 電子發燒友App
電子發燒友App


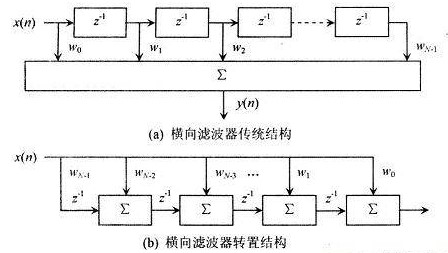
這一節主要講解一下轉置型FIR濾波器實現。
FIR濾波器的單位沖激響應h(n)可以表示為如下式:
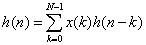
對應轉置型結構的FIR濾波器,如圖1所示,抽頭系數與上一節中講解直接型FIR濾波器的實例相同,濾波器階數為10。

圖1
可以發現轉置型結構不對輸入數據寄存,而是對乘累加后的結果寄存,這樣關鍵路徑上只有1個乘法和1個加法操作,相比于直接型結構,延時縮短了不少。
綜合得到結果如下:
Number of Slice Registers: 1
Number of Slice LUTs: 18
Number of DSP48E1s: 11
Minimum period: 4.854ns{1} (Maximum frequency: 206.016MHz)
關鍵路徑延時報告如圖2所示,其中乘累加操作延時Tdspdck_A_PREG_MULT 2.655ns;另外還有一項net delay居然有1.231ns,如此大是因為fanout=11,仔細研究可以發現在h(n)表達式中x(n)與所有11個抽頭系數進行了乘法操作,因此fanout達到了11,這也是轉置型FIR濾波器的缺點:輸入數據的fanout過大。
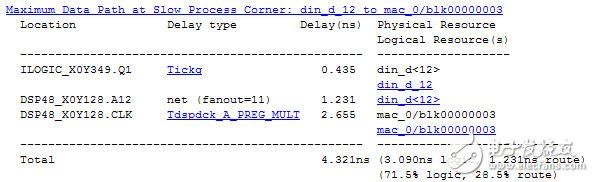
圖2
線性相位:
與直接型結構相同,由FIR濾波器的線性相位特征,轉置型結構的FIR濾波器也可優化,如圖3所示為線性相位FIR濾波器轉置型結構,總共11個抽頭系數,其中5對系數兩兩相同,因此可以省去5個乘法器,采用6個DSP資源實現轉置型FIR濾波器。

圖3
流水線實現:
為了進一步縮短關鍵路徑的延時,將乘法器和加法器邏輯分割開,中間加入流水線級,結果如圖4所示,在線性相位結構的基礎上,加入一級寄存器,這樣最大限度上優化時序。
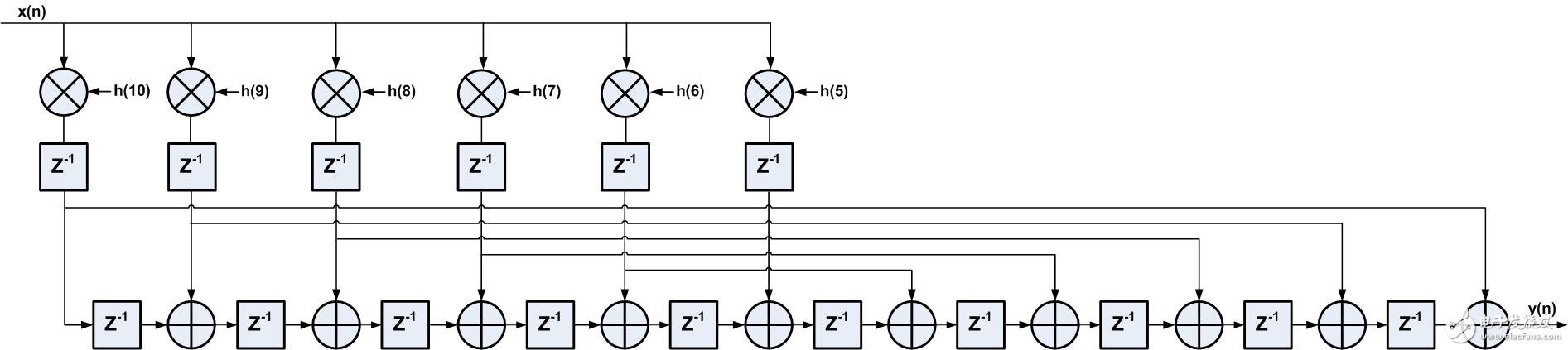
圖4
綜合得到結果如下:
Number of Slice Registers: 355
Number of Slice LUTs: 340
Number of DSP48E1s: 6
Minimum period: 3.861ns{1} (Maximum frequency: 259.000MHz)
如圖5所示為與圖2中相對應路徑的延時報告(圖2由ISE的Timing Analysis工具產生,圖5是由PlanAhead的Timing Analysis工具產生),其中由于采用線性相位結構,輸入信號的fanout只有6,延時從原先的1.231ns減小到1.01ns;并且分隔乘法器和加法器邏輯之后,關鍵路徑上只有乘法器的延時:1.42ns。
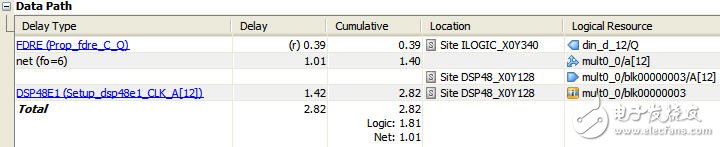
圖5
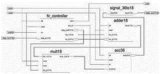
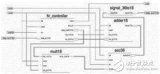
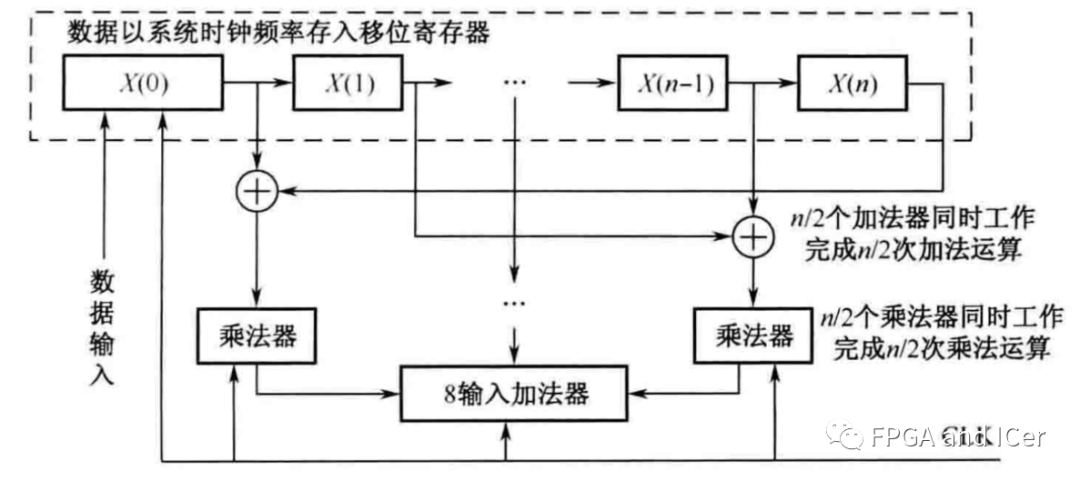
脈動型FIR濾波器是對直接型的升級,在每個操作后都加入流水線級,每個動作都打一拍,就跟心臟跳動一樣,因此稱為脈動型,這種結構非常適用于高速數據流的處理。如圖1所示為脈動型FIR濾波器結構。

圖1
與直接型結構不同的是,輸入數據到下一個處理單元都需要打2拍,這是為了使乘法后的累加數據同步,下面推導驗證:
x(n)為輸入數據,yt(n)為直接型結構的輸出
yt(n)=x(n)h(0)+x(n-1)h(1)+x(n-2)h(2)…x(n-10)h(10)
ys(n)為脈動型結構的輸出,如圖1中有P1、P2…P10共10個節點
P1=x(n-4)h(0)
P2=(P1 + x(n-5)h(1))*Z-1=x(n-5)h(0) + x(n-6)h(1)
…
P10=(P9 + x(n-23)h(10))*Z-1
ys(n)=x(n-14)h(0) + x(n-15)h(1) + … + x(n-23)h(9)+ x(n-24)h(10)
由ys(n)和yt(n)的表達式,可以推導出ys(n)=yt(n-14)
因此脈動型FIR濾波器的延遲較大
如圖2所示為11抽頭系數脈動型FIR濾波器FPGA實現結構(實例與前幾節相同),穿了一層“衣服”,采用Xilinx FPGA中的DSP48E1 實現,基本處理單元中的操作都可在一個DSP48E1中完成,輸入數據經過DSP48E1中寄存2拍后通過ACOUT輸出,直接連接到下一個 DSP48E1中的ACIN端口,累加輸出PCOUT直接連接到下一個DSP48E1中的PCIN端口,這些連接都沒有經過FPGA的Fabric連線邏輯,而是通過DSP Block的內部走線連接,這樣實現能夠縮短路徑的延時。
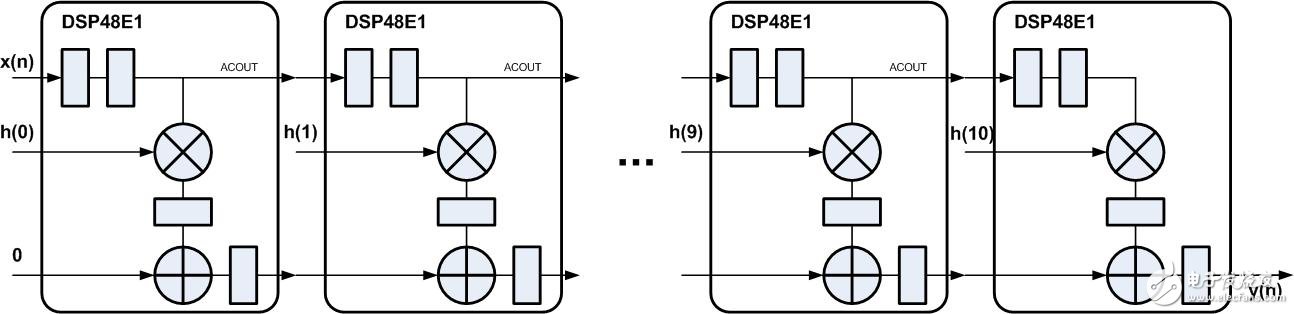
圖2
編寫了相關代碼,綜合結果如下:
Number of Slice Registers: 4
Number of Slice LUTs: 19
Number of DSP48E1s: 11
Minimum period: 3.006ns{1} (Maximum frequency: 332.668MHz)
線性相位實現:
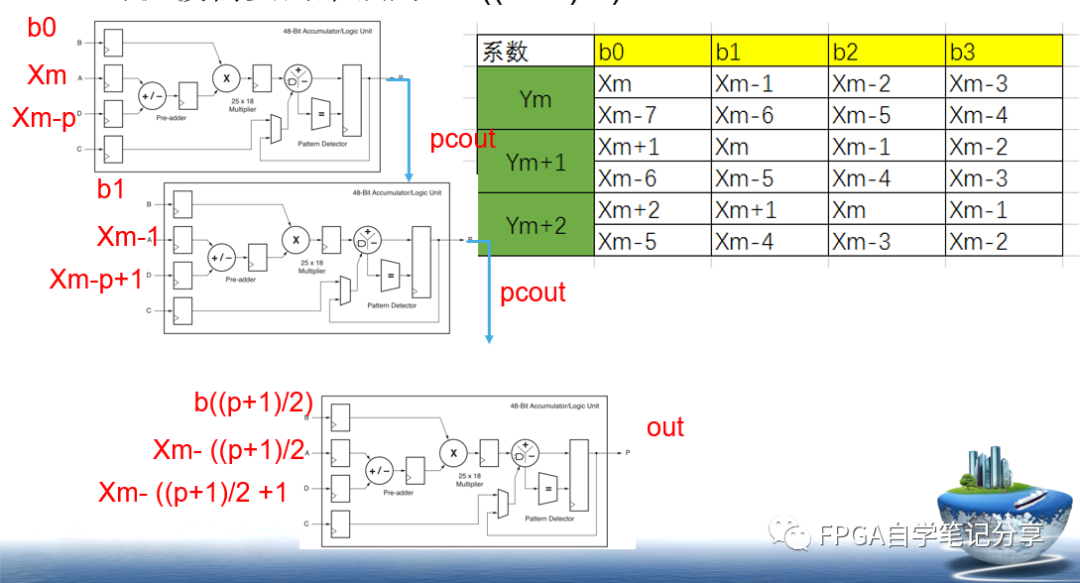
與前幾節相同,由于FIR濾波器的線性相位特性,相對應有線性相位的實現結構,如圖3所示,利用DSP48E1中預加器實現乘法前的加法操作。對于脈動型 FIR濾波器的線性相位結構有很多注意點,其中預加器數據的配對,常規情況下,此例中應是x(n)和x(n-10)、x(n-1)和x(n-9)、 x(n-2)和x(n-8)、x(n-3)和x(n-7)、x(n-4)和x(n-6),而圖3中結構,加入了延時11的移位寄存器,預加器配對的數據為 x(n-2)和n(n-12)、x(n-4)和x(n-12)、x(n-6)和x(n-12)、x(n-8)和x(n-12)、x(n-10)和x(n- 12),可以發現預加器配對數據中有一個數據始終是x(n-12),但是每一個配對數據的相對延時與常規情況下相同:10、8、6、4和2。
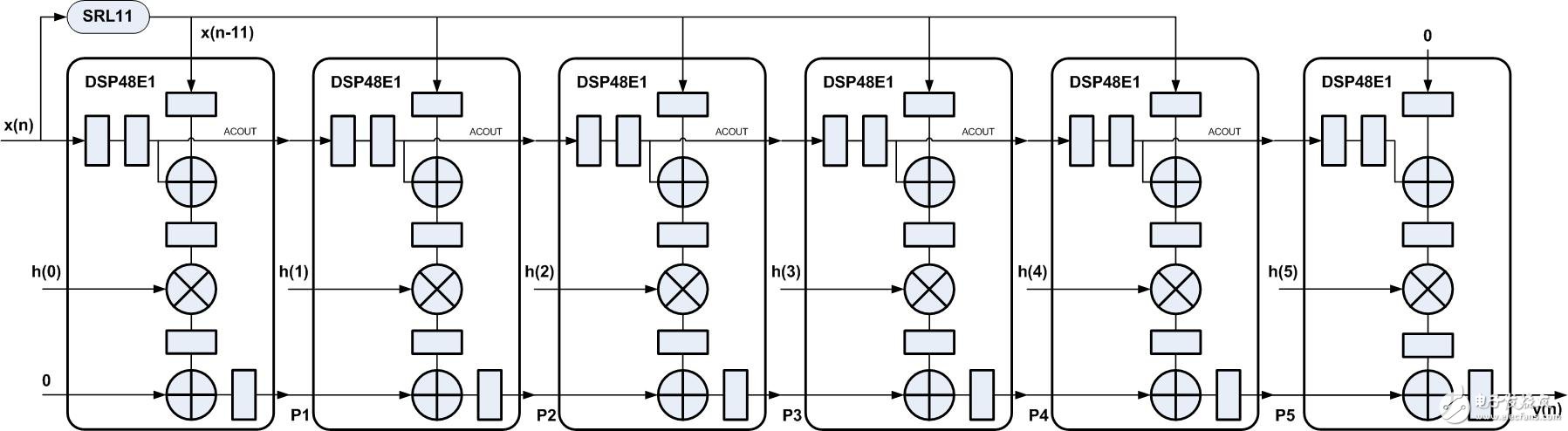
圖3
而各節點P1、P2、P3、P4、P5和y(n)的表達式如下
P1=x(n-5)h(0) + x(n-15)h(0)
P2=( P1 + (x(n-6)h(1) + x(n-14)h(1)) )Z-1=x(n-6)h(0) + x(n-16)h(0) + x(n-7)h(1) + x(n-15)h(1)
P3=( P2 + (x(n-8)h(2) + x(n-14)h(2)) )Z-1=x(n-7)h(0) + x(n-17)h(0) + x(n-8)h(1) + x(n-16)h(1) + x(n-9)h(2) + x(n-15)h(2)
P4=( P3 + (x(n-10)h(3) + x(n-14)h(3)) )Z-1=x(n-8)h(0) + x(n-18)h(0) + x(n-9)h(1) + x(n-17)h(1) + x(n-10)h(2) + x(n-16)h(2) + x(n-11)h(3) + x(n-15)h(3)
P5=( P4 + (x(n-12)h(4) + x(n-14)h(4)) )Z-1=x(n-9)h(0) + x(n-19)h(0) + x(n-10)h(1) + x(n-18)h(1) + x(n-11)h(2) + x(n-17)h(2) + x(n-12)h(3) + x(n-16)h(3) + x(n-13)h(4) + x(n-15)h(4)
y(n)=(P5 + x(n-14)h(5))Z-1= x(n-10)h(0) + x(n-20)h(0) + x(n-11)h(1) + x(n-19)h(1) + x(n-12)h(2) + x(n-18)h(2) + x(n-13)h(3) + x(n-17)h(3) + x(n-14)h(4) + x(n-16)h(4) + x(n-15)h(5)
因抽頭系數對稱,由h(0)=h(10),h(1)=h(9),h(2)=h(8),h(3)=h(7),h(4)=h(6)可得
y(n)= x(n-10)h(0) + x(n-11)h(1) + x(n-12)h(2) + x(n-13)h(3) + x(n-14)h(4) + x(n-15)h(5) + x(n-16)h(6) + x(n-17)h(7) + x(n-18)h(8) + x(n-19)h(9) + x(n-20)h(10)
驗證得到y(n)=yt(n-10),比普通脈動結構延時小,但是相比于其他結構的FIR濾波器延時還是較大的。
編寫了相關代碼,綜合結果如下:
Number of Slice Registers: 84
Number of Slice LUTs: 99
Number of DSP48E1s: 6
Minimum period: 3.256ns{1} (Maximum frequency: 307.125MHz)
在DSP in FPGA: FIR濾波器設計(一)、(二)中分別講解了直接型、轉置型和脈動型結構FIR濾波器的實現方法,這三種結構是FPGA實現中比較常用的方法,以下對這三種結構做一個比較:
(1) 直接型:方法簡單易實現,但是使用加法樹優化后增加了功耗
(2) 轉置型:關鍵路徑延時較小,時序易滿足,但是輸入數據扇出較大,不適用于階數較高的濾波器實現
(3) 脈動型:適用于高速數據處理,但是延時相比于其它結構較大
?
?







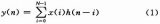







 工商網監
工商網監
評論