 電子發(fā)燒友App
電子發(fā)燒友App


什么是FPGA
FPGA(Field-Programmable Gate Array),即現(xiàn)場可編程門陣列,它是在PAL、GAL、CPLD等可編程器件的基礎(chǔ)上進一步發(fā)展的產(chǎn)物。它是作為專用集成電路(ASIC)領(lǐng)域中的一種半定制電路而出現(xiàn)的,既解決了定制電路的不足,又克服了原有可編程器件門電路數(shù)有限的缺點。
FPGA和CPLD的主要區(qū)別
早在1980年代中期,F(xiàn)PGA已經(jīng)在PLD設(shè)備中扎根。CPLD和FPGA包括了一些相對大數(shù)量的可編輯邏輯單元。CPLD邏輯門的密度在幾千到幾萬個邏輯單元之間,而FPGA通常是在幾萬到幾百萬。
CPLD和FPGA的主要區(qū)別是他們的系統(tǒng)結(jié)構(gòu)。CPLD是一個有點限制性的結(jié)構(gòu)。這個結(jié)構(gòu)由一個或者多個可編輯的結(jié)果之和的邏輯組列和一些相對少量的鎖定的寄存器組成。這樣的結(jié)果是缺乏編輯靈活性,但是卻有可以預(yù)計的延遲時間和邏輯單元對連接單元高比率的優(yōu)點。而FPGA卻是有很多的連接單元,這樣雖然讓它可以更加靈活的編輯,但是結(jié)構(gòu)卻復(fù)雜的多。
CPLD和FPGA另外一個區(qū)別是大多數(shù)的FPGA含有高層次的內(nèi)置模塊(比如加法器和乘法器)和內(nèi)置的記憶體。因此一個有關(guān)的重要區(qū)別是很多新的FPGA支持完全的或者部分的系統(tǒng)內(nèi)重新配置。允許他們的設(shè)計隨著系統(tǒng)升級或者動態(tài)重新配置而改變。一些FPGA可以讓設(shè)備的一部分重新編輯而其他部分繼續(xù)正常運行。
CPLD和FPGA還有一個區(qū)別:CPLD下電之后,原有燒入的邏輯結(jié)構(gòu)不會消失;而FPGA下電之后,再次上電時,需要重新加載FLASH里面的邏輯代碼,需要一定的加載時間。
FPGA工作原理
FPGA采用了邏輯單元陣列LCA(Logic Cell Array)這樣一個概念,內(nèi)部包括可配置邏輯模塊CLB(Configurable Logic Block)、輸出輸入模塊IOB(Input Output Block)和內(nèi)部連線(Interconnect)三個部分。
與傳統(tǒng)邏輯電路和門陣列(如PAL,GAL及CPLD器件)相比,F(xiàn)PGA具有不同的結(jié)構(gòu),F(xiàn)PGA利用小型查找表(16×1RAM)來實現(xiàn)組合邏輯,每個查找表連接到一個D觸發(fā)器的輸入端,觸發(fā)器再來驅(qū)動其他邏輯電路或驅(qū)動I/O,由此構(gòu)成了既可實現(xiàn)組合邏輯功能又可實現(xiàn)時序邏輯功能的基本邏輯單元模塊,這些模塊間利用金屬連線互相連接或連接到I/O模塊。
FPGA的邏輯是通過向內(nèi)部靜態(tài)存儲單元加載編程數(shù)據(jù)來實現(xiàn)的,存儲在存儲器單元中的值決定了邏輯單元的邏輯功能以及各模塊之間或模塊與I/O間的聯(lián)接方式,并最終決定了FPGA所能實現(xiàn)的功能,F(xiàn)PGA允許無限次的編程。
FPGA在下一代網(wǎng)絡(luò)架構(gòu)中的重要意義
這里將著重討論FPGA在諸如NFV等虛擬網(wǎng)絡(luò)架構(gòu)中的作用和意義。
電信網(wǎng)絡(luò)是NFV的一個主要應(yīng)用場景,它出現(xiàn)的最直接的動因之一就是為了支持指數(shù)級的帶寬增長。據(jù)預(yù)測,五年后全球的IP流量將較今日增長超過3倍。在萬物互聯(lián)的今天,尤其是5G、物聯(lián)網(wǎng)、自動駕駛等技術(shù)已經(jīng)成為各大公司爭奪的焦點之時,各種設(shè)備和服務(wù)都需要電信網(wǎng)絡(luò)及其數(shù)據(jù)中心進行處理和支持。然而,傳統(tǒng)的電信基礎(chǔ)架構(gòu)和數(shù)據(jù)中心很難進行有效的擴展,其主要原因有以下兩點:
硬件層面:傳統(tǒng)電信網(wǎng)絡(luò)基礎(chǔ)架構(gòu)使用的是各類專用硬件設(shè)備,如各類接入設(shè)備、各層交換機、路由器、防火墻、QoS等。這樣做的問題有很多,例如,不同設(shè)備之間的兼容性差、維護升級困難、容易造成供應(yīng)商壟斷從而大幅提高成本、若需要加入新功能則要開發(fā)新硬件設(shè)備等等。
軟件層面:不同設(shè)備都需要各自對應(yīng)的軟件進行配置和控制,從而難以在管理員層面進行大范圍統(tǒng)一部署和配置,且需要學(xué)習(xí)來自不同供應(yīng)商和規(guī)格的設(shè)備的軟件配置方法。若某些網(wǎng)絡(luò)功能通過軟件實現(xiàn),傳統(tǒng)的實現(xiàn)方法中對服務(wù)器的有效利用率很低,且無法進行服務(wù)的動態(tài)遷移,等等。
因此,虛擬化技術(shù) - 更具體而言,網(wǎng)絡(luò)功能虛擬化NFV技術(shù),逐漸成為各大運營商解決上述問題的有效途徑。歐洲電信標準協(xié)會(ETSI)關(guān)于NFV比較有名的示意圖如下所示。
總體而言,和傳統(tǒng)方法相比,NFV利用通用的服務(wù)器(大多是基于英特爾x86處理器)、通用的存儲設(shè)備、以及通用的高速以太網(wǎng)交換機,實現(xiàn)傳統(tǒng)電信網(wǎng)絡(luò)基礎(chǔ)架構(gòu)的各種網(wǎng)絡(luò)功能。具體而言,就是將網(wǎng)絡(luò)功能在通用服務(wù)器中用軟件實現(xiàn),數(shù)據(jù)使用通用的存儲設(shè)備存儲,網(wǎng)絡(luò)流量通過通用的網(wǎng)卡和高速交換機進行轉(zhuǎn)發(fā)。這樣理論上能很好的解決上述硬件層面的問題:使用通用設(shè)備而非專用設(shè)備,提高了數(shù)據(jù)中心的可擴展能力,不會被某個供應(yīng)商制約,反而會通過開放競爭減少硬件采購和部署的成本。
另外,借助虛擬化技術(shù),將網(wǎng)絡(luò)功能在不同虛擬機中實現(xiàn),這樣理論上能解決軟件層面的問題:即某個特定應(yīng)用不會占用服務(wù)器的全部資源,反之,一個服務(wù)器可以同時運行多個虛擬機或網(wǎng)絡(luò)服務(wù)。同時,虛擬機在數(shù)據(jù)中心的擴展和遷移也更加方便,不會造成服務(wù)下線或中斷。
NFV和另外一項技術(shù):軟件定義網(wǎng)絡(luò)(Software Defined Network - SDN)經(jīng)常一起出現(xiàn)。它們的一個主要的核心思想就是將網(wǎng)絡(luò)的控制面和轉(zhuǎn)發(fā)面進行分離。這樣,所有的數(shù)據(jù)轉(zhuǎn)發(fā)面設(shè)備都可以同時被控制、配置、管理,從而避免了管理員需要分別配置每個網(wǎng)絡(luò)設(shè)備的低效情形。
引用一下《中國電信CTNet2025網(wǎng)絡(luò)架構(gòu)白皮書》的話:
“從更好的適應(yīng)互聯(lián)網(wǎng)應(yīng)用的角度出發(fā),未來網(wǎng)絡(luò)架構(gòu)必須要求網(wǎng)絡(luò)能力接口的開放和標準化,通過軟件定義網(wǎng)絡(luò)技術(shù),能夠?qū)崿F(xiàn)面向業(yè)務(wù)提供網(wǎng)絡(luò)資源和能力的調(diào)度和定制化,同時為進一步加速網(wǎng)絡(luò)能力的平臺化,還需要提供網(wǎng)絡(luò)可編程的能力,真正實現(xiàn)網(wǎng)絡(luò)業(yè)務(wù)的深度開放。”
請注意,在之前的表述中我使用了很多“理論上”怎樣怎樣,這是由于上面關(guān)于NFV的優(yōu)點很多都是人們美好的想象和愿景。在實際的工程實踐中,設(shè)計實現(xiàn)有效的NFV架構(gòu)面臨著很多問題。例如,不同的應(yīng)用場景中,網(wǎng)絡(luò)負載的種類五花八門,而很多應(yīng)用都需要進行線速的處理,如QoS和流量整形(之前的博文介紹過)、VPN、防火墻、網(wǎng)絡(luò)地址轉(zhuǎn)換、加密解密、實時監(jiān)控、深度包檢測(DPI)等等。即使有DPDK等專用的軟件開發(fā)庫,目前單純使用軟件實現(xiàn)這些網(wǎng)絡(luò)服務(wù)的線速處理,在技術(shù)上存在很大困難,且用軟件實現(xiàn)的網(wǎng)絡(luò)功能在性能上很難和專有硬件相比。這樣一來,人們會反過來質(zhì)疑使用NFV的出發(fā)點和動機。同時,鑒于NFV仍處于方案探討和摸索階段,很多相關(guān)的協(xié)議和標準還沒有確定,這也在一定程度上使很多企業(yè)猶豫是否要投入大量資源去進行前期的探究工作。
因此,如何有效的實現(xiàn)這些虛擬化的網(wǎng)絡(luò)功能(Virtualized Network Function - VNF),是我們前階段的主要工作和這篇白皮書主要探討的問題。
虛擬網(wǎng)絡(luò)功能(VNF)的有效實現(xiàn)
在這里,實現(xiàn)虛擬網(wǎng)絡(luò)功能的“有效性”主要體現(xiàn)在以下幾個方面:
1.VNF必須非常靈活、便于使用;
2.容易大規(guī)模擴展,不局限于某種應(yīng)用場景或網(wǎng)絡(luò);
3.性能方面應(yīng)該不低于,甚至高于專用硬件。
介于此,白皮書中給出了幾個有潛力的發(fā)展方向以供參考:
1.控制面和轉(zhuǎn)發(fā)面的分離和獨立擴展。
2.設(shè)計并優(yōu)化、標準化擁有可編程能力的轉(zhuǎn)發(fā)面。
在電信網(wǎng)絡(luò)的應(yīng)用場景中,NFV的一個典型應(yīng)用就是虛擬化的寬帶遠程接入服務(wù)vBRAS,即virtual broadband remote access server,又被稱為vBNG,即virtual broadband network gateway。在vBRAS中可能包含很多虛擬網(wǎng)絡(luò)功能,例如遠程用戶撥入驗證服務(wù)(Remote Authentication Dial-In User Service, RADIUS)、動態(tài)主機設(shè)置協(xié)議(Dynamic Host Configuration Protocol,DHCP),以及之前提過的DPI、防火墻、QoS等。
一個重要的發(fā)現(xiàn)是,這些網(wǎng)絡(luò)應(yīng)用從計算資源的需求上可以分成兩類。一類不需要大量的計算資源,如RADIUS和DHCP。同時這類應(yīng)用很多屬于控制平面。因此這類應(yīng)用很適合直接放在控制平面,并且有很好的縱向和橫向的擴展性,也很適合用通用的計算和存儲設(shè)備進行實現(xiàn)。
另一類應(yīng)用往往需要很大的計算能力,如流量管理、路由轉(zhuǎn)發(fā)、數(shù)據(jù)包處理等,且通常需要在線速下(如40Gbps、100Gbps或更高)進行處理。這類應(yīng)用往往屬于數(shù)據(jù)平面。對于數(shù)據(jù)平面而言,它還需要支持很多種計算量很大的網(wǎng)絡(luò)功能,這樣才能區(qū)別于使用專有硬件,符合NFV技術(shù)的初衷。綜上而言,數(shù)據(jù)平面應(yīng)該具備以下兩點主要能力“
1.能線速進行高吞吐量的復(fù)雜數(shù)據(jù)包處理;
2.同時支持多種網(wǎng)絡(luò)功能,具有很強的可編程能力。
然而,如果直接使用軟件方法實現(xiàn),這兩點功能很難同時滿足。因此我們采用了FPGA作為智能硬件加速平臺,很好的同時解決了處理速度和可編程性兩個問題。首先,F(xiàn)PGA相比純軟件方法,在數(shù)據(jù)包處理上擁有著絕對優(yōu)勢的硬件并行性能,因此被用作硬件加速器使用。其次,相比于傳統(tǒng)的專有硬件設(shè)備,F(xiàn)PGA擁有靈活的可編程能力,可以支持各種應(yīng)用的實現(xiàn)。
虛擬寬帶遠程接入服務(wù):從BRAS到vBRAS的演進
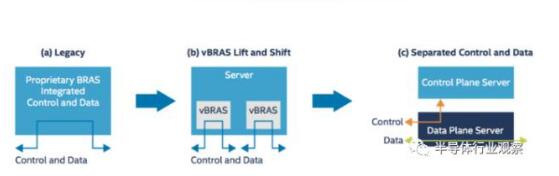
圖1:vBRAS的演化
上圖為我們展示了傳統(tǒng)BRAS逐步演進到vBRAS的三個主要過程:
1.第一階段,傳統(tǒng)的BRAS使用專用設(shè)備,且控制面和轉(zhuǎn)發(fā)面緊耦合。圖中可以看到控制路徑和數(shù)據(jù)路徑是相互重合的。
2.第二階段,采用了虛擬化技術(shù),且采用了服務(wù)器取代了專用BRAS設(shè)備,使用軟件和虛擬機實現(xiàn)多個vBRAS。但同時也可以看到,此時控制面和轉(zhuǎn)發(fā)面還是相互耦合實現(xiàn)。由于兩者性能差別很大,這種實現(xiàn)方式很容易造成數(shù)據(jù)通路的性能瓶頸,或因數(shù)據(jù)通路流量過大而占用了控制面的帶寬。反之,控制面的流量會影響數(shù)據(jù)面的線速包處理的能力。
3.第三階段,采用虛擬化技術(shù),且控制面和轉(zhuǎn)發(fā)面相互分離。從圖中可以看到,控制面和轉(zhuǎn)發(fā)面由兩個服務(wù)器分開實現(xiàn),控制流量和轉(zhuǎn)發(fā)流量相互不影響。此外,控制流量能在數(shù)據(jù)/轉(zhuǎn)發(fā)服務(wù)器和控制服務(wù)器之間雙向流動,實現(xiàn)控制面對轉(zhuǎn)發(fā)面的控制。
這第三個階段就是目前英特爾、HPE和中國電信北研院聯(lián)合研發(fā)的最新成果。接下來就詳細講解其技術(shù)細節(jié)。
高性能vBRAS的設(shè)計方法
設(shè)計實現(xiàn)上述第三階段中高性能的vBRAS方案,需要分別實現(xiàn)vBRAS-c (control) 和vBRAS-d (data),即vBRAS控制設(shè)備和vBRAS數(shù)據(jù)設(shè)備。這兩類設(shè)備都應(yīng)該使用標準化的通用服務(wù)器實現(xiàn)。此外,對于vBRAS數(shù)據(jù)設(shè)備而言,需要針對計算量龐大的應(yīng)用進行專門的優(yōu)化和加速,使其能進行高吞吐量、低延時的數(shù)據(jù)包處理。
下圖展示了本應(yīng)用實例中,vBRAS-c和vBRAS-d的設(shè)計方法。
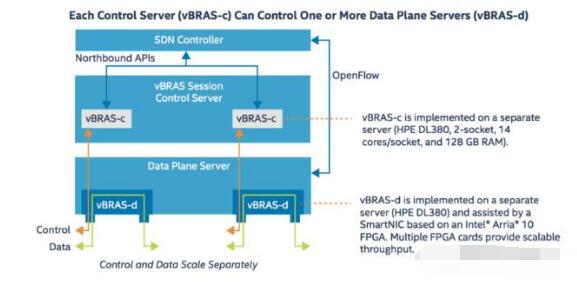
圖2:vBRAS的轉(zhuǎn)控分離架構(gòu)
對于vBRAS-c節(jié)點,其重要的設(shè)計思想就是輕量化和虛擬化,使其方便在數(shù)據(jù)中心或云端進行擴展和移植,同時可以分布式實現(xiàn),以控制多個數(shù)據(jù)平面節(jié)點。因此在本例中,vBRAS-c由一個獨立的HPE DL380服務(wù)器實現(xiàn)。DL380服務(wù)器中包含兩個CPU插槽(socket),每個插槽中均有一塊14核的Xeon處理器。服務(wù)器的總內(nèi)存為128GB。網(wǎng)絡(luò)接口方面,vBRAS-c可以使用標準的網(wǎng)卡進行網(wǎng)絡(luò)通信,比如一塊或多塊英特爾X710 10GbE網(wǎng)卡即可滿足控制平面的流量要求。具體的vBRAS控制應(yīng)用則在虛擬機中實現(xiàn),多個虛擬機由SDN控制器統(tǒng)一控制。
對于vBRAS-d節(jié)點,總體也通過獨立的DL380實現(xiàn)。針對上文提到的優(yōu)化加速的部分,本實例中使用了基于Arria10 FPGA的智能網(wǎng)卡加速網(wǎng)絡(luò)功能,如線速處理QoS和多級流量整形。在一個DL380中,可以插入多塊FPGA智能網(wǎng)卡,實現(xiàn)并行數(shù)據(jù)處理,成倍提高數(shù)據(jù)吞吐量。同時,vBRAS-d節(jié)點通過OpenFlow與SDN控制器交互,且一臺vBRAS-c設(shè)備可以控制多個vBRAS-d設(shè)備。
基于Arria10 FPGA的智能網(wǎng)卡解析
使用FPGA智能網(wǎng)卡進行網(wǎng)絡(luò)加速的好處有以下幾點:
1.解放了寶貴的CPU內(nèi)核,將原本在CPU中實現(xiàn)的數(shù)據(jù)處理卸載到FPGA上進行加速實現(xiàn)。這樣CPU可以用來做其他的工作,在虛擬化的基礎(chǔ)上進一步實現(xiàn)了資源的有效利用。
2.FPGA擁有低功耗、靈活可編程的特點。在白皮書中提到,在選用的Arria10 GT1150 器件上實現(xiàn)了硬件QoS和多級流量整形后,只占用了FPGA的40%的邏輯資源。換言之,還有60%的資源可以被用來進行其他的網(wǎng)絡(luò)功能處理和加速。同時,可以隨時對FPGA進行編程,因此多種網(wǎng)絡(luò)功能的加速都可以用一套硬件設(shè)備完成,不需要更換加速卡或其他硬件設(shè)備。即使是用戶自己定義的功能,也可以實現(xiàn),不需要專有設(shè)備完成。這樣很好的平衡了高性能和高通用性兩者間的矛盾。
3.FPGA能進行高速并行的數(shù)據(jù)包處理,且本身就廣泛應(yīng)用于網(wǎng)絡(luò)通信領(lǐng)域,解決方案豐富且成熟。
下圖概括介紹了本實例中在FPGA中實現(xiàn)的數(shù)據(jù)包轉(zhuǎn)發(fā)的數(shù)據(jù)通路設(shè)計。
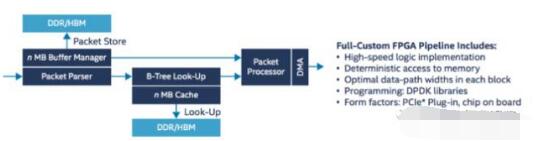
圖3:FPGA數(shù)據(jù)包處理的數(shù)據(jù)通路
由圖中可見,本設(shè)計包含多個模塊,如Parser、Look-Up、Buffer Manager、Packet Processor,以及內(nèi)存控制器和DMA等。數(shù)據(jù)包進入FPGA后,依次通過各個模塊進行特征提取、分類、查找,如果需要就通過PCIe和DMA與CPU進行交互。同時,Buffer Manager會對不同來源的數(shù)據(jù)包進行流量控制、QoS和流量整形等操作。
此外,這款FPGA智能網(wǎng)卡支持多種包處理模式,即可以將數(shù)據(jù)包完全在FPGA內(nèi)部處理后轉(zhuǎn)發(fā),不經(jīng)過CPU;也可以將數(shù)據(jù)包通過PCIe傳送到CPU,使用DPDK進行包處理,再通過FPGA轉(zhuǎn)發(fā);或者二者結(jié)合,一部分功能在CPU中實現(xiàn),另外一部分卸載到FPGA上完成。可見靈活度很高。
性能測試
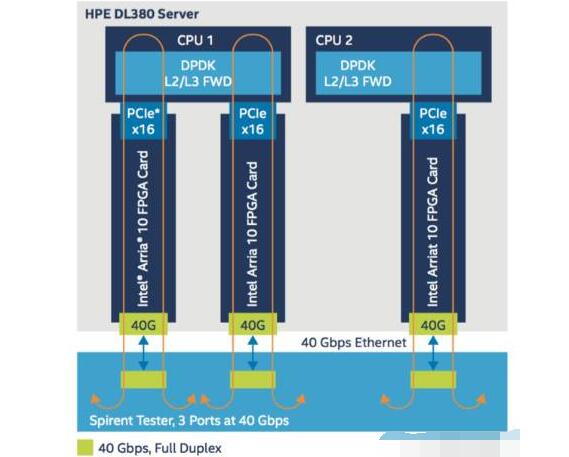
圖4:數(shù)據(jù)平面的服務(wù)器和FPGA架構(gòu)
圖中可見,一個DL380服務(wù)器上插了3塊相互獨立的FPGA智能網(wǎng)卡,每塊網(wǎng)卡支持40Gbps數(shù)據(jù)吞吐量,因此一個vBRAS-d服務(wù)器支持的總吞吐量為120Gbps。每塊網(wǎng)卡通過PCIex16接口與CPU相連,在CPU中運行DPDK L2/L3 FWD應(yīng)用,將數(shù)據(jù)轉(zhuǎn)發(fā)回FPGA,然后在FPGA中進行QoS和數(shù)據(jù)整形。在測試中,流量的產(chǎn)生和接收都通過Spirent測試儀實現(xiàn)。
對于QoS,每個智能網(wǎng)卡可以支持4000用戶,故單服務(wù)器支持12000個用戶。每個用戶支持2個優(yōu)先級,且分配給每個用戶的帶寬可以編程控制。例如,每個用戶分配8.5Mbps帶寬,則開啟流量整形后單服務(wù)器總流量應(yīng)為12000x8.5=102Gbps,如下圖所示。
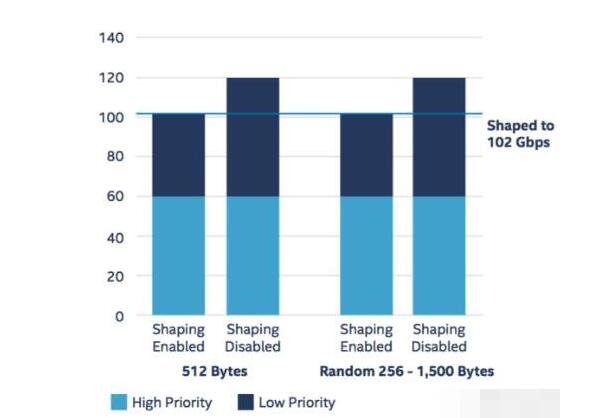
數(shù)據(jù)平面的性能測試結(jié)果
我們看到,當數(shù)據(jù)包為定長512字節(jié)時,關(guān)閉流量整形功能后,高優(yōu)先級流量和低優(yōu)先級流量都沒有損失,各為60Gbps(對應(yīng)每個用戶的實際流量為5Mbps高優(yōu)先級+5Mbps低優(yōu)先級),因此總流量為120Gbps。開啟流量整形功能后,高優(yōu)先級流量沒有損失,仍為60Gbps。對于低優(yōu)先級,由于每個用戶分配8.5Mbps帶寬且高優(yōu)先級已經(jīng)占用了其中的5Mbps,因此只剩余3.5Mbps帶寬供低優(yōu)先級流量通過。可見低優(yōu)先級流量遭到限流,總流量變成3.5Mx12000=42Gbps,使得總流量變成102Gbps。這在總體上證明了單個vBRAS-d節(jié)點可以支持超過100Gbps的流量處理。
此外還進行了一些功耗測試能性能對比,我在此挑選了一張結(jié)果圖如下所示。
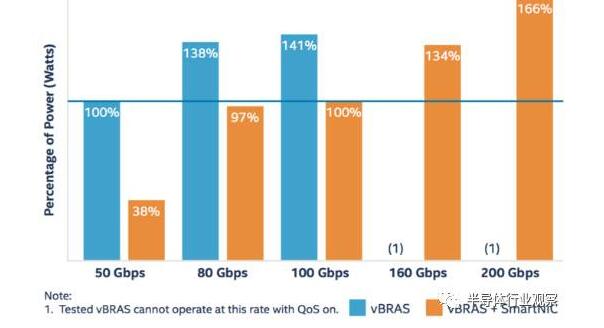
圖5:不同帶寬時總能耗性能比的對比
這張圖表示了實現(xiàn)不同帶寬時,總功耗性能比的一系列比較。功耗性能比的定義為,實現(xiàn)1Tbps時所需要的總功耗(千瓦)。圖中將不含F(xiàn)PGA智能網(wǎng)卡的vBRAS實現(xiàn)50Gbps時的功耗性能比作為基準值(100%)。由圖中可以看到,vBRAS+FPGA智能網(wǎng)卡的方案總能降低超過40%的總功耗,最多可達到60%。這進一步印證了上文中闡述過的使用FPGA進行網(wǎng)絡(luò)功能加速的好處所在。
其他性能測試和對比不再贅述,詳細內(nèi)容在白皮書中可以看到。總體而言,相比于傳統(tǒng)的vBRAS服務(wù)器+標準網(wǎng)卡的方案,使用vBRAS+FPGA智能網(wǎng)卡的解決方案可以減少約50%的功耗,以及帶來超過3倍的性能提升。
SWOT四個維度解析當前國內(nèi)發(fā)展FPGA前景
(1)首先說優(yōu)勢。相比較xilinx和altera,國產(chǎn)FPGA廠商目前基本沒有絕對優(yōu)勢,只有比較優(yōu)勢,比如起點高,再也不用從微米級技術(shù)開始做起,一開始就從幾十納米進入,工藝差距可以縮小到2-3代的水平。另外,中國是FPGA芯片的應(yīng)用大國,國產(chǎn)FPGA有本土化的各種優(yōu)勢,比如對中小客戶需求的理解等比國外巨頭要更接地氣等。
(2)劣勢的話很明顯,從專利、技術(shù)產(chǎn)品到人才及市場品牌等,國產(chǎn)FPGA廠商都和國外巨頭存在很大的差距。
(3)再說機會,當前中國廠商面臨的機會比較多,因為從國家層面來看已經(jīng)把FPGA列為國家戰(zhàn)略芯片,政府在這個領(lǐng)域的投入可能會逐步增加,雖然政府直接主導(dǎo)這個產(chǎn)業(yè)發(fā)展未必是好的方式,但是給予民營企業(yè)各方面的支持卻是非常重要的。另外,隨著中國經(jīng)濟的發(fā)展,中國的企業(yè)能吸引到更多更優(yōu)秀的國際化人才加入,尤其是一些高端的FPGA領(lǐng)軍人才,對一個企業(yè)的發(fā)展至關(guān)重要。最后,隨著人工智能和大數(shù)據(jù)等新興行業(yè)的發(fā)展,F(xiàn)PGA市場容量可能會出現(xiàn)大規(guī)模的增長。
(4)最后說威脅。說道威脅,專利是一個。當中國企業(yè)還很弱小,遠遠對國際巨頭構(gòu)不成競爭的時候,這個風險還不大,如果已經(jīng)形成競爭關(guān)系的時候,可能巨頭們就會拿起專利武器來捍衛(wèi)自己的利益,如同中興、華為在發(fā)展過程中遇到的問題一樣,這就要求中國的FPGA廠商要苦練內(nèi)功,在專利和技術(shù)方面踏踏實實做好積累,以應(yīng)對將來可能出現(xiàn)的專利戰(zhàn)以及國際化,否則即使能做出產(chǎn)品,可能也走不遠。
總體來看,雖然目前中國在FPGA這個領(lǐng)域比國外的主流廠商還存在很大差距,但是考慮到中國經(jīng)濟的發(fā)展和綜合國力的增強以及政府對芯片產(chǎn)業(yè)的高度重視,還有這個市場可能出現(xiàn)的大幅增長,中國的國產(chǎn)FPGA和國外主流廠商的差距會逐步縮小,雖然這個過程會比較長,但趨勢是無疑的。
近些年中國陸陸續(xù)續(xù)誕生了一些FPGA廠商,如京微雅閣、安路、同創(chuàng)、高云半導(dǎo)體等公司,都先后推出自己的FPGA芯片,有的已經(jīng)在商用,有的在大公司進行樣品認定和試驗項目,這是一個很好的信號。在今年的“IC-CHINA 2017”大會中,高云發(fā)布了3款新品,不僅發(fā)布了集成ARM3的SOC FPGA,還有基于55nm SRAM工藝的“晨熙”系列和基于55nm嵌入式Flash+SRAM的“小蜜蜂”4個系列11款產(chǎn)品,基本覆蓋了lattice 70%~80%左右的產(chǎn)品,特別是小蜜蜂系列,對應(yīng)lattice 的XO2/XO3,對其形成強有力的替代競爭優(yōu)勢。另外,高云28nm的產(chǎn)品已經(jīng)在研發(fā)中,預(yù)計2019年左右推出。目前高云FPGA芯片累計出貨量即將達到200萬片,對于一個成立才3年左右的公司,這個發(fā)展是相當迅速的,如果芯片的良率在應(yīng)用中得到逐步提高,芯片可靠性得到了用戶的認可,這將會對國外廠商產(chǎn)生很大的沖擊。與此同時,安路也發(fā)布了它最新55nm的第二代“小精靈”ELF2系列高性能低功耗和內(nèi)嵌MCU的SOC FPGA,向國外廠家的中低端產(chǎn)品發(fā)起了挑戰(zhàn)。
回頭看中國每個發(fā)展得不錯的行業(yè),基本都遵循一個邏輯,先是從低端開始突破,對國外同類產(chǎn)品進行替代,在行業(yè)站穩(wěn)了腳跟之后,開始持續(xù)改進,不斷提升自己的技術(shù)、產(chǎn)品、服務(wù)以及專利積累等,到了一定階段之后可以在細分領(lǐng)域里面創(chuàng)造一些需求,以不斷向高端進軍,最終在行業(yè)里面的高端占有一席之地。中國通訊制造業(yè)、高鐵制造等都是遵循這個邏輯發(fā)展的。 “低端突破-》持續(xù)改進-》創(chuàng)造需求-》高端引領(lǐng)” 是中國各個行業(yè)發(fā)展的必由之路。對于FPGA行業(yè)來說,也完全可以按照這個思路發(fā)展。
FPGA市場前景誘人,但是門檻之高在芯片行業(yè)里無出其右。全球有60多家公司先后斥資數(shù)十億美元,前赴后繼地嘗試登頂FPGA高地,其中不乏英特爾、IBM、德州儀器、摩托羅拉、飛利浦、東芝、三星這樣的行業(yè)巨鱷,但是最終登頂成功的只有位于美國硅谷的四家公司:Xilinx(賽靈思)、Altera(阿爾特拉)、Lattice(萊迪思)、Microsemi(美高森美),其中,Xilinx與Altera這兩家公司共占有近90%的市場份額,專利達到6000余項之多,如此之多的技術(shù)專利構(gòu)成的技術(shù)壁壘當然高不可攀。而Xilinx始終保持著全球FPGA的霸主地位。當今,半導(dǎo)體市場格局已成三足鼎立之勢,F(xiàn)PGA,ASIC和ASSP三分天下。市場統(tǒng)計數(shù)據(jù)表明,F(xiàn)PGA已經(jīng)逐步侵蝕ASIC和ASSP的傳統(tǒng)市場,并處于快速增長階段。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論