 電子發(fā)燒友App
電子發(fā)燒友App


采用硬件加速發(fā)揮MicroBlaze處理能力
MicroBlaze處理器是賽靈思(Xilinx)在嵌入式開發(fā)套件 (EDK) 中提供的兩款32位內核之一,是實現硬件加速的靈活工具。圖1是MicroBlaze的典型設計。該內核含有一個32位乘法器,但不含浮點單元(FPU)、桶式移位器或專用硬件加速器。對Xilinx公司Spartan FPGA 器件而言,默認系統(tǒng)含有區(qū)域優(yōu)化的MicroBlaze(采用三級流水線),但大多數客戶通常在開始時使用速度優(yōu)化版(采用五級流水線)進行性能評估,其優(yōu)點是小巧簡潔,易于擴展。

Xilinx客戶針對這種處理器設計所要求的兩個實際應用案例可說明MicroBlaze在硬件加速方面的作用。本文以 Spartan 器件為重點,比較 FPGA 解決方案和標準控制器內核,展現我們能夠達到的性價比。這一方法同樣適用于Virtex FPGA。
案例1:實施位反轉算法
在第一個應用示例中,假定MicroBlaze處理器的運行速度僅為50MHz。采用 Spartan-3或Spartan-6器件可輕松實現這一速度。諸如本地存儲器總線(指令和數據,LMB)以及處理器本機總線(PLB)等所有內部總線的運行速度均達到50MHz。為簡單起見,假定沒有連接外部DDR存儲器。
現在假設客戶想要在這個CPU上實施位反轉算法。MicroBlaze自身沒有通過硬件直接提供這個功能。再假定每秒需要完成2萬次位反轉操作。
要解決這個問題,大多數客戶首先會采用純軟件方案,因為這樣可輕松地實現想要的功能。而且如果性能足夠高,無需進行任何修改。
為此,讓我們先從簡單的軟件算法出發(fā),實施簡短精悍的解決方案。結果確實簡單、精巧而且容易理解,不過效率很低。
unsigned int v=value;
unsigned int r = v;
int s = sizeof(v) * CHAR_BIT - 1;
for (v >>= 1; v; v >>= 1)
{
r <<= 1;
r |= v & 1;
s--;
}
r <<= s;
return r;
這段程序運行相當順利,不過就算在專門針對速度優(yōu)化的MicroBlaze(使用五級流水線)上運行處理一個32 位字的算法,也用了220個周期。要執(zhí)行2萬次位反轉操作,在速度為50MHz的MicroBlaze上約需88ms。
客戶試圖采用略有不同的方法來優(yōu)化算法,但仍作為純軟件解決方案來實施。
要進一步提升性能,就要采用純硬件解決方案,通過一種新的方式來讓硬件加速器充分發(fā)揮性能。
為了加速這種基礎操作,只需要在MicroBlaze快速單工鏈路(FSL)上連接一個非常簡單的內核。標準FSL實施方案使用FSL總線(包括同步或異步FIFO)將數據從 MicroBlaze內核傳輸到FSL 硬件加速器IP核。帶FIFO 的FSL總線與FIFO可對上述兩者間的數據存取進行去耦。
如果采用帶FIFO的標準FSL總線,則一般情況下執(zhí)行時間為4個周期:一個周期用來將MicroBlaze上的數據通過FSL寫入FIFO;一個周期用來將數據從FIFO 傳輸到FSL IP;一個周期用來把結果從FSL IP傳送回 FSL總線的FIFO中;最后一個周期則負責從FSL總線讀出結果并傳輸至 MicroBlaze。
MicroBlaze到FSL總線的連接以及FSL總線到FSL IP的連接可在EDK的圖形視圖中輕松創(chuàng)建。
這樣代碼要長得多,效率也有大幅度提升,但時間還是太長了,執(zhí)行2萬次操作現在仍然大概需要52ms。
隨后客戶在互聯網上進行了一些調查,找到一種更好的算法,把代碼改編為:
unsigned x = value;
?? unsigned r;
?? x = (((x & 0xaaaaaaaa) >> 1) | ((x
& 0x55555555) << 1));
?? x = (((x & 0xcccccccc) >> 2) | ((x
& 0x33333333) << 2));
x = (((x & 0xf0f0f0f0) >> 4) | ((x
& 0x0f0f0f0f) << 4));
x = (((x & 0xff00ff00) >> 8) | ((x
& 0x00ff00ff) << 8));
r = ((x >> 16) | (x << 16));
return r;
這個代碼看起來效率高,短小精悍。而且它不需要會造成流水線中斷的分支。它在這個核心系統(tǒng)上運行只需29 個周期。
不過這個算法需要在1 、2、4、8和16位之間進行移位操作。我們在MicroBlaze的屬性窗口中激活桶式移位器。不管移位操作的長度如何,采用桶式移位器可允許我們在一個周期內完成移位指令。這樣可以讓純軟件算法在 MicroBlaze上運行得稍快一些。
激活MicroBlaze硬件上的桶式移位器可將處理算法所需時間縮短到22個周期。與第一個版本的軟件算法相比,此算法得到了顯著改善。目前采用此算法,執(zhí)行所有 2萬次操作只需8.8ms,效率提升了10倍,不過仍未達到客戶要求。
不過效率還有提升的空間。算法中的時延非常關鍵,應盡可能地縮短。但在我們的實施方案中,采用兩根FSL總線仍需要四個時鐘周期。不過我們可以通過將 MicroBlaze與硬件加速器之間的現有連接方式改為直接連接,便可將時延減半,縮短至兩個時鐘周期。這樣一個周期用于將數據寫入 FSL硬件加速器IP,而另一個周期則負責讀回結果。
在采用直接連接方式時,需注意幾個問題。首先,協處理器IP應存儲輸入,并以寄存方式提供結果。請注意在執(zhí)行此操作時沒有使用帶FIFO的FSL總線。
此外,以不同時鐘速率運行 MicroBlaze和FSL硬件加速器IP 容易發(fā)生問題。為避免發(fā)生沖突,設計人員最好將MicroBlaze和 FSL硬件加速器IP的運行速率設為一致。
不過,如何在不使用FSL總線的情況下將MicroBlaze和FSL硬件加速器IP直接連接起來呢?這很簡單,只需將MicroBlaze和硬件加速器的數據線連接起來即可。如果需要,可再添加握手信號。
例如,使用位反轉IP,只需一個寫入信號即可。IP會一直很快運行,足以對MicroBlaze的任何請求做出及時響應。
IP本身非常簡單。以下是摘錄 VHDL 代碼中的一段:
architecture behavioral of
fsl_bitrev is
-- data value sent by microblaze:
signal data_value :
std_logic_vector(0 to 31) := (others=>'0');
begin
-- bitreversed value to write back:
FSL_M_Data <= data_value;
process(FSL_Clk)
begin
if rising_edge(FSL_CLK) then
???? if (FSL_S_Exists = '1') then
?????? -- create the bitreversed data:
?? data_value(0) <= FSL_S_Data(31);
?? data_value(1) <= FSL_S_Data(30);
?? data_value(2) <= FSL_S_Data(29);
...
data_value(30) <= FSL_S_Data(1);
data_value(31) <= FSL_S_Data(0);
?? end if;
end if;
end process;
end architecture behavioral;
如果在兩者之間沒有使用 FSL總線的情況下添加這個IP,您必須對項目的MHS文件進行如下修改:
BEGIN microblaze
?...
?PARAMETER C_FSL_LINKS = 1
?...
PORT FSL0_S_EXISTS = net_vcc
?PORT FSL0_S_DATA = FSL0_S_DATA
?PORT FSL0_M_DATA = FSL0_M_DATA
?PORT FSL0_M_WRITE = FSL0_M_EXISTS
?PORT FSL0_M_Full = net_gnd
END
BEGIN fsl_bitrev
PARAMETER INSTANCE = fsl_bitrev_0
?PARAMETER HW_VER = 1.00.a
?PORT FSL_S_DATA = FSL0_M_DATA
?PORT FSL_S_EXISTS = FSL0_M_EXISTS
?PORT FSL_M_Data = FSL0_S_DATA
?PORT FSL_M_Full = net_gnd
?PORT FSL_Clk = clk_50_0000MHz
END
現在效率顯著提高。硬核僅在兩個周期內可完成位反轉操作:一個周期用于把數據寫入IP,另一個周期則負責讀回結果。處理2萬個位反轉操作現在只需0.8ms。
與最初采用的算法相比,效率提升了110倍。與效率最高的最新軟件算法相比,此算法仍使系統(tǒng)性能提升了11倍。
當然,本例只有在您的CPU不提供位反轉尋址功能的情況下才有效。大多數 DSP都有此功能,但大多數微控制器都不具備這個功能。具備增加這個功能的特性可大幅度提升這種算法的處理速度。
雖然修改不大,但收效十分明顯。我們甚至將代碼壓縮到兩個字大小。當然,現在硬件要求增加一些芯片。不過以此為代價獲得比任何標準微控制器更高的速度,是值得的。
案例2:高速浮點性能
現在我們給出另一個 MicroBlaze算法加速示例。一個客戶聲稱他的浮點處理在MicroBlaze系統(tǒng)上運行非常慢。他使用的算法可采用簡單的環(huán)路同時得出幾個結果。
for (i=0;i<512;i++) {
?? f_sum += farr[i];
f_sum_prod += farr[i] * farr[i];
???? f_sum_tprod += farr[i] *
farr[i] * farr[i];
f_sqrt + =
sqrt(farr[i]);
if (min_f > farr[i]) { min_f =
farr[i]; }
if (max_f < farr[i]) { max_f =
farr[i]; }
}
所有數值均是單精度浮點值。我們首先想到的是最基礎的一個問題:浮點單元 (FPU) 激活了嗎?檢查項目設置后,我們發(fā)現FPU仍然處于未啟用狀態(tài)。這就是為什么永遠無法計算出這幾個數的原因。FPU可在 MicroBlaze屬性設置中加以激活。
FPU支持共有兩種。我們也選擇擴展FPU (Extended FPU)來支持求平方根運算。現在,在50MHz 的MicroBlaze上需要 1,108,685個周期才能完成 512個值的全部循環(huán)。查看生成的匯編程序代碼后,可以了解到創(chuàng)建平方根是仍然在使用數學庫(Math-lib)功能。其在數學功能中的定義為:
double sqrt(double);
不過客戶使用平方根函數僅為處理浮點數值。因此,MicroBlaze FPU定義了一個新的函數來取代原來的函數,解決這個問題:
float sqrtf(float);
把表達式f_sqrt += sqrt(farr[i])變?yōu)閒_sqrt += sqrtf(farr[i]),就會調用MicroBlaze內部的FPU內部平方根功能。現在執(zhí)行代碼只需要35,336個周期。特別是與第一個根本沒有使用FPU的方案相比,我們再次通過小小的調整就實現了31倍的提升。在相同的執(zhí)行時間內,可能需要大約1.5GHz的CPU才能給出上述這些結果。
不過客戶仍不滿意,客戶要求更高的速度。在這種情況下,把算法從浮點運算變?yōu)楣厅c運算并不適合。因此,我們開發(fā)了一款新型專用硬件加速器(新型FSL IP)來加快對循環(huán)的處理。

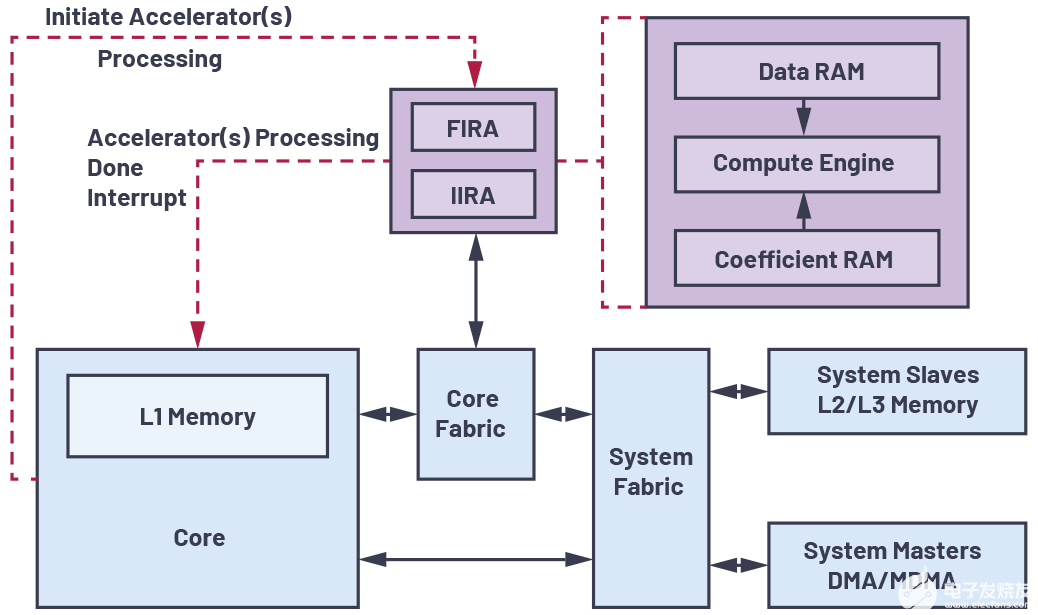
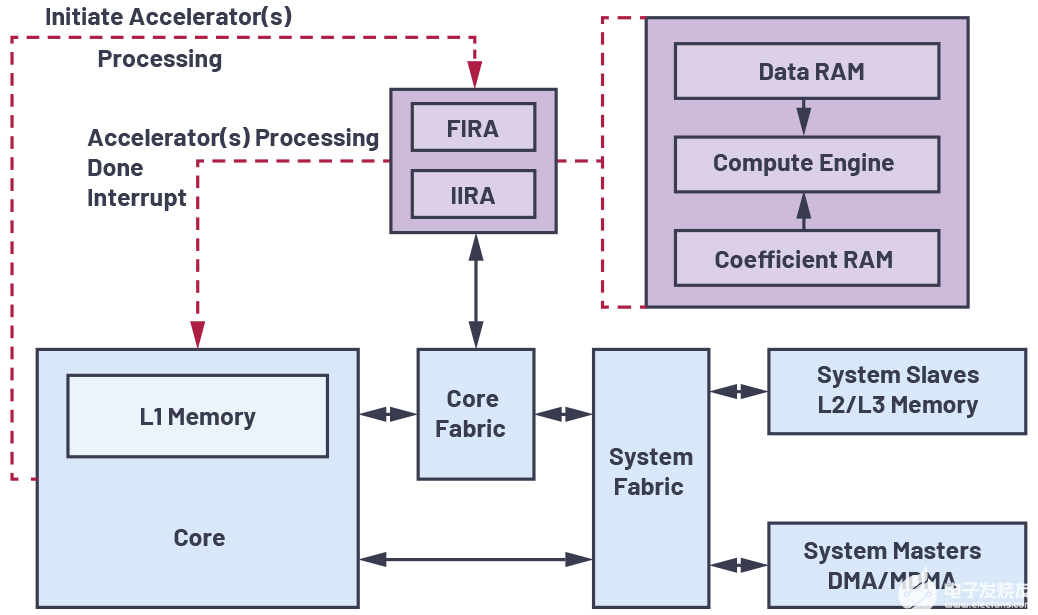
新的FSL IP使用CORE Generator模塊浮點_v4_0來為4x ADD、2x MUL、1x GREATER、1x LESS和1x SQRT等操作創(chuàng)建9個示例。所有這些示例都可以實體化,并對相同的輸入數據進行完全并行處理(圖2)。
FSL IP中實例的創(chuàng)建帶有部分時延,但吞吐率僅為1。這要求為加速器內部的控制器硬件準備更多的芯片,不過這樣可以在每個時鐘周期內向協處理器提供新數據。
在取回結果前,只有在處理循環(huán)末端才需要增加周期。
我們采用直連方式把MicroBlaze連接到FSP IP時不需要FIFO。傳輸的所有數據都將緩存在IP內,并隨即加以處理。
從FSL IP返回到MicroBlaze的連接是使用FSL總線創(chuàng)建的。由于我們必須發(fā)回一些結果,因而這更加容易實現,而且可以更加簡單地在IP內完成。部分CoreGen模塊有一些已被添加到執(zhí)行時間中的時延,并被getfsl()調用完全覆蓋。MicroBlaze只需要等到所有結果都存入FSL總線FIFO。不過,只要數據率是1,即可完全實現所要求的吞吐率。
FSL總線的額外延遲僅會占用為數不多的一些周期。使用FSL硬件加速器的C代碼如下:for (i=0;i<512;i++) {
putfsl(farr[i],fsl0_id);
}
// get the min,max values:
getfsl(min_f,fsl0_id);
getfsl(max_f,fsl0_id);
// get the sum and products:
getfsl(f_sum,fsl0_id);
getfsl(f_sum_prod,fsl0_id);
getfsl(f_sum_tprod,fsl0_id);
getfsl(f_sqrt,fsl0_id);
算法的最終實施僅需大約4,630個周期,而且依然是全浮點實施。
硬件需要本來應該用于實施硬件加速器的更多芯片才能并行計算出所有結果。不過與擴展FPU實施方案相比,我們最終提升了大約7.6倍。否則,如果使用標準處理器來替換這個50MHz的處理器,可能需要大約380MHz的CPU才能勝任(假設硬件自帶有浮點平方根函數)。
更為顯著的是與使用PFU的最初方案,而非平方根函數的對比效果:總體提升了大約239倍。這種效果可能需要12GHz左右的浮點處理器才能實現。
如上述例子所示,有時候小小的調整就會顯著影響算法的處理效果。實施這些調整,可以讓您的50MHz MicroBlaze系統(tǒng)與高性能DSP相媲美。
首先,找出執(zhí)行時間過長的核心算法,然后對其加速——通過簡單調整軟件,使用硬件,或使用硬件加速器進行更為復雜的調整。如此一來,您的處理器系統(tǒng)會強于標準控制器。





















 工商網監(jiān)
工商網監(jiān)
評論