 電子發燒友App
電子發燒友App


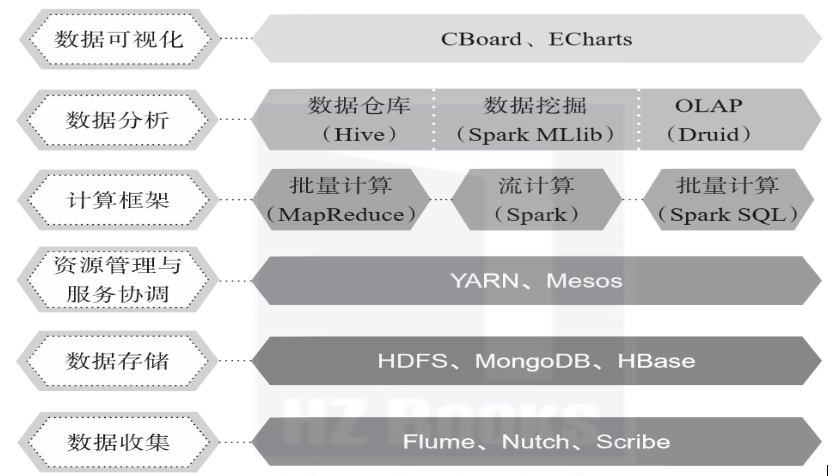
大數據技術的體系龐大且復雜,基礎的技術包含數據的采集、數據預處理、分布式存儲、NoSQL數據庫、數據倉庫、機器學習、并行計算、可視化等各種技術范疇和不同的技術層面。首先給出一個通用化的大數據處理框架,主要分為下面幾個方面:數據采集與預處理、數據存儲、數據清洗、數據查詢分析和數據可視化。
一、數據采集與預處理
對于各種來源的數據,包括移動互聯網數據、社交網絡的數據等,這些結構化和非結構化的海量數據是零散的,也就是所謂的數據孤島,此時的這些數據并沒有什么意義,數據采集就是將這些數據寫入數據倉庫中,把零散的數據整合在一起,對這些數據綜合起來進行分析。數據采集包括文件日志的采集、數據庫日志的采集、關系型數據庫的接入和應用程序的接入等。在數據量比較小的時候,可以寫個定時的腳本將日志寫入存儲系統,但隨著數據量的增長,這些方法無法提供數據安全保障,并且運維困難,需要更強壯的解決方案。
Flume NG作為實時日志收集系統,支持在日志系統中定制各類數據發送方,用于收集數據,同時,對數據進行簡單處理,并寫到各種數據接收方(比如文本,HDFS,Hbase等)。Flume NG采用的是三層架構:Agent層,Collector層和Store層,每一層均可水平拓展。其中Agent包含Source,Channel和 Sink,source用來消費(收集)數據源到channel組件中,channel作為中間臨時存儲,保存所有source的組件信息,sink從channel中讀取數據,讀取成功之后會刪除channel中的信息。
NDC,Netease Data Canal,直譯為網易數據運河系統,是網易針對結構化數據庫的數據實時遷移、同步和訂閱的平臺化解決方案。它整合了網易過去在數據傳輸領域的各種工具和經驗,將單機數據庫、分布式數據庫、OLAP系統以及下游應用通過數據鏈路串在一起。除了保障高效的數據傳輸外,NDC的設計遵循了單元化和平臺化的設計哲學。
Logstash是開源的服務器端數據處理管道,能夠同時從多個來源采集數據、轉換數據,然后將數據發送到您最喜歡的 “存儲庫” 中。一般常用的存儲庫是Elasticsearch。Logstash 支持各種輸入選擇,可以在同一時間從眾多常用的數據來源捕捉事件,能夠以連續的流式傳輸方式,輕松地從您的日志、指標、Web 應用、數據存儲以及各種 AWS 服務采集數據。
Sqoop,用來將關系型數據庫和Hadoop中的數據進行相互轉移的工具,可以將一個關系型數據庫(例如Mysql、Oracle)中的數據導入到Hadoop(例如HDFS、Hive、Hbase)中,也可以將Hadoop(例如HDFS、Hive、Hbase)中的數據導入到關系型數據庫(例如Mysql、Oracle)中。Sqoop 啟用了一個 MapReduce 作業(極其容錯的分布式并行計算)來執行任務。Sqoop 的另一大優勢是其傳輸大量結構化或半結構化數據的過程是完全自動化的。
流式計算是行業研究的一個熱點,流式計算對多個高吞吐量的數據源進行實時的清洗、聚合和分析,可以對存在于社交網站、新聞等的數據信息流進行快速的處理并反饋,目前大數據流分析工具有很多,比如開源的strom,spark streaming等。
Strom集群結構是有一個主節點(nimbus)和多個工作節點(supervisor)組成的主從結構,主節點通過配置靜態指定或者在運行時動態選舉,nimbus與supervisor都是Storm提供的后臺守護進程,之間的通信是結合Zookeeper的狀態變更通知和監控通知來處理。nimbus進程的主要職責是管理、協調和監控集群上運行的topology(包括topology的發布、任務指派、事件處理時重新指派任務等)。supervisor進程等待nimbus分配任務后生成并監控worker(jvm進程)執行任務。supervisor與worker運行在不同的jvm上,如果由supervisor啟動的某個worker因為錯誤異常退出(或被kill掉),supervisor會嘗試重新生成新的worker進程。
當使用上游模塊的數據進行計算、統計、分析時,就可以使用消息系統,尤其是分布式消息系統。Kafka使用Scala進行編寫,是一種分布式的、基于發布/訂閱的消息系統。Kafka的設計理念之一就是同時提供離線處理和實時處理,以及將數據實時備份到另一個數據中心,Kafka可以有許多的生產者和消費者分享多個主題,將消息以topic為單位進行歸納;Kafka發布消息的程序稱為producer,也叫生產者,預訂topics并消費消息的程序稱為consumer,也叫消費者;當Kafka以集群的方式運行時,可以由一個服務或者多個服務組成,每個服務叫做一個broker,運行過程中producer通過網絡將消息發送到Kafka集群,集群向消費者提供消息。Kafka通過Zookeeper管理集群配置,選舉leader,以及在Consumer Group發生變化時進行rebalance。Producer使用push模式將消息發布到broker,Consumer使用pull模式從broker訂閱并消費消息。Kafka可以和Flume一起工作,如果需要將流式數據從Kafka轉移到hadoop,可以使用Flume代理agent,將Kafka當做一個來源source,這樣可以從Kafka讀取數據到Hadoop。
Zookeeper是一個分布式的,開放源碼的分布式應用程序協調服務,提供數據同步服務。它的作用主要有配置管理、名字服務、分布式鎖和集群管理。配置管理指的是在一個地方修改了配置,那么對這個地方的配置感興趣的所有的都可以獲得變更,省去了手動拷貝配置的繁瑣,還很好的保證了數據的可靠和一致性,同時它可以通過名字來獲取資源或者服務的地址等信息,可以監控集群中機器的變化,實現了類似于心跳機制的功能。
二、數據存儲
Hadoop作為一個開源的框架,專為離線和大規模數據分析而設計,HDFS作為其核心的存儲引擎,已被廣泛用于數據存儲。
HBase,是一個分布式的、面向列的開源數據庫,可以認為是hdfs的封裝,本質是數據存儲、NoSQL數據庫。HBase是一種Key/Value系統,部署在hdfs上,克服了hdfs在隨機讀寫這個方面的缺點,與hadoop一樣,Hbase目標主要依靠橫向擴展,通過不斷增加廉價的商用服務器,來增加計算和存儲能力。
Phoenix,相當于一個Java中間件,幫助開發工程師能夠像使用JDBC訪問關系型數據庫一樣訪問NoSQL數據庫HBase。
Yarn是一種Hadoop資源管理器,可為上層應用提供統一的資源管理和調度,它的引入為集群在利用率、資源統一管理和數據共享等方面帶來了巨大好處。Yarn由下面的幾大組件構成:一個全局的資源管理器ResourceManager、ResourceManager的每個節點代理NodeManager、表示每個應用的Application以及每一個ApplicationMaster擁有多個Container在NodeManager上運行。
Mesos是一款開源的集群管理軟件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等應用架構。
Redis是一種速度非常快的非關系數據庫,可以存儲鍵與5種不同類型的值之間的映射,可以將存儲在內存的鍵值對數據持久化到硬盤中,使用復制特性來擴展性能,還可以使用客戶端分片來擴展寫性能。
Atlas是一個位于應用程序與MySQL之間的中間件。在后端DB看來,Atlas相當于連接它的客戶端,在前端應用看來,Atlas相當于一個DB。Atlas作為服務端與應用程序通訊,它實現了MySQL的客戶端和服務端協議,同時作為客戶端與MySQL通訊。它對應用程序屏蔽了DB的細節,同時為了降低MySQL負擔,它還維護了連接池。Atlas啟動后會創建多個線程,其中一個為主線程,其余為工作線程。主線程負責監聽所有的客戶端連接請求,工作線程只監聽主線程的命令請求。
Kudu是圍繞Hadoop生態圈建立的存儲引擎,Kudu擁有和Hadoop生態圈共同的設計理念,它運行在普通的服務器上、可分布式規模化部署、并且滿足工業界的高可用要求。其設計理念為fast analytics on fast data。作為一個開源的存儲引擎,可以同時提供低延遲的隨機讀寫和高效的數據分析能力。Kudu不但提供了行級的插入、更新、刪除API,同時也提供了接近Parquet性能的批量掃描操作。使用同一份存儲,既可以進行隨機讀寫,也可以滿足數據分析的要求。Kudu的應用場景很廣泛,比如可以進行實時的數據分析,用于數據可能會存在變化的時序數據應用等。
在數據存儲過程中,涉及到的數據表都是成千上百列,包含各種復雜的Query,推薦使用列式存儲方法,比如parquent,ORC等對數據進行壓縮。Parquet 可以支持靈活的壓縮選項,顯著減少磁盤上的存儲。
三、數據清洗
MapReduce作為Hadoop的查詢引擎,用于大規模數據集的并行計算,”Map(映射)”和”Reduce(歸約)”,是它的主要思想。它極大的方便了編程人員在不會分布式并行編程的情況下,將自己的程序運行在分布式系統中。
隨著業務數據量的增多,需要進行訓練和清洗的數據會變得越來越復雜,這個時候就需要任務調度系統,比如oozie或者azkaban,對關鍵任務進行調度和監控。
Oozie是用于Hadoop平臺的一種工作流調度引擎,提供了RESTful API接口來接受用戶的提交請求(提交工作流作業),當提交了workflow后,由工作流引擎負責workflow的執行以及狀態的轉換。用戶在HDFS上部署好作業(MR作業),然后向Oozie提交Workflow,Oozie以異步方式將作業(MR作業)提交給Hadoop。這也是為什么當調用Oozie 的RESTful接口提交作業之后能立即返回一個JobId的原因,用戶程序不必等待作業執行完成(因為有些大作業可能會執行很久(幾個小時甚至幾天))。Oozie在后臺以異步方式,再將workflow對應的Action提交給hadoop執行。
Azkaban也是一種工作流的控制引擎,可以用來解決有多個hadoop或者spark等離線計算任務之間的依賴關系問題。azkaban主要是由三部分構成:Relational Database,Azkaban Web Server和Azkaban Executor Server。azkaban將大多數的狀態信息都保存在MySQL中,Azkaban Web Server提供了Web UI,是azkaban主要的管理者,包括project的管理、認證、調度以及對工作流執行過程中的監控等;Azkaban Executor Server用來調度工作流和任務,記錄工作流或者任務的日志。
流計算任務的處理平臺Sloth,是網易首個自研流計算平臺,旨在解決公司內各產品日益增長的流計算需求。作為一個計算服務平臺,其特點是易用、實時、可靠,為用戶節省技術方面(開發、運維)的投入,幫助用戶專注于解決產品本身的流計算需求。
四、數據查詢分析
Hive的核心工作就是把SQL語句翻譯成MR程序,可以將結構化的數據映射為一張數據庫表,并提供 HQL(Hive SQL)查詢功能。Hive本身不存儲和計算數據,它完全依賴于HDFS和MapReduce。可以將Hive理解為一個客戶端工具,將SQL操作轉換為相應的MapReduce jobs,然后在hadoop上面運行。Hive支持標準的SQL語法,免去了用戶編寫MapReduce程序的過程,它的出現可以讓那些精通SQL技能、但是不熟悉MapReduce 、編程能力較弱與不擅長Java語言的用戶能夠在HDFS大規模數據集上很方便地利用SQL 語言查詢、匯總、分析數據。
Hive是為大數據批量處理而生的,Hive的出現解決了傳統的關系型數據庫(MySql、Oracle)在大數據處理上的瓶頸 。Hive 將執行計劃分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一個Query會被編譯成多輪MapReduce,則會有更多的寫中間結果。由于MapReduce執行框架本身的特點,過多的中間過程會增加整個Query的執行時間。在Hive的運行過程中,用戶只需要創建表,導入數據,編寫SQL分析語句即可。剩下的過程由Hive框架自動的完成。
Impala是對Hive的一個補充,可以實現高效的SQL查詢。使用Impala來實現SQL on Hadoop,用來進行大數據實時查詢分析。通過熟悉的傳統關系型數據庫的SQL風格來操作大數據,同時數據也是可以存儲到HDFS和HBase中的。Impala沒有再使用緩慢的Hive+MapReduce批處理,而是通過使用與商用并行關系數據庫中類似的分布式查詢引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分組成),可以直接從HDFS或HBase中用SELECT、JOIN和統計函數查詢數據,從而大大降低了延遲。Impala將整個查詢分成一執行計劃樹,而不是一連串的MapReduce任務,相比Hive沒了MapReduce啟動時間。
Hive 適合于長時間的批處理查詢分析,而Impala適合于實時交互式SQL查詢,Impala給數據人員提供了快速實驗,驗證想法的大數據分析工具,可以先使用Hive進行數據轉換處理,之后使用Impala在Hive處理好后的數據集上進行快速的數據分析。總的來說:Impala把執行計劃表現為一棵完整的執行計劃樹,可以更自然地分發執行計劃到各個Impalad執行查詢,而不用像Hive那樣把它組合成管道型的map->reduce模式,以此保證Impala有更好的并發性和避免不必要的中間sort與shuffle。但是Impala不支持UDF,能處理的問題有一定的限制。
Spark擁有Hadoop MapReduce所具有的特點,它將Job中間輸出結果保存在內存中,從而不需要讀取HDFS。Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
Nutch 是一個開源Java 實現的搜索引擎。它提供了我們運行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬蟲。
Solr用Java編寫、運行在Servlet容器(如Apache Tomcat或Jetty)的一個獨立的企業級搜索應用的全文搜索服務器。它對外提供類似于Web-service的API接口,用戶可以通過http請求,向搜索引擎服務器提交一定格式的XML文件,生成索引;也可以通過Http Get操作提出查找請求,并得到XML格式的返回結果。
Elasticsearch是一個開源的全文搜索引擎,基于Lucene的搜索服務器,可以快速的儲存、搜索和分析海量的數據。設計用于云計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用方便。
還涉及到一些機器學習語言,比如,Mahout主要目標是創建一些可伸縮的機器學習算法,供開發人員在Apache的許可下免費使用;深度學習框架Caffe以及使用數據流圖進行數值計算的開源軟件庫TensorFlow等,常用的機器學習算法比如,貝葉斯、邏輯回歸、決策樹、神經網絡、協同過濾等。
五、數據可視化
對接一些BI平臺,將分析得到的數據進行可視化,用于指導決策服務。主流的BI平臺比如,國外的敏捷BI Tableau、Qlikview、PowrerBI等,國內的SmallBI和新興的網易有數等。
在上面的每一個階段,保障數據的安全是不可忽視的問題。
基于網絡身份認證的協議Kerberos,用來在非安全網絡中,對個人通信以安全的手段進行身份認證,它允許某實體在非安全網絡環境下通信,向另一個實體以一種安全的方式證明自己的身份。
控制權限的ranger是一個Hadoop集群權限框架,提供操作、監控、管理復雜的數據權限,它提供一個集中的管理機制,管理基于yarn的Hadoop生態圈的所有數據權限。可以對Hadoop生態的組件如Hive,Hbase進行細粒度的數據訪問控制。通過操作Ranger控制臺,管理員可以輕松的通過配置策略來控制用戶訪問HDFS文件夾、HDFS文件、數據庫、表、字段權限。這些策略可以為不同的用戶和組來設置,同時權限可與hadoop無縫對接。
簡單說有三大核心技術:拿數據,算數據,賣數據。
首先做為大數據,拿不到大量數據都白扯。現在由于機器學習的興起,以及萬金油算法的崛起,導致算法地位下降,數據地位提高了。舉個通俗的例子,就好比由于教育的發展,導致個人智力重要性降低,教育背景變重要了,因為一般人按標準流程讀個書,就能比牛頓懂得多了。谷歌就說:拿牛逼的數據喂給一個一般的算法,很多情況下好于拿傻傻的數據喂給牛逼的算法。而且知不知道弄個牛逼算法有多困難?一般人連這個困難度都搞不清楚好不好……拿數據很重要,巧婦難為無米之炊呀!所以為什么好多公司要燒錢搶入口,搶用戶,是為了爭奪數據源呀!不過運營,和產品更關注這個,我是程序員,我不管……
其次就是算數據,如果數據拿到直接就有價值地話,那也就不需要公司了,政府直接賺外快就好了。蘋果落地都能看到,人家牛頓能整個萬有引力,我就只能撿來吃掉,差距呀……所以數據在那里擺著,能挖出啥就各憑本事了。算數據就需要計算平臺了,數據怎么存(HDFS, S3, HBase, Cassandra),怎么算(Hadoop, Spark)就靠咱們程序猿了……
再次就是賣得出去才能變現,否則就是搞公益了,比如《疑犯追蹤》里面的李四和大錘他們……見人所未見,預測未來并趨利避害才是智能的終極目標以及存在意義,對吧?這個得靠大家一塊兒琢磨。
其實我覺得最后那個才是“核心技術”,什么Spark,Storm,Deep-Learning,都是第二梯隊的……當然,沒有強大的算力做支撐,智能應該也無從說起吧。










 工商網監
工商網監
評論