 電子發(fā)燒友App
電子發(fā)燒友App


近日,中央計算架構(gòu)委員會組織了一次年中團(tuán)建,邀請各分委會的兄弟們來火焰山避暑,順便聊聊汽車下一代中央計算架構(gòu)的實施進(jìn)展。
首先登場的是趾高氣揚(yáng)的SOC兄弟,還沒等進(jìn)門,就開始喊道:外面傳感器是越來越多,數(shù)據(jù)量也是越來越大,還都想把原始數(shù)據(jù)送過來;我把拜把子兄弟都喊過來幫忙了,可高達(dá)Gbps級別的數(shù)據(jù),我該如何與拜把子兄弟們實時交互信息呢?
接著登場的是大腹便便的存儲兄弟,好不容易坐穩(wěn),一臉愁容的說道:各位看我體型也能猜出我甜蜜的煩惱了吧,什么高精地圖數(shù)據(jù),外部傳感器數(shù)據(jù),內(nèi)部智能座艙數(shù)據(jù)全都需要我存儲,存慢了就背鍋,誰有什么好方法讓SOC給我的數(shù)據(jù)傳的快點呀。
其他小弟默默無語,兩位大佬的問題不解決,中央計算架構(gòu)似乎很難有所進(jìn)展,而兩位大佬問題的共同點就是:如何解決下一代中央計算架構(gòu)下的片內(nèi)高速實時通信需求。業(yè)內(nèi)給出的一種解決方案就是PCIE。
PCIE簡介
2001年初,Intel提出要采用新一代的總線技術(shù)來連接內(nèi)部多種芯片,并取代當(dāng)時使用的PCI總線,并稱之為第三代輸入輸出技術(shù)(3GIO技術(shù))。2001底,雷厲風(fēng)行的Intel就聯(lián)合AMD、DELL、IBM等20多家業(yè)內(nèi)主導(dǎo)公司開始起草新技術(shù)的規(guī)范,并于2002年完成,這種新的總線標(biāo)準(zhǔn)對外正式命名為PCI Express(PCIE/PCI-E)。
PCIE(Peripheral Component Interconnect Express)是一種全雙工、端到端、串行、高速可擴(kuò)展通信總線標(biāo)準(zhǔn)。
全雙工,是指允許設(shè)備在同一時刻,既可以發(fā)送數(shù)據(jù)也可以接收數(shù)據(jù)。這就好比一條雙向車道,南來的北往的互不干擾。而實現(xiàn)總線上數(shù)據(jù)發(fā)送或接收的物理介質(zhì)是一對差分線,接收端通過比較兩根線上信號的差值,來判斷發(fā)送端發(fā)送的是“邏輯0”還是“邏輯1”。采用差分信號傳輸,可以極大提高抗干擾能力,從而大幅提升傳輸頻率。而這樣的兩對發(fā)送和接收組成的一個差分回路(總共4條線),被稱為1xLane,如圖1所示。
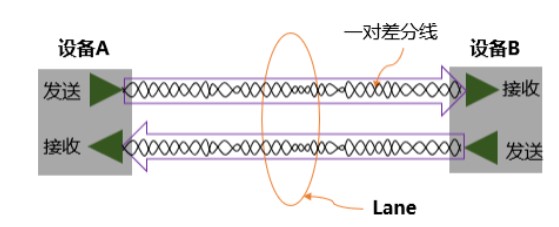
圖1 1xLane結(jié)構(gòu)示意圖
端到端,指的是一條PCIE鏈路(Link)兩端只能各連接一個設(shè)備,這兩個設(shè)備互為數(shù)據(jù)的發(fā)送端和接收端,如圖2的設(shè)備A和設(shè)備B。而一條Link可以由多條上文介紹的Lane組成,這就好比雙向道路中,每一向道路中又可以包含多條車道。常見的Lane有x1,x2,x4,x8,x16,x32等。
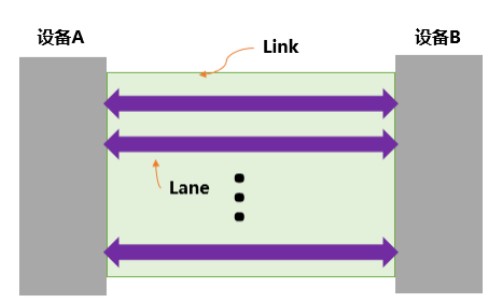
圖2 一條PCIE鏈路
串行,數(shù)據(jù)一位一位的依次傳輸,每一位占據(jù)一個固定的時間長度。有點電子學(xué)基礎(chǔ)的朋友可能要問,為什么不采用并行方式呢,一個固定時間長度,能同時傳輸8/16/32bit…,傳輸速率不是更快嗎?巧了,PCIE的眾多總線前輩們采用的也的確是并行方式。
采用并行的方式,數(shù)據(jù)通常在公共時鐘周期的第一個上升沿將數(shù)據(jù)發(fā)送出去,數(shù)據(jù)通過傳輸介質(zhì)到達(dá)接收端,接收端在公共時鐘周期的第二個上升沿對數(shù)據(jù)進(jìn)行采集,發(fā)送和接收正好經(jīng)歷一個公共時鐘周期。也就說在這一個公共時鐘周期內(nèi),發(fā)送端的發(fā)送數(shù)據(jù)必須保持不變,以保證接收端可以正確的采樣。
在并行方式下,公共時鐘周期必須大于數(shù)據(jù)在傳輸介質(zhì)中的傳輸時間(數(shù)據(jù)從發(fā)送端到接收端的時間),否則也將無法正確采樣。而并行方式中有幾十根數(shù)據(jù)線,要遵循木桶原理,即保證數(shù)據(jù)傳輸最慢的那根數(shù)據(jù)線滿足公共時鐘周期,這也是為什么高速并行總線需要做等長處理。
所以并行方式要想提高傳輸速率,必須不斷提高時鐘頻率。但是受限于傳輸時間,時鐘頻率不可能非常高。同時隨著頻率越來越高,并行的連線相互干擾異常嚴(yán)重,已經(jīng)到了不可跨越的程度。再加上時鐘相位偏移等因素,導(dǎo)致采用并行方式并不能滿足越來越高的數(shù)據(jù)傳輸速率要求。
而采用串行的方式便可完美解決上述問題,時鐘信號和數(shù)據(jù)信號一同編碼在同一數(shù)據(jù)流中,數(shù)據(jù)流一位一位的傳輸,接收端從數(shù)據(jù)流中恢復(fù)時鐘信息。由于沒有時鐘線,也就不存在時鐘相位偏移。再加上數(shù)據(jù)包分解、標(biāo)記和重組技術(shù)的進(jìn)步,使得串行傳輸數(shù)據(jù)的速度可以越來越快。
高速,PCIE目前已經(jīng)正式發(fā)布6個標(biāo)準(zhǔn)版本,最新的為PCIE 6.0,其傳輸速率基本上遵循了下一代比上一代翻倍的定律。我們首先以PCIE 1.0來舉例介紹下傳輸速率與我們更常用的帶寬單位之間的關(guān)系。
PCIE標(biāo)準(zhǔn)中用GT/s(GigaTransfers per second,一秒內(nèi)電位變化的次數(shù))表示傳輸速率,而一次電位變化從數(shù)據(jù)角度來說就相當(dāng)于傳輸了一個Bit。但是PCIE的電位變化并不全都用來傳輸有效數(shù)據(jù),里面還包含了時鐘信號。PICE 1.0采用的8/10b編碼,就包含了2位時鐘信號,這意味著傳輸8位有效數(shù)據(jù)要經(jīng)歷10次電位變化。(注:PCIE 3.0以前使用8/10b編碼,PCIE 3.0及以后版本使用120/130b編碼。)
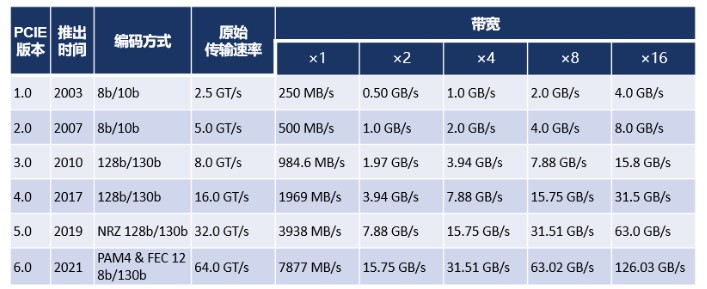
PCIE 1.0標(biāo)準(zhǔn)中Lanex1的傳輸速率為2.5GT/s,換算成GBps為2GBps(2.5x8/10),換算成MB/s為250MB/s(2/8x1000),x2,x4,x8,x16依次類推。表1給出了PCIE 1.0到6.0不同Lane下的帶寬數(shù)據(jù)。PCIE 6.0在Lanex16時可以提供高達(dá)126GB/s的帶寬,這不就是汽車直男的心動女生嗎。
表1 PCIE 1.0到6.0不同Lane下的帶寬數(shù)據(jù)
而在2022年P(guān)CI-SIG開發(fā)者大會上,PCIE接口標(biāo)準(zhǔn)委員會PCI-SIG就公布了PCIE 7.0的規(guī)范目標(biāo),稱其數(shù)據(jù)速率高達(dá)128 GT/s,并在2025年向其成員發(fā)布。這相當(dāng)于在編碼開銷之前,通過16通道 (x16) 連接能實現(xiàn)512 GB/s的雙向吞吐量。
PCIE拓?fù)浣Y(jié)構(gòu)
一、基于x86計算機(jī)系統(tǒng)
PCIE總線在x86計算機(jī)系統(tǒng)中作為局部總線,主要用來連接處理器系統(tǒng)中的外部設(shè)備。在x86計算機(jī)系統(tǒng)中,PCIE設(shè)備主要包括根復(fù)合體(Root Complex,RC),交換機(jī)(Switch),終端設(shè)備(Endpoingt),PCIE到PCI/PCI-X的橋(Bridge)等。一個典型的基于x86計算機(jī)系統(tǒng)的PCIE拓?fù)浣Y(jié)構(gòu)如圖3所示。
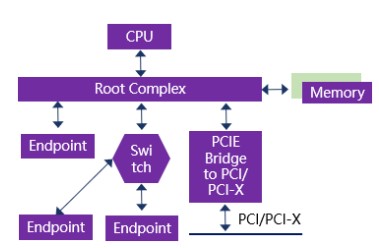
圖3 基于x86計算機(jī)系統(tǒng)的PCIE拓?fù)浣Y(jié)構(gòu)
RC將PCIE總線端口、存儲器等一系列與外部設(shè)備有關(guān)的接口都集成在一起。CPU平時比價忙,便會把很多事情交給RC去做,比如訪問內(nèi)存,通過內(nèi)部PCIE總線及外部Bridge拓展出若干個其他的PCIE端口。
Endpoint作為終端設(shè)備,可以是PCIE SSD、PCIE網(wǎng)卡等,既可以掛載到RC上,也可以掛載到Switch上。
Switch擴(kuò)展了PCIE端口,可以將數(shù)據(jù)由一個端口路由到另一個端口,從而實現(xiàn)多設(shè)備的互聯(lián),具體的路由方法包括ID路由,地址路由,隱含路由。靠近RC的端口稱為上游端口,擴(kuò)展出來的端口稱為下游端口。下游端口可以掛載其他Switch或者Endpoint,并且對他們進(jìn)行管理。
從上游過來的數(shù)據(jù),它需要鑒定:(1)否是是傳給自己的數(shù)據(jù),如果是便接收;(2)是不是自己下游端口的數(shù)據(jù),如果是便轉(zhuǎn)發(fā);(3)如果都不是,便拒絕。從下游端口掛載的Endpoint傳給RC的數(shù)據(jù),Switch會進(jìn)行相應(yīng)的仲裁,確定數(shù)據(jù)的優(yōu)先級,并將優(yōu)先級高的數(shù)據(jù)傳送到上游端口中去。
Bridge則是用來實現(xiàn)PCIE設(shè)備與PCI/PCI-X設(shè)備之間的連接,實現(xiàn)兩種不同協(xié)議之間的相互轉(zhuǎn)換。
二、基于汽車
汽車電子電氣架構(gòu)的多樣性,導(dǎo)致很難有像x86一樣的統(tǒng)一架構(gòu)。而基于中央計算架構(gòu),Mircochip曾給出過一種架構(gòu)方案,如圖4所示。
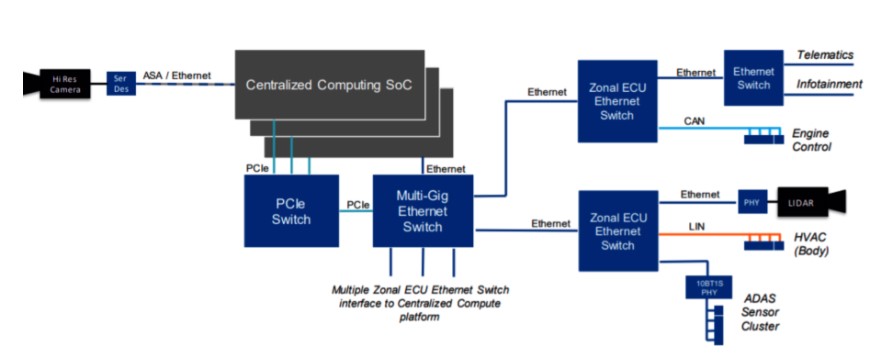
圖4 汽車上的一種PCIE架構(gòu)
在此架構(gòu)中,PCIE Switch串聯(lián)起整個片內(nèi)通信。中央計算單元中的不同SOC,Ethernet Switch等均掛載其上面。外部傳感器通過Zonal ECU的Ethernet Switch串聯(lián)在一起。
PCIE分層體系
在PCIE總線中,數(shù)據(jù)報文在接收和發(fā)送過程中,需要經(jīng)歷三層蹂躪,包括事務(wù)層(Transaction Layer)、數(shù)據(jù)鏈路層(Data Link Layer)和物理層(Physical Layer)。各層又都包含發(fā)送和接收兩塊功能。這種分層的體系結(jié)構(gòu)和網(wǎng)絡(luò)的經(jīng)典七層模型有異曲同工之妙,但不同的是,PCIE總線中每一層都是使用硬件邏輯實現(xiàn)的。
工作流程如圖5所示,數(shù)據(jù)報文首先在設(shè)備A的核心層中產(chǎn)生,然后再經(jīng)過該設(shè)備的事務(wù)層、數(shù)據(jù)鏈路層和物理層,最終發(fā)送出去。而接收端的數(shù)據(jù)也需要通過物理層、數(shù)據(jù)鏈路層和事務(wù)層,并最終到達(dá)設(shè)備B的核心層。
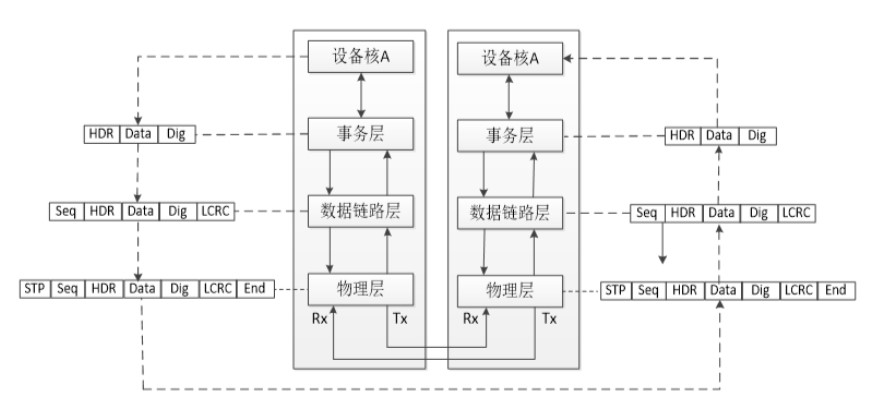
圖5 PCIE工作流程
一、事務(wù)層。
事務(wù)層位于PCIE分層體系的最高層,一方面接收設(shè)備核心層的數(shù)據(jù)請求,封裝為TLP(Transaction Layer Packet)并在TLP頭中定義好總線事務(wù)后,發(fā)送給數(shù)據(jù)鏈路層。另一方面,從數(shù)據(jù)鏈路層中接收數(shù)據(jù)報文,掐頭去尾保留有效數(shù)據(jù)后轉(zhuǎn)發(fā)至PCIE設(shè)備核心層。
PCIE中定義的總線事務(wù)有存儲器讀寫、I/O 讀寫、配置讀寫、Message總線事務(wù)和原子操作等總線事務(wù)。這些總線事務(wù)可以通過Switch等設(shè)備傳送到其他PCIE設(shè)備或者RC。RC也可以使用這些總線事務(wù)訪問PCIE設(shè)備。
以存儲器讀為例,網(wǎng)絡(luò)中某個有需求的Endpoint初始化該請求后發(fā)送出去,請求經(jīng)過Switch之后到達(dá)RC,RC收到存儲器讀請求后在系統(tǒng)緩存中抓取數(shù)據(jù)并回傳完成報告。完成報告同樣經(jīng)過Switch后到達(dá)Endpoint,Endpoint收到完成報告后結(jié)束此次事務(wù)請求。
事務(wù)層還使用流量控制機(jī)制來保證PCIE鏈路的使用效率。
二、數(shù)據(jù)鏈路層
數(shù)據(jù)鏈路層在PCIE總線中發(fā)揮著承上啟下的作用。來自事務(wù)層的報文在通過數(shù)據(jù)鏈路層時,將被添加Sequence Number前綴和CRC后綴,并使用ACK/NAK協(xié)議保證來自發(fā)送端事務(wù)層的報文可以可靠、完整地發(fā)送到接收端的數(shù)據(jù)鏈路層。來自物理層的報文在經(jīng)過數(shù)據(jù)鏈路層時,會被剝離Sequence Number前綴和CRC后綴再被發(fā)送到事件層。
PCIE總線的數(shù)據(jù)鏈路層還定義了多種DLLP(Data Link Layer Packet),DLLP產(chǎn)生于數(shù)據(jù)鏈路層,終止于數(shù)據(jù)鏈路層。值得注意的是,TLP與DLLP并不相同,DLLP并不是由TLP加上Sequence Number前綴和CRC后綴組成的。
三、物理層
物理層是PCIE總線的最底層,將PCIE設(shè)備連接在一起。PCIE總線的物理電氣特性決定了PCIE鏈路只能使用端到端的連接方式。PCIE總線的物理層為PCIE設(shè)備間的數(shù)據(jù)通信提供傳送介質(zhì),為數(shù)據(jù)傳送提供可靠的物理環(huán)境。
物理層是PCIE體系結(jié)構(gòu)最重要,也是最難以實現(xiàn)的組成部分。PCIE總線的物理層定義了LTSSM(Link Training and Status State Machine)狀態(tài)機(jī),PCIE鏈路使用該狀態(tài)機(jī)管理鏈路狀態(tài),并進(jìn)行鏈路訓(xùn)練、鏈路恢復(fù)和電源管理。
PCIE總線的物理層還定義了一些專門的“序列”,有的書籍將物理層這些“序列”稱為PLP(Phsical Layer Packer),這些序列用于同步PCIE鏈路,并進(jìn)行鏈路管理。值得注意的是PCIE設(shè)備發(fā)送PLP與發(fā)送TLP的過程有所不同。對于系統(tǒng)軟件而言,物理層幾乎不可見,但是系統(tǒng)程序員仍有必要較為深入地理解物理層的工作原理。
汽車領(lǐng)域應(yīng)用案例
一、理想
從網(wǎng)絡(luò)上公開資料獲悉,理想2023年要上市的新車,除了采用800V純電平臺,還將采用其最新的第三代架構(gòu)LEEA3.0,如圖6所示。LEEA3.0為中央計算平臺+區(qū)域控制架構(gòu),中央計算平臺很有可能采用類似工控機(jī)的模塊化方案,將實現(xiàn)智能車控、自動駕駛和智能座艙功能的三塊板子通過高性能交換機(jī)連接在一起,并設(shè)計到一套殼體中,有點類似特斯拉HW3.0的松耦合方案。
而高性能交換機(jī)的方案有兩種,一種是PCIE Switch,一種是TSN Switch。PCIE Switch主要充當(dāng)算力芯片之間“話事人”,通過提供20Gb/s以上的端到端的數(shù)據(jù)傳輸帶寬,可以解決高帶寬、低延時的痛點需求。同時通過物理隔離,單點失效將不會影響系統(tǒng)失效。TSN Switch主要充當(dāng)與安全芯片及區(qū)域控制器的通信,提供時間確定性的數(shù)據(jù)流轉(zhuǎn)發(fā)和數(shù)據(jù)交換。
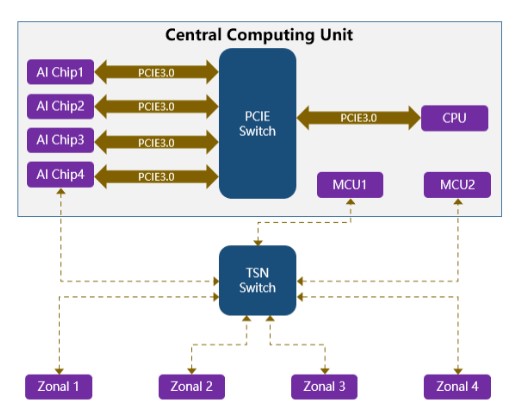
圖6 ?LEEA3.0原理示意圖(圖片來源:基于網(wǎng)絡(luò)公開資料整理)
二、Mircochip
2020年9月,Microchip在一期《Inter-Processor Connectivity for Future Centralized Vehicle Computer Platforms》分享中,共享了其對下一代中央計算平臺的一些觀點。什么區(qū)域配合計算中心、SOA、以太網(wǎng),都是寫老掉牙的話題,沒什么新意。但在提到下一代架構(gòu)以太網(wǎng)帶寬的挑戰(zhàn)時,預(yù)測中央計算平臺中送入的數(shù)據(jù)量將達(dá)到200Gbps(說實話我愣是沒估算出來,大家看下面圖自己領(lǐng)悟吧),如圖7所示。
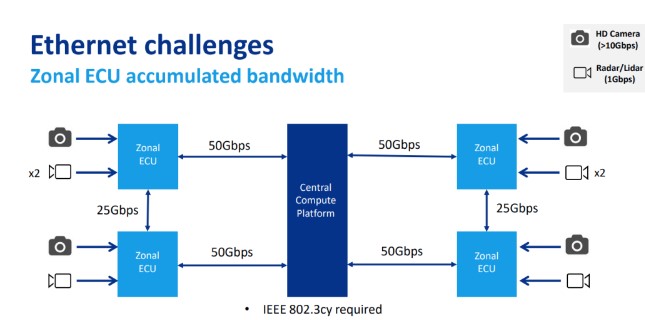
圖7 以太網(wǎng)面臨的帶寬挑戰(zhàn)(來源:Microchip官方材料)
中央計算單元為了解決這么大數(shù)據(jù)的涌入問題,必須采用PCIE。PCIE可掛載的Endpoint如圖8所示。
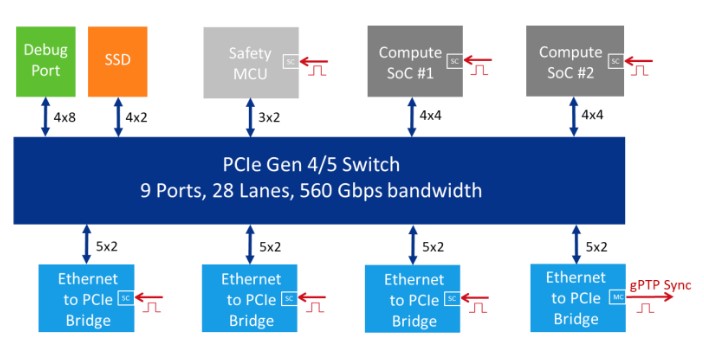
圖8 PCIE掛載節(jié)點示意圖(來源:Microchip官方材料)
基于以上需求,2022年2月,Mircochip宣布推出市場上首款通過汽車級認(rèn)證的第四代PCIE交換機(jī),提供了一種面向分布式異構(gòu)計算系統(tǒng)的高速、低延遲連接解決方案,主要用于提供連接ADAS內(nèi)CPU和加速器所需的最低延遲和高帶寬性能。
審核編輯:劉清












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論