 電子發燒友App
電子發燒友App


在嵌入式系統設計過程中,許多軟件工程師受困于動態內存管理。本文介紹一種將堆棧中的內存碎片降至最少的解決方案,其中講到了內存碎片和內存丟失的區別,以及一種在編程中有利于檢測并消除內存丟失的策略。
標準C庫函數malloc()和free()可在任意的時間段中,為應用分配任意大小的內存塊。隨著內存塊的使用和釋放,在整個內存區域中,分配給堆棧的存儲區將混雜著許多正在使用或已經釋放的存儲塊,而未被使用的任何小塊內存區將變得無法使用。例如,某個應用要求堆棧分配30字節,如果堆棧中只有20個長度為3字節的小存儲塊(總共為60字節),那么堆棧仍然無法為該應用分配內存,因為所需的30字節必須是連續的。
在執行時間較長的程序中,內存碎片可能導致系統的內存枯竭,盡管分配的內存總量并未超出總的可用內存總數。內存碎片的數量取決于堆棧的實現策略。大多數程序員均采用由編譯器提供的malloc()和free()函數創建的堆棧,因此內存碎片就不受程序員的控制。
內存丟失是應用程序的缺陷,更具體地,內存丟失是一塊已經分配但永遠不會被釋放的內存區。如果所有指向內存塊的指針超出界限或者指向其他的區域,那么應用程序將永遠不能釋放那塊內存區。對于將會在某時刻退出的桌面應用程序,較小的內存丟失還可以承受,因為退出進程將把占用的所有內存返還給操作系統。但對于長時間運行的嵌入式系統,則通常需要確保絕對沒有內存丟失。
避免內存丟失不是輕而易舉的,為了確保所有分配的內存都在隨后釋放,必須建立一套明確的規則,以確定哪個應用占用了內存。為跟蹤內存,可采用類、指針數組或鏈表。由于在動態內存分配中,程序員無法預先知道在給定時間內需要分配多少數據塊,因此通常需要采用鏈表結構。
在嵌入式系統設計過程中,要利用數組保存內存分配的每一個塊記錄,在內存塊釋放的同時,也將該記錄從數組中刪除。在主循環的每次迭代之后,分配的內存塊的總數目將打印出來。理想情況下,要按類型對這些內存塊排序,但指向malloc()和free()的調用則不包含任何類型信息。內存分配的大小是最好的標識,因此成為設計工程師需要記錄的信息。此外,還需要存儲分配的內存塊地址信息,這樣,當調用釋放函數時,就可以方便地定位或刪除塊記錄。

在添加和刪除塊記錄時,還需要跟蹤每種大小的內存塊數目,程序的列表1給出了實現上述功能的代碼。
隨著內存塊的分配和釋放,數組:
=======================
typedef struct
{
void * address;
size_t size;
} BlockEntry;
======================
跟蹤當前存在的所有內存塊。另一數組則跟蹤當前存在的每種大小的內存塊總數:
======================
typedef struct
{
int count;
size_t size;
} Counter;
======================
函數mDisplayTable()允許我們在每次主循環結束時輸出結果。如果printf()不可用,則可利用調試器中斷系統并檢驗數組的內容。
上述代碼還必須使NUM_SIZES 和 NUM_BLOCKS足夠大,以處理系統中的大量內存分配;但也不能太大,從而導致在系統運行之前就已耗盡所有的RAM。
輸出
快速地瀏覽代碼,可以注意到結構類型Sensor的長度定義如下:
=======================
typedef struct
{
int offset;
int gain;
char name[10];
} Sensor;
======================
假定int為32位數據,那么Sensor的長度將為18(4+4+10),但在測試中,結果表明為20。編譯器可以在存儲結構的數據成員之間自由地添加填充,以將對齊強制設定為一個字邊界。特殊情況下,每個字段開始于一個已存在的字邊界,那么為什么還需要填充呢?填充添加在存儲結構的最末端,如果聲明了一個數組Sensor,那么該數組的所有成員(而不僅僅是第一個成員)將會進行字對齊。根據處理器的不同,字對齊的速度將有所差異,有時這些編譯器將提供可根據速度選擇字對齊長度的切換開關。在任何情形下,最好不要根據源代碼的定義對存儲結構的長度作任何假設。

下面考察當使用這些函數時,將得到何種類型的輸出。程序清單2給出了一個顯示存儲動態內存方式的示例。程序清單2將通常作為主外部循環的迭代了10次,并在每次迭代的末尾,調用函數mDisplay-Table()輸出分配的內存塊情況。
許多內存塊均在初始化階段進行分配,但我們對這些內存塊并不感興趣,因為這段代碼將不會重復,因此不會產生內存丟失。由于我們并不希望這些內存分配導致分配表混亂,因此在啟動感興趣的迭代之前需要將該分配表清空。為了清空分配表,需要調用函數mClearTable()。
主循環調用的三個不同的函數
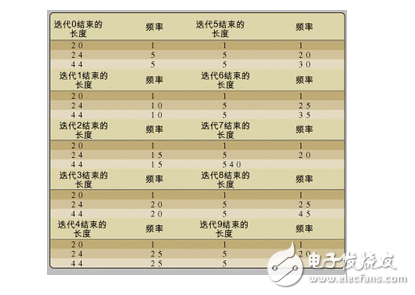
函數replacer():指示了一個用來分配內存塊并且直到出現循環迭代才釋放的指針。如果檢驗主循環中的迭代,可以發現分配的內存塊并未釋放。通過監控總數為20的內存塊,從表1可以看出,每次迭代之后的內存塊總數都為1,因此沒有出現內存丟失。
函數growAndShrink():管理長度為24個結構體的鏈表,該鏈表的長度將隨時間發生變化,但我們并不希望鏈表無限增長。通過檢驗總數為24的內存塊,我們可以發現,雖然任意時間內存塊的數目都可能發生變化,但決不會超過25個。
函數growForever():處理內存塊長度為44的情形。這里我們可以非常清晰地看到,分配的內存塊數目在持續增長。當首次觀察該表時,可能無法找到表的源頭。我們首先只能快速而粗略對mMalloc()上的條件斷點進行檢驗,該斷點只有當長度參數達到44時才觸發。當到達該斷點時,可以檢驗堆棧,以確定進行內存分配的地方。工程師完全能夠多次執行這樣的操作,因為這種長度的內存塊可在多處進行分配。
嚴格地說,在函數growForever()中分配的內存不是丟失,因為所有分配的內存塊均帶有引用,因此理論上可以在后來釋放。如果特定應用這樣做,那么結果就非常明顯。
長度是關鍵因素
當不同類型的對象共享相同長度的內存時,上述技術就不那么有效了。實際中碰到這樣的情形并不多,但即便可能引發問題,仍然還有很多別的選擇。
更為先進的方法則是為每個記錄存儲類型信息。這并不困難,但我卻不愿采用這種方法,因為該方法要求為函數mMalloc()的標記添加一些新東西。我們可以定義一個列出所有可能分配的類型的枚舉類型。在每次調用函數mMalloc()時,將傳遞一個附加的參數,并且該參數為枚舉類型中的一個元素。如果在表中該參數連同地址一起被存儲,那么總能識別出這類對象。
這也使得我們可以將分配長度不同,但類型相關(如可變長度的字符數組)的內存塊鏈接起來。
C++通過使我們重載或刪除按類基(per-class basis)而使得這種方法更加簡便易行。盡管這是一種有效的方法,但這里我仍然不會采用這種方法,因為我更傾向采用適合C語言環境的技術。
分配位置
有時,位置信息比類型信息更為有效。幸而我們能夠靈活地使用宏定義,從而無須更換標記即可選擇這些信息。
==========================
#define mMalloc(size_t size)
mMallocLineNo(size, __LINE__,
__FILE__)
=========================
mMallocLineNo()函數是程序清單1中函數mMalloc()的變異。現在我們期望像程序清單3那樣存儲行號和文件名信息,為保持額外信息,結構BlockEntry將具有如下形式:
=========================
typedef struct
{
void * addr;
size_t size;
int line;
char * file;
} BlockEntry;
==========================
通過為每個內存塊存儲行號和文件名,就能精確地定位任何分配的內存塊。可以為所有特定長度的表項設計一個輸出行號和文件名為mDisplayLocation()的函數,這樣就能輕易地識別出長度可疑的內存塊的來源。
再次回到表1,可能我們會擔心長度為44的內存塊。為了更多地了解這些內存的來源,可以在函數main()的末尾添加如下代碼:
========================
mDisplayLocation(44);
=======================
這能將行44輸出50遍。
=======================
line = 162, file = listing2.c
=======================
這清晰地表明內存塊在函數growForever()中分配。
可變的長度
某些內存分配的長度可以發生急劇變化,例如:
==========================
char *p = malloc(strlen(name)+1);
==========================
是分配一塊足以存儲字符串名和字符串截止符的內存的通用方法。在嵌入式系統中,不會經常對字符串和文件進行操作;數據結構的分配則不是這樣,例如:
==========================
Motor *m = malloc(sizeof(Motor));
==========================
如果假定Motor為存儲結構,那么上述分配將總是得到相同長度的內存塊,在上面描述的函數中,將在輸出中更簡便地識別出這些內存塊。
在分配可變長度內存塊時,可以行號和文件名的組合為核心計算內存分配的計數。示例中,我們存儲了行號和文件名,但打印的總數則取決于長度。通過行號和文件名的聚合分配將有助于在相同的位置將所有的分配組合起來,而不管分配的長度如何。某些情況下,即便可變的長度不成問題,這樣的分析仍然能帶給我們更多的啟發。
內存表
任何含有內存丟失的代碼都將導致這里給出的內存表不斷增大,而且并非所有的丟失都能像growForever()示例那樣清晰無誤地進行識別。即便采用其它技術進行丟失檢測和消除,這些輸出表仍將有助于確定丟失是否已被消除。
這里給出的循環并不處理可變的輸入數據。在實際項目中,通常插入一些調用(如仿真鍵盤敲擊序列的調用)以模擬輸入。在實際系統中,還必須創建一些適當的輸入。除非自己希望改變代碼,否則完全無須訪問導致內存丟失的代碼段。因此,這里的示例或許向大家提供了一個良好的開端,但任何內存丟失仍然需要進行一些檢測。
內存使用率的測量
如果需要修改malloc(),理想情況下應當采用不同的名稱取代所有的malloc()調用。我將其取名為mmalloc(),意即“measured malloc”。這樣我們就能編寫一個執行一些額外工作并調用常規malloc()的函數,這也可以通過其他途徑實現,如采用#define取代malloc(),或在編譯庫中利用鏈接程序重命名malloc()函數。
這種方法的一個缺陷在于,不能對從我無法更改或重新編譯的庫函數中調用的malloc()進行監控。例如,標準庫包含一個依次調用malloc()的函數strdup(),我們無法用malloc()調用加以取代,除非我們擁有正在使用的庫的源代碼。
測量使用率的第一步是簡單地添加需要分配的內存并減去任何已經釋放的內存。對于malloc(),這當然微不足道。假定定義了一個靜態值G_inUse,那么下面的代碼就能跟蹤內存的分配:
==========================
void *mmalloc(size_t size){
G_inUse += size;
return malloc(size);
}
==========================
mfree()略微復雜一些,因為free()并不傳遞表示內存大小的變量。函數free()傳遞指向內存塊的指針。通常表示釋放內存大小的量隱藏在指針所指向數據塊之前的數據頭中,所以可以得到下面的函數:
==========================
void mfree(void *p)
{
size_t *sizePtr=((size_t *) p)-1;
G_inUse -= *sizePtr;
free(p);
}
==========================
因為在釋放過程中或許不會使用這種轉換,或者需要在略微不同的偏移位置存儲表示釋放內存大小的量,因此這種方法是無法移植的。
釋放的內存大小或許并不與分配的內存匹配,malloc()的某些實現方法向上舍入為最接近的一個值。例如,如果要求分配11字節,而實際上卻接收到了12字節。在這種情況下,12將存儲在數據頭中。因此分配和釋放的數據塊就能通過使用G_inUse-1實現平衡。










 工商網監
工商網監
評論