 電子發燒友App
電子發燒友App


1月6日江蘇衛視《最強大腦》,上演了一場精彩的人機對決,這次的戰場不再是圍棋,而是人臉識別。
人類的出戰代表為王峰(微博),其為90后世界記憶大師,《最強大腦》名人堂輪值主席。
2015年以隊長身份參加《最強大腦第二季》,在《最強大腦》中德國際對抗賽中,王峰率領中國代表隊4:0完勝德國隊,本人以一敵二,并打破快速記憶撲克牌世界紀錄。
機器的一方則是百度機器人“小度”,百度大腦在人工智能領域的很多研究成果都植入到其身上。
“百度大腦”已建成超大規模的神經網絡,擁有萬億級的參數、千億樣本、千億特征訓練,能模擬人腦的工作機制。百度大腦如今智商已經有了超前的發展,在一些能力上甚至超越了人類。
在人臉識別技術的國際測評中,百度最高能達到99.77%的準確率,2015年曾獲得過兩次世界第一。而人機大戰的第一場就是PK人臉識別。
“小度”將與名人堂選手約戰三場,主要在人臉識別、語音識別上面PK,前三期人機大戰,采用三局兩勝制,如果百度大腦全勝,將參加角逐最后的腦王爭霸。
第一輪:跨年齡識別
嘉賓(章子怡)從20張蜜蜂少女隊成員童年照中挑出3張高難度照片,選手通過動態錄像表演將所選童年照和在場的成年少女向匹配。選擇正確者得1分。
蜜蜂少女隊人員眾多且每個人在賽場上化妝表演, 不排除有微整形、戴美瞳等因素干擾。
此外,挑選的童年照都在0-4歲范圍內,與現在成年少女隊的年齡跨度比較大。
同時,比賽現場有實時照片傳輸、現場攝影機捕捉人臉圖像晃動、燈光干擾等因素都會影響人工智能的識別準確率。
最為困難的是,蜜蜂少女隊人員中有一對雙胞胎,恰巧被現場嘉賓抽中。
最終,事先并不知情的王峰未能從雙胞胎中區分出差別,導致判斷錯誤,第一輪得0分。
?
而百度機器人則給出了兩個結果,區別是相似度僅相差0.01%,相似度較高那個最終被證明是正確答案,從而拿到第一輪的1分。
第一輪過后,人機大戰的比分是1:0,人類暫時落后。
第二輪:千臉跨年齡識別
人機共同觀察一位30歲以上的觀眾,隨后將他從30張小學集體照中找出。這一輪在上一輪的基礎上增加了難度,因此分值提高,選擇正確者得2分。
這一回合樣本容量大,30張集體照大約需要在1000-2000個人臉中找到對應的人,年齡跨度也覆蓋在80、90后等年齡層中。
最終,機器和王峰先后在合照中正確識別出了嘉賓選擇出的觀眾,均得2分。加上第一輪的得分,機器最終得3分,王峰得2分。
經過兩輪角逐,百度機器人以微弱優勢勝出,王峰為雙胞胎那萬分之一的差別付出了代價。
人臉識別的技術難點
人類大腦從上百萬年前開始就擁有了人臉識別的能力,而機器沒有直覺,也并沒有久遠的進化歷史,只能靠分析數據來學習。
計算機只認識0和1,所以它必須通過無數次的學習來找到人類直覺的規律并將它轉變成0和1存儲在腦子里,從而模擬人類通過直覺思考的過程。
人臉識別技術研究的困難,不同于普通的圖像識別。就人的臉部特征而言,每個人的臉部結構都是相似的,這對于利用人臉區分人類個體不利,還有一些特殊情況,比如雙胞胎甚至多胞胎。
其次就是表情、光照條件、整容等外因影響。不同的表情、角度觀察,光照條件的影響,人臉遮蓋物,如口罩、墨鏡、頭發、胡須,甚至是整容、P圖等行為,都增加了人臉識別的難度。
而對雙胞胎的識別,技術上就更困難了。
人臉識別是在臉部骨骼上取盡可能多的點,通過計算機把這些點分別與自己已經存儲的臉比較,有差別就判斷出來了。因為雙胞胎骨骼太相似,導致差別特別細微,所以取的面部骨骼點不夠多的話是識別不出來的。
人臉識別主要步驟
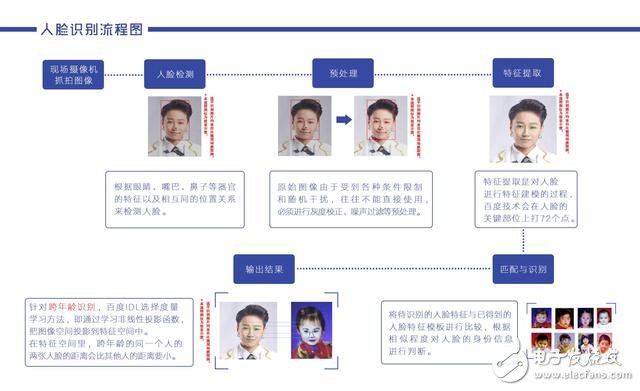
(以比賽為例,現場小度識別蜜蜂少女成員的原理流程圖)
具體分解如下:
Step 1 人臉檢測:
根據眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之間的幾何位置關系來檢測人臉,即在在一副圖像或一序列圖像(比如視頻)中判斷是否有人臉,若有則返回人臉的大小、位置等信息。
Step 2 人臉圖像預處理:
系統獲取的原始圖像由于受到各種條件的限制和隨機干擾,往往不能直接使用,必須在圖像處理的早期階段對它進行灰度校正、噪聲過濾等圖像預處理。
人臉圖像的預處理主要包括人臉對準,人臉圖像的增強,以及歸一化等工作。
人臉對準是為了得到人臉位置端正的人臉圖像;
圖像增強是為了改善人臉圖像的質量,不僅在視覺上更加清晰圖像,而且使圖像更利于計算機的處理與識別。
歸一化工作的目標是取得尺寸一致,灰度取值范圍相同的標準化人臉圖像。
【人臉圖像的預處理】
Step 3 人臉圖像特征提取:
人臉特征提取就是針對人臉的某些特征進行的。人臉特征提取,也稱人臉表征,它是對人臉進行特征建模的過程。
Step 4 人臉圖像匹配與識別:
人臉識別就是將待識別的人臉特征與已得到的人臉特征模板進行比較,根據相似程度對人臉的身份信息進行判斷。這一過程又分為兩類:
一類是人臉確認,是一對一進行圖像比較的過程,將某人面像與指定人員面像進行一對一的比對,根據其相似程度(一般以是否達到或超過某一量化的可信度指標/閥值為依據)來判斷二者是否是同一人。
另一類是人臉辨認,是一對多進行圖像匹配對比的過程。將某人面像與數據庫中的多人的人臉進行比對(有時也稱“一對多”比對),并根據比對結果來鑒定此人身份,或找到其中最相似的人臉,并按相似程度的大小輸出檢索結果。
百度大腦提升跨年齡人臉識別的方法
影響人臉識別的因素有很多,其中影響人臉檢測的因素有:光照、人臉姿態、遮擋程度;
影響特征提取的因素有:光照、表情、遮擋、年齡、模糊是影響人臉識別精度的關鍵因素。而在跨年齡人臉檢測中影響因素更多。
一般而言,在跨年齡階段人臉識別中,類內變化通常會大于類間變化,這造成了人臉識別的巨大困難。同時,跨年齡的訓練數據難以收集。沒有足夠多的數據,基于深度學習的神經網絡很難學習到跨年齡的類內和類間變化。
基于第一點,百度IDL的人臉團隊選擇用度量學習的方法。即通過學習一個非線性投影函數,把圖像空間投影到特征空間中。在這個特征空間里,跨年齡的同一個人的兩張人臉的距離會比不同人的相似年齡的兩張人臉的距離要小。
針對第二點,考慮到跨年齡人臉的稀缺性。百度用一個用大規模人臉數據訓練好的模型作為底座,然后用跨年齡數據對他做更新。這樣不容易過擬合。
將這兩點結合起來做端到端的訓練,可以大幅度提升跨年齡識別的識別率。
另外,百度人臉測試集有2百萬人的2億張圖片作為訓練樣本數據。
專家點評
百度首席科學家吳恩達:小度不僅代表百度人工智能,更代表中國
百度首席科學家吳恩達
世界頂級的科學家也只能理解人腦運作機制的一部分,百度人工智能算法參考人腦較少,更多基于數據分析和深度學習。
在這次比賽中,我們選擇的競賽項目對于機器來說非常非常困難,涉及到人臉識別、語音識別等,但事實上這些對于人類來說卻相對容易。人們可以通過直覺來進行很好地判斷,比如見到一個人,你不假思索就能認出他是誰。但是機器必須從大量數據進行訓練,有些項目中甚至需要識別不清晰的、老舊的照片,所以我認為這對于機器來說是個巨大的挑戰。
人臉識別這項技能,人類大腦從上百萬年前開始就擁有了,而機器沒有直覺,也并沒有久遠的進化歷史,只能靠分析數據來學習。所以這項技能對于哪怕是世界上最先進的AI技術也是非常困難的。
今天,我們基于強大的數據分析,很容易識別兩張近期的照片。但是對于識別整容、化濃妝或者十幾年跨度的照片,我們并沒有大量的數據可以分析。所以這是人臉識別技術遇到的世界性的挑戰,也是今天比賽中最大的難點之一。
全世界棋類比賽中頂級的選手很少,人臉識別能力每個人都具備。這次人機大戰,是頂級的人臉識別選手和擅長棋類游戲的人工智能比拼,很公平。
人類正在步入人工智能時代,不久的未來,人工智能技術就能應用到走失兒童項目,強大的人工智能創造者依然是人類。
小度目前不能完全明白人類的思想,但是要向王峰還有名人堂的頂級大腦學習, 更好服務人類。小度不僅代表百度人工智能,更代表中國。這次人機大戰是百度大腦第一次出現在公開場合的比賽,結果無法知道,只能靜待其觀。
《最強大腦》Dr.魏:人工智能的后面也是人,是科學家工作的結晶
人認為最簡單的事情,對人工智能來說是很困難的。比如運動,雖然三歲的時候你就會爬樓梯,但是現在我們都不知道怎么讓機器人像人一樣流暢地爬樓梯,特別是樓梯的好多參數是無法預知的時候。
人可以爬各種各樣的樓梯,在不同光照條件,不同身體狀況等。但是機器人到現在無法象人一樣流暢。從進化上來說,運動,包括像爬樓梯這樣的運動,大腦很早就學會了。
而人學會圍棋對進化中的大腦來說,是很晚才開始玩的。所以,對人來說,樓梯容易一點,圍棋難一點。但是可能對機器來說圍棋更容易一些,上樓梯更難一些。
感知和運動,這是人類擅長的。這個事情我們就干了幾百萬年,我們恰恰不擅長邏輯和運算為代表的抽象思維能力。機器不擅長感知和運動。你會發現機器人能下圍棋或者記下海量的信息,但是沒有辦法像人這樣運動,或者像人一樣去感知這個復雜而快速變化的世界。
人工智能目前擅長的是一個規則定義清楚的東西,他能夠解決,就是圍棋。圍棋是有規則的,他是有一個目標狀態,就是我占得去比你大,我把你圍死了,國際象棋更是,我就把你kill。目前人工智能算法能解決的問題很多都是有規則的,或者目標狀態定義清楚的。但是人類社會,人腦要實現的東西并沒有規則,甚至連準確的目標狀態都沒法提前知道。
人的很多技能,就是一直練下去一直會提升。除了有些是生理上的衰老,你的肌肉系統衰老,那沒辦法。但是很多技能,如果不被物理身體限制的話,很多技能都是越練越好。另外,人類的整體智商是逐年提升的,所謂的弗林效應,平均智商每10年提高3個點左右,當然,主要提高的是抽象思維能力。
人工智能后面也是人,它是很多工程師和科學家工作的結晶。機器贏人類,這是科技發展的必然結果。這天遲早會到來,只是來的早和晚的事情。
科技的發展,其實是超越我們的想象的。這一天遲早會到來,包括我們目前還不能實現的通用人工智能。只是現在的工程師做的是一個一個區域地攻克,有些硬骨頭要啃。在這舞臺上你可以說在某些領域人工智能已經達到登峰造極的程度了。
人工智能在面孔識別上超過人類。應該是2012年,就說人臉識別超過了人類的平均水平,是里程碑事件。那現在,百度大腦超越的人類中出類拔萃的一群人。可以說在這個專業方向上,人工智能的準確率已經達到很高的水準,下一步應該是提高運算的效率和能耗。
任何新技術出現的時候老百姓都恐慌,汽車出現恐慌,火車出現恐慌,計算機出現恐慌。這個是終極恐慌,因為汽車出現的恐慌只是這個東西很快,能撞死我。火車也是一樣。
老百姓第一想到的是自己的失業,自動化的工廠起來想的是產業工人的失業,人工智能的出現,可能讓很多一般智力活動(包括很多白領的工作)甚至專業人員(包括某些領域的醫生)的工作受到威脅。但是,我覺得人類的整體的失業率不一定會下滑,有些的工作死了,新的工作又產生了。
百度深度學習研究院主任林元慶: 打敗人類不是目的
百度這幾年在人工智能上投入了相當的力量做技術研發,我們想在人比較擅長的領域和人較量一下,到底我們的水平做到什么樣了,在這些方面是不是和人接近,還是說有很大的差距。
打敗人類不是目的,希望我們能演化出很好的技術服務人類。
百度這幾年在人工智能上投入了相當的力量做技術研發,我們想在人比較擅長的領域和人較量一下,到底我們的水平做到什么樣了,在這些方面是不是和人接近,還是說有很大的差距。









 工商網監
工商網監
評論