 電子發燒友App
電子發燒友App


著名:?本文是從 Michael Nielsen的電子書Neural Network and Deep Learning的深度學習那一章的卷積神經網絡的參數優化方法的一些總結和摘錄,并不是我自己的結論和做實驗所得到的結果。我想Michael的實驗結果更有說服力一些。本書在github上有中文翻譯的版本,
前言
最近卷積神經網絡(CNN)很火熱,它在圖像分類領域的卓越表現引起了大家的廣泛關注。本文總結和摘錄了Michael Nielsen的那本Neural Network and Deep Learning一書中關于深度學習一章中關于提高泛化能力的一些概述和實驗結果。力爭用數據給大家一個關于正則化,增加卷積層/全連接數,棄權技術,拓展訓練集等參數優化方法的效果。
本文并不會介紹正則化,棄權(Dropout), 池化等方法的原理,只會介紹它們在實驗中的應用或者起到的效果,更多的關于這些方法的解釋請自行查詢。
mnist數據集介紹
本文的實驗是基于mnist數據集合的,mnist是一個從0到9的手寫數字集合,共有60,000張訓練圖片,10,000張測試圖片。每張圖片大小是28*28大小。我們的實驗就是構建一個神經網絡來高精度的分類圖片,也就是提高泛化能力。
提高泛化能力的方法
一般來說,提高泛化能力的方法主要有以下幾個:
正則化
增加神經網絡層數
使用正確的代價函數
使用好的權重初始化技術
人為拓展訓練集
棄權技術
下面我們通過實驗結果給這些參數優化理論一個直觀的結果
1. 普通的全連接神經網絡的效果
我們使用一個隱藏層,包含100個隱藏神經元,輸入層是784,輸出層是one-hot編碼的形式,最后一層是Softmax層。訓練過程采用對數似然代價函數,60次迭代,學習速率η=0.1,隨機梯度下降的小批量數據大小為10,沒有正則化。在測試集上得到的結果是97.8%,代碼如下:
>>> import network3
>>> from network3 import Network
>>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>> training_data, validation_data, test_data = network3.load_data_shared()
>>> mini_batch_size = 10
>>> net = Network([
FullyConnectedLayer(n_in=784, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
2.使用卷積神經網絡 — 僅一個卷積層
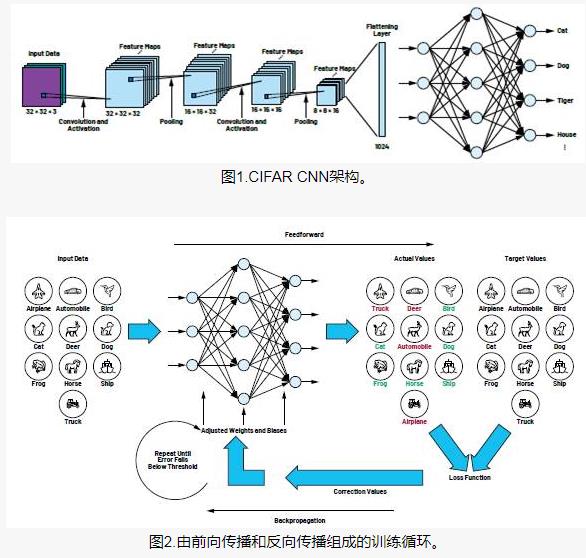
輸入層是卷積層,5*5的局部感受野,也就是一個5*5的卷積核,一共20個特征映射。最大池化層選用2*2的大小。后面是100個隱藏神經元的全連接層。結構如圖所示

在這個架構中,我們把卷積層和chihua層看做是學習輸入訓練圖像中的局部感受野,而后的全連接層則是一個更抽象層次的學習,從整個圖像整合全局信息。也是60次迭代,批量數據大小是10,學習率是0.1.代碼如下,
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
經過三次運行取平均后,準確率是98.78%,這是相當大的改善。錯誤率降低了1/3,。卷積神經網絡開始顯現威力。
3.使用卷積神經網絡 — 兩個卷積層
我們接著插入第二個卷積-混合層,把它插入在之前的卷積-混合層和全連接層之間,同樣的5*5的局部感受野,2*2的池化層。
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=40*4*4, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
這一次,我們擁有了99.06%的準確率。
4.使用卷積神經網絡 — 兩個卷積層+線性修正單元(ReLU)+正則化
上面我們使用的Sigmod激活函數,現在我們換成線性修正激活函數ReLU
f(z)=max(0,z),我們選擇60個迭代期,學習速率η=0.03, ,使用L2正則化,正則化參數λ=0.1,代碼如下
>>> from network3 import ReLU
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
這一次,我們獲得了99.23%的準確率,超過了S型激活函數的99.06%. ReLU的優勢是max(0,z)中z取最大極限時不會飽和,不像是S函數,這有助于持續學習。
5.使用卷積神經網絡 — 兩個卷基層+線性修正單元(ReLU)+正則化+拓展數據集
拓展訓練集數據的一個簡單方法是將每個訓練圖像由一個像素來代替,無論是上一個像素,下一個像素,或者左右的像素。其他的方法也有改變亮度,改變分辨率,圖片旋轉,扭曲,位移等。
我們把50,000幅圖像人為拓展到250,000幅圖像。使用第4節一樣的網絡,因為我們是在訓練5倍的數據,所以減少了過擬合的風險。
>>> expanded_training_data, _, _ = network3.load_data_shared(
"../data/mnist_expanded.pkl.gz")
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
這次的到了99.37的訓練正確率。
6.使用卷積神經網絡 — 兩個卷基層+線性修正單元(ReLU)+正則化+拓展數據集+繼續插入額外的全連接層
繼續上面的網絡,我們拓展全連接層的規模,300個隱藏神經元和1000個神經元的額精度分別是99.46%和99.43%.
我們插入一個額外的全連接層
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
這次取得了99.43%的精度。拓展后的網絡并沒有幫助太多。
7.使用卷積神經網絡 — 兩個卷基層+線性修正單元(ReLU)+拓展數據集+繼續插入額外的全連接層+棄權技術
棄權的基本思想就是在訓練網絡時隨機的移除單獨的激活值,使得模型對單獨的依據丟失更為強勁,因此不太依賴于訓練數據的特質。我們嘗試應用棄權技術到最終的全連接層(不是在卷基層)。這里,減少了迭代期的數量為40個,全連接層使用1000個隱藏神經元,因為棄權技術會丟棄一些神經元。Dropout是一種非常有效有提高泛化能力,降低過擬合的方法!
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(
n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
FullyConnectedLayer(
n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
mini_batch_size)
>>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
validation_data, test_data)
使用棄權技術,的到了99.60%的準確率。
8.使用卷積神經網絡 — 兩個卷基層+線性修正單元(ReLU)+正則化+拓展數據集+繼續插入額外的全連接層+棄權技術+組合網絡
組合網絡類似于隨機森林或者adaboost的集成方法,創建幾個神經網絡,讓他們投票來決定最好的分類。我們訓練了5個不同的神經網絡,每個都大到了99.60%的準去率,用這5個網絡來進行投票表決一個圖像的分類。
采用這個方法,達到了99.67%的準確率。
總結
卷積神經網絡 的一些技巧總結如下:
1. 使用卷積層極大地減小了全連接層中的參數的數目,使學習的問題更容易
2. 使用更多強有力的規范化技術(尤其是棄權和卷積)來減小過度擬合,
3. 使用修正線性單元而不是S型神經元,來加速訓練-依據經驗,通常是3-5倍,
4. 使用GPU來計算
5. 利用充分大的數據集,避免過擬合
6. 使用正確的代價函數,避免學習減速
7. 使用好的權重初始化,避免因為神經元飽和引起的學習減速













 工商網監
工商網監
評論