 電子發燒友App
電子發燒友App


Cortex-M3的異常處理機制分析
?詳細闡述CortexM3異常的分類、優先級、進入和退出,以及在CortexM3異常處理機制中使用的新技術——遲到(late?arriving)和尾鏈(tail?chaining);最后,比較CortexM3和ARM7異常控制機制的區別,并量化分析遲到和尾鏈技術在異常處理中的優越性。
關鍵詞? CortexM3? 異常? 遲到? 尾鏈? 中斷控制器
引言
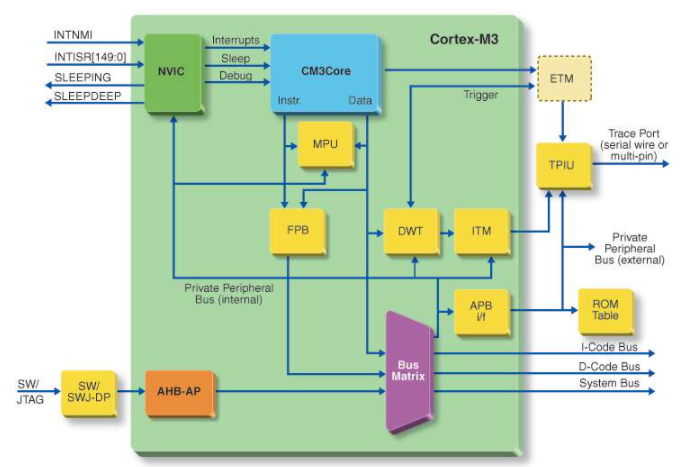
CortexM3是ARM公司第一款基于ARMv7M的微控制器內核,在指令執行、異常控制、時鐘管理、跟蹤調試和存儲保護等方面相對于ARM7有很大的區別。尤其在異常處理機制方面有很大的改進,其異常響應只需要12個時鐘周期。NVIC(Nested Vectored Interrupt Controller,嵌套向量中斷控制器)是CortexM3處理器的一個緊耦合部件,可以配置1~240個帶有256個優先級、8級搶占優先權的物理中斷,為處理器提供出色的異常處理能力[1]。同時,搶占(pre?emption)、尾鏈(tail?chaining)、遲到(late?arriving)技術的使用,大大縮短了異常事件的響應時間。
異常或者中斷是處理器響應系統中突發事件的一種機制。當異常發生時,CortexM3通過硬件自動將編程計數器(PC)、編程狀態寄存器(xPSR)、鏈接寄存器(LR)和R0~R3、R12等寄存器壓進堆棧。在Dbus(數據總線)保存處理器狀態的同時,處理器通過Ibus(指令總線)從一個可以重新定位的向量表中識別出異常向量,并獲取ISR函數的地址,也就是保護現場與取異常向量是并行處理的。一旦壓棧和取指令完成,中斷服務程序或故障處理程序就開始執行。執行完ISR,硬件進行出棧操作,中斷前的程序恢復正常執行。圖1為CortexM3處理器的異常處理流程[2]。

圖1? CortexM3異常處理流程
1? CortexM3異常類型
同ARM7相比,CortexM3在異常的分類和優先級上有很大的差異,如表1所列。
表1CortexM3異常類型及優先級
CortexM3將異常分為復位、不可屏蔽中斷、硬故障、存儲管理、總線故障和應用故障、SVcall、調試監視異常、PendSV、SysTick以及外部中斷等。CortexM3采用向量表來確定異常的入口地址。與大多數其他ARM內核不同,CortexM3向量表中包含異常處理程序和ISR的地址,而不是指令。復位處理程序的初始堆棧指針和地址必須分別位于0x0和0x4。這些值在隨后的復位中被加載到適當的CPU寄存器中。向量表偏移控制寄存器將向量表定位在CODE(Flash)或SRAM中。復位時,默認情況下為CODE模式,但可以重新定位。異常被接受后,處理器通過Ibus查表獲取地址,執行異常處理程序。
在CortexM3的優先級分配中,較低的優先級值具有較高的優先級。NVIC將異常的優先級分成兩部分:搶占優先級(pre?emption priority)部分和子優先級(sub?priority)部分,可以通過中斷申請/復位控制寄存器來確定兩個部分所占的比例。搶占優先級和子優先級共同作用確定了異常的優先級。搶占優先級用于決定是否發生搶占,一個異常只有在搶占優先級高于另一個異常的搶占優先級時才能發生搶占。當多個掛起異常具有相同的搶占優先級時,子優先級起作用[3]。通過NVIC設置的優先級權限高于硬件默認優先級。當有多個異常具有相同的優先級時,則比較異常號的大小,異常號小的被優先激活。
2? CortexM3異常處理
2.1? 異常的進入
當一個異常出現以后,CortexM3處理器由硬件通過Dbus保存處理器狀態,同時通過Ibus讀取向量表中的SP,更新PC和LR,執行中斷服務子程序。
為了應對堆棧操作階段到來后的更高優先級異常,CortexM3支持遲到和搶占機制,以便對各種可能事件做出確定性的響應。
搶占是一種對更高優先級異常的響應機制。CortexM3異常搶占的處理過程[2] 如圖2所示。當新的更高優先級異常到來時,處理器打斷當前的流程,執行更高優先級的異常操作,這樣就發生了異常嵌套。遲到是處理器用來加速搶占的一種機制。如果一個具有更高優先級的異常在上一個異常執行壓棧期間到達,則處理器保存狀態的操作繼續執行,因為被保存的狀態對于兩個異常都是一樣的。但是,NVIC馬上獲取的是更高優先級的異常向量地址。這樣在處理器狀態保存完成后,開始執行高優先級異常的ISR。

圖2? 異常搶占流程
2.2? 異常的返回
CortexM3異常返回的操作[2]如圖3所示。當從異常中返回時,處理器可能會處于以下情況之一[4]:
◆ 尾鏈到一個已掛起的異常,該異常比棧中所有異常的優先級都高;
◆ 如果沒有掛起的異常,或是棧中最高優先級的異常比掛起的最高優先級異常具有更高的優先級,則返回到最近一個已壓棧的ISR;
◆ 如果沒有異常已經掛起或位于棧中,則返回到Tread模式。
為了應對異常返回階段可能遇到的新的更高優先級異常,CortexM3支持完全基于硬件的尾鏈機制,簡化了激活的和未決的異常之間的移動,能夠在兩個異常之間沒有多余的狀態保存和恢復指令的情況下實現back?to?back處理。尾鏈發生的2個條件[2]: 異常返回時產生了新的異常;掛起的異常的優先級比所有被壓棧的異常的優先級都高。
尾鏈發生后,CortexM3處理過程如圖3中尾鏈分支所示。這時,CortexM3處理器終止正在進行的出棧操作并跳過新異常進入時的壓棧操作,同時通過Ibus立即取出掛起異常的向量。在退出前一個ISR返回操作6個周期后,開始執行尾鏈的ISR。

圖3? 異常的返回
3? CortexM3和ARM7中斷控制器比較
在過去的十年中,基于ARMv4的ARM7系列微控制器廣泛應用在各個領域。在ARM7系列中,并沒有對中斷進行獨立的服務,而是通過犧牲處理器一定的性能來換取有效的中斷響應和中斷處理機制。CortexM3高度耦合的NVIC可以實現硬件中斷處理,同時支持遲到和尾鏈機制,加快了異常響應的速度,充分發揮了處理器的性能。
圖4 為CorexM3和ARM7在中斷控制器結構方面的差異。
比較可知,NVIC是直接作為CortexM3處理器的一部分,集成在處理器核內部;而VIC只是游離在ARM7內核的外圍,這樣就必然占用內核資源,影響了處理速度。CortexM3和ARM7中斷控制器在功能和實現方式上的差異如表2所列。

圖4? CortexM3和ARM7中斷控制器結構的差異
表2? CortexM3和ARM7中斷控制器功能和實現方式的差異
3.1? 處理器響應單個異常
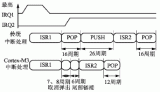
CortexM3和ARM7異常處理過程如圖5所示。

圖5? CortexM3和ARM7異常處理過程
ARM7處理器的異常開銷:

CortexM3處理器的異常開銷:

其中,TARM7為ARM7處理異常的時間開銷;TARM7_PUSH和TARM7_POP為ARM7進行壓棧和出棧的操作時間;TCoretxM3為CortexM3處理異常的時間開銷;TM3_PUSH和TM3_POP為CortexM3進行壓棧和出棧的操作時間。
可見,由于采用處理器狀態硬件保存,CortexM3處理器少用了18周期,節省了42.8%的異常開銷。
3.2? 處理器響應遲到異常
CortexM3和ARM7在處理遲到高優先級異常時的差異如圖6所示。
當IRQ2正在為執行ISR2保存處理器狀態時,遲到了一個優先級更高的異常IRQ1。這時ARM7繼續進行壓棧操作。在壓棧操作完成后,ARM7繼續為執行ISR1進行壓棧操作,然后執行ISR1。其實,兩次壓棧操作所保存的內容是一樣的。因此,CortexM3對這個階段的操作進行了優化,引進了遲到異常技術,只進行一次的壓棧操作。并且在ISR1執行完成之后,CortexM3沒有進行出棧操作,而是通過一個6周期的尾鏈,直接進入ISR2的執行。

圖6? NVIC對遲到的具有更高優先級異常的響應
在上面的例子中,ARM7處理器的異常開銷:

CortexM3處理器的異常開銷:

其中,TARM7_later和TM3_later分別為ARM7和CortexM3處理遲到異常所用的時間開銷;Ttailchaining為CortexM3處理尾鏈所用的時間。
通過計算可以看出,CortexM3少用了44周期,節省65%的異常開銷。
3.3? 處理器處理back?to?back異常
若一個新的異常在上一個異常寄存器出棧時到來,ARM7和CortexM3的處理方式也有很大不同。CortexM3和ARM7在處理back?to?back異常時的差異如圖7所示。ARM7繼續當前的出棧操作,在出棧操作完成后,處理器為執行ISR2進行壓棧操作,然后執行ISR2。其實,這時候處理器出棧和壓棧的內容是一致的。CortexM3同樣優化了這個階段的操作,引進了尾鏈機制。當IRQ2到來時,CortexM3立即中止已經進行了8個周期的出棧操作,轉而進行尾鏈操作,然后執行ISR2。

圖7? NVIC搶占出棧
在處理back?to?back異常時,ARM7處理器用在ISR1到ISR2轉換的異常開銷:

CortexM3處理器用在ISR1到ISR2轉換的異常開銷:

其中,TARM_btb和TM3_btb分別為ARM7和CortexM3處理back?to?back異常轉換所用的時間開銷;Tcancel為發生尾鏈時CortexM3已用于狀態恢復的時間。
通過計算可以看出,CortexM3少用了28周期。其實,CortexM3處理器用在ISR1到ISR2轉換的異常開銷最低可以優化到只用6個周期, 這樣就極大地提高了back?to?back異常的響應能力。
結語
本文闡述了CortexM3處理器的異常處理機制。通過和ARM7進行比較,量化分析了CortexM3在異常處理方面的優勢,對工程師使用CortexM3的異常處理會有一定參考和幫助。










 工商網監
工商網監
評論