 電子發(fā)燒友App
電子發(fā)燒友App


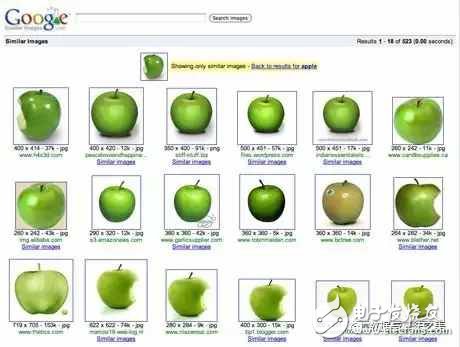
很多搜索引擎可以用一張圖片,搜索互聯(lián)網(wǎng)上所有與它相似的圖片。你輸入網(wǎng)片的網(wǎng)址,或者直接上傳圖片,Google就會(huì)找出與其相似的圖片。下面這張圖片是美國(guó)女演員Alyson Hannigan。

上傳后,Google返回如下結(jié)果:

類(lèi)似的”相似圖片搜索引擎”還有不少,TinEye甚至可以找出照片的拍攝背景。
===================================================
這種技術(shù)的原理是什么?計(jì)算機(jī)怎么知道兩張圖片相似呢?
根據(jù)Neal Krawetz博士的解釋?zhuān)矸浅:?jiǎn)單易懂。我們可以用一個(gè)快速算法,就達(dá)到基本的效果。
這里的關(guān)鍵技術(shù)叫做”感知哈希算法”(Perceptual hash algorithm),它的作用是對(duì)每張圖片生成一個(gè)”指紋”(fingerprint)字符串,然后比較不同圖片的指紋。結(jié)果越接近,就說(shuō)明圖片越相似。
下面是一個(gè)最簡(jiǎn)單的實(shí)現(xiàn):
第一步,縮小尺寸。
將圖片縮小到8×8的尺寸,總共64個(gè)像素。這一步的作用是去除圖片的細(xì)節(jié),只保留結(jié)構(gòu)、明暗等基本信息,摒棄不同尺寸、比例帶來(lái)的圖片差異。

第二步,簡(jiǎn)化色彩。
將縮小后的圖片,轉(zhuǎn)為64級(jí)灰度。也就是說(shuō),所有像素點(diǎn)總共只有64種顏色。
第三步,計(jì)算平均值。
計(jì)算所有64個(gè)像素的灰度平均值。
第四步,比較像素的灰度。
將每個(gè)像素的灰度,與平均值進(jìn)行比較。大于或等于平均值,記為1;小于平均值,記為0。
第五步,計(jì)算哈希值。
將上一步的比較結(jié)果,組合在一起,就構(gòu)成了一個(gè)64位的整數(shù),這就是這張圖片的指紋。組合的次序并不重要,只要保證所有圖片都采用同樣次序就行了。

得到指紋以后,就可以對(duì)比不同的圖片,看看64位中有多少位是不一樣的。在理論上,這等同于計(jì)算“漢明距離”(Hamming distance)。如果不相同的數(shù)據(jù)位不超過(guò)5,就說(shuō)明兩張圖片很相似;如果大于10,就說(shuō)明這是兩張不同的圖片。
具體的代碼實(shí)現(xiàn),可以參見(jiàn)Wote用python語(yǔ)言寫(xiě)的imgHash.py。代碼很短,只有53行。使用的時(shí)候,第一個(gè)參數(shù)是基準(zhǔn)圖片,第二個(gè)參數(shù)是用來(lái)比較的其他圖片所在的目錄,返回結(jié)果是兩張圖片之間不相同的數(shù)據(jù)位數(shù)量(漢明距離)。
這種算法的優(yōu)點(diǎn)是簡(jiǎn)單快速,不受圖片大小縮放的影響,缺點(diǎn)是圖片的內(nèi)容不能變更。如果在圖片上加幾個(gè)文字,它就認(rèn)不出來(lái)了。所以,它的最佳用途是根據(jù)縮略圖,找出原圖。
實(shí)際應(yīng)用中,往往采用更強(qiáng)大的pHash算法和SIFT算法,它們能夠識(shí)別圖片的變形。只要變形程度不超過(guò)25%,它們就能匹配原圖。這些算法雖然更復(fù)雜,但是原理與上面的簡(jiǎn)便算法是一樣的,就是先將圖片轉(zhuǎn)化成Hash字符串,然后再進(jìn)行比較。
昨天,我在isnowfy的網(wǎng)站看到,還有其他兩種方法也很簡(jiǎn)單,這里做一些筆記。
一、顏色分布法
每張圖片都可以生成顏色分布的直方圖(color histogram)。如果兩張圖片的直方圖很接近,就可以認(rèn)為它們很相似。
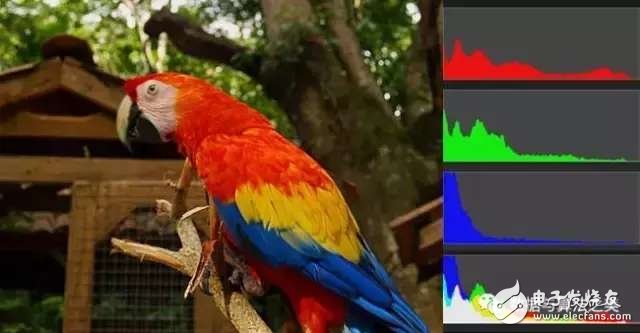
任何一種顏色都是由紅綠藍(lán)三原色(RGB)構(gòu)成的,所以上圖共有4張直方圖(三原色直方圖 + 最后合成的直方圖)。
如果每種原色都可以取256個(gè)值,那么整個(gè)顏色空間共有1600萬(wàn)種顏色(256的三次方)。針對(duì)這1600萬(wàn)種顏色比較直方圖,計(jì)算量實(shí)在太大了,因此需要采用簡(jiǎn)化方法。可以將0~255分成四個(gè)區(qū):0~63為第0區(qū),64~127為第1區(qū),128~191為第2區(qū),192~255為第3區(qū)。這意味著紅綠藍(lán)分別有4個(gè)區(qū),總共可以構(gòu)成64種組合(4的3次方)。
任何一種顏色必然屬于這64種組合中的一種,這樣就可以統(tǒng)計(jì)每一種組合包含的像素?cái)?shù)量。
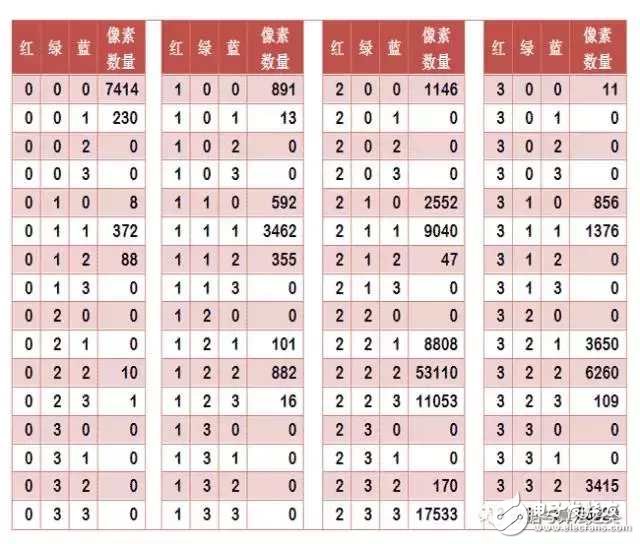
上圖是某張圖片的顏色分布表,將表中最后一欄提取出來(lái),組成一個(gè)64維向量(7414, 230, 0, 0, 8, …, 109, 0, 0, 3415, 53929)。這個(gè)向量就是這張圖片的特征值或者叫”指紋”。
于是,尋找相似圖片就變成了找出與其最相似的向量。這可以用皮爾遜相關(guān)系數(shù)或者余弦相似度算出。
二、內(nèi)容特征法
除了顏色構(gòu)成,還可以從比較圖片內(nèi)容的相似性入手。
首先,將原圖轉(zhuǎn)成一張較小的灰度圖片,假定為50×50像素。然后,確定一個(gè)閾值,將灰度圖片轉(zhuǎn)成黑白圖片。

如果兩張圖片很相似,它們的黑白輪廓應(yīng)該是相近的。于是,問(wèn)題就變成了,第一步如何確定一個(gè)合理的閾值,正確呈現(xiàn)照片中的輪廓?
顯然,前景色與背景色反差越大,輪廓就越明顯。這意味著,如果我們找到一個(gè)值,可以使得前景色和背景色各自的”類(lèi)內(nèi)差異最小”(minimizing the intra-class variance),或者”類(lèi)間差異最大”(maximizing the inter-class variance),那么這個(gè)值就是理想的閾值。
1979年,日本學(xué)者大津展之證明了,”類(lèi)內(nèi)差異最小”與”類(lèi)間差異最大”是同一件事,即對(duì)應(yīng)同一個(gè)閾值。他提出一種簡(jiǎn)單的算法,可以求出這個(gè)閾值,這被稱(chēng)為“大津法”(Otsu’s method)。下面就是他的計(jì)算方法。
假定一張圖片共有n個(gè)像素,其中灰度值小于閾值的像素為 n1 個(gè),大于等于閾值的像素為 n2 個(gè)( n1 + n2 = n )。w1 和 w2 表示這兩種像素各自的比重。
w1 = n1 / n
w2 = n2 / n
再假定,所有灰度值小于閾值的像素的平均值和方差分別為 μ1 和 σ1,所有灰度值大于等于閾值的像素的平均值和方差分別為 μ2 和 σ2。于是,可以得到
類(lèi)內(nèi)差異 = w1(σ1的平方) + w2(σ2的平方)
類(lèi)間差異 = w1w2(μ1-μ2)^2
可以證明,這兩個(gè)式子是等價(jià)的:得到”類(lèi)內(nèi)差異”的最小值,等同于得到”類(lèi)間差異”的最大值。不過(guò),從計(jì)算難度看,后者的計(jì)算要容易一些。
下一步用”窮舉法”,將閾值從灰度的最低值到最高值,依次取一遍,分別代入上面的算式。使得”類(lèi)內(nèi)差異最小”或”類(lèi)間差異最大”的那個(gè)值,就是最終的閾值。具體的實(shí)例和Java算法,請(qǐng)看這里。
 ?
?
有了50×50像素的黑白縮略圖,就等于有了一個(gè)50×50的0-1矩陣。矩陣的每個(gè)值對(duì)應(yīng)原圖的一個(gè)像素,0表示黑色,1表示白色。這個(gè)矩陣就是一張圖片的特征矩陣。
兩個(gè)特征矩陣的不同之處越少,就代表兩張圖片越相似。這可以用”異或運(yùn)算”實(shí)現(xiàn)(即兩個(gè)值之中只有一個(gè)為1,則運(yùn)算結(jié)果為1,否則運(yùn)算結(jié)果為0)。對(duì)不同圖片的特征矩陣進(jìn)行”異或運(yùn)算”,結(jié)果中的1越少,就是越相似的圖片。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論