 電子發燒友App
電子發燒友App


作者 | 孫健波(阿里巴巴技術專家)、趙鈺瑩
導讀:云原生時代,Kubernetes 的重要性日益凸顯。然而,大多數互聯網公司在 Kubernetes 上的探索并非想象中順利,Kubernetes 自帶的復雜性足以讓一批開發者望而卻步。本文中,阿里巴巴技術專家孫健波在接受采訪時基于阿里巴巴 Kubernetes 應用管理實踐過程提供了一些經驗與建議,以期對開發者有所幫助。
在互聯網時代,開發者更多是通過頂層架構設計,比如多集群部署和分布式架構的方式來實現出現資源相關問題時的快速切換,做了很多事情來讓彈性變得更加簡單,并通過混部計算任務來提高資源利用率,云計算的出現則解決了從 CAPEX 到 OPEX 的轉變問題。
云計算時代讓開發可以聚焦在應用價值本身,相較于以前開發者除了業務模塊還要投入大量精力在存儲、網絡等基礎設施,如今這些基礎設施都已經像水電煤一樣便捷易用。云計算的基礎設施具有穩定、高可用、彈性伸縮等一系列能力,除此之外還配套解決了一系列應用開發“最佳實踐”的問題,比如監控、審計、日志分析、灰度發布等。原來,一個工程師需要非常全面才能做好一個高可靠的應用,現在只要了解足夠多的基礎設施產品,這些最佳實踐就可以信手拈來了。但是,在面對天然復雜的 Kubernetes 時,很多開發者都無能為力。
作為 Jira 和代碼庫 Bitbucket 背后的公司,Atlassian 的 Kubernetes 團隊首席工程師 Nick Young 在采訪中表示:
雖然當初選擇 Kubernetes 的戰略是正確的(至少到現在也沒有發現其他可能的選擇),解決了現階段遇到的許多問題,但部署過程異常艱辛。
那么,有好的解決辦法嗎?
太過復雜的 Kubernetes
“如果讓我說 Kubernetes 存在的問題,當然是‘太復雜了’”,孫健波在采訪中說道,“不過,這其實是由于 Kubernetes 本身的定位導致的。”
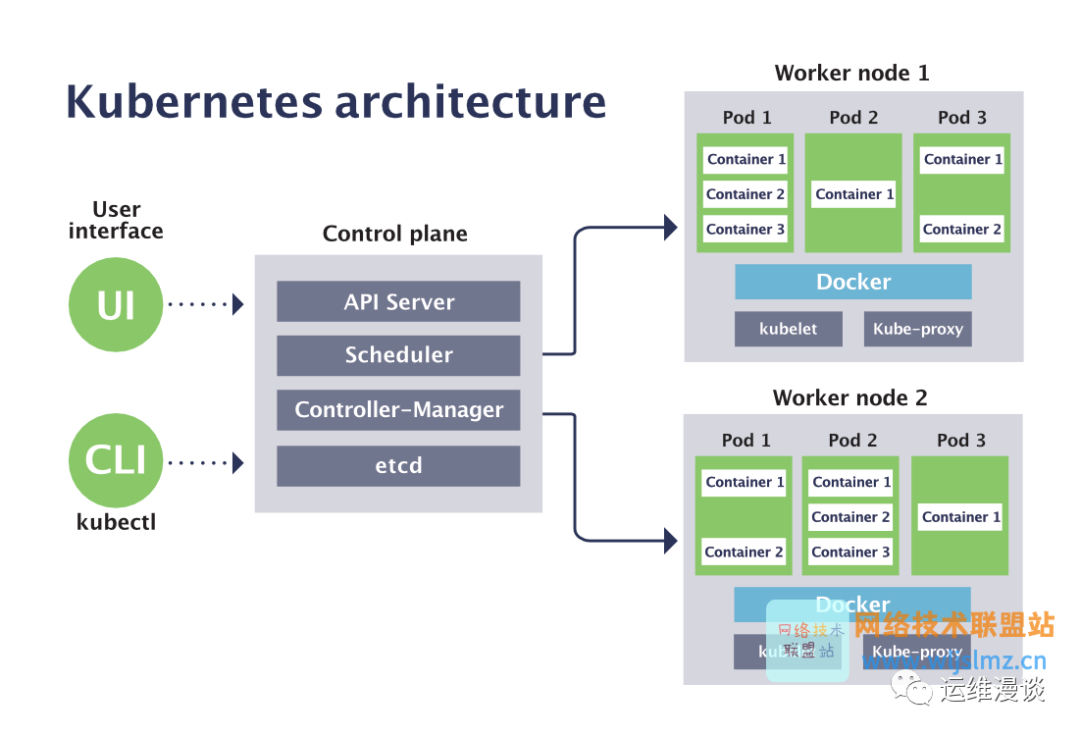
孫健波補充道,Kubernetes 的定位是“platform for platform”。它的直接用戶,既不是應用開發者,也不是應用運維,而是“platform builder”,也就是基礎設施或者平臺級工程師。但是,長期以來,我們對 Kubernetes 項目很多時候都在錯位使用,大量的應用運維人員、甚至應用研發都在直接圍繞 Kubernetes 很底層的 API 進行協作,這是導致很多人抱怨 “Kubernetes 實在是太復雜了”的根本原因之一。
這就好比一名 Java Web 工程師必須直接使用 Linux Kernel 系統調用來部署和管理業務代碼,自然會覺得 Linux “太反人類了”。所以,目前 Kubernetes 項目實際上欠缺一層更高層次的封裝,來使得這個項目能夠對上層的軟件研發和運維人員更加友好。
如果可以理解上述的定位,那么 Kubernetes 將 API 對象設計成 all-in-one 是合理的,這就好比 Linux Kernel 的 API,也不需要區分使用者是誰。但是,當開發者真正要基于 K8s 管理應用、并對接研發、運維工程師時,就必然要考慮這個問題,也必然要考慮如何做到像另一層 Linux Kernel API 那樣以標準、統一的方式解決這個問題,這也是阿里云和微軟聯合開放云原生應用模型 Open Application Model (OAM)的原因。
有狀態應用支持
除了天然的復雜性問題,Kubernetes 對于有狀態應用的支持也一直是眾多開發者花費大量時間研究和解決的問題,并不是不可以支持,只是沒有相對較優的解決方案。目前,業內主流的針對有狀態應用的解法是 Operator,但是編寫 Operator 其實是很困難的。
在采訪中,孫健波表示,這是因為 Operator 本質上是一個“高級版”的 K8s 客戶端,但是 K8s API Server 的設計,是“重客戶端”的模型,這當然是為了簡化 API Server 本身的復雜度,但也導致了無論是 K8s client 庫,還是以此為基礎的 Operator,都變的異常復雜和難以理解:它們都夾雜了大量 K8s 本身的實現細節,比如 reflector、cache store、informer 等。這些,并不應該是 Operator 編寫者需要關心的,Operator 編寫者應該是有狀態應用本身的領域專家(比如 TiDB 的工程師),而不應該是 K8s 專家。這是現在 K8s 有狀態應用管理最大的痛點,而這可能需要一個新的 Operator 框架來解決這個問題。
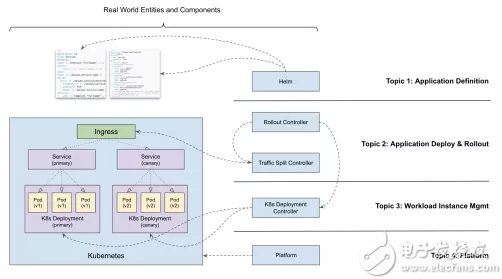
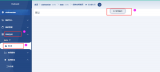
另一方面,復雜應用的支持不止編寫 Operator 這么簡單,這里還需要有狀態應用交付的技術支撐,這是目前社區上各種持續交付項目都有意或者無意間忽略掉的事情。事實上,持續交付一個基于 Operator 的有狀態應用,跟交付一個無狀態的 K8s Deployment 的技術挑戰完全不是一個量級的。這也是孫健波所在團隊在 CNCF 應用交付領域小組(CNCF SIG App Deliver)倡導“應用交付分層模型”的重要原因:如下圖所示,四層模型分別為“應用定義”、“應用交付”、“應用運維與自動化”、“平臺層”,只有通過這四個層不同能力的合力協作,才能真正做到高質量和高效率的交付有狀態應用。
舉個例子,Kubernetes API 對象的設計是“all-in-one”的, 即:應用管理過程中的所有參與者,都必須在同一個 API 對象上進行協作。這就導致開發者會看到,像 K8s Deployment 這樣的 API 對象描述里, 既有應用開發關注的字段,也可以看到運維關注的字段,還有一些字段可能還是被多方關注的。
實際上,無論是應用開發、應用運維,還是 HPA 這樣的 K8s 自動化能力,它們都有可能需要控制一個 API 對象里的同一個字段。最典型的情況就是副本數(replica)這種參數。但是,到底誰 own 這個字段,是一個非常棘手的問題。
綜上,既然 K8s 的定位是云時代的 Linux Kernel,那么 Kubernetes 就必須在 Operator 支持、API 層以及各類接口定義的完善上不斷進行突破,使得更多生態參與者可以更好的基于 K8s 構建自己的能力和價值。
阿里巴巴大規模 Kubernetes 實踐
如今,Kubernetes 在阿里經濟體的應用場景涵蓋了阿里方方面面的業務,包括電商、物流、離在線計算等,這也是目前支撐阿里 618、雙 11 等互聯網級大促的主力軍之一。阿里集團和螞蟻金服內部運行了數十個超大規模的 K8s 集群,其中最大的集群約 1 萬個機器節點,而且這其實還不是能力上限。每個集群都會服務上萬個應用。在阿里云 Kubernetes 服務(ACK)上,我們還維護了上萬個用戶的 K8s 集群,這個規模和其中的技術挑戰在全世界也是首屈一指的。
孫健波透露,阿里內部早在 2011 年便開始了應用容器化,當時最開始是基于 LXC 技術構建容器,隨后開始用自研的容器技術和編排調度系統。整套系統本身沒有什么問題,但是作為基礎設施技術團隊,目標一定是希望阿里的基礎技術棧能夠支撐更廣泛的上層生態,能夠不斷演進和升級,因此,整個團隊又花了一年多時間逐漸補齊了 K8s 的規模和性能短板。總體來看,升級為 K8s 是一個非常自然的過程,整個實踐過程其實也很簡單:
第一:解決應用容器化的問題,這里需要合理利用 K8s 的容器設計模式;
第二:解決應用定義與描述的問題,這里需要合理的利用 OAM,Helm 等應用定義工具和模型來實現,并且要能夠對接現有的應用管理能力;
第三:構建完整的應用交付鏈,這里可以考慮使用和集成各種持續交付能力。
如上的三步完成,就具備了對接研發、運維、上層 PaaS 的能力,能夠講清楚自己的平臺價值。接下來就可以試點開始,在不影響現有應用管理體系的前提下,一步步換掉下面的基礎設施。
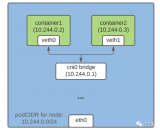
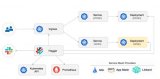
Kubernetes 本身并不提供完整的應用管理體系,這個體系是整個云原生的生態基于 K8s 構建出來的,可以用下圖表示:

Helm 就是其中最成功的一個例子,它位于整個應用管理體系的最上面,也就是第 1 層,還有 Kustomize 等各種 YAML 管理工具,CNAB 等打包工具,它們都對應在第 1.5 層。然后有 Tekton、Flagger 、Kepton 等應用交付項目,對應在第 2 層。Operator ,以及 K8s 的各種工作負載組件,比如 Deployment、StatefulSet,對應在第 3 層。最后才是 K8s 的核心功能,負責對工作負載的容器進行管理,封裝基礎設施能力,對各種不同的工作負載對接底層基礎設施提供 API 等。
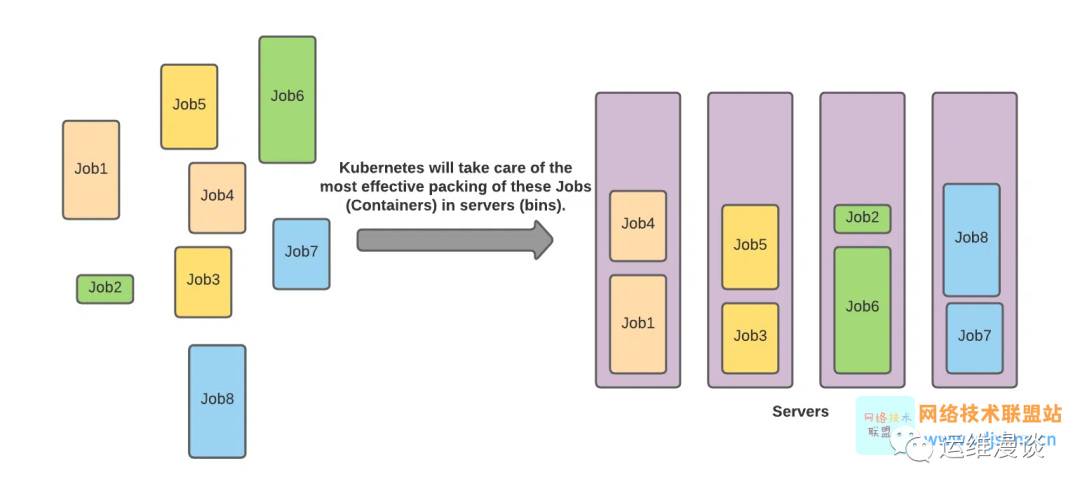
初期,整個團隊最大的挑戰來自于規模和性能瓶頸,但這個解法也是最直接的。孫健波表示,隨著規模逐漸增大,我們看到規模化鋪開 K8s 最大的挑戰實際上是如何基于 K8s 進行應用管理和對接上層生態。比如,我們需要統一的管控來自數十個團隊、數百個不同目的的 Controller;我們需要以每天近萬次的頻率交付來自不同團隊的生產級應用,這些應用的發布、擴容策略可能完全不同;我們還需要對接數十個更加復雜的上層平臺,混合調度和部署不同形態的作業以追求最高的資源利用率,這些訴求才是阿里巴巴 Kubernetes 實踐要解決的問題,規模和性能只是其中一個組成部分。
除了 Kubernetes 的原生功能外,在阿里巴巴內部會開發大量的基礎設施以 K8s 插件的形式對接到這些功能上,隨著規模的擴大,用統一的方式發現和管理這些能力成為了一個關鍵問題。
此外,阿里巴巴內部也有眾多存量 PaaS,這些是為了滿足用戶不同業務場景上云所構建的,比如有的用戶希望上傳一個 Java 的 War 包就可以運行,有的用戶希望上傳一個鏡像就可以運行。在這些需求背后,阿里各團隊幫用戶做了許多應用管理的工作,這也是存量 PaaS 出現的原因,而這些存量 PaaS 與 Kubernetes 對接過程可能會產生各種問題。目前,阿里正在通過 OAM 這個統一標準的應用管理模型,幫助這些 PaaS 向 K8s 底盤進行對接和靠攏,實現標準化和云原生化。
解耦運維和研發
通過解耦,Kubernetes 項目以及對應的云服務商就可以為不同的角色暴露不同維度、更符合對應用戶訴求的聲明式 API。比如,應用開發者只需要在 YAML 文件中聲明”應用 A 要使用 5G 可讀寫空間“,應用運維人員則只需要在對應的 YAML 文件里聲明”Pod A 要掛載 5G 的可讀寫數據卷“。這種”讓用戶只關心自己所關心的事情“所帶來的專注力,是降低 Kubernetes 使用者學習門檻和上手難度的關鍵所在。
孫健波表示,現在大多數的解法實際上是“悲觀處理”。比如,阿里內部的 PaaS 平臺,為了減輕研發使用的負擔,長期以來只開放給研發設置 5 個 Deployment 的字段。這當然是因為 K8s YAML "all-in-one"的設計,使得完整的 YAML 對研發來說太復雜,但這也導致 K8s 本身的能力,絕大多數情況下對研發來說是完全沒有體感的。而對 PaaS 平臺運維來說,他反而覺得 K8s YAML 太簡單,不夠描述平臺的運維能力,所以要給 YAML 文件添加大量 annotation。
此外,這里的核心問題在于,對運維人員而言,這種“悲觀處理”的結果就是他自己太“獨裁”,包攬了大量細節工作,還費力不討好。比如擴容策略,目前就是完全由運維一方說了算。可是,研發作為編寫代碼的實際人員,才是對應用怎么擴容最有發言權的,而且研發人員也非常希望把自己的意見告訴運維,好讓 K8s 更加 靈活,真正滿足擴容需求。但這個訴求在目前的系統里是無法實現的。
所以,“研發和運維解耦”并不是要把兩者割裂,而是要給研發提供一個標準、高效的,同運維進行溝通的方式,這也是 OAM 應用管理模型要解決的問題。孫健波表示,OAM 的主要作用之一就是提供一套研發從自己的角度表達訴求的標準和規范,然后這套標準“你知,我知,系統知”,那么上面這些問題也就迎刃而解了。
具體來說,OAM 是一個專注于描述應用的標準規范。有了這個規范,應用描述就可以徹底與基礎設施部署和管理應用的細節分開。這種關注點分離(Seperation of Conerns)的設計好處是非常明顯的。舉個例子,在實際生產環境中,無論是 Ingress、CNI 還是 Service Mesh,這些表面看起來一致的運維概念,在不同的 Kubernetes 集群中可謂千差萬別。通過將應用定義與集群的運維能力分離,我們就可以讓應用開發者更專注應用本身的價值點,而不是”應用部署在哪“這樣的運維細節。
此外,關注點分離讓平臺架構師可以輕松地把平臺運維能力封裝成可被復用的組件,從而讓應用開發者專注于將這些運維組件與代碼進行集成,從而快速、輕松地構建可信賴的應用。OAM 的目標是讓簡單的應用管理變得更加輕松,讓復雜的應用交付變得更加可控。孫健波表示,未來,團隊將專注于將這套體系逐步向云端 ISV 和軟件分發商側推進,讓基于 K8s 的應用管理體系真正成為云時代的主流。
嘉賓介紹:孫健波,阿里巴巴技術專家。Kubernetes 項目社區成員。目前在阿里巴巴參與大規模云原生應用交付與管理相關工作,2015 年參與編寫《Docker 容器與容器云》技術書籍。曾任職七牛,參與過時序數據庫、流式計算、日志平臺等項目相關應用上云過程。
今年 12 月 6-7 日北京 ArchSummit 全球架構師峰會上,孫健波老師會繼續分享《阿里巴巴 Kubernetes 應用管理實踐中的經驗與教訓》,會介紹阿里對解耦研發和運維過程中的現有實踐,以及實踐本身存在的問題;以及實施的標準化、統一化解決的思路,以及對社區的進一步思考。
本文為云棲社區原創內容,未經允許不得轉載。































 工商網監
工商網監
評論