 電子發燒友App
電子發燒友App


0 引言
龍芯2F是中國科學院計算技術研究所研制的高性能通用處理器,具有低功耗、低成本以及自主安全的特點,已應用于高性能計算和日常生活領域。
龍芯2F以開源的Linux作為操作系統。Glibe庫是Linux系統最底層的運行庫,為其上的應用程序提供系統接口以及其它功能函數。此外,它還是以 C語言構建開發程序時使用的基本函數庫。本文基于龍芯2F體系結構對Glibc庫進行優化,對于提升龍芯2F的平臺性能與用戶體驗有重要意義。
1 Glibc庫介紹
Glibc庫是GNU發布的C運行庫,它封裝了Linux操作系統提供的系統服務,除此之外,還提供了其它必要的功能服務實現。Glibc庫是Li- nux系統最底層的函數庫,是除了操作系統核心以外,所有應用程序賴以執行的基礎環境。Linux系統上的其它函數庫都需要直接或間接依賴于Glibc 庫。
Glibc庫包含兩類函數,一種是與核心溝通的系統函數,它們封裝了系統調用,對傳入參數進行預處理之后就轉到系統調用來完成功能,其目的是使得用戶可以方便地使用操作系統核心提供的服務。系統調用接口與Linux操作系統相關,大部分流程固定,沒有太大優化余地,對
其不做處理。
C庫中的另一類函數提供常見的通用功能實現,包括標準輸入輸出控制,字符串處理,正則表達式,字符串加密,查找與排序等。它們提供基本的、與操作系統無關的功能,其中的部分函數有一定的計算量,是優化工作關注的部分。
Glibc庫的版本在不斷更新,本文以當前最新的Glibc2.11版本為基礎進行優化。
2 龍芯2F體系結構
龍芯2F處理器實現了64位的MIPSⅢ指令集,整數寄存器和浮點寄存器均為64位,支持o32/n32和n64的ABI類型。除了 MIPS標準指令外,龍芯2F還提供了特有的整型計算和浮點計算指令。整型指令包括單條指令對3個寄存器進行操作的乘法、除法以及求模運算,浮點指令包括
乘加、開平方等運算。
龍芯2F包含兩級Cache結構,L1 Cache數據和指令獨立,均為64kB;L2 Cache數據和指令共享,為512kB。L1 cache和L2 cache都采用四路組相聯結構,組內采用隨機替換策略,cache行大小均為32字節。
3 Glibc庫的優化
根據對Glibc庫組成的分析,文章對其中的字符串與內存處理,數據轉換,哈希表查找以及加密函數進行了優化,以下各節分別介紹其優化方法和優化效果。
3.1 字符串與內存處理函數
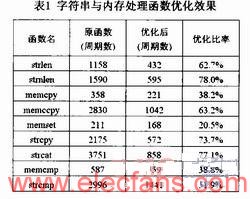
字符串與內存處理函數組提供了較為豐富的函數來完成各種操作,包括字符串與內存的移動、比較和查找等。兩者的操作通常一一對應,因為C語言中的字符串即用一段連續的內存來表示,區別在于字符串用空字符NULL來表示結尾,而內存塊的結尾由其大小確定。
對本組函數進行分析可知,部分函數之間的實現流程類似,如strlen和strnlen,memcpy和memccpy等。此外某些函數可通過調用其它函數來完成,如strcpy可由strlen與memcpy函數完成。
由于這一特點,字符串與內存處理函數組的優化方法可以相互借鑒,使用的優化方法主要包括以下幾種:
優化訪存指令。本組函數的處理流程一般是從一個或兩個內存地址開始讀取內存并進行相應的操作。在讀取過程中考慮內存地址的對齊情況及讀取單位,分別使用不同格式的訪存指令。
分塊處理。根據龍芯2F處理器的寄存器個數將待處理的字符串或內存分塊,以充分利用寄存器進行循環展開。
匯編實現。本組函數包含了一些使用頻繁且對系統性能影響較大的函數,如內存拷貝memcpy函數等,對此類函數我們使用匯編或內嵌匯編來實現,以避免編譯器可能生成低效的代碼。
表l是本組函數中主要函數的優化效果,以字符串規模或內存大小512B作為輸入。
3.2 數據轉換函數
數據轉換函數包括字符串轉換為整數和浮點數。文章分別在每類函數中取一個例子說明優化過程。
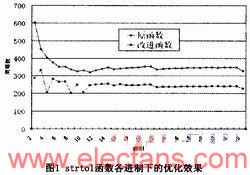
字符串轉換為整數包括strtol、strtoul、strtoll等函數,它們分別解析不同的整數類型,支持從2到36的轉換進制。各函數實現上不同的地方僅在于不同類型的整數大小范圍不同,處理流程類似。下面以strtol函數為例介紹優化過程,它的功能為將字符串轉換為long型整數。
Glibc庫中strtol的實現使用普通的逐字節讀取并計算的方式。我們首先對轉換進制分情況處理,對于2的冪次方的進制,如2、4、8、16、32,字符串中的每個數字在二進制位上沒有關聯。可以將它們逐個轉換成二進制位后填入返回值的相應位置,具有較快的轉換速度。其次十進制轉換是一種常用的情況,也將其單獨列出,可以省去對字母進行判斷。
給定進制后,在該進制下整數至多有多少位就可以確定。當字符串中的合法數字個數超過位數限制時,直接返回該類型下的最大值即可。當字符串中的合法數字小于位數限制時,可知解析后的結果絕對不會超過該整數類型的表示范圍,此時我們將字符串進行分段并對解析進程進行循環展開。如果合法數字個數恰好等于位數限制,此時解析結果有超過該類型下最大值的可能性,首先將小于位數限制的部分解析完成后,再考慮最后一位數字。提前確定解析結果的范圍可以避免每次循環內都要對是否超出該類型的最大值進行判斷。
取進制從2到36,字符串的長度從1到該進制下的最大值進行測試,得到各進制下的優化效果如圖1所示,各進制的平均優化比率為30.9%。
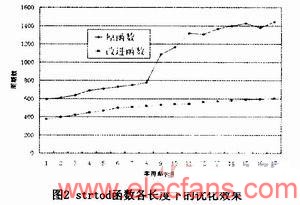
strtod、strtof、strtold等函數將字符串轉換為浮點數。我們以strtod函數為例進行介紹,它將字符串轉換為double型浮點數。
Glibc庫中strtod的實現使用高精度計算。首先遍歷整個字符串,找出其中的整數、小數和指數部分,各個部分分別使用高精度計算解析,再將結果合并。對于一般的實現來說,各個部分的取值不會太大,此時使用高精度計算時間消耗較大,改進的實現將每個部分再進行分
塊,對每個分塊使用整數進行解析,實現方式與strtol相同。各個部分的分塊解析完成后,使用一個long double類型作為臨時變量合并解析結果以避免精度丟失,最后將該變量轉換為doulble類型返回。對于strtof函數,使用double類型作為臨時變量。而對于strtold函數,使用上述方法無法保證精度,仍采用原始的實現。
由于雙精度浮點數的有效位數為16至17位,對字符串長度從1到17進行測試,得到各長度下的優化效果如圖2所示,各長度的平均優化比率為49.8%。
3.3 哈希表查找函數
Glibc庫中哈希表所包含的關鍵字和數據分別為字符串和內存塊,其相關的函數包括hcreate,hdestory以及hsearch,分別完成哈希表的創建,銷毀和查找。創建與銷毀操作都是一次性的,我們對查找操作進行優化。
hsearch函數讀入字符串關鍵字作為參數,首先將其映射為整數關鍵值,接著使用雙重散列逐個取出元素進行判斷。
Glibc庫中字符串映射為整數的實現方法為,首先求得字符串的長度作為初值,接著將其不斷左移4位并從末尾到頭部逐個與字符串中的字符相加。該方法需要對字符串進行兩次遍歷,并且當字符串較長時,字符串的長度和進行累加的前幾個字符會被移出而不影響最終的映射值。例如對32位的整型數來說,只有字符串的前8個字符對映射值有影響。
我們使用ELF哈希算法來替換原有的映射實現,此算法不先對字符串求長,僅進行移位和累加操作的循環,為了避免原始實現的缺點,每次循環中都會判斷移位是否超出范圍,如果超出,則把中間結果的高八位異或到低八位上。該哈希函數只需對字符串遍歷一遍,并且考慮了移位越界,避免了只有前幾個字符影響映射值的缺陷。
3.4 加密函數
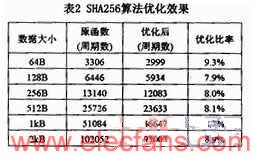
Glibc庫中的加密函數為crypt函數,該函數單向加密給定的字符串,支持的算法包括MD5、SHA以及DES算法。由于MD5與DES算法的實現流程固定且做了較充分的展開,因此我們主要考慮SHA算法。針對該算法有設計硬件結構進行的優化,而我們的工作從代碼實現角度進行。下面以SHA-256為例說明優化過程,其它SHA算法與之類似。
由于龍芯2F只支持小尾端的字符序,因此SHA算法首先將進行運算的字轉換為大尾端。原始實現中使用表達式x=((n<<24)| ((n&0xff00)<<8)|((n>>8)&0xff00)|(n>>24))進行轉換,其中n為無符號的 32位整數。該轉換操作總共需要兩次與,四次移位與三次或運算,我們對其
進行改進,采用二分方的思想,使用表達式n1=(n<<16)|(n>>16)和x=(((n1&0xff00ff00)& gt;>8)|(n1&0xff00ff)<<8))。其中計算n1的表達式可以由編譯器編譯為一條循環移位指令,這樣改進的實現共需要兩次與,三次移位與一次或運算,省去了一次移位與兩次或運算。
算法接下來的操作是消息擴散與迭代計算,計算公式分別如圖3和圖4所示。

我們對其計算過程進行層數為2的循環展開。對于迭代計算過程,循環展開之后還可以繼續進行賦值傳遞優化,減少運算量和迭代次數。循環展開層數增加時,循環次數減小,但增加了循環內的計算量,寄存器的數目滿足不了中間結果的保存,需要讀寫內存,反而造成性能的下降。經過實驗確定,層數為2是一個較好的選擇。
表2是改進前后SHA256算法的性能對比,取數據大小從64B到2kB倍增。
4 總結
Glibc庫是Linux系統最底層的運行庫,是所有應用程序賴以執行的基礎環境。本文基于龍芯2F平臺對Glibc庫中的字符串與內存處理函數、數據轉換函數、哈希表查找函數以及加密函數進行了代碼優化,大部分函數的優化比率達到30%以上,對龍芯2F平臺的整體運行性能提升具有重要意義。













 工商網監
工商網監
評論