 電子發燒友App
電子發燒友App


dd其實是工作于比較低層的一個數據拷貝和轉換的*nix平臺的工具,但是因為dd命令支持*nix平臺的一些特殊設備,因此我們可以利用dd命令的這個特性來簡單的測試磁盤的性能。
dd命令
先說一下兩個相關的特殊設備
/dev/null
空設備,通常用作輸出設備,這個是*nix系統上面的黑洞,所有送到這個空設備上的內容都會憑空消失。
/dev/zero
空字符,通常用作輸入,從/dev/zero中讀取時,它能源源不斷的提供空字符(ASCII NUL, 0×00)出來,要多少有多少。
于是就有了下面的用法:
測試磁盤的寫入:/usr/bin/time dd if=/dev/zero of=/tmp/foo bs=4k count=1024000
這個命令時往磁盤的文件/tmp/foo中寫入一個4G大小的文件,當然文件的內容全部是空字符了,同時用/usr/bin/time來對命令的執行進行計時,命令中的bs指的是寫入文件時的塊大小,其實就相當于Oracle中的block大小了,count是寫入的塊數。采取這種方法來寫入數據時只是測試的連續讀磁盤的性能,而不是隨機讀的性能,不能采取這種方法檢查一個機器的IOPS的,只能檢查磁盤的吞吐率。
測試磁盤的讀取:/usr/bin/time dd if=/tmp/foo of=/dev/null bs=4k
上面的命令是從/tmp/foo文件中讀取數據,然后扔掉,這里bs用的是讀取時塊的大小。和上面寫入的命令一樣,這樣測試的僅僅是最大的讀取性能,而不是隨機IO的性能。
還能讀寫同時測試:/usr/bin/time dd if=/tmp/foo of=/tmp/foo2 bs=4k
在上面的命令中都用到了time命令對操作進行計時,這樣才能正確的進行判斷。要記住的一點是dd命令只能夠提供一個大概的測試,通過這個簡單的命令可以對磁盤系統的最大性能有一個大概的了解,要了解更詳細的信息還要通過其他方法來查看。
理解iostat的各項輸出
在Linux中,我們執行一個iostat -x命令,我們能看到如下的輸出
$iostat -x
Linux 2.4.21-50a6smp (linux) 11/03/2009
avg-cpu: %user %nice %sys %iowait %idle
0.42 0.00 0.26 0.47 98.86
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
hdc 0.01 0.00 0.00 0.00 0.07 0.00 0.03 0.00 24.48 0.00 4.90 4.57 0.00
hda 0.89 8.54 0.74 4.49 12.60 104.22 6.30 52.11 22.32 0.03 5.41 1.01 0.53
我們先列舉一下各個性能指標的簡單說明。
rrqm/s:每秒進行merge的讀操作數目。
wrqm/s:每秒進行merge的寫操作數目。
r/s:每秒完成的讀I/O設備次數。
w/s:每秒完成的寫I/O設備次數。
rsec/s:每秒讀扇區數。
wsec/s:每秒寫扇區數。
rkB/s:每秒讀K字節數。
wkB/s:每秒寫K字節數。
avgrq-sz:平均每次設備I/O操作的數據大小(扇區)。
avgqu-sz:平均I/O隊列長度。
await:平均每次設備I/O操作的等待時間(毫秒)。
svctm:平均每次設備I/O操作的服務時間(毫秒)。
%util:一秒中有百分之多少的時間用于I/O操作,或者說一秒中有多少時間I/O隊列是非空的。
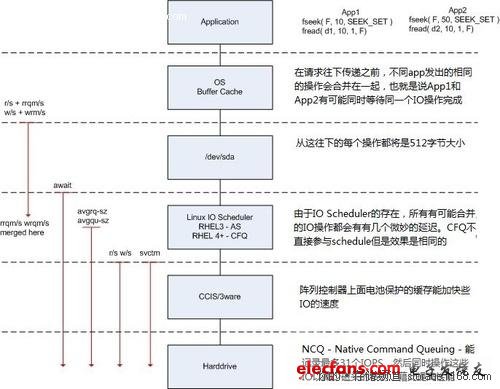
IO的執行過程的各個參數
上圖的左邊是iostat顯示的各個性能指標,每個性能指標都會顯示在一條虛線之上,這表明這個性能指標是從虛線之上的那個讀寫階段開始計量的,比如說圖中的w/s從Linux IO scheduler開始穿過硬盤控制器(CCIS/3ware),這就表明w/s統計的是每秒鐘從Linux IO scheduler通過硬盤控制器的寫IO的數量。
結合上圖對讀IO操作的過程做一個說明,在從OS Buffer Cache傳入到OS Kernel(Linux IO scheduler)的讀IO操作的個數實際上是rrqm/s+r/s,直到讀IO請求到達OS Kernel層之后,有每秒鐘有rrqm/s個讀IO操作被合并,最終轉送給磁盤控制器的每秒鐘讀IO的個數為r/w;在進入到操作系統的設備層(/dev/sda)之后,計數器開始對IO操作進行計時,最終的計算結果表現是await,這個值就是我們要的IO響應時間了;svctm是在IO操作進入到磁盤控制器之后直到磁盤控制器返回結果所花費的時間,這是一個實際IO操作所花的時間,當await與svctm相差很大的時候,我們就要注意磁盤的IO性能了;而avgrq-sz是從OS Kernel往下傳遞請求時單個IO的大小,avgqu-sz則是在OS Kernel中IO請求隊列的平均大小。
現在我們可以將iostat輸出結果和我們前面討論的指標掛鉤了。
平均單次IO大小(IO Chunk Size) <=> avgrq-sz
平均IO響應時間(IO Response Time) <=> await
IOPS(IO per Second) <=> r/s + w/s
吞吐率(Throughtput) <=> rkB/s + wkB/s
topiostat的應用實例
觀察IO Scheduler的IO合并(IO Merge)
前面說過IO在執行過程中會被合并以提高效率,下面就結合dd命令和iostat命令看一下。
我們先執行dd命令,設置bs參數值為1k,完整命令如下
dd if=/dev/zero of=test bs=1k count=1024000
同時打開另外一個終端執行iostat命令,這里只查看變化那個磁盤的更改,每秒刷新一次數據,完整命令如下
iostat -x hdc7 1
然后我們可以得到下面的結果
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
hdc7 0.00 9447.00 0.00 776.00 0.00 80616.00 0.00 40308.00 103.89 480.18 805.95 1.29 100.00
avg-cpu: %user %nice %sys %iowait %idle
0.50 0.00 56.00 43.50 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
hdc7 0.00 9534.00 0.00 872.00 0.00 81384.00 0.00 40692.00 93.33 274.56 401.19 1.14 99.00
avg-cpu: %user %nice %sys %iowait %idle
2.50 0.00 46.50 14.00 37.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
hdc7 0.00 6766.00 1.00 276.00 8.00 58808.00 4.00 29404.00 212.33 197.27 321.66 1.95 54.00
avg-cpu: %user %nice %sys %iowait %idle
0.50 0.00 0.50 0.00 99.00
看結果中第一組數據中的avgrq-sz,為103.89個扇區,磁盤的每個扇區為512字節,因此平均IO大小為103.89*512/1024=52k字節,遠遠大于我們dd命令時給定的參數1k字節,也就是說IO在中間被合并了。看巨大的wrqm/s也能得出同樣的結論。
附:在windows中監視IO性能
本來準備寫一篇windows中監視IO性能的,后來發現好像可寫的內容不多,windows在細節這方面做的不是那么的好,不過那些基本信息還是有的。
在Windows中監視性能基本都用性能監視器了,與IO性能相關的有兩個大類,一個是”LogicalDisk”,另外一個是”PhysicalDisk”,”LogicalDisk”更多的是用來監視文件相關的IO性能,而”PhysicalDisk”則是用來監視LUN或者是磁盤卷,下面就列舉下與前面所列舉的IO性能相關的計數器,具體的自己研究了:
單次IO大小
?Avg. Disk Bytes/Read
?Avg. Disk Bytes/Write
IO響應時間
?Avg. Disk sec/Read
?Avg. Disk sec/Write
IOPS
?Disk Reads/sec
?Disk Writes/sec
?Disk Transfers/sec
IO吞吐率
?Disk Bytes/sec
?Disk Read Bytes/sec
?Disk Write Bytes/sec













 工商網監
工商網監
評論