流的匹配,則會執行指定的任務,如果不能,就執行默認的規則(丟棄或發送至 NPU)。我們允許的基本任務包括:丟棄包、將包直接轉發至網絡端口、將包轉發給異常包處理 NPU 或復制包并依據獨立規則轉發包。我們的擴展任務包括包塌縮 (Packet collapse)(刪除包的一部分)、包擴展/寫入(在包中插入一系列字節)、包覆蓋 (packet overwrite)(修改一系列字節)及其組合。以包覆蓋規則為例,可以是修改MAC 源地址或目的地地址、修改 VLAN 的內或外部標記 (tag),或更改第 4 層報頭標記。插入/刪除的例子可以是簡單到刪除現有的 EtherType、插入 MPLS 標簽或者 VLAN Q-in-Q 標記,也可以是復雜到需要先插入一個作為 GRE 交付報頭的 IP 報頭,接著緊隨一個 GRE 報頭(通用路由協議封裝 (GRE) 是一種隧道協議,具體參閱因特網 RFC 1702 號文件)。
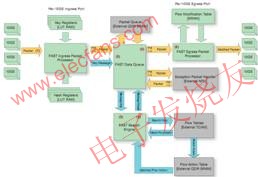
圖 1 – 流加速子系統中的數據流

?
圖 2 – 針對 Type II 以太網 TCP/IP 包的 5 元組密鑰提取
FAST 包處理器
FAST 入口包處理器可對所有包進行解碼,以確定第 2 層、3 層以及 4 層的內容(若存在)。在完成以太網第 2 層的初步解碼之后,可對包進行更進一步的 2 層處理。隨后我們繼續進行第 3 層,處理 IPv4 或 IPv6 包。假定我們發現這種第 3 層類型的其中之一存在,我們即繼續進行第 4 層處理。
在對包進行解碼的同時,我們的密鑰抽取單元也在定位并存儲密鑰字段,以生成可供我們 FAST 搜索引擎在日后用于數據流查找的搜索密鑰。圖 2 是 Type II 以太網 (Ethernet Type II)的 TCP/IP 包格式和待抽取的標準 5 元組密鑰,此外還顯示了從本例中抽取的結果密鑰。
我們還可同時對入口處理器與出口處理器的各類包執行 IP、TCP、UDP 以及 ICMP 校驗和計算。兩個 Virtex-5 FPGA DSP48E slice 可提供校驗和計算以及驗證所需的加法器。我們的第一個 DSP 可在 32 位的邊界內對數據流進行匯總,而第二個 DSP 則負責在相關層的計算結束時將所得總數折疊成 16 位的校驗和。然后我們進行校驗和的計算;對于重計算,我們可將傳輸進入的數據流的校驗和字節位置清空,使用存儲緩沖器將校驗和結果的倒數重新插回。可將第 4 層校驗和要求的偽報頭字節多路復用到傳輸進入的數據流中,以用于最終計算。
每個輸出端口的 FAST 出口包處理器都可根據規則表(規則存儲在內部 BRAM 中)進行包修改和第 3 層至 4 層校驗和的重新計算及插入。該 FEPP 超越了傳統的包修改“固定功能”方案,從而能夠按照指定的修改規則編號對包進行覆蓋、插入、刪除或者截斷操作等修改。我們的數據流修改規則支持可代表操作類型的操作碼規范,以 OpLoc 代表啟始位置、OpOffset 代表偏移、Insert Size 代表插入的數據大小、Delete Size 代表刪除的數據大小,以及是否執行第 3 層和第 4 層校驗和計算和插入以及是否進行修改規則鏈化。
我們的新一代實施方案不僅能夠顯著提升性能、進一步加強高速緩沖的能力,同時還能添加新功能。通過把我們的 FAST 芯片組升級到單個的賽靈思 Virtex-6 FPGA,我們不僅能夠將新一代 FAST 的功能、接口和性能提升到一個前所未有的水平,同時還能縮小板級空間并降低功耗要求,從而實現單芯片深度包處理協處理器單元。
我們能夠使用包覆蓋特性來簡單地對諸如 MAC 目的地地址、MAC 源地址、VLAN 標記甚或是單個 TCP 標志等現有字段進行修改。
如果只需要修改 MAC 目標地址,FEPP 在接受到包時收到的“任務”將會被使用,例如,流修改表(圖 3)中的規則 2。對規則 2 預先配置的內容包括:指定操作碼(覆蓋)、OpLoc(在包中所處的位置,比如第 2 層)、OpOffset(距離啟始位置的偏移)、掩碼類型(使用什么字節)以及修改數據(實際覆蓋的數據)等。執行的結果是使用預先配置的修改數據覆蓋從第 2 層位置開始的 6 個字節。
?
圖 3 – 簡單 MAC 目的地地址覆蓋修改
另一種覆蓋實例是如規則 6 所示的方案,例如我們希望修改某個特定的 TCP 標志,如 ACK、SYN 或者 FIN(參見圖 4)。該規則將使用操作碼(覆蓋)、OpLoc(第 4 層)、OpOffset(從第 4 層開始 0 偏移)、掩碼類型(使用字節 14)和位掩碼(字節中的那些位需要掩蔽)。我們可以使用掩碼類型來包含或是排除特定的字節,從而指定多個字段實現覆蓋。

?
圖 4 – TCP 標志的覆蓋修改
我們的覆蓋功能不僅限于數據流修改規則表中存儲的內容,而且還能包括作為關聯數據存儲在數據流任務表 (Flow AcTIon Table) 中的內容。可以通過指定規則,讓傳輸到 FEPP 的關聯數據成為任務的組成部分,從而顯著擴展可用于修改的數據的范圍。其結果,舉例來說,是可以覆蓋整個 VLAN 標記范圍。
我們的插入/刪除功能能夠實現甚至更為復雜的包修改。以規則 5(參見圖 5)為例,使用我們的插入/刪除功能。包括操作碼(插入/刪除)、OpLoc(第 2 層)、OpOffset(從第 12 個字節開始)、ISize(插入數據大小= 22 個字節)、DSize(刪除的字節大小 = 2個字節)和Insert Data(0x8847,MPLS 標簽)等與規則5相關的各種任務,將刪除現有的 EtherType,并插入新的 EtherType="8847",這說明新的包將是一個 MPLS 單播包,接著是由插入數據所指定的 MPLS 標簽組。

?
圖 5 – MPLS 標簽插入修改
布局規劃與時序收斂
在設計我們獨特的包處理器過程中,我們面臨的最嚴峻挑戰是 FPGA 設計復雜程度不斷增大,路由和使用密度的增加,各種 IP 核的集成,多種硬邏輯對象的使用(如 BRAM、GTP、DSP 以及類似對象),以及在項目最早期階段的數據流規劃不足等。我們發布的 Phase 1 Virtex-5 FPGA 的bit文件建立在較低的使用密度之上,特別是較低的 BRAM 使用密度基礎之上,結果導致相對簡單的時序收斂。在稍后階段因為增加了新的重要功能,導致 BRAM 的利用密度接近 97%,我們開始強烈意識到優化布局規劃的重要意義,以及產品生命周期初期的決策將對后期造成怎樣的影響。
布局規劃的主要目標通過減少路由延遲來改進時序。為此,在設計分析過程中非常重要的事情就是將數據流和管腳配置納入考慮范圍。現在已經與 ISE? 結合一起的賽靈思 PlanAheadTM工具作為布局規劃和時序分析的單點工具 (point tool),為我們提供了如何在高利用率的使用設計中為了實現時序收斂而需要穿越重重復雜網絡的交互分析和可視化功能。PlanAhead 使我們能深入了解我們的設計,即我們需要提供最少數量的約束條件來引導映射、布置以及布線工具充分滿足我們的時序要求。我們發現,要做到這一點,往往需要在基于模塊的設計區域約束之外優化放置一部分關鍵的 BRAM。
回想起來,如果我們在項目最初階段即花更多的時間使用 PlanAhead 來進行假定方案的驗證,幫助我們看到最佳的數據流和管腳,我們在設計后期的任務就會輕松許多。
動態自適應包處理
我們的整數流加速子系統能夠在最高的靈活程度下以線速檢查并和修改包,同時能夠動態地與應用層業務進行交互,實現高度自適應的包處理。Virtex-class FPGA 是重要的實現手段,提供了一個前一代 FPGA 無法實現的片上系統平臺,加速基于內容的路由以及實施重要包處理功能。
我們的新一代實施方案不僅能夠顯著提升性能、進一步加強高速緩沖的能力,同時還能添加新功能。通過在單個賽靈思 Virtex-6 FPGA 中升級我們的 FAST 芯片組,我們不僅能夠將新一代 FAST 的功能、接口和性能提升到一個前所未有的水平,同時還能縮小電路板空間并降低功耗要求,從而實現單芯片深度包處理協處理器單元。









 工商網監
工商網監
評論