 電子發(fā)燒友App
電子發(fā)燒友App


這一篇主要來介紹存儲區(qū),總線,以及IO設(shè)備等其他幾大組件,來了解整個計算機(jī)是如何工作的。 這些東西都是看得見摸得著的硬件,平時我們買電腦時最關(guān)注的就是CPU的速度,內(nèi)存的大小,主板芯片等等的參數(shù)。
1. 存儲器
前面我們以一個簡單通用的計算機(jī)模型來介紹了CPU的工作方式,CPU執(zhí)行指令,而存儲器為CPU提供指令和數(shù)據(jù)。 在這個簡單的模型中,存儲器是一個線性的字節(jié)數(shù)組。CPU可以在一個常數(shù)的時間內(nèi)訪問每個存儲器的位置,雖然這個模型是有效的,但是并不能完全反應(yīng)現(xiàn)代計算機(jī)實(shí)際的工作方式。
1.1 存儲器系統(tǒng)層次結(jié)構(gòu)
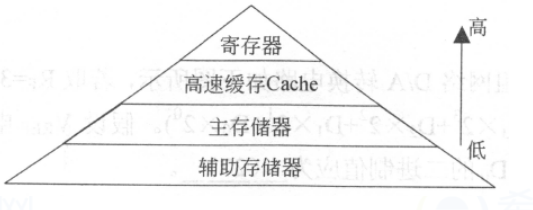
在前面介紹中,我們一直把存儲器等同于了內(nèi)存,但是實(shí)際上在現(xiàn)代計算機(jī)中,存儲器系統(tǒng)是一個具有不同容量,不同訪問速度的存儲設(shè)備的層次結(jié)構(gòu)。整個存儲器系統(tǒng)中包括了寄存器、Cache、內(nèi)部存儲器、外部存儲。下圖展示了一個計算機(jī)存儲系統(tǒng)的層次圖。層次越高速度越快,但是價格越高,而層次越低,速度越慢,價格越低。
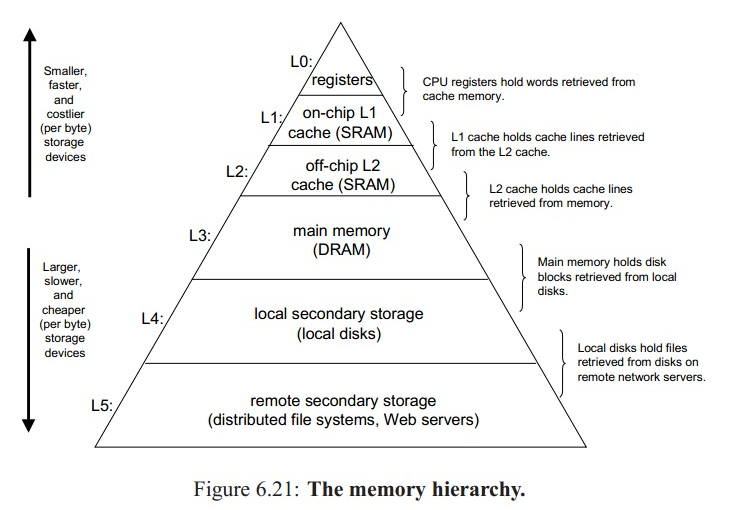
相對于CPU來說,存儲器的速度是相對比較慢的。無論CPU如何發(fā)展,速度多塊,對于計算機(jī)來說CPU總是一個稀缺的資源,所以我們應(yīng)該最大程度的去利用CPU。其面我們提到過CPU周期,一個CPU周期是取1條指令的最短的時間。由此可見,CPU周期在很大程度上決定了計算機(jī)的整體性能。你想想如果當(dāng)CPU去取一條指令需要2s,而執(zhí)行一個指令只需要2ms,對于計算機(jī)來說性能是多么大的損失。所以存儲器的速度對于計算機(jī)的速度影響是很大的。
對于我們來說,總是希望存儲器的速度能和CPU一樣或盡量的塊,這樣一個CPU周期需要的時鐘周期就越少。但是現(xiàn)實(shí)是,這樣的計算機(jī)可能相當(dāng)?shù)陌嘿F。所以在計算機(jī)的存儲系統(tǒng)中,采用了一種分層的結(jié)構(gòu)。速度越快的存儲器容量越小,這樣就能做到在性能和價格之間的一個很好的平衡。
1.2 存儲技術(shù)
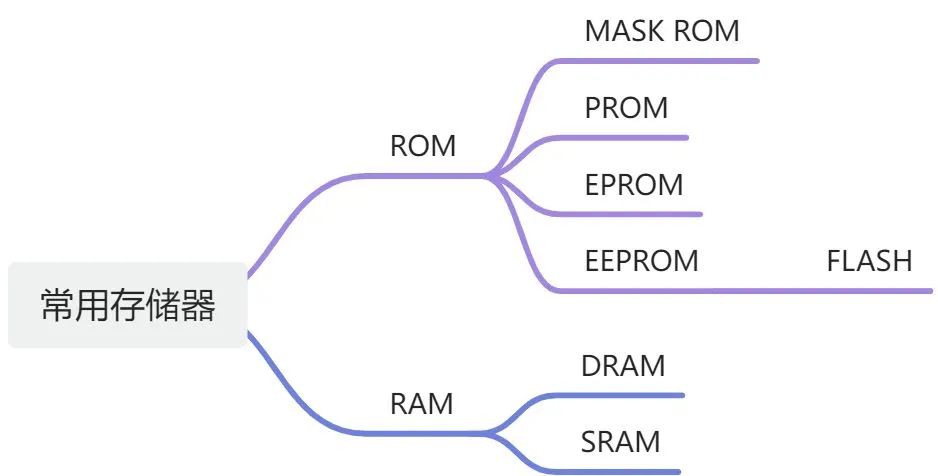
計算機(jī)的發(fā)展離不開存儲器的發(fā)展,早起的計算機(jī)沒用硬盤,只有幾千字節(jié)的RAM可用。而我們現(xiàn)在4G,8G的內(nèi)存已經(jīng)隨處可見,1T的大硬盤以及上百G的固態(tài)硬盤,而價格也比10年,20年前便宜的很多很多。所以我先大概了解下各種存儲技術(shù)。目前存儲技術(shù)大致分為SRAM存儲器、DRAM存儲器、ROM存儲器和磁盤。
1.2.1 寄存器
在上一篇文章的圖中我們有看得CPU內(nèi)部有很多寄存器,而上一張圖也顯示,寄存器在存儲層次結(jié)構(gòu)的頂端。它也叫觸發(fā)器,它往往和CPU同時鐘頻率,所以速度非常快。但是一個寄存器需要20多個晶體管,所以如果大量使用,CPU的體積會非常大。所以在CPU中只有少量的寄存器。而每個寄存器的大小都是8-64字節(jié)。
1.2.2 RAM隨機(jī)訪問存儲
RAM(Read-Access Memory)分為兩類,靜態(tài)(SRAM)和動態(tài)(DRAM)。SDRAM比DRAM要快的多,但是價格也要貴的多。
靜態(tài)RAM: SRAM將每個位存儲在一個雙穩(wěn)態(tài)的存儲單元中,每個存儲單元是用一個六晶體管電路實(shí)現(xiàn)的。它的特點(diǎn)是可以無限期(只要有電)的保持在兩個穩(wěn)定狀態(tài)中的一個(正好可以存放0或1),而其他任何狀態(tài)都是不穩(wěn)定的會馬上切換到這兩個狀態(tài)中的一個;
動態(tài)RAM: DRAM是利用電容內(nèi)儲存電荷的多寡來代表一個二進(jìn)制位元(bit)是1還是0,每一bit由一個晶體管和電容組成。由于在現(xiàn)實(shí)中電容會有漏電的現(xiàn)象,導(dǎo)致電位差不足而使記憶消失,因此除非電容經(jīng)常周期性地充電,否則無法確保記憶長存。由于這種需要定時刷新的特性,因此被稱為“動態(tài)”記憶體。
SRAM相比DRAM速度更快功耗更低,而由于結(jié)構(gòu)相對復(fù)雜占用面積較大,所以一般少量在CPU內(nèi)部用作Cache,而不適合大規(guī)模的集成使用,如內(nèi)存。而DRAM主要用來作為計算機(jī)的內(nèi)部主存。
Cache: 目前我們CPU中一般集成了2到3級的Cache,容量從128K到4M。對于CPU總的Cache來說,它們的也是和CPU同頻率的,所以理論上執(zhí)行速度和寄存器應(yīng)該是相同的,但是Cache往往用來存儲一些指令和數(shù)據(jù),這樣就存在一個命中的問題。當(dāng)沒有命中的時候,需要向下一集的存儲器獲取新的數(shù)據(jù),這時Cache會被lock,所以導(dǎo)致實(shí)際的執(zhí)行速度要比寄存器慢。同樣對于L1,L2,L3來說,速度也是越來越慢的;
主存: 也就是我們說的內(nèi)存,使用DRAM來實(shí)現(xiàn)。但是我們目前聽的內(nèi)存一般叫DDR SDRAM,還有早期的SDRAM。這是一種同步的DRAM技術(shù),我們不需要了解他的詳情,只需要知道它能有效的提高DRAM的傳輸帶寬。而DDR表示雙倍的速率,而現(xiàn)在又有了DDR2,DDR3,DDR4,他們的帶寬也是越來越大。
1.2.3 ROM只讀存儲
前面的RAM在斷電后都會丟失數(shù)據(jù),所以他們是易失的。另一方面非易失的存儲器即便在斷點(diǎn)后也能保存數(shù)據(jù)。一般我們稱之為ROM(Read-Only Memory)。雖然這么說,但是ROM在特殊的情況下還是可以寫入數(shù)據(jù)的,否則就不能叫存儲器了。
PROM: 可編程ROM,只能被編程一次,PROM包含一種熔絲,每個存儲單元只能用高電流燒斷一次;
EPROM:可擦寫可編程ROM,有一個透明的石英窗口,紫外線通過窗口照射到存儲單元就被清除為0,而對它編程是使用一種特殊的設(shè)備來寫入1。寫入次數(shù)1K次;
EEPROM:: 電子可擦除可編程ROM,不需要特殊設(shè)備而可以直接在印制的電路板上編程。寫入次數(shù)10萬次;
Flash Memory: 這是我們見到最多的閃存,有NOR Flash、NAND Flash、V-NAND Flash、SLC、MLC、TLC。雖然是基于EEPROM,但是速度上卻要快很多。其中NOR 、NANA Flash大量的使用在U盤,SD卡、手機(jī)存儲上。
ROM在計算機(jī)中應(yīng)用也比較多,比如我們的BIOS芯片,最開始采用PROM,后來使用EPROM,如果損壞計算機(jī)就無法啟動了。而目前手機(jī)中也采用ROM來燒入系統(tǒng),而RAM作為內(nèi)存,使用Flash Memory作為機(jī)身存儲。
1.2.4 磁盤存儲
也就是我們最常見的硬盤。目前硬盤主流已經(jīng)是500G,1T。轉(zhuǎn)速也在7200轉(zhuǎn)左右。相對于8G的內(nèi)存,一個500G的硬盤可以說是相當(dāng)?shù)谋阋恕5菃栴}在于他的速度非常的慢,從磁盤讀取數(shù)據(jù)需要幾個毫秒,而CPU時鐘周期是以納秒計算。磁盤讀取操作要比DRAM慢10萬倍,比SRAM慢百萬倍。
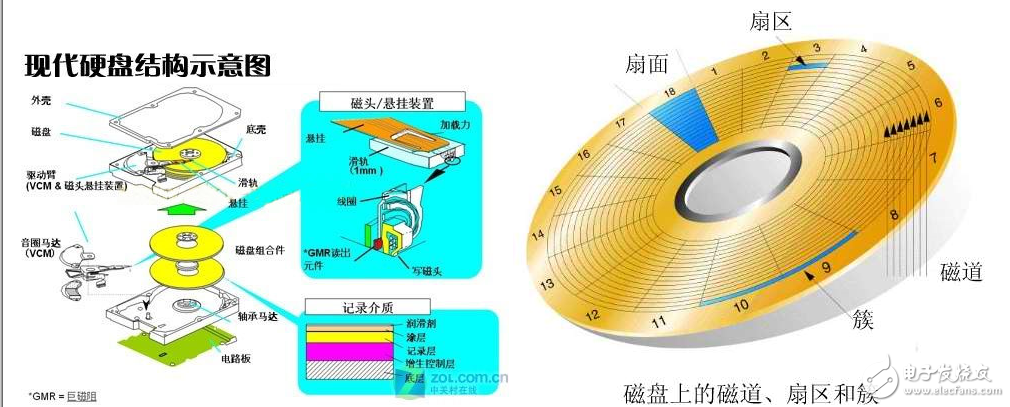
相對于CPU,內(nèi)部存儲的電子結(jié)構(gòu),磁盤存儲是一種機(jī)械結(jié)構(gòu)。數(shù)據(jù)都通過電磁流來改變極性的方式被電磁流寫到磁盤上,而通過相反的方式讀回。一個硬盤由多個盤片組成,每個盤片被劃分為磁道,扇區(qū)和最小的單位簇。而每個盤面都有一個磁頭用來讀取和寫入數(shù)據(jù)。而硬盤的馬達(dá)裝置則控制了磁頭的運(yùn)動。
1.2.5 虛擬硬盤(VHD)和固態(tài)硬盤(SSD)
隨著計算機(jī)的發(fā)展,緩慢的磁盤速度已經(jīng)成為計算機(jī)速度的障礙了。大多數(shù)情況下,你的CPU夠快,內(nèi)存夠大,可是打開一個程序或游戲時,加載的速度總還是很慢。(關(guān)于程序加載的過程后面的文章會講到)。原因就是磁盤讀寫速度太慢,所以一度出現(xiàn)了虛擬硬盤。就是把一部分內(nèi)存虛擬成硬盤,這樣一些緩存文件直接放到內(nèi)存中,這樣就加快了程序訪問這些數(shù)據(jù)的速度。但是他的問題是易失的。當(dāng)然你可以保存到磁盤,但是加載和回寫的速度會隨著數(shù)據(jù)量加大而加大。所以這個適用于一些臨時數(shù)據(jù)的情況,比如瀏覽器緩存文件。
而固態(tài)硬盤是最近幾年出來的,而且隨著技術(shù)的發(fā)展,價格也越來越便宜,越來越多的人采用SSD+HHD的方式來搭建系統(tǒng),提高系統(tǒng)的速度。其實(shí)SSD在上世紀(jì)80年代就有基于DRAM的產(chǎn)品,但是因?yàn)橐资院蛢r格而無法推廣開來。而現(xiàn)在的SSD則是使用Flash Memory。目前市面上最常見的是SLC,MLC,TLC存儲介質(zhì)的固態(tài)硬盤。我們知道Flash都是與寫入次數(shù)限制的。而SLC》MLC》TLC。目前主流的SSD都是使用MLC,比如Intel 520,三星830系列。當(dāng)然目前三星也退出了基于TLC的固態(tài)硬盤,價格相對要便宜一些。
1.2.6 遠(yuǎn)程存儲
簡單可以理解為是將數(shù)據(jù)指令存儲在其他機(jī)器上,比如分布式系統(tǒng),WebService Server,HTTP Server以及現(xiàn)在炒的火熱的云端存儲。計算機(jī)通過網(wǎng)絡(luò)相互連接。比較起磁盤,遠(yuǎn)程存儲的速度是以秒來計算。
1.3 局部性
通過上面介紹我們對計算機(jī)存儲器有了一個了解,并且知道了存儲器層次越高速度越快。那么為什么我們要對存儲器分層呢? 分成是為了彌補(bǔ)CPU和存儲器直接速度的差距。這種方式之所有有效,是因?yàn)閼?yīng)用程序的一個特性:局部性。
我們知道計算機(jī)的體系是存儲程序,順序執(zhí)行。所以在執(zhí)行一個程序的指令時,它后面的指令有很大的可能在下一個指令周期被執(zhí)行。而一個存儲區(qū)被訪問后,也可能在接下來的操作中再次被訪問。這就是局部性的兩種形式:
時間局部性
空間局部性
對于現(xiàn)代計算機(jī)來說,無論是應(yīng)用程序,操作系統(tǒng),硬件的各個層次我們都是用了局部性。
硬件:通過引入Cache存儲器來保存最近訪問的指令數(shù)據(jù)來提高對主存的訪問速度。
操作系統(tǒng): 允許是用主存作為虛擬地址空間被引用塊的高速緩存以及從盤文件的塊的高速緩存。
應(yīng)用程序:將一些遠(yuǎn)程服務(wù)比如HTTP Server的HTML頁面緩存在本度的磁盤中。
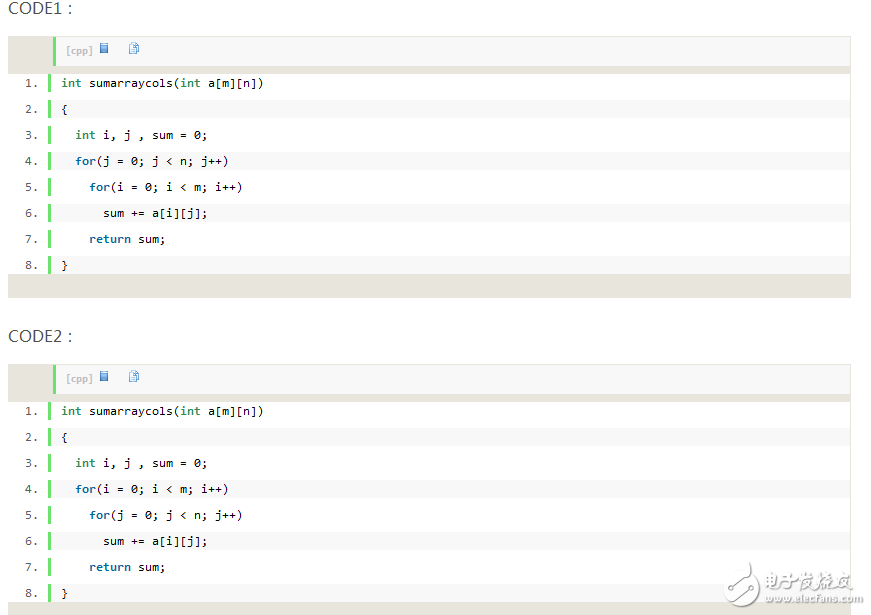
以上2段代碼差別只有for循環(huán)的順序,但是局部性卻相差了很多。我們知道數(shù)組在內(nèi)存中是按照行的順序來存儲的。但是CODE1確實(shí)按列去訪問,這可能就導(dǎo)致緩存不命中(需要的數(shù)據(jù)并不在Cache中,因?yàn)镃ache存儲的是連續(xù)的內(nèi)存數(shù)據(jù),而CODE1訪問的是不聯(lián)系的),也就降低了程序運(yùn)行的速度。
2 存儲器訪問和總線
前面介紹了存儲器的存儲技術(shù)和分層,也一直提到CPU從存儲器中獲取數(shù)據(jù)和指令,這一節(jié)就介紹一下CPU和存儲器之間是如何通信的。
2.1 總線
所謂總線是各種功能部件之間傳送信息的公共通信干線,它是由導(dǎo)線組成的傳輸線束。我們知道計算機(jī)有運(yùn)算器,控制器,存儲器,輸入輸出設(shè)備這五大組件,所以總線就是用來連接這些組件的導(dǎo)線。
按照計算機(jī)所傳輸?shù)男畔⒎N類,計算機(jī)的總線可以劃分為
數(shù)據(jù)總線: 數(shù)據(jù)總線DB是雙向三態(tài)形式的總線,即它既可以把CPU的數(shù)據(jù)傳送到存儲器或輸入輸出接口等其它部件,也可以將其它部件的數(shù)據(jù)傳送到CPU。數(shù)據(jù)總線的位數(shù)是微型計算機(jī)的一個重要指標(biāo),通常與微處理的字長相一致。我們說的32位,64位計算機(jī)指的就是數(shù)據(jù)總線。
地址總線: 地址總線AB是專門用來傳送地址的,由于地址只能從CPU傳向外部存儲器或I/O端口,所以地址總線總是單向三態(tài)的,這與數(shù)據(jù)總線不同。地址總線的位數(shù)決定了CPU可直接尋址的內(nèi)存空間大小。
控制總線:控制總線主要用來傳送控制信號和時序信號。控制總線的傳送方向由具體控制信號而定,一般是雙向的,控制總線的位數(shù)要根據(jù)系統(tǒng)的實(shí)際控制需要而定。其實(shí)數(shù)據(jù)總線和控制總線可以共用。
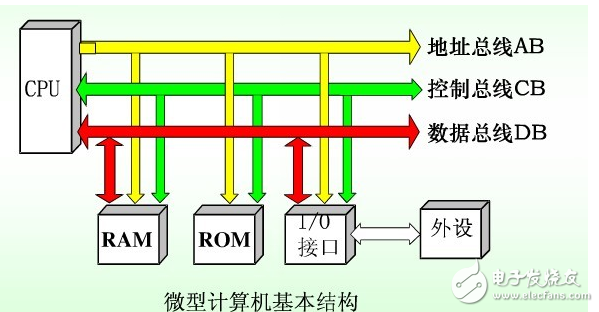
總線也可以按照CPU內(nèi)外來分類:
內(nèi)部總線:在CPU內(nèi)部,寄存器之間和算術(shù)邏輯部件ALU與控制部件之間傳輸數(shù)據(jù)所用的總線稱為片內(nèi)部總線。
外部總線:通常所說的總線指片外部總線,是CPU與內(nèi)存RAM、ROM和輸入/輸出設(shè)備接口之間進(jìn)行通訊的通路,也稱系統(tǒng)總線。
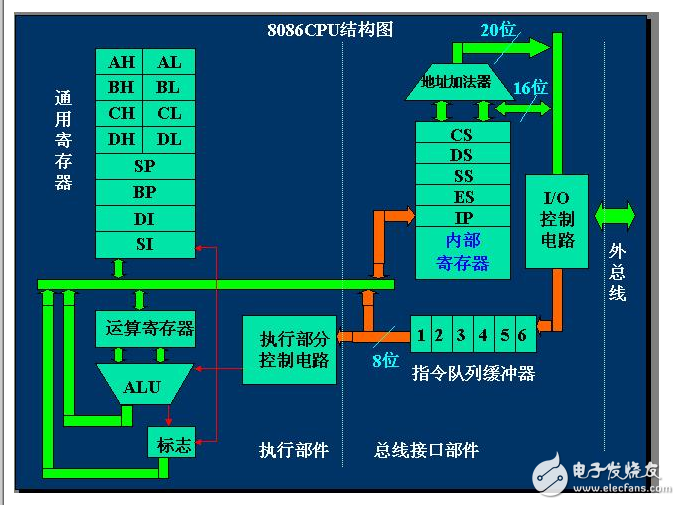
2.2 控制芯片
前面我面介紹了總線的分類,在我們的簡單模型中。CPU通過總線和存儲器之間直接進(jìn)行通信。實(shí)際上在現(xiàn)代的計算機(jī)中,存在一個控制芯片的模塊。CPU需要和存儲器,I/O設(shè)備等進(jìn)行交互,會有多種不同功能的控制芯片,我們稱之為控制芯片組(Chipset)。
對于目前的計算機(jī)結(jié)構(gòu)來說,控制芯片集成在主板上,典型的有南北橋結(jié)構(gòu)和單芯片結(jié)構(gòu)。與芯片相連接的總線可以分為前端總線(FSB)、存儲總線、IQ總線,擴(kuò)展總線等。
南北橋芯片結(jié)構(gòu):
北橋芯片,它控制著CPU的類型,主板的總線頻率,內(nèi)存控制器,顯示核心等。它直接與CPU、內(nèi)存、顯卡、南橋相連,所以它數(shù)據(jù)量非常大;
前端總線:是將CPU連接到北橋芯片的總線。FSB的頻率是指CPU和北橋之間的數(shù)據(jù)交換速度。速度越快,數(shù)據(jù)帶寬越高,計算機(jī)性能越好;
內(nèi)存總線:是將內(nèi)存連接到北橋芯片的總線。用于和北橋之間的通信;
顯卡總線:是將顯卡連接到北橋芯片的總新。目前有AGP,PCI-E等接口。其實(shí)并沒有顯卡總線一說,一般認(rèn)為屬于I/O總線;
南橋芯片,它主要負(fù)責(zé)外部接口和內(nèi)部CPU的聯(lián)系;
I/O總線:連接外部I/O設(shè)備連接到南橋的總線, 比如USB設(shè)備,ATA,SATA設(shè)備,以及一些擴(kuò)展接口;
擴(kuò)展總線:主要是主板上提供的一些PCI,ISA等插槽;
單芯片結(jié)構(gòu): 單芯片組主要是是取消了北橋,因?yàn)楝F(xiàn)在CPU中內(nèi)置了內(nèi)存控制器,不需要再通過北橋來控制,這樣就能提高內(nèi)存控制器的頻率,減少延遲。而現(xiàn)在一些CPU還集成了顯示單元。也使得顯示芯片的頻率更高,延遲更低。
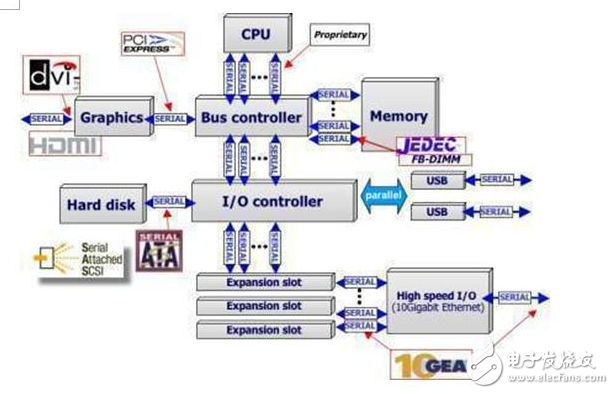
2.3 運(yùn)行頻率
數(shù)據(jù)帶寬 = (總線頻率*數(shù)據(jù)位寬)/ 8
2.3.1 外頻
外頻是建立在數(shù)字脈沖信號震動速度基礎(chǔ)上的。它是CPU與系統(tǒng)總線以及其他外部設(shè)備共同運(yùn)行的速度。我們知道計算機(jī)中有一個時序發(fā)生器來保證各個部件協(xié)同工作,而這里說的外頻率就是這個時序發(fā)生器的頻率。外頻也是系統(tǒng)總線的工作頻率。
2.3.2 頻率和控制芯片
在計算機(jī)剛開始的時候,CPU和內(nèi)存還有I/O設(shè)置是直接通過總線連接的而沒有控制芯片。所有設(shè)備都同步的工作在同一個總線頻率下。
但是隨著CPU的發(fā)展,CPU速度越來越塊。但受限于I/O設(shè)備。于是就出現(xiàn)了芯片。他使得I/O總線不在直接和CPU的系統(tǒng)總線相連。這樣就有了2個不同頻率的總線,這個芯片實(shí)際起到了一個降頻的作用,也就相對于系統(tǒng)總線的分頻技術(shù)。
但CPU速度發(fā)展相當(dāng)快,CPU的速度已經(jīng)高于內(nèi)存運(yùn)行的速度,于是引入了倍頻的概念。CPU在不改變外頻和系統(tǒng)總線頻率的情況下運(yùn)行在更高的頻率。
發(fā)展到后來,就出現(xiàn)了北橋芯片,而CPU和北橋之前的總線稱為了FSB總線,而內(nèi)存與北橋之前稱為內(nèi)存總線。
2.3.2 分頻和倍頻
分頻:使得I/O設(shè)備可以和較高的外頻協(xié)同工作。比如AGP,PCI總線,運(yùn)行頻率在66MHZ和33MHZ,所以對于一個100MHZ的外頻來說,采用2/3或1/3分頻的方式就能使得CPU和外設(shè)同步的工作了。否則設(shè)備可能無法正常工作。
倍頻: 為了提高CPU頻率又正常的和內(nèi)存進(jìn)行工作,所以產(chǎn)生了倍頻。所以對于CPU來說他實(shí)際的頻率是外頻*倍頻。
2.3.3 FSB頻率
前面我們現(xiàn)在已經(jīng)知道CPU和北橋芯片連接是通過FSB。而FSB頻率表示CPU和北橋芯片之間的工作速度。但是從前面我們就知道FSB的實(shí)際頻率是和外頻一樣的。但是隨著技術(shù)的發(fā)展,Intel的QDR技術(shù)和AMD的HT技術(shù),使得CPU在一個時鐘周期可以傳送4次數(shù)據(jù),所以對于FSB淶說雖然工作早外頻的頻率下,但是等效的頻率是外頻的4倍。所以我們說的FSB頻率是等效頻率,而不是實(shí)際的工作頻率。隨著技術(shù)的發(fā)展,Intel芯片的FSB有800MHz,1600HMz等等。但隨著北橋芯片的消失,F(xiàn)SB的概率也慢慢遠(yuǎn)去。
2.3.4 內(nèi)存頻率
對于內(nèi)存頻率我們可以看到,一般包括了核心頻率,總線頻率和傳輸頻率:
核心頻率和外頻類似,是建立在脈沖震蕩信號上的。
總線頻率就是指內(nèi)存總線的工作頻率。也就是內(nèi)存和北橋芯片之間的工作頻率。
而傳輸頻率類似FSB,是指實(shí)際傳輸數(shù)據(jù)的頻率。
對于SDR來說,它的3個頻率是一致的。而DDR在一個時鐘周期可以傳送2次數(shù)據(jù),所以它的傳輸頻率是核心和總線頻率的2倍。DDR2在DDR的基礎(chǔ)上,采用了4bit預(yù)讀,所以總線頻率是核心頻率的2倍,而DDR3采用了8bit預(yù)讀,總線頻率是核心頻率的4倍。
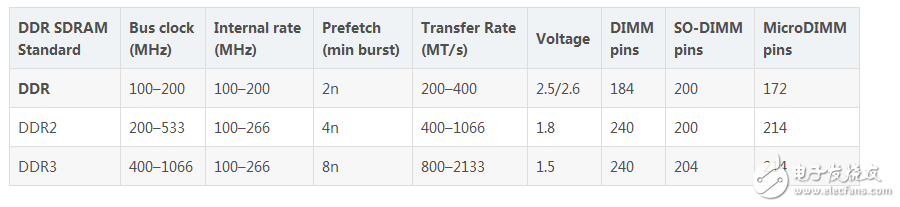
從下表我們就能看出。所以我們常說的DDR3 1600,DDR2 800指的是內(nèi)存的傳輸頻率。相同的技術(shù)還有顯卡的AGP4X,8X,PCIE-8X,16X等技術(shù)。
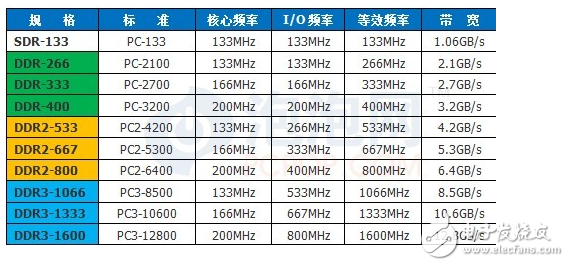
而隨著FSB速度不斷加快,內(nèi)存的總線頻率組建成為了瓶頸,于是出現(xiàn)了DDR雙通道,雙通道是指芯片擁有2個內(nèi)存控制器,所以可以使得傳輸速率翻倍。
2.3.5 內(nèi)存總線工作方式
因?yàn)閮?nèi)存總線頻率不同,所以內(nèi)存和CPU之間存在同步和異步兩種工作方式。
同步方式:內(nèi)存總線頻率和CPU外頻相同。比如以前的PC133和P3處理器,他們以同步的方式工作在133MHZ下。而當(dāng)你超頻時就需要擁有更高總線頻率的內(nèi)存。當(dāng)然也需要北橋芯片的支持。
異步方式:內(nèi)存總線頻率和CPU外頻不同。睡著CPU外頻的提高,內(nèi)存也必須更新,所以出現(xiàn)了異步的方式。比如P4 CPU外頻為200MHz,而內(nèi)存卻可以使用DDR333來運(yùn)行。同時異步方式也在超頻時經(jīng)常使用。一般來說會有一個內(nèi)存異步比率。在BIOS中會有相應(yīng)的選項(xiàng)。
從性能上來講,同步方式的延遲要好于異步方式,這也是為什么以前會說P4 200外頻的CPU要使用DDR400才能發(fā)揮最大功效。但這也不是絕對的。比如我的I5處理器CPU外頻工作在100MHz,而我使用的DDR3-1600的總線頻率在200MHz,雖然不同步,但是擁有更高的傳輸速率。所以不能一概而論。
從前面我們知道了FSB對整個系統(tǒng)的性能影響很大,1600MHZ的FSB能提供的數(shù)據(jù)帶寬也只有12.8GB/s,所以隨著技術(shù)的發(fā)展,現(xiàn)在最新的計算機(jī)基本都采用了單芯片設(shè)計,北橋的功能被集成到了CPU內(nèi)部。于是我們前面說的FSB也就不存在了。對于Intel和AMD這2大芯片廠商,分別有自己的技術(shù)來提高CPU和存儲器以及其他設(shè)備之間的傳輸速率,滿足更高的計算要求。
QPI: Intel的QuickPath Interconnect技術(shù)縮寫為QPI,譯為快速通道互聯(lián)。用來實(shí)現(xiàn)芯片之間的直接互聯(lián),而不是在通過FSB連接到北橋。早期20位寬的QPI連接其帶寬可達(dá)驚人的每秒25.6GB,遠(yuǎn)非FSB可比。而隨著技術(shù)發(fā)展,在高端安騰處理中峰值可以達(dá)到96GB/s。
HT:HyperTransport本質(zhì)是一種為主板上的集成電路互連而設(shè)計的端到端總線技術(shù),目的是加快芯片間的數(shù)據(jù)傳輸速度。HyperTransport技術(shù)在AMD平臺上使用后,是指AMD CPU到主板芯片之間的連接總線(如果主板芯片組是南北橋架構(gòu),則指CPU到北橋)即HT總線。HT3.1理論上可以達(dá)到51.2GB/s。
除此之外,但芯片中的QPI和HT傳輸不需要經(jīng)過北橋新片,在CPU內(nèi)存除了集成內(nèi)存控制器意外還可以集成PCI-E2.0的圖形核心,使得集成顯卡的核心頻率和數(shù)據(jù)吞吐量大幅提高。
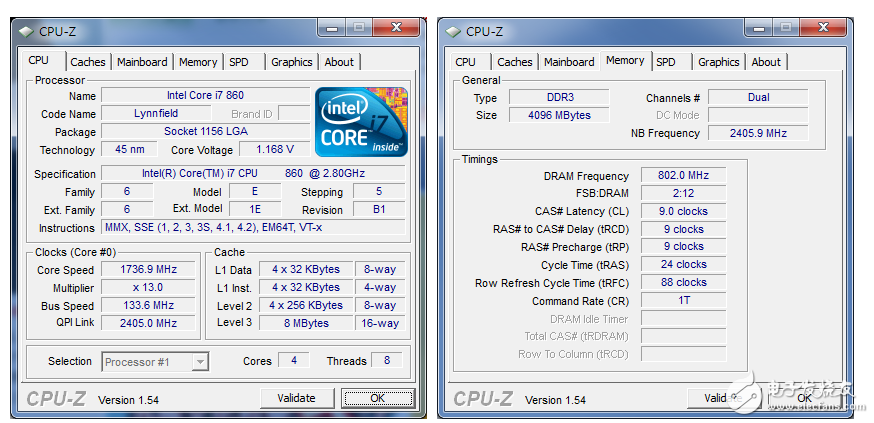
如圖,Core I7處理器外頻只有133MHz, 使用QPI技術(shù)后總線頻率達(dá)到2.4GMhz,而使用DDR3-1600的內(nèi)存,內(nèi)存總線頻率在800MHz。
2.3.7 小結(jié)
這一結(jié)介紹了計算機(jī)總線系統(tǒng)以及CPU和各個設(shè)備之間的交互。我們可以看到除了CPU自身的速度之外,總線的速度也影響這計算機(jī)的整體性能。從發(fā)展的過程來看,總線也是一個分分合合的過程。從最初的一條總線,到后來的單獨(dú)出來的I/O總線,內(nèi)存總線,就是為了提高CPU的效率。而當(dāng)CPU和內(nèi)存速度都發(fā)展到一定階段后,又出現(xiàn)了DDR,雙通道等技術(shù),在不提高核心頻率的情況下提高了傳輸率。于是又出現(xiàn)了CPU和內(nèi)存間直接總線通信降低延遲的情況。 (從2000年開始接觸電腦DIY,一直到07年畢業(yè),都對DIY很有興趣,但是隨著電腦越來越快,目前以及弄不太清楚了,復(fù)習(xí)這些知識也費(fèi)了我好多時間。)
3. I/O設(shè)備
前面主要介紹了系統(tǒng)總線和CPU與內(nèi)存之間的通信,最后一部分簡單介紹一下CPU和I/O設(shè)備是如何通信的。對于計算機(jī)來說輸入輸出設(shè)備也是五大組件。我們知道相對于CPU,I/O設(shè)備的工作頻率要慢的很多。比如早期的PCI接口工作頻率只有33MHz,硬盤的IDE-ATA6的傳輸速率也只有133MB/s。而現(xiàn)在的 SATA3接口速率能達(dá)到600MB/s。
3.1 I/O設(shè)備原理
對于硬件工程師來說,I/O設(shè)備是電子芯片、導(dǎo)線、電源、電子控制設(shè)備、電機(jī)等組成的物理設(shè)備。而對于程序員來說,關(guān)注的只是I/O設(shè)備的編程接口。
3.1.1 I/O設(shè)備分類
塊設(shè)備: 塊設(shè)備把信息存放在固定大小的塊中,每個塊都有自己的地址,獨(dú)立于其他塊,可尋址。例如磁盤,USB閃存,CD-ROM等。
符號設(shè)備:字符設(shè)備以字符為單位接收或發(fā)送一個字符流,字符設(shè)備不可以尋址。列入打印機(jī)、網(wǎng)卡、鼠標(biāo)鍵盤等。
3.1.2 設(shè)備控制器
I/O設(shè)備一般由機(jī)械部件和電子部件兩部分組成。電子設(shè)備一般稱為設(shè)備控制器,在計算機(jī)上一般以芯片的形式出現(xiàn),比如我們前面介紹的南橋芯片。不同的控制器可以控制不同的設(shè)備。所以南橋芯片中包含了多種設(shè)備的控制器,比如硬盤控制器,USB控制器,網(wǎng)卡、聲卡控制器等等。而通過總線以及卡槽提供和設(shè)備本身的連接。比如PCI,PCI-E,SATA,USB等。
3.1.3 驅(qū)動程序
對于不同的設(shè)備控制器,進(jìn)行的操作控制也是不同的。所以需要專門的軟件對他進(jìn)行控制。這個軟件的作用就是用來專門和設(shè)備控制器對話,這種軟件稱為驅(qū)動程序。一般來說驅(qū)動程序由硬件設(shè)別廠商提供。所以我們有時會碰到一些設(shè)備因?yàn)闆]有安裝驅(qū)動程序而無法使用的情況。 而目前的OS總都包含了大量的通用驅(qū)動程序,使得我們在安裝完系統(tǒng)后不需要在額外的安裝驅(qū)動。但是通用的驅(qū)動只能使用設(shè)備的基本功能。
驅(qū)動程序因?yàn)槭欠遣僮飨到y(tǒng)廠商開發(fā),并且需要被安裝到操作系統(tǒng)并調(diào)用,所以需要有一個統(tǒng)一的模型來開發(fā)驅(qū)動程序。否則操作系統(tǒng)是無法操作各式各樣的設(shè)備的。前面我們知道設(shè)備非為兩大類,所以一般操作系統(tǒng)都定義了這兩類設(shè)備的標(biāo)準(zhǔn)接口。
3.1.4 內(nèi)存映射I/O
每個控制器都有幾個寄存器和CPU進(jìn)行通信。通過寫入這些寄存器,可以命令設(shè)備發(fā)送或接受數(shù)據(jù),開啟或關(guān)閉。而通過讀這些寄存器就能知道設(shè)備的狀態(tài)。因?yàn)榧拇嫫鲾?shù)量和大小是有限的,所以設(shè)備一般會有一個RAM的緩沖區(qū),來存放一些數(shù)據(jù)。比如硬盤的讀寫緩存,顯卡的顯存等。一方面提供數(shù)據(jù)存放,一方面也是提高I/O操作的速度。
現(xiàn)在的問題是CPU如何和這些設(shè)備的寄存器或數(shù)據(jù)緩沖區(qū)進(jìn)行通信呢?存在兩個可選方案:
為每個控制器分配一個I/O端口號,所有的控制器可以形成一個I/O端口空間。存放在內(nèi)存中。一般程序不能訪問,而OS通過特殊的指令和端口號來從設(shè)備讀取或是寫入數(shù)據(jù)。早期計算機(jī)基本都是這種方式。
將所有控制器的寄存器映射到內(nèi)存空間,于是每個設(shè)備的寄存器都有一個唯一的地址。這種稱為內(nèi)存映射I/O。
另一種方式是兩種的結(jié)合,寄存器擁有I/O端口,而數(shù)據(jù)緩沖區(qū)則映射到內(nèi)存空間。Pentinum就是使用這種方式,所以在IBM-PC兼容機(jī)中,內(nèi)存的0-640K是I/O端口地址,640K-1M的地址是保留給設(shè)備數(shù)據(jù)緩沖區(qū)的。(關(guān)于內(nèi)存分布后面文章會介紹)
對于我們程序員來說這兩種方案有所不同
對于第一種方式需要使用匯編語言來操作,而第2種方式則可以使用C語言來編程,因?yàn)樗恍枰厥獾闹噶羁刂疲瑢Υ齀/O設(shè)備和其他普通數(shù)據(jù)訪問方式是相同的。
對于I/O映射方式,不需要特殊的保護(hù)機(jī)制來組織對I/O的訪問,因?yàn)镺S已經(jīng)完成了這部分工作,不會把這一段內(nèi)存地址分配給其他程序。
對于內(nèi)存可用的指令,也能使用在設(shè)備的寄存器上。
任何技術(shù)有有點(diǎn)就會有缺點(diǎn),I/O內(nèi)存映射也一樣:
前面提到過Cache可以對內(nèi)存進(jìn)行緩存,但是如果對I/O映射的地址空間進(jìn)行緩存就會有問題。所以必須有機(jī)制來禁用I/O映射空間緩存,這就增大了OS的復(fù)雜性。
另一個問題是,因?yàn)榘l(fā)送指令后需要判斷是內(nèi)存還是I/O操作,所以它們需要能夠檢查全部的內(nèi)存空間。以前CPU,內(nèi)存和I/O設(shè)備在同一個總線上,所以檢查很方便。但是后來為了提高CPU和內(nèi)存效率,CPU和內(nèi)存之間有一條高速的總線(比如QPI)。這樣I/O設(shè)備就無法查看內(nèi)存地址,因?yàn)閮?nèi)存地址總線旁落到了內(nèi)存和CPU的高速總線上,所以需要一個額外的芯片來處理(北橋芯片,內(nèi)存控制器的作用),增大了系統(tǒng)的復(fù)雜度。
3.2 CPU和I/O設(shè)備數(shù)據(jù)交換方式
前面已經(jīng)知道CPU通過內(nèi)存映射的方式和I/O設(shè)備交換數(shù)據(jù),但是對于CPU來說,無論是從內(nèi)存還是I/O設(shè)備讀取數(shù)據(jù),都需要把地址放到地址總線上,然后在向控制總線傳遞一個READ信號,還要用一條信號線來表示是從內(nèi)存還是I/O讀取數(shù)據(jù)。因?yàn)镮/O映射的內(nèi)存區(qū)域是特定的,所以不存在無法區(qū)分是內(nèi)存還是I/O操作。目前一共有3種方式進(jìn)行操作:
程序控制I/O: CPU在向I/O設(shè)備發(fā)出指令后,通過程序查詢方式檢查I/O設(shè)備是否完成工作,如果完成就讀取數(shù)據(jù),這種方式缺點(diǎn)是CPU在I/O設(shè)備工作時被占用。
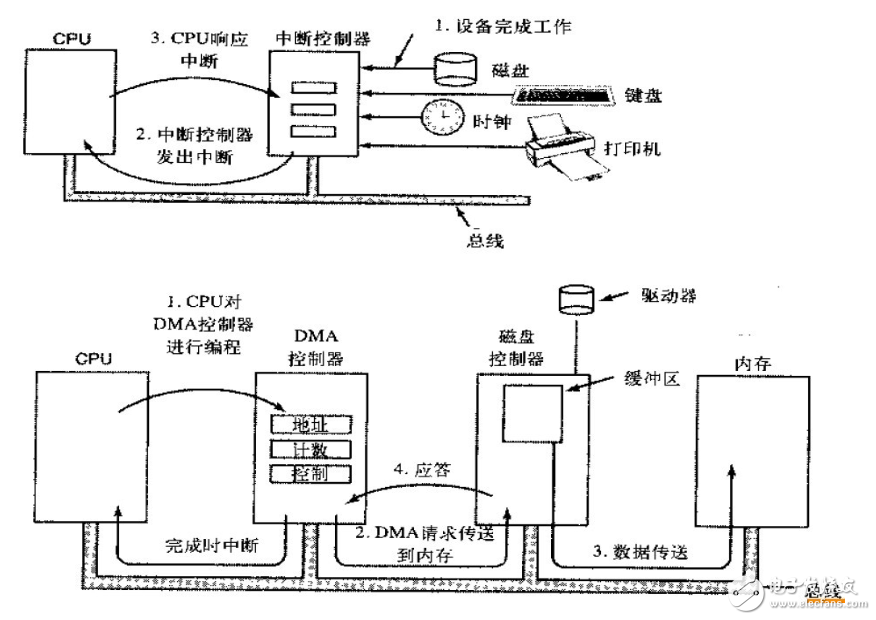
中斷驅(qū)動I/O: CPU是稀缺資源,所以為了提高利用率,減少I/O等待。在I/O設(shè)備工作時CPU不再等待,而是進(jìn)行其他的操作,當(dāng)I/O設(shè)備完成后,通過一個硬件中斷信號通知CPU。CPU在來處理接下來的工作,比如讀取數(shù)據(jù)存放到內(nèi)存。但是每次只能請求一個字節(jié),效率很低。
DMA: Direct Memory Access利用一種特性的芯片存在于CPU和I/O設(shè)備之間。CPU需要操作I/O設(shè)備時只需要發(fā)送消息給DMA芯片,后面的事情全部內(nèi)又DMA來完成,當(dāng)把所需要數(shù)據(jù)放入內(nèi)存后在通知CPU進(jìn)行操作,整個過程DMA直接和內(nèi)存總線打交道,而CPU也只需要和DMA芯片和內(nèi)存交互,大大提高了速度。
總結(jié)
這一篇文章介紹了計算機(jī)組件中的存儲器的分類和工作原理,以及I/O設(shè)別的工作方式。通過總線將各個部件連接起來。我們可以看到計算機(jī)的發(fā)展不光是CPU,存儲器以及I/O設(shè)備的發(fā)展,總線也是起了非常關(guān)鍵的作用。通過前2章的介紹,應(yīng)該對計算機(jī)硬件的工作原理有了大概的了解。后面開始將主要偏向計算機(jī)操作系統(tǒng)軟件的工作方式。當(dāng)然這些也是和一些硬件的特性分不開的。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論