 電子發燒友App
電子發燒友App


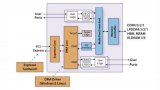
您的開發團隊是否需要在極短的時間內打造出既復雜又富有競爭力的新一代系統?賽靈思All Programmable器件可助您一臂之力,它相對傳統可編程邏輯和I/O,新增了軟件可編程ARM處理系統、可編程模擬混合信號(AMS)子系統和不斷豐富的高復雜度的IP,支持開發團隊突破原有的種種設計限制。賽靈思有多種All Programmable器件可供用戶選擇,構成這些器件的各種硅片組合使用賽靈思獨特的高性能3D堆疊硅片互聯技術彼此互聯。這些領先一代的All Programmable器件為用戶提供的功能,遠超常規可編程邏輯所能及,為用戶開啟了一個全面可編程系統集成的新時代。
All Programmable抽象化與自動化有何意義?
其意義在于采用賽靈思All Programmable器件,用戶的開發團隊可以用更少的部件實現更多系統功能,提升系統性能,降低系統功耗,減少材料清單(BOM)成本,同時滿足嚴格的產品上市時間要求。但如果不借助強大的硬件、軟件、系統設計工具和設計流程,則無法將這些優勢交到您的設計團隊的手中,您也不可能實現這些優勢。賽靈思把所需的這些硬件、軟件和系統設計開發流程統稱為“All Programmable抽象化(All Programmable Abstraction)”。
在這種使用All Programmable抽象化進行先進的領先一代的硬件、軟件和系統開發過程中,起著核心作用的是賽靈思Vivado設計套件。Vivado設計套件是一種以IP和系統為中心的、領先一代的全新SoC增強型綜合開發環境,可解決用戶在系統級集成和實現過程中常見的生產力瓶頸問題。
就在同類競爭解決方案還在試圖通過擴展過時且松散連接的分立工具來跟上片上集成的高速發展的時候,Vivado設計套件憑借業界最先進的SoC增強型設計方法和算法,提供了獨特、高度集成的開發環境,為設計者帶來了設計生產力的極大提升。Vivado設計套件將硬件、軟件和系統工程師的生產力提升到了一個全新的水平。
以下九大理由,將讓您了解到Vivado設計套件為何能夠提供領先一代的設計生產力、簡便易用性,以及強大的系統級集成能力。
加快系統實現
理由一:突破器件密度極限:在單個器件中更快速集成更多功能
如果設計工具能夠讓All Programmable器件集成更多功能,用戶就能夠在系統設計中選擇盡可能小的器件,從而直接帶來系統成本和功耗的下降。Vivado設計套件提供一種集成環境,能夠讓架構、軟件和硬件開發人員在通用設計環境中協作工作,從而最大程度地提升設計效率,充分發揮All Programmable器件的可編程邏輯架構及其專用片上功能模塊的潛力。
以OpenCores.org的以太網MAC(媒體訪問控制器)模塊設計為例。作為實驗,賽靈思反復原樣復制OpenCores以太網MAC,直至它們填充帶有693,120個邏輯單元的Virtex-7 690T FPGA。賽靈思又以類似的方法填充帶有622,000個邏輯單元的同類競爭器件。下圖顯示的是實驗結果。
按邏輯單元數量來衡量(一個“標準”的邏輯單元由一個4輸入LUT(查找表)和一個觸發器組成),賽靈思Virtex-7 690T器件的原始容量比同類競爭器件(帶有622,000個邏輯單元)高出11%。但如圖1所示,如果用Vivado設計套件將所有這些以太網MAC模塊實例填充到賽靈思Virtex-7 690T器件中,賽靈思Virtex-7 690T器件要比同類競爭器件容納的實例數多出36%。這個實驗表明,Vivado設計套件與賽靈思7系列FPGA架構結合使用所產生的效率,要遠高于同類競爭工具/器件組合所產生的效率。

(注:圖1根據LUT和Slice計數結果,對賽靈思7系列All Programmable器件和同類競爭可編程邏輯器件進行比較。賽靈思7系列All Programmable器件slice含四個6輸入LUT、八個觸發器以及相關的多路復用器和算術進位邏輯,相當于1.6個邏輯單元。)
Vivado設計套件如何最大化器件利用率
Vivado設計套件之所以能夠實現更高的器件利用率,是因為它采用高級擬合算法,而且賽靈思7系列可編程邏輯架構在每個Slice內采用真正獨立的LUT。值得注意的是,圖1詳盡地體現了賽靈思7系列的LUT和Slice擬合結果,兩者均實現了近100%的利用率。而同類競爭的可編程邏輯器件在器件利用率僅達到63%就用盡了可用的Slice。產生這種低利用率的根源歸咎于該競爭器件的可編程邏輯架構,這種架構在許多情況下不允許把兩個LUT捆綁成一個物理集群。在完整的設計中,這顯然會產生大量未充分利用的集群。這是由于為了滿足架構的引腳共享要求,只有一個LUT得到使用,而另一個LUT則不能再用于設計中其余的邏輯。這項實驗清楚地表明,用戶可以使用更小的7系列All Programmable來實現更大的系統設計。
在這個IP模塊擬合實驗中,Vivado設計套件與同類可編程器件形成了鮮明的對:Vivado設計套件實現了99%的LUT利用率,而且即便在如此高利用率水平下,它還能在完成設計布局布線的同時,滿足時序約束。Vivado布局布線算法旨在處理高密度、高難度設計,便于用戶將更多邏輯置于該器件中,從而降低用戶的系統材料清單(BOM)成本和系統功耗。
理由二:Vivado以可預測的結果提供穩健可靠的性能和低功耗
出于納米級IC設計的物理原因,互聯已經成為28nm及更高工藝節點的可編程邏輯器件架構的性能瓶頸。Vivado設計套件采用先進的布局布線算法,可突破該性能瓶頸,而且點擊鼠標即可得到高性能結果。
Vivado設計套件的分析型布局布線算法能夠同步優化包括時序、互聯使用和走線長度在內的多重變量,提供可預測的設計收斂。同時,Vivado的實現引擎可保證在邏輯利用率高的大型器件上得到的結果和在器件利用率較低的設計上得到的結果一樣優異。此外,在系統設計規模隨著系統功能的增加而逐步增大的情況下,Vivado既能保持高性能結果,還能提高各次運行結果間的一致性。
如圖2所示,與同類競爭工具相比,Vivado設計套件可隨著利用率的提升提供更出色的性能,同時還能處理更大規模的設計。

注:如圖2所示,同類競爭工具的結果的平均變動要比使用Vivado設計套件得到的結果大四倍。另外,值得注意的是同類競爭解決方案在填滿器件時,可用性能下降了一半。與此形成鮮明對比的是,Vivado設計套件在受測的不同設計上得到的結果一致,性能保持穩定。最后還需要注意是同類競爭解決方案不能處理Vivado設計套件能夠成功處理的大型系統。同類競爭解決方案很快就不堪重負。
Vivado降低系統功耗
Vivado設計套件提供了業界一流的系統功耗分析與優化工具。從架構或器件選擇階段開始,設計人員就可以運用準確且易用性無與倫比的Xilinx Power Estimator(XPE,賽靈思功耗評估器)電子數據表來確定系統功耗。設計人員不僅能夠通過XPE的快速 評估(Quick Estimate)和IP向導輕松入門,而且還能夠簡單并排比較多種實現方案,幫助設計團隊微調設置,以便地為各種場景精確建模。
當設計進入編譯階段,Vivado設計套件繼續提供準確的功耗分析和估算。Vivado設計套件開箱即用,能夠在不給系統設計的時序造成負面影響的情況下自動降低設計的功耗。如果用戶還需要進一步降低功耗,可以使用Vivado設計套件獨有功能,充分利用賽靈思7系列精細粒度時鐘門控技術,進一步降低整個系統設計或部分設計的功耗。
這種Vivado設計套件實現的智能時鐘門控優化技術能夠平均降低動態功耗18%,如圖3所示。

Vivado設計套件提供了一系列無與倫比功能與特性,可幫助用戶輕松完成對設計的分析工作。用戶可以甄別出功耗最大的模塊,從而明確從哪些模塊切入,高效而明顯降低系統功耗。所有這些功能都內置在通用Vivado集成設計環境(IDE)中,所以設計團隊僅借助一款統一的工具套件,就可一次性最小化系統功耗。
系統功耗是設計大多數產品時應考慮的一個重要因素,Vivado設計套件提供的領先一代設計工具是對賽靈思All Programmable器件的有力補充和完善。
理由三:Vivado設計套件提供了無與倫比的運行時間和存儲器利用率
從設計人員生產力考慮,設計工具應能夠快速運行,最好是快到每天能夠完成多次編譯,這樣設計團隊就能夠迅速得到最終設計。從一開始Vivado設計套件就是為高速運行設計的,比同類競爭的可編程邏輯設計工具的速度明顯要快得多。
同樣以之前討論過的OpenCores以太網MAC模塊設計為例。圖4說明,隨著實例數量的增加,Vivado設計套件的運行時間比競爭對手的軟件快三倍。此外,數據還表明,Vivado的運行時間的增減可以預測,即運行時間只單調地隨設計規模增減。與此形成鮮明對比的是,同類競爭軟件的運行時間無規律性。例如94個實例的設計完成的速度比使用84個實例的設計快。

Vivado內存占用更小
Vivado設計套件采用先進高效的數據模型和結構,內存占用極小且明顯低于同類競爭解決方案的內存占用。此處仍以OpenCores以太網MAC模塊為例。要成功運行規模最大的設計(154個實例),競爭軟件需要占用16GB的RAM,相比之下運行同樣規模大小的設計,Vivado設計套件占用的內存要小三分之二(見圖5)。內存占用減少意味著Vivado設計套件擁有明顯的生產力優勢,因為設計人員在編譯較大型系統設計時不會耗盡內存。

加快系統集成
理由四:使用Vivado高層次綜合生成基于C語言的IP
如今的無線、醫療、軍用和消費類應用均比以往更加尖端,使用的算法也比以往更加復雜。業界算法開發的金標準就是采用C、C++和SystemC高級編程語言。過去設計流程中需要經過一個緩慢且容易出錯的步驟來將用C、C++或SystemC語言編寫的算法轉換為適合于綜合的Verilog或VHDL硬件描述。而現在Vivado設計套件系統版本中提供的Vivado高層次綜合功能可輕松地自動完成這一步驟。
您以往可能聽說過C語言級硬件綜合。不管您聽說過什么,C語言級算法綜合已成為系統級設計的捷徑。當前有超過400名用戶正在成功利用Vivado高層次綜合(HLS)技術開發符合C、C++和SystemC語言規范的賽靈思All Programmable器件用IP硬核。
Vivado HLS通過下列功能,讓系統和設計架構師走上IP硬核開發的捷徑:
● 算法描述、數據類型規格(整數、定點或浮點)和接口(FIFO、AXI4、AXI4-Lite、AXI4-Stream)抽象化;
● 采用可提供最佳QoR(結果質量)的基于指令的架構感知型編譯器;
● 使用C/C++測試平臺仿真、自動化VHDL/Verilog仿真和測試臺生成功能加快模塊級驗證;
● 發揮整套Vivado設計套件的功能,將生成的IP硬核輕松嵌入基于RTL的設計流程中;發揮Vivado System Generator for DSP的功能,將生成的IP硬核輕松嵌入基于模型的設計;發揮Vivado IP集成器(Vivado IP Integrator)的功能,將生成的IP硬核輕松集成到基于模塊的設計。
這樣硬件設計人員就有更多時間投入到設計領域的探索中,即有更多時間評估備選架構,找出真正理想的設計解決方案,輕松應對各種嚴峻的系統設計挑戰。例如設計人員將行業標準的浮點math.h運算與Vivado HLS結合使用,就能夠在實現較手動編碼的RTL更優異的QoR的同時,讓線性代數算法的執行速度呈數量級提高(10倍),如表1所示。

通過集成到OpenCV環境中的預先編寫、預先驗證的視覺與視頻功能,Vivado HLS還能加速基于賽靈思Zynq-7000 All Programmable SoC器件的系統的實時Smarter Vision算法的開發工作。此類系統使用運行在Zynq SoC的雙核ARM處理系統上的軟件和位于Zynq SoC高性能FPGA架構上的硬件來運行這些算法(如圖6所示)。

使用Vivado HLS Smarter Vision庫的各項功能,用戶借助硬件加速就能迅速實現復雜像素處理接口和基本視頻分析功能的實時運行。
(如欲立即開始使用Vivado HLS,敬請下載《如何使用Vivado高層次綜合的FPGA設計》。這是一本以賽靈思對其主要客戶舉辦的培訓為依據的綜合性用戶指南。該指南可快速向軟件工程師教授如何將軟件算法
理由五:利用System Generator for DSP實現基于模塊的DSP設計集成
如上文所述,Vivado設計套件系統版本提供System Generator for DSP,這是一款行業領先的將DSP算法轉換為高性能生產質量級硬件的高級設計工具,轉換所需時間僅為傳統RTL設計方法的幾分之一。Vivado System Generator for DSP可讓開發人員運用業界最先進的All Programmable系統建模工具(MathWorks提供的Simulink和MATLAB),無縫集成那些可用Vivado HLS綜合到硬件中的算術函數、SmartCORE與LogiCORE IP、定制RTL以及基于C語言的模塊,從而加速高度并行系統的開發。圖7所示的是使用Vivado HLS和Vivado System Generator for DSP將基于C語言的模塊集成到Simulink中的設計流程。

Vivado System Generator for DSP提供自動定點/浮點硬件生成功能、可將Simulink仿真速度提高1000倍的硬件協同仿真功能、用于基于RTL的Vivdo設計流程的系統集成功能,以及用Vivado IP集成器實現的基于模塊的設計功能,可進一步加快系統實現。
理由六:利用Vivado IP集成器實現基于模塊的IP集成
Vivado設計套件提供行業首款即插即用IP集成設計環境Vivado IP集成器 (Vivado IPI),打破了RTL設計生產力的局限性。
Vivado IP集成器提供圖形化、腳本編寫(Tcl)、生成即保證正確(correct-by-construction)的設計開發流程。此外,它還提供具有器件和平臺意識的環境,以及強大的集成調試功能,能支持主要IP接口的智能自動連接、一鍵式IP子系統生成、實時設計規則檢查(DRC)和接口修改傳遞等。
設計人員在使用Vivado IP集成器建立IP模塊之間的連接時,工作在抽象的“接口”層面而非“信號”層面。抽象上升到接口層面大大提高了設計人員的生產力。雖然主要使用的是業界標準的AXI4接口,IP集成器也支持數十種其他常用接口。
工作在接口層面的設計團隊可以快速組裝采用Vivado HLS與Vivado System Generator for DSP創建的IP、賽靈思SmarteCORE與LogiCORE IP、聯盟成員IP和專有IP的復雜系統。結合使用Vivado IP集成器和Vivado HLS可顯著降低開發成本,僅為使用RTL方法的1/15。
圖8顯示的是系統級設計在Vivado IP集成器中的視圖,這個系統采用了一個賽靈思Zynq-7000處理系統、Vivado HLS生成的圖像濾波器加速器和一個用Vivado System Generator for DSP生成的增益控制加速器。

加速系統驗證
理由七:用于設計和仿真的Vivado集成設計環境
Vivado設計套件還提供完整的全集成成套工具,用于在先進的集成設計環境(IDE)中完成設計輸入、時序分析、硬件調試和仿真工作。Vivado設計套件的集成設計環境的這種設計分析功能采用共享的可擴展數據模型,以容納超大型All Programmable器件。Vivado設計套件在整個設計流程中使用這一單一的數據模型,讓設計團隊能夠盡早在整個設計流程中隨時掌握時序、功耗、資源利用率、路由擁塞等關鍵設計指標。估算也會隨著設計流程的推進越來越準確,從而在減少設計迭代次數的同時推動更快完成設計收斂。

Vivado設計套件是唯一在自身的集成設計環境中提供混合語言仿真器的設計解決方案。而同類競爭仿真器的用戶必須或選擇VHDL仿真,或選擇Verilog仿真。對集成眾多廠商提供的IP的最新系統設計來說,混合語言仿真器至關重要。
Vivado設計套件的仿真和調試使用相同的波形觀測儀,這樣可以避免從仿真環境切換到硬件調試環境后還需要重新學習。競爭解決方案往往迫使用戶學習和使用不同波形的工具來完成相同工作。在仿真功能和調試功能全集成的情況下,設計團隊能夠更快地完成工作,且避免出錯,使用Vivado設計套件就是這種情況。
類似地,同類競爭開發工具的交叉探測功能呈碎片化且極度有限。此外這些交叉探測功能一般局限于某種單一的工具。與此對比鮮明的是,Vivado設計套件提供的全面、集成式front-to-back交叉探測功能,適用于所有不同設計視圖,諸如實現設計、綜合設計、時序報告,甚至還可追溯到設計團隊的原始RTL代碼。
由于Vivado設計套件使用單一數據模型架構,所以可在各種設計資源、原理圖視圖、層級瀏覽器、設計報告、消息、布局規劃和Vivado器件編輯器(Vivado Device Editor)之間進行大范圍交叉探測。借助這種獨特的功能,可以即時反饋整個系統開發過程中發現的任何設計問題,從而加快調試,快速完成時序收斂。
此外,競爭性設計解決方案使用多個磁盤文件用于工具間通信。使用多個磁盤文件帶來的復雜性和低效率不僅會降低工具性能,而且還會造成多重接口,從而顯著增大工具間溝通不暢的幾率。然而,Vivado設計套件則不存在這種問題。它采用單一的共享數據模型處理設計的各方面工作,如圖10所示。

理由八:綜合而全面的硬件調試
Vivado設計套件的探測方法直觀、靈活、可重復。設計人員可選擇最適合自己設計流程的探測策略:
● RTL設計文件、綜合設計和XDC約束文件
● 網表插入
● 用于自動運行探測的互動式TCL或腳本
先進的觸發器和采集功能
Vivado設計套件為檢測復雜事件提供先進的觸發器和采集功能。在調試進程中所有的觸發器參數均可使用,用戶可以實時檢查或動態修改參數,且無需重新編譯設計。
Zynq SoC支持處理器系統(PS)與可編程邏輯(PL)之間交叉觸發
Vivado設計套件還支持Zynq-7000 All Programmable SoC器件內處理器系統(PS)與可編程邏輯(PL)之間的交叉觸發。有了這項功能,結合使用賽靈思軟件開發套件(SDK)、Vivado IP集成器和Vivado邏輯分析器(Vivado Logic Analyzer),可以協同調試同時使用Zynq處理器系統和可編程邏輯的嵌入式設計。再搭配強大的軟件調試器GNU Debugger(GDB)實用工具,設計人員使用Vivado IP集成器和Vivado邏輯分析器可以同步調試軟/硬件算法。Zynq-7000 All Programmable SoC平臺和賽靈思ILA(集成邏輯分析器)IP核間提供有特定的接口信號,可支持無縫協同調試操作。
實現硬件實時讀/寫操作 — JTAG to AXI Master
Vivado設計套件可在硬件調試過程中實時地完成Zynq處理器系統和可編程邏輯間的讀/寫事務處理。最新調試IP核(JTAG to AXI Master)與簡便易用的IP Integrator流相結合,能夠在設計中訪問任何基于AXI的IP模塊中的數據。
優勢包括:
● 在設計過程中,能夠在外設上完成簡單的讀/寫操作
● 無需重新編譯就能將測試模式寫入存儲器
● 通過AXI接口能夠測試和校正IP核
● 能夠檢查任何AIX外設設備內的數據
集成串行I/O分析器
Vivado串行I/O分析器為基于FPGA的系統設計中日漸常用的高速串行I/O通道提供了一種快速、便捷的互動式設置調試方法。Vivado串行I/O分析器能夠在串行I/O通道運行期間對多種高速串行I/O通道進行誤碼率(BER)測試,并實時調整高速串行收發器的參數。這款基于鏈路的Vivado串行I/O分析器,能夠將系統中任何收發器的發射器(TX)連接到任何收發器的接收器(TX)。此外發射器和接收器無需采用相同的SerDes架構。Vivado串行I/O分析器還能夠自動檢測各條鏈路,讓開發人員創建定制鏈路,執行2D眼圖掃描并實時掃描收發器參數(如圖11所示)。

理由九:采用C、C++和SystemC語言將驗證速度提高100倍以上
如前文所討論的,Vivado設計套件系統版本內置Vivado HLS,可幫助用戶的設計團隊用C、C++和SystemC語言迅速完成算法設計的創建與迭代工作,同時還在驗證工作中發揮這些高級編程語言的高仿真速度優勢。使用Vivado HLS定點和業界標準浮點math.h庫,開發人員運用C函數規范即可快速為設計建模并完成設計迭代,然后僅根據時鐘周期和吞吐量等考慮因素建立目標感知的RTL架構。將C、C++和SystemC語言用作初始設計和建模語言可極大地加快仿真速度(比RTL仿真速度快數千倍)。在一個視頻設計實例中,10個經處理的視頻幀的仿真速度采用C語言比采用HDL快12,000倍,如表2所示。

總結
賽靈思Vivado設計套件是一種以IP和系統為中心的、領先一代的全新SoC增強型開發環境,用于解決系統級集成和實現工作中的生產力瓶頸問題。這套設計工具專為系統設計團隊開發,旨在幫助他們在更少的器件中集成更多系統功能,同時提升系統性能,降低系統功耗,減少材料清單(BOM)成本。
Vivado設計套件由于如下九大理由,是幫助您實現上述這些目標的理想系統設計工具:
● Vivado設計套件可讓用戶進一步提升器件密度。
● Vivado設計套件可提供穩健可靠的性能,降低功耗以及可預測的結果。
● Vivado設計套件可提供無與倫比的運行時間和存儲器利用率。
● Vivado HLS能夠讓用戶用C、C++或SystemC語言編寫的描述快速生成IP核。
● Vivado設計套件借助MathWorks公司提供的Simulink和MATLAB工具可支持基于模型的DSP設計集成。
● Vivado IP集成器突破RTL的設計生產力制約。
● Vivado集成設計環境為設計和仿真提供統一集成開發環境。
● Vivado設計套件提供綜合而全面的硬件調試功能。
● Vivado HLS使用C、C++或CSystem語言可將驗證速度提高100倍以上。
您的設計團隊不妨立即試試Vivado設計套件,體驗一下其帶來的強大優勢?

















 工商網監
工商網監
評論