 電子發燒友App
電子發燒友App


當人們提到卷積神經網絡(CNN), 大部分是關于計算機視覺的問題。卷積神經網絡確實幫助圖像分類以及計算機視覺系統核心取得了重要突破,例如Facebook自動照片加tag的功能啊,自動駕駛車輛等。
近年來,我們也嘗試用CNN去解決神經語言學(NLP)中的問題,并且獲得了一些有趣的結果。理解CNN在NLP中的作用比較困難,但是它在計算機視覺中的作用就更容易理解一些,所以呢,在本文中我們先從計算機視覺的角度出發談一談CNN,慢慢再過渡到NLP的問題中去~
什么是卷積神經網絡
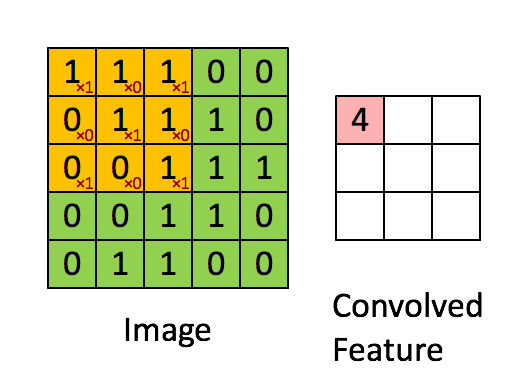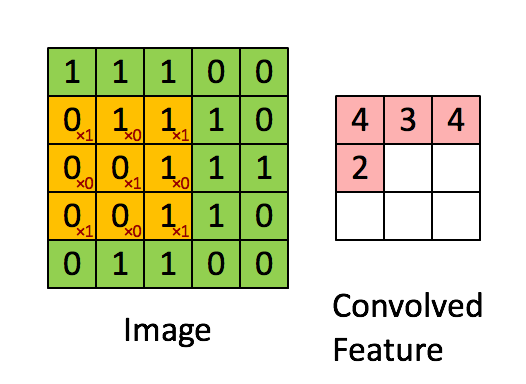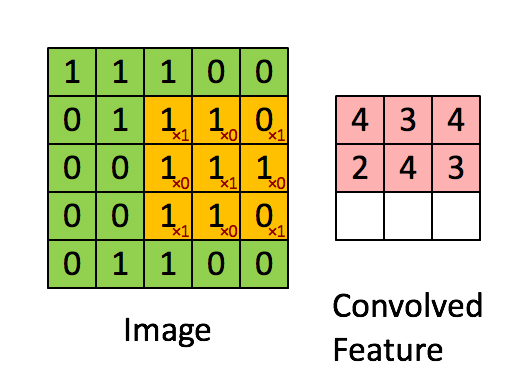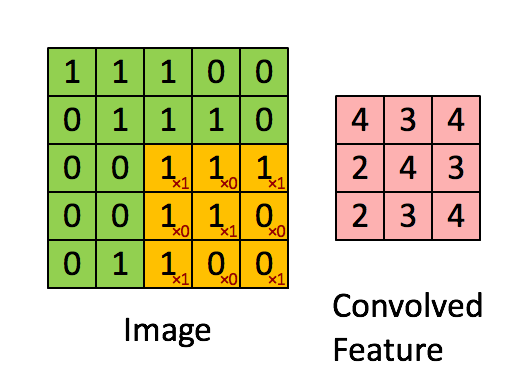
對我來說,最容易理解卷積的辦法是把它理解成一個滑動的窗口函數,就像是一個矩陣一樣。雖然很拗口,但是看起來很直觀(如下圖,自行領悟):
?
Convolution with 3×3 Filter. Source:
讓我們發揮想象力,左邊的矩陣代表一個黑白圖像。每個方格對應一個像素,0表示黑色,1表示白色(通常來說,計算機視覺處理的圖像是一個灰度值在0到255之間的灰度圖)。滑動的窗口被稱為一個(卷積)內核、過濾器(譯者:有那么點濾波器的感覺)或者特征檢測器(譯者:用于特征提取)。
現在,我們用一個3×3的過濾器,將它的值與原矩陣中的值相乘,然后求和。為了得到右邊的矩陣,我們需要將在完整的矩陣中每一個3×3子矩陣做一次操作。
你可能在想這種操作有什么作用,下面有兩個例子
模糊處理
讓像素與周圍像素值平均后,圖像發生模糊。
(譯者:類似于將周圍幾個像素的數值平攤一下)

?
?
邊緣檢測
對像素與周圍像素值做差后,邊界就變得顯著了。
為了更好地理解這個問題,先想想在一個像素變化平滑連續的圖像上,一塊像素點和周圍的幾個像素點相同的時候,會發生什么:那些因相互比較產生的增量就會消失,每個像素的最終值將會是0,也就是黑色。(譯者:猜是沒有對比度了)。如果那有很強的有著明顯色差的邊界,例如從白色到黑色的圖像邊界,那你就會得到明顯的反差,從而得到白色。

這個 GIMP manual 網址有更多的例子。(譯者:如銳化啊、邊緣加強之類的,還有一個似乎是可以這樣做卷積修圖的軟件)。如果想了解得更多的話,建議你們看看這個 Chris Olah’s post on the topic.
什么是卷積神經網絡
你現在已經知道了什么是卷積了,那么什么是卷積神經網絡呢?簡單說來,CNN就是用好幾層使用非線性激活函數(如,ReLu,tanh)的卷積得到答案的神經網絡。
在傳統的前饋神經網絡中,我們將每一層的每個輸出和下一層的每個輸入相互連接,這也被稱為完全連接層或仿射層。但是CNN中并不是這樣。相反,我們使用卷積在輸入層中計算輸出(譯者:卷積造成部分映射,參見之前的卷積圖),這就導致了局部連接,一個輸出值連接到部分的輸入(譯者:利用層間局部空間相關性將相鄰每一層的神經元節點只與和它相近的上層神經元節點連接)。
每一層都需要不同的過濾器(通常是成千上萬的),就類似上文提到的那樣,然后將它們的結果合并起來。那還有一個叫做池(pooling layer)或者下采樣層(subsampling layers)的東西,之后再說吧。
在訓練階段中,CNN能夠通過訓練集自動改善過濾器中的參數值。舉個例子,在圖像分類問題中,CNN能夠在第一層時,用原始像素中識別出邊界,然后在第二層用邊緣去檢測簡單的形狀,然后再用這些形狀來識別高級的圖像,如人臉形狀啊,房子啊(譯者:特征提取后可以通過特征分辨圖像)。最后一層就是用高級的圖像來進行分類。

?
在計算方面有兩個值得注意的東西:局部不變性(Location Invariance)和組合性(Compositionality)。
假設你要辨別圖像上有木有大象,進行一次二分類(就是分成有大象和沒有大象的兩種)。
咱們的過濾器將掃描整個圖像,所以并不用太在意大象到底在哪兒。在現實中,pooling也使得你的圖像在平移、旋轉、縮放的時候保持不變(后者的情況更多些)。
組合性(局部組合性),每個過濾器獲取了低層次的圖片的一部分,組合起來成了高層次圖片。
這就是為什么CNN在計算機視覺上表現地如此給力。在從像素建邊,從邊到確立形狀,從形狀建立更加復雜的物體過程中,CNN會給人一個直觀的感受。
CNN在NLP中的用途
相比于圖像與像素,大多數的NLP問題的輸入是句子或者文檔構成的矩陣。矩陣的每一行一般來說是一個單詞,也可以是一個字符(如,字符)。所以呢,每一行就是表示一個單詞的向量。通常每一個向量是一個放棄詞向量word embeddings(低緯度的表示方法),例如word2vec or GloVe, 它們也可以是one-hot vectors 用于表示單詞。對于一個10個詞的句子,用一個100維的embedding表示,我們就有10×100的矩陣作為我們的輸出,這就是我們的“圖像”。
在這樣看來,我們的過濾器在一個圖像的小塊像素上滑動,但是在NLP問題上,我們用過濾器在矩陣的每一個完整的行上面滑動(就是一個單詞)。所以呢,過濾器的寬度一般和輸入矩陣的寬度相同。高度、區域大小一般各有不同,但是一般都是一次讀2-5個單詞。
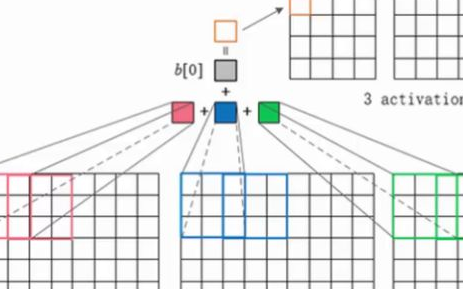
將上面說的全部聯系起來,那么一個用于NLP問題的CNN就是醬紫的(花點時間,試著理解下面這張圖,想想每一維度是怎么被計算的,目前可以忽略池pooling,過會兒再說):

?
用于句子分類的卷積神經網絡結構圖。
我們有三種過濾器,它們的高度分別為: 2,3, 4,每種過濾器共兩個。每個過濾器在句子矩陣里進行卷積并且產生一個長短不一的特征映射(feature maps),然后一個1-max pooling在每個映射上運行,每個特征映射的最大數值都被記錄下來。因此,一個單變量特征向量由所有六個映射生成,這6個特征被級聯以形成用于倒數第二層的特征向量。 最后的 Softmax層就以輸入的形式接收到這些特征向量,然后用它來進行句子分類;這里我們假設二分類,也就是描述兩個可能的輸出狀態。
Source: Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
那我們能不能擁有像計算機視覺那樣的直觀感受呢?局部不變性(Location Invariance)和局部組合性(local Compositionally,譯者:我猜是mac自動更換造成的書寫錯誤)產生了對于圖像處理的直觀感受,但是這些對于NLP問題來說并不是特別直觀。你可能更加注意一個單詞出現在句子中的哪一個位置。(這里有一個疑問,因為后文說了,并不在意它在哪個位置,而是在意它有沒有出現過)
相互靠近的像素非常可能有‘語義’上面的聯系,比如可能是一個物體的一個部分,但是對于一個單詞而言,上述的規律并不是總是對的。在大部分的語言中,一個詞組可以被分成幾個孤立的部分。
同樣的,組合的特性也不是特別的明顯。我們知道,單詞之間肯定有特定的組合規律,才能相互連接,就像形容詞用來修飾名詞一樣,但是這些規則究竟怎么運轉,更高層次的表達究竟意味著什么,都不是像在計算機視覺中那樣明顯,那樣直觀。
在這樣的情況下,CNN看上去并不是特別適合用于NLP問題的處理。然而,RNN就能夠給你更加直觀的感受啦。它們象征著我們如何組織語言(或者,最少也是我們腦海中怎么組織語言):從左到右依次讀。幸運的是, 這并不代表CNN沒用。所有的模型都有錯誤,但是并不代表著它們沒用用。恰好,實際應用證明了CNN對于解決NLP問題相當不錯。簡單的詞袋模型Bag of Words model是一個基于錯誤假設的過簡單化模型,但是還是被當做標準方法這么多年,并且取得了不錯的成績。
一個對于CNN的爭議就是在于他們的速度,他們快,非常快。卷積是計算機圖形的核心部分,并在GPU上的硬件級別上實現(你可以想象這有多快了吧)。相比于類似N-Grams之類的東西, CNN在單詞或者分類的表示方面效率極高。在處理大量的詞匯時,快速運算超出3-Grams的數據開銷巨大。甚至連Google都不可以計算超過5-Grams的數據。但是卷積過濾器可以自動學習到一種很好的表達方式,而不用多余地去表示所有的詞匯。因此,它完全可以擁有一個大小大于5的過濾器。我想啊,在第一層中設計這么多自動學習的過濾器,它們提取特征的行為很像(但不局限于)N-Grams的方式,但是卻用一個更加簡潔有效的方法表示它們。
CNN 的超參(HYPER-PARAMETERS)
在解釋CNN是如何作用于NLP問題之前,我們先看看在建立CNN的時候需要做哪些選擇。希望這會幫助你更好地理解這一領域的文獻。
寬、窄卷積神經網絡
當我在上文中解釋卷積的時候,我忽略了一點運用過濾器的小細節。我們在一個矩陣的中心有3×3的過濾器工作得很棒,但是它在邊界的表現如何呢?你應該如何應用這個過濾器于矩陣的第一個元素(沒有任何相鄰的上方元素和左邊元素)? 你可以用0來填充邊界。所有超過矩陣邊界的元素都當做0來處理。這么做之后呢,你就可以將過濾器用于矩陣中的每一個元素,并且獲得更大的等大小的輸出。使用0填充的(zero-padding)也稱為寬卷積(wide convolution),不用0填充稱為窄神經網絡。下面是一個例子。

步長(Stride size)
另一個卷積的超參是步長,也就是每一步你想移動你的過濾器多少距離。上述的所有的例子,步長均為1。對連續應用過濾器采樣子矩陣,就會導致采樣信息的重疊。一個更大的步長意味著更少地使用過濾器和更小的輸出。下面的例子來自于the Stanford cs231 website 展示了步長為1和步長為2運用于一維輸入的情況:

Convolution Stride Size.?
Left: Stride size 1. Right: Stride size 2. Source: ?
在文獻中我們通常看到的都是步長大小為1的情景,但是較大的步幅讓你建立一個處理過程類似RNN的模型,就像樹型結構。
池層(POOLING LAYERS)
卷積神經網絡的另一個關鍵在于Pooling layers,它通常在卷積層后面使用。Pooling layers用于下采樣上一層的輸入。最簡單也是最常見的做法是,取每個過濾器中的最大值為輸出。你不必對一個完整的矩陣都做pooling操作,你可以對一個小窗口做pooling。如下圖,展示一個在2×2窗口的max pooling操作(在NLP問題中,我們通常要對整個輸入進行pooling操作,產生每個過濾器產生一個單獨的數字輸出):

Max pooling in CNN. Source:
為什么要進行Pooling操作呢?有以下這么幾個原因。
Pooling操作的一個優勢在于它能夠產生一個固定大小的輸出矩陣。這個矩陣通常被用于分類。例如,如果你有1000個過濾器并且你對每一個過濾器都進行了Max Pooling操作,那么你就得到了1000維的輸出。不管你過濾器的大小,也不管你輸入的大小,你的輸出大小就是固定的。這樣你就可以用各種各樣長度的句子和各種各樣大小的過濾器,但是總會得到相同的輸出維度,從而進行分類。
Pooling的使用也可以減少輸出的維度,同時(我們希望這樣)保存最顯著的信息。你可以想象一下,每個過濾器能夠識別出一種特征,例如,識別出這個句子有沒有含有一個類似”not amazing”的否定詞。如果句子中的某個地方出現了這個詞組,那么掃描采樣這一塊的過濾器就會產生一個大的數值,在別的區域產生一個小的值。這樣做之后呢,你就能夠保持那些關于某些特征有沒有出現在句子中的信息,而損失了這個特征究竟出現在句子的哪個位置的信息。但是,損失的這個信息并沒有什么用途吧?對啊,這是有一點像a bag of n-grams model所做的那樣。你損失了關于定位的全局信息(某些東西出現在句子中的某些地方),但是你保留下來了被你的過濾器采樣到的局部信息,就像”not amazing”與”amazing not”非常不同一樣。(這就是我上文說的一個有疑問的說法)
在圖像識別中,Pooling也可以提供基礎的平移、旋轉不變性。當你對于某個區域進行Pooling操作的時候,結果通常來說會保持一致,無論你是旋轉還是平移你圖像的像素,因為Max Pooling會最終識別出同樣的數值。
通道(CHANNELS)
我們需要理解的最后一個理論是通道。通道是輸入數據的一種不同的‘樣子’。例如,在圖像識別中,我們一般使用的是RGB(red, green, blue) 通道。在通道里應用卷積的時候,你可以采用不同的或者相同的權值。在NLP問題中,你可以想到通道的種類是非常多的:用不同的word embeddings(word2vec and GloVe for example)來區分通道,或者,你可以為不同的語言表達的同樣意思的句子、單詞設計一個通道。
用于NLP的CNN
現在讓我們看看一些CNN在自然語言處理中的應用。我會嘗試總結一些研究成果與結論。總之,我會漏了描述很多有趣的應用(請在評論中告訴我),但我希望至少覆蓋一些比較流行的結果。
CNN天生就適合用于分類任務,例如情感分析,垃圾郵件檢測或主題分類。卷積和池操作會丟失單詞的局部順序,所以呢,句子標記,例如詞性標注或實體提取,是有點難以適應純CNN架構(也不是不可能,你可以添加位置特征的輸入)。
[1] 評估一個CNN結構在各種分類數據集中的表現,主要包括情感分析和主題分類的任務。 CNN結構跨數據集的問題上有著非常不錯的表現,同時最新的技術也使得它在小數據上表現優異。 出人意料的是,論文中使用的網絡是非常簡單的,這就是為什么它非常的有效。輸入層是一個由連續的word2vec word embeddings組成的句子。在卷積層的后面跟著多個過濾器,然后是一個max-pooling layer,最后是一個softmax分類器。該論文也對兩個不同的通道做實驗,通道是以靜態和動態word embeddings形式的,并且其中一個能夠在訓練中被調整,一個不能被調整。一個相似的但是更加復雜的結構在[2]中被提出。[6] 加入了一個新增的層用于在網絡結構中進行“語義聚合”(semantic clustering) 。

[4]從頭訓練一個CNN,不需要pre-trained word向量,例如word2vec或者GloVe。它直接將卷積用于one-hot向量。作者還提出了一種空間節約的bag-of-words似的輸入數據表示方法 ,減少了網絡需要訓練的參數個數。在[5]中,作者用一個二外的無監督“region embedding”擴展了這個模型,該擴展是學習用CNN來預測文本區域的內容。這些論文中使用的方法似乎在長文本(例如,電影評論)的處理中做得不錯,但是他們在短文本(例如,微博)中的處理效果還不得而知。直觀地來看,這確實很有道理。對短文本使用pre-trained word embeddings將會產生更大的收益,相比將它們用于處理長文本。
建立一個CNN解耦狗意味著許多超參可供選擇,就像我上文提到的那樣:輸入表示法(word2vec, GloVe, one-hot),卷積過濾器的數量和大小,池操作的策略(max, average),以及激活函數(ReLU, tanh)。[7]通過調整CNN結構的超參,多次運行程序,研究、分析其的性能和方差,從而得出驗證性的評價。如果你想要將你的CNN用于文本分類,用這篇論文的結論作為基礎起始點是再好不過的了。一些脫穎而出的結論是,max-pooling的效果總是好于average_pooling;一個理想狀況下的過濾器大小是很重要的,但是大部分還是依具體情況而定;正則化與否在NLP問題中似乎沒有多大影響。這項研究的需要注意的是,在文件長度方面,所有的數據集都頗為相似。所以呢,同樣的準則看清了并不適用于那些看起來相當不同的數據。
[8]研究了CNN對關系抽取和關系分類的應用。除了單詞向量,作者用了單詞與關注的實體(譯者:attention mechanism里的概念)之間的相對位置作為卷積層的另一個輸入。這個模型假定實體的位置已經被給定,并且各實例的輸入包含一個上述的關系。[9]和[10]也研究的是同樣的模型。
在微軟的[11]和[12]研究中,能夠發現一個CNN在NLP中有趣的應用。這些論文描述的是如果得知那些可以被用于信息檢索的句子的語義上有意義的表示方法。論文中的例子包括,根據讀者現在閱讀的文章,推薦出讀者可能感興趣的文章。句子的表示方法是用基于搜索引擎的日志數據來進行訓練的。
大多數的CNN結構以用這種或者那種方式從embeddings (低維表示法) 中學習作為它們訓練過程的一部分。并非所有的論文都關注于如果訓練或者研究分析learned embeddings意義何在。[13]展示了一個CNN結構。這個結構用于預測Facebook的位置標簽,同時,產生有意義的單詞和句子的embeddings。這些learned embeddings隨后被成功地用于其他的問題: 以點擊流數據作為訓練集,將用戶可能產生潛在興趣的文章推薦給用戶。
字符級CNN(CHARACTER-LEVEL CNNS)
這個專業名詞翻譯是我自己猜的,也可能是漢字、個性之類的。
目前為止,所有模型的表示方法都是基于單詞的。但是也有將CNN應用于字符的研究。 [14] 研究了character-level embeddings,將它們和pre-trained word embeddings結合在一起,并且將CNN用于詞性標注 (Part of Speech tagging). [15][16] 研究了直接用CNN從字符中進行訓練,不需要接住任何的pre-trained embeddings。值得注意的是,作者用了一個共9層的深度神經網絡,并將其用于情感分析和文本分類的作用。結果表明,在大數據的情況下,直接從字符級輸入的學習效果非常好(百萬級的例子),但是在較小的數據集上面表現得比較差(百條、千條例子)。 [17] 研究了字符級CNN在語言模型(Language Modeling)上面的應用,用字符級CNN的輸出作為LSTM(長期短期記憶單元)的輸入。同樣的模型可以用于多個語言。
最讓人驚奇的是上面所說的所以論文都是在最近的1-2年內發表的。非常明顯的,CNN在NLP問題上面很早就取得了很好的成績,。雖然自然語言處理(幾乎)是剛剛開始起步,但是新成果和新技術的發展步伐正在顯著加快。
[1]?Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.?
[2]?Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. Acl, 655–665.?
[3]?Santos, C. N. dos, & Gatti, M. (2014). Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In COLING-2014 (pp. 69–78).?
[4]?Johnson, R., & Zhang, T. (2015). Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. To Appear: NAACL-2015, (2011).?
[5]?Johnson, R., & Zhang, T. (2015). Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding.?
[6]?Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., Wang, F., & Hao, H. (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357.?
[7]?Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,?
[8]?Nguyen, T. H., & Grishman, R. (2015). Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP, 39–48.?
[9]?Sun, Y., Lin, L., Tang, D., Yang, N., Ji, Z., & Wang, X. (2015). Modeling Mention , Context and Entity with Neural Networks for Entity Disambiguation, (Ijcai), 1333–1339.?
[10]?Zeng, D., Liu, K., Lai, S., Zhou, G., & Zhao, J. (2014). Relation Classification via Convolutional Deep Neural Network. Coling, (2011), 2335–2344.?
[11]?Gao, J., Pantel, P., Gamon, M., He, X., & Deng, L. (2014). Modeling Interestingness with Deep Neural Networks.?
[12]?Shen, Y., He, X., Gao, J., Deng, L., & Mesnil, G. (2014). A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management – CIKM ’14, 101–110.?
[13]?Weston, J., & Adams, K. (2014). # T AG S PACE : Semantic Embeddings from Hashtags, 1822–1827.?
[14]?Santos, C., & Zadrozny, B. (2014). Learning Character-level Representations for Part-of-Speech Tagging. Proceedings of the 31st International Conference on Machine Learning, ICML-14(2011), 1818–1826.?
[15]?Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9.?
[16]?Zhang, X., & LeCun, Y. (2015). Text Understanding from Scratch. arXiv E-Prints, 3, 011102.?
[17]?Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2015). Character-Aware Neural Language Models.












 工商網監
工商網監
評論