 電子發燒友App
電子發燒友App


背景及現狀
奇安信集團作為一家網絡安全公司,專門為政府、企業,教育、金融等機構和組織提供企業級網絡安全技術、產品和服務,奇安信的 NGSOC 產品的核心引擎是一個 CEP 引擎,用于實時檢測網絡攻擊,其技術演進過程如下圖所示。
2015 年開始使用基于 Esper 的 CEP 方案,但是當時遇到了很多問題,其中最顯著的是性能問題,因為 Esper 對于規則條目的支持數量不多,一般情況下超過幾十條就會受到嚴重影響;
2017 年奇安信的技術方案演進到了使用 C++ 實現的 Dolphin 1.0,其在單機上的性能表現大幅度提升;
2018 年奇安信決定將技術方案全面轉向基于 Flink 的 Sabre。

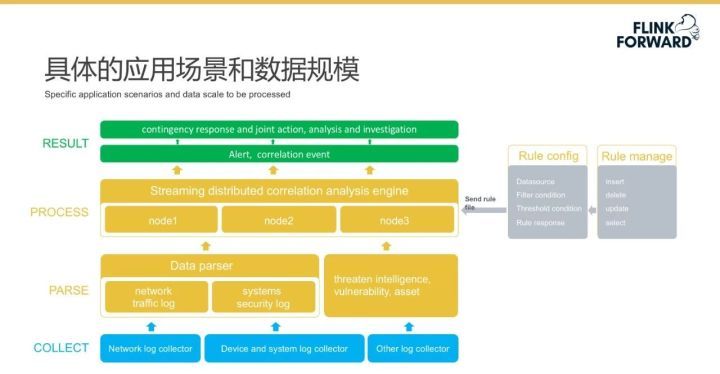
奇安信產品具體的應用場景是企業系統的安全檢測和數據分析,其自下而上分為四個業務處理流程,分別是數據的采集、解析、處理和展示結果,這其中最核心的是第三層數據處理。該產品的用戶主要是安全規則團隊,其可以使用規則編輯器來對安全規則進行添加、刪除、編輯和查找操作,并可批量啟動/停用多個規則,同時可以將處于啟動狀態的有效規則統一發送給產品。
在數據規模方面,產品解決的不是一個或幾個大型數據集群的問題,而是數以百計的中小型數據集群的運維問題。在 B2B 領域,由于產品是直接部署到客戶方,很多客戶使用的是內部隔離網,無法連接外網,且沒有專門人員負責集群的運維,這種情況下哪怕一個小升級都會耗費大量時間。因此,產品更多關注該領域下數據集群可運維性問題的解決。
奇安信在最初計劃使用 Flink 作為技術方案并進行調研的過程中,發現了其一系列的痛點問題。由于企業級硬件資源環境受限,規則集數量及種類不確定,使得 Flink 程序運行難以控制,并且現有的庫“Flink SQL”和“Flink CEP”均不能滿足其業務性能需求。具體的痛點如下:
**1.不能進行語義優化、不便于動態更新規則。 ** 網絡安全事件井噴式發生的今天,安全需求迅速擴展。為了能夠在有限時間內對特定語義的快速支持,關聯引擎的整體架構必須異常靈活,才能適應未來安全分析場景的各種需求,而基于開源關聯引擎實現的產品會在激烈的需求變化時遇到很多問題。
2.狀態監控 & 高可用支持不足。
面向企業級的網絡安全監測引擎具有一些特定需求,當前解決方案對此支持較差。
比如,現實情況中客戶對算子實例和 Taskmanager 概念較為模糊,真正關心的運行狀態的基本單位是規則。Flink 監控頁面顯示的是算子實例及 Task manager 進程整體內存的運行狀態,而在網絡安全監控的業務場景中,對運行狀態和資源的監控均需要細化到規則層面。
其次,在算子層面,Flink 原生 Window 算子,沒有較好的資源(CPU / 內存)保護機制,且存在大量重復告警,不符合網絡安全監測領域的業務需求。
再次,Flink 缺乏一些必要算子,例如不支持“不發生算子”。一個較為常見的應用場景,某條規則指定在較長時間內沒收到某臺服務器的系統日志,則認為此臺服務器發生了異常,需要及時通知用戶。
3.CEP 網絡負載高、CPU 利用率低。
和互聯網企業內部使用的大型集群相比,奇安信面向的企業級應用集群規模較小,硬件資源受限,且客戶的定制需求較多,導致安全監測的規則要求更嚴格,引擎發布成本較高。但是,現有的 Flink 開源解決方案,或者需要根據業務需求進行改造,或者性能較差,均不能較好地解決上述問題。
首先,原生 Flink 只提供了函數式編程模式,即需要手動編寫復合特定業務需求的固定程序代碼,由此導致開發測試周期較長,不便于動態更新規則,可復用性較弱,且不能從全局語義層面進行優化,性能較差。
其次,Flink-CEP 僅是一個受限的序列算子,在運行時需要將所有數據傳輸到 CEP 算子,然后在 CEP 算子中串行執行各個條件語句。這種匯集到單點的運行模式,較多的冗余數據需要執行條件匹配,由此產生了不必要的網絡負載,而且降低了 CPU 利用率。
再次,還存在一些非官方開源的輕量級 CEP 引擎,比如 Flink-siddhi,功能簡單,不是一個完整的解決方案。
其他的痛點問題還包括不支持空值窗口出發、以及聚合不保存原始數據等。

為了解決上述問題,奇安信在 Flink 的基礎上推出了一種全新的 CEP 引擎, Sabre。其整體架構如下圖所示,其中包含三大核心模塊,左側是配置端,中間是 Sabre-server,右側是 Sabre 運行端。核心數據流存在兩條主線,紅線表示規則的提交、編譯、發布和運行流程。綠線表示狀態監控的生成、收集、統計和展示流程。如圖所示,此架構與 Hive 極為相似,是一種通用的大數據 OLAP 系統架構。下面詳細介紹三大核心模塊和兩大核心數據流。
首先,通過規則配置端創建規則,采用性能保護配置端修改性能保護策略;
然后,將任務所屬的規則文件和性能保護策略文件一并推送到 Sabre-server 提供的 REST 接口,該接口會調用文件解析及優化方法構建規則有向無環圖。
接著,執行詞法語法分析方法,將規則有向無環圖中各個節點的 EPL 轉換為與其對應的 AST(AbstractSyntax Tree,抽象語法樹),再將 AST 翻譯為任務 java 代碼。
最后,調用 maven 命令打包 java 代碼為任務 jar 包,并將任務 jar 包及基礎運行庫一并提交到 Flink-on-YARN 集群。
Flink 有多種運行模式(例如 standalone Flink cluster、Flink cluster on YARN、Flink job on YARN 等),Sabre 采用了“Flink job on YARN”模式,在奇安信 NGSOC 應用的特定場景下,采用 YARN 可統一維護硬件資源,并且使用 Flink job on YARN 可與 Hadoop 平臺進行無縫對接,以此很好的實現了任務間資源隔離。
在 Sabre 任務執行過程中,Kafka 數據源向引擎提供原始事件。引擎處理結果分為回注事件和告警事件兩類。告警事件會輸出到目的 Kafka,供下級應用消費。回注事件表示一條規則的處理結果可直接回注到下級規則,作為下級規則的數據源事件,由此可實現規則的相互引用。
綠線流程表示任務執行過程中會定時輸出節點的運行監控消息到 Sabre-server 的監控消息緩存器,然后監控消息統計器再匯總各個規則實例的運行監控消息,統計為整條規則的運行監控狀態,最后通過 Sabre-server 提供的 REST 接口推送給規則監控端。
技術架構

Sabre 的組件依賴與版本兼容情況如下圖所示。
大多數情況下,奇安信會以黑盒的方式發布產品,但是如果用戶方已經部署大數據處理平臺,則產品會以 APP 的方式提供使用。
由于客戶規模較大,項目種類較多,部署環境較為復雜,或者存在多種 Yarn 集群版本,或者 Sabre 需作為單一 Flink 應用發布到客戶已部署的 Flink 集群。
如何節省成本及提高實施效率,快速適配上述復雜的部署環境是個亟需解決的問題,為此 Sabre 的設計原則是僅采用 Flink 的分布式計算能力,業務代碼盡可能減少對 API 層的依賴,以便于兼容多種 Flink 版本。
如圖所示,Deploy、Core、APIs、Libraries 四層是大家熟知的 Flink 基本的組件棧。Sabre 對 API 層的依賴降到了最低,只引用了 DataStream、KeyedStream 和 SplitStream 三種數據流 API。函數依賴只包括 DataStream 的 assignTimestamps、flatMap、union、keyBy、split、process、addSink 等函數,KeyedStream 最基礎的 process 函數,以及 SplitStream 的 select 函數。由于依賴的 Flink API 較少,Sabre 可以很容易適配到各個 Flink 版本,從而具有良好的 Flink 版本兼容性。

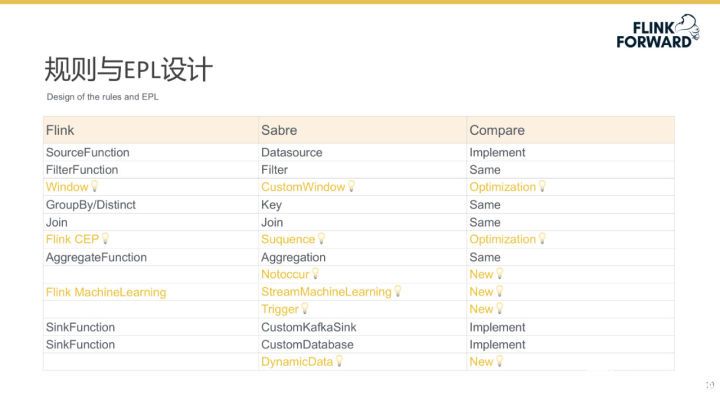
在算子方面,Sabre 對 Flink 進行了一系列的重構,下圖展示了這 Flink 和 Sabre 這二者之間的對比關系,其中主要包含三列,即 Flink 原生算子、Sabre 算子和兩者之間的比較結果。比較結果主要有四種情況,相同(Same)、實現(Implement)、優化(優化)和新增(New)。Sabre 共有 13 種完全自研的核心算子,其中 Datasource、CustomKafkaSink 和 CustomDatabase 按照 Flink 接口要求做了具體實現,Filter、Key、Join 和 Aggregation 按照 Flink 原有算子的語義做了重新實現,CustomWindow 和 Sequence 在 Flink 原有算子語義的基礎上做了優化實現。
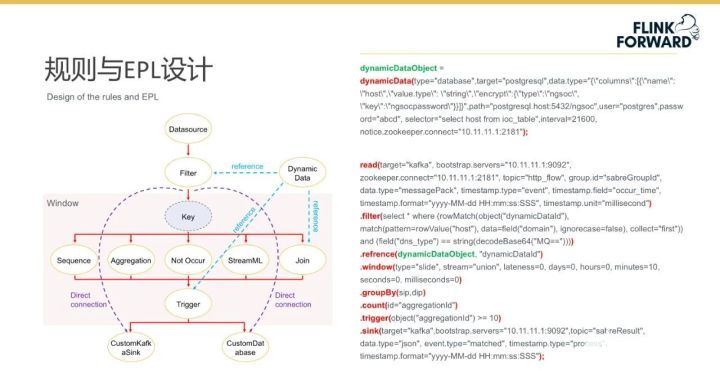
下圖展示了 Sabre 的規則與 EPL 設計。序列 Sequence、聚合 Aggregation、不發生 NotOccur、流式機器學習 StreamML 和連接 Join 均屬于 Window 執行時間包含的計算性算子。藍色虛線表示引用動態數據(Dynamic data),紫色虛線表示 Filter 無須經過 Window 可直連輸出組件。
Window 算子
眾所周知,Join 和 Aggregation 的時間范圍由 Window 限定,而 Flink 原有 Window 算子不適合網絡安全監測需求,為此 Sabre 設計了一種“自定義 Window 算子”,且重新實現了與“自定義 Window 算子”相匹配的 Join 和 Aggregation 算子。全新的 Window 具有以下六個主要特點:
實時觸發、即刻匹配:其目的是為了滿足自動化實時響應的需求,一旦告警發出,會及時觸發響應;
匹配不重復:重復告警對于規則引擎來講是一個常見問題,大量重復告警會增加安全人員的工作量,而該算子會將整個窗口與告警相關的事件全部清空,以此減少重復告警的數量;
糾正亂序:將 Window 窗口以特定單位為邊界切成一個個的時間槽,一旦發現亂序情況,插入亂序事件時可直接定位時間槽,基于流式狀態機進行局部計算,并且窗口事件超時,同步更新計算性算子的值,并入 count 算子,刪除超時事件的同時,同步減少 count 值;
實時資源和狀態監控:由于 Window 對與內存和 CPU 的影響比較大,因此需要對該類資源進行特別監控以及保護;
流量控制:主要是為了更好地保護下級應用。

Sequence 序列算子
Sabre 用 EPL 對 Flink CEP 實現的序列算子進行了重新設計,左邊是 Flink CEP 官方代碼展示,采用程序代碼的方式拼湊“NFA 自動機”。右邊是 Sabre 中 Sequence 算子的實現方式,其中包含了三個不同的 filter,通過正則表達式的使用來提升其表達的能力,并且,Sabre 將 filter 前置,無效事件不會傳輸到 window 算子,從而較少了不必要的網絡負載。并且,只有較少的有效數據需要執行正則匹配,降低了 CPU 利用率(filter 可以并行)。

NotOccur 不發生算子
NotOccur 是 Sabre 在 Flink 基礎上新增的一個算子,支持空事件觸發。

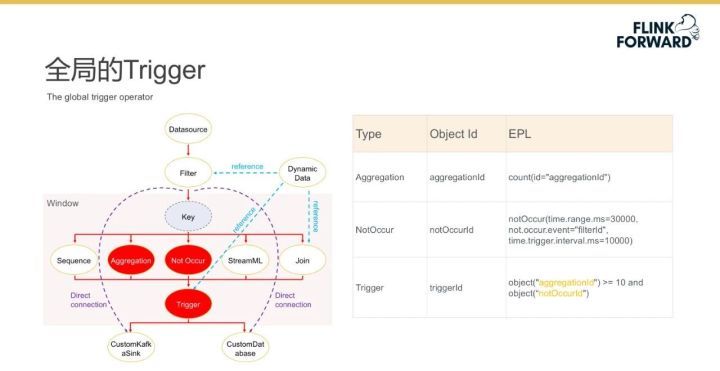
Trigger 全局算子
Sabre 還實現了一種針對窗口的全局觸發器 Trigger,Trigger 能夠將多個子計算性算子組合為復雜表達式,并實現了具有 GroupBy/Distinct 功能的 Key 算子以適配此 Trigger 算子。
Dynamic Data
Dynamicdata 可以映射為數據庫中的一個表,但是對這個表要進行特別的優化,具體來講,如果一個事件的 IP 在威脅情報列表中,而這個威脅情報有可能比較長,比如十幾萬行甚至更長,這種情況下需要對該表數據結構進行優化以提升效率。Dynamic data 可以在其他算子中使用,如 Filter、Join 等。

流式統計與機器學習 StreamML
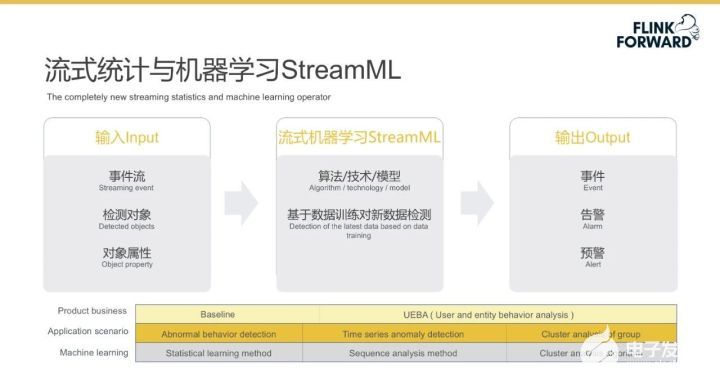
機器學習在網絡異常檢測上已經越來越重要,為適應實時檢測的需求,Sabre 沒有使用 Flink MachineLearning,而是引入了自研的流式機器學習算子 StreamML。
Flink MachineLearning 是一種基于批模式 DataSetApi 實現的機器學習函數庫,而 StreamML 是一種流式的機器學習算子,其目的是為了滿足網絡安全監測的特定需求。與阿里巴巴開源的 Alink 相比,StreamML 允許機器學習算法工程師通過配置規則的方式即可快速驗證算法模型,無需編寫任何程序代碼。并且,流式機器學習算子 StreamML 實現了“模型訓練/更新”與“模型使用”統一的理念。其核心功能是通過算法、技術及模型實現數據訓練及對新數據檢測。該流式機器學習算子 StreamML 引入的輸入有三類,分別是:事件流、檢測對象和對象屬性;輸出也包含三類,分別是:事件、告警和預警。
流式機器學習算子 StreamML 的組件棧包含三部分,從下往上依次為:機器學習方法、應用場景和產品業務。通過基本的機器學習算法(比如:統計學習算法、序列分析算法、聚類分析算法),流式機器學習算子 StreamML 可滿足具體特定的安全監測應用場景(比如:行為特征異常檢測、時間序列異常檢測、群組聚類分析),進而為用戶提供可理解的產品業務(比如:基線、用戶及實體行為分析 UEBA)。
行為特征異常檢測:根據采集的樣本數據(長時間)對統計分析對象建立行為基線,并以此基線為準,檢測發現偏離正常行為模式的行為。例如:該用戶通常從哪里發起連接?哪個運營商?哪個國家?哪個地區?這個用戶行為異常在組織內是否為常見異常?
時間序列異常檢測:根據某一個或多個統計屬性,判斷按時間順序排列的數值序列是否異常,由此通過監測指標變化來發現安全事件。例如:監測某網站每小時的訪問量以防止 DDOS 攻擊;建模每個賬號傳輸文件大小的平均值,檢測出傳輸文件大小的平均值離群的賬號。
群組聚類分析:對數據的特征屬性間潛在相關性進行挖掘,將具有類似特征值的數據進行分組聚類。例如:該用戶是否擁有任何特殊特征?可執行權限/特權用戶?基于執行的操作命令和可訪問的實體,來識別IT管理員、DBA 和其它高權限用戶。

因為采用了 Flink 作為底層運行組件,所以 Sabre 具有與 Flink 等同的執行性能。并且,針對網絡安全監測領域的特定需求,Sabre 還在以下方面進行了性能優化:
全局組件(數據源、動態表)引用優化。由于 Kafka 類型的數據源 topic 有限,而規則數量可動態擴展,導致多個規則會有極大概率共用同一個數據源,根據 EPL 語義等價原則合并相同的數據源,進而可以減少數據輸入總量及線程總數。
全新的匹配引擎。序列 Sequence 算子采用了新穎的流式狀態機引擎,復用了狀態機緩存的狀態,提升了匹配速度。類似優化還包含大規模 IP 匹配引擎和大規模串匹配引擎。在流量、日志中存在大規模 IP 和字符串匹配需求,通過 IP 匹配引擎和大規模串匹配引擎進行優化以提高效率。
表計算表達式優化。對于規則中引用的動態表,會根據表達式的具體特性構建其對應的最優計算數據結構,以避免掃描全表數據,進而確保了執行的時間復雜度為常量值。
自定義流式 Window 算子。采用“時間槽”技術實現了亂序糾正功能,并具有可以實時輸出無重復、無遺漏告警的特性。
圖上字段自動推導,優化事件結構。根據規則前后邏輯關系,推導出規則中標注使用的原始日志相關字段,無須輸出所有字段,以此優化輸出事件結構,減少了輸出事件大小。
圖上數據分區自動推導,優化流拓撲。由于特定的功能需要,Window 往往會緩存大量數據,以致消耗較多內存。通過對全局窗口 Hash 優化,避免所有全局窗口都分配到同一個 Taskmanager 進程,由此提高了引擎整體內存的利用率。

上圖是 Sabre 流式狀態機引擎的表示,其主要負責的功能是序列匹配。圖中左邊是標準的正則引擎,通常的流程可以從 Pattern 到語法樹到 NFA 再到 DFA,也可以從 Paterrn 直接到 NFA;圖左下側是一個正則表達式的 NFA 表示,右側是該正則表達式的 DFA 表示,使用該 DFA 的時候進行了改進(如圖中綠色線)。其目的是為了在出現亂序的時候提升處理性能,在亂序發生在正則表達式后半段的時候,該改進對于性能提升的效果最好。

大規模正則引擎主要使用了兩種互補的方法(圖上半側和下半側)。在將 NFA 轉向 DFA 的時候,很多情況下是不成功的,這種情況下往往會生成 DFA 的半成品,稱為Unfinished-DFA,第一種方法屬于混合狀態自動機,包含 NFA 和 DFA,其適用于Pattern 量少于 1000 的情況。而第二種方法適用于 Pattern 量大于 1000 甚至上萬的情況,該方法中首先需要尋找錨點,再做匹配,以降低整體的時間復雜度。這兩種方法相結合能夠較好地解決大規模正則匹配的問題。
產品運維
多級規則
多級規則是產品運維的一個顯著特點。如下圖所示,為滿足復雜場景需求,一種規則的輸出可直接作為另一種規則的輸入。通過這種規則拆分的方式,能分層構造較為復雜的“多級規則”。如:圖中的“暴力探測”規則結果可以直接回注到下面的“登陸成功 ”規則,而無須額外的通信組件,由此實現更為復雜的“暴力破解”規則。

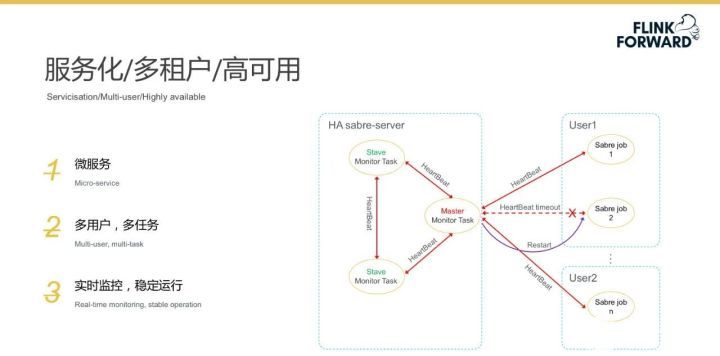
服務化/多租戶/資源監控
產品采用微服務架構,使用多租戶、多任務來滿足多個規則引擎的使用場景,同時對資源進行了實時監控來保證系統的穩定運行。
規則級的狀態/資源監控
規則級的狀態和資源監控是非常重要的產品需求,產品采用分布式監控,提供三級分布式監控能力(用戶、任務和規則),并支持吞吐量、EPS、CPU 和內存的監控。

整體系統保護
整體系統保護主要涉及兩方面,即流量控制和自我保護。
流量控制:為了增強 Sabre 引擎的健壯性,避免因規則配置錯誤,導致生成大量無效告警,在輸出端做了流量控制,以更好地保護下級應用。當下級抗壓能力較弱時(例如數據庫),整個系統會做輸出降級。
自我保護:跑在 JVM 上的程序,經常會遇到由于長時間 Full GC 導致 OOM 的錯誤,并且此時 CPU 占用率往往非常高,Flink 同樣存在上述問題。自我保護功能采用了同時兼顧“Window隸屬規則的優先級”及“Window引用規則數量”兩個條件的加權算法,以此根據全局規則語義實現自動推導 Window 優先級,并根據此優先級確定各個 Window 的自我保護順序。實時監控 CPU 及內存占用,當超過一定閾值時,智能優化事件分布,以防出現 CPU 長期過高或內存使用率過大而導致的 OOM 問題。

未來發展與思考
























 工商網監
工商網監
評論