 電子發燒友App
電子發燒友App


來源:半導體行業觀察
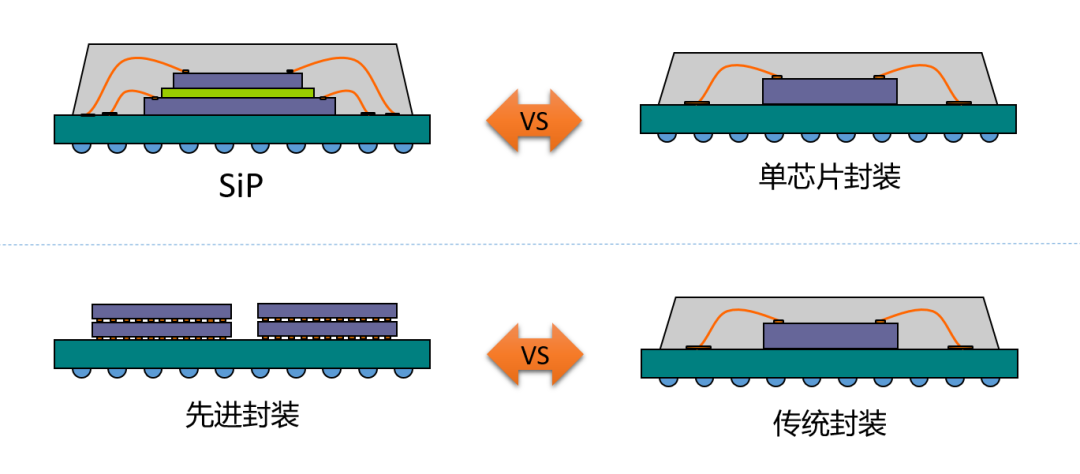
在上《先進封裝最強科普》中,我們對市場上的先進封裝需求進行了一些討論。但其實具體到各個廠商,無論是英特爾(EMIB、Foveros、Foveros Omni、Foveros Direct)、臺積電(InFO-OS、InFO-LSI、InFO-SOW、 InFO-SoIS、CoWoS-S、CoWoS-R、CoWoS-L、SoIC)、三星(FOSiP、X-Cube、I-Cube、HBM、DDR/LPDDR DRAM、CIS)、ASE(FoCoS、FOEB)、索尼( CIS)、美光 (HBM)、SKHynix (HBM)?還是YMTC (XStacking),他們的封裝的各不相同,而且這些封裝類型也被我們所有最喜歡的 AMD、Nvidia?等公司使用。
在本文中,我們將解釋所有這些類型的封裝及其用途。
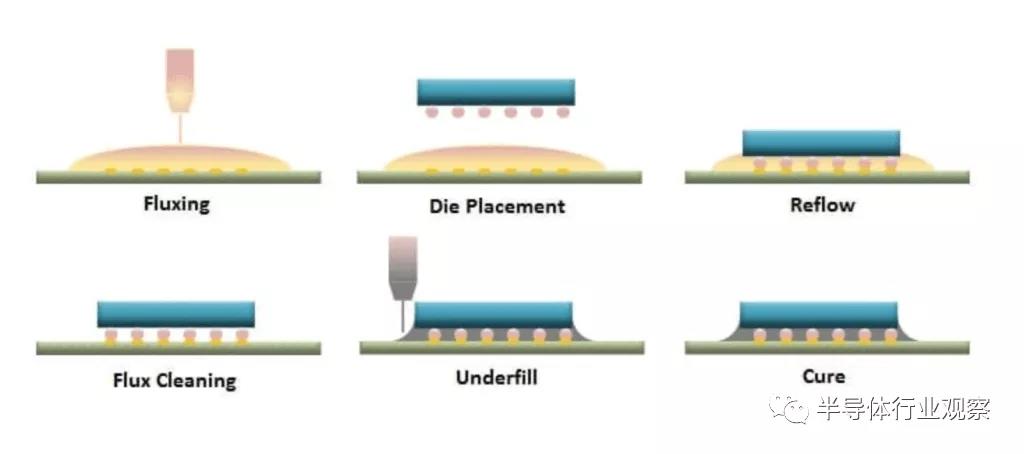
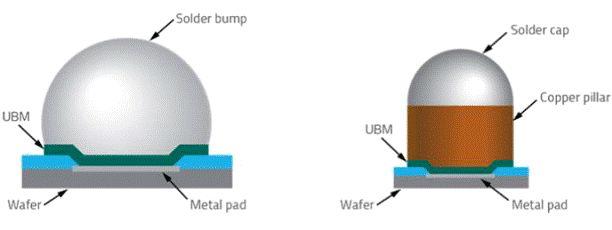
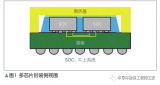
倒裝芯片是引線鍵合后常見的封裝形式之一。它由來自代工廠、集成設計制造商和外包組裝和測試公司等眾多公司提供。在倒裝芯片中,PCB、基板或另一個晶圓將具有著陸焊盤。然后將芯片準確地放置在頂部,并使用凸塊接觸焊盤,之后芯片被送到回流焊爐,加熱組件并回流焊凸點以將兩者結合在一起。焊劑被清除,底部填充物沉積在兩者之間。這只是一個基本的工藝流程,因為有許多不同類型的倒裝芯片,包括但不限于fluxless。
雖然倒裝芯片非常普遍,但間距小于 100?微米的高級版本則不太常見。關于我們在第 1?部分中建立的先進封裝的定義,只有臺積電、三星、英特爾、Amkor?和 ASE?涉及使用倒裝芯片技術的大量邏輯先進封裝。其中 3?家公司也在制造完整的硅片,而另外兩家公司則是外包組裝和測試 (OSAT)。
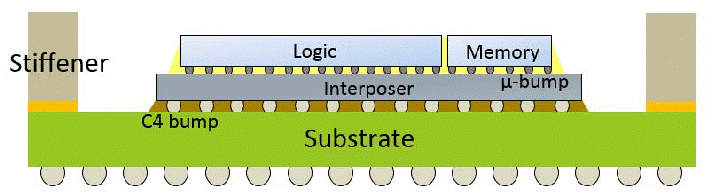
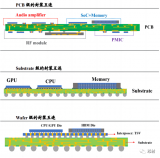
這個尺寸就是大量不同類型倒裝芯片封裝類型開始涌入的地方。我們將以臺積電為例,然后擴展并將其他公司的封裝解決方案與臺積電的封裝解決方案進行比較。臺積電所有封裝選項的最大差異與基板材料、尺寸、RDL?和堆疊有關。
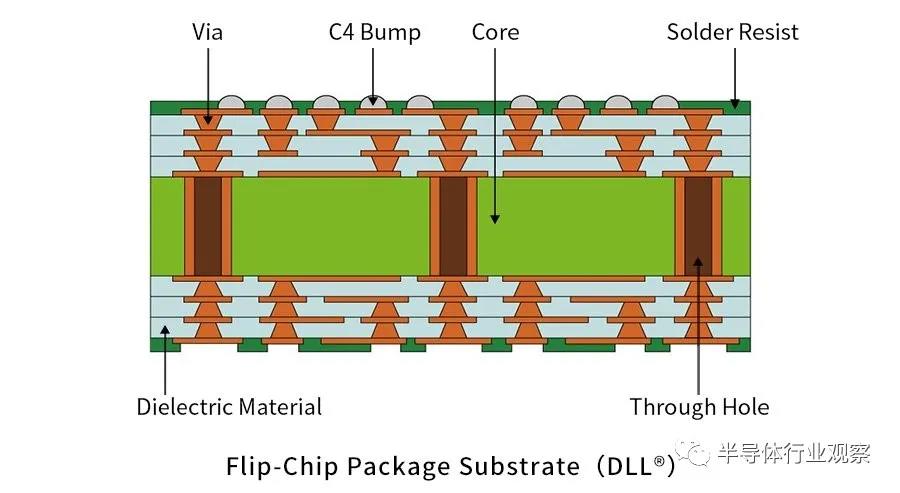
在標準倒裝芯片中,最常見的基板通常是有機層壓板,然后覆以銅。從這里開始,布線圍繞核心兩側構建,討論最多的是 Ajinomoto build-up films ?(ABF)。該內核在頂部構建了許多層,這些層負責在整個封裝中重新分配信號和功率。這些承載信號的層是使用干膜層壓(dry film lamination)和使用 CO2?激光或紫外線激光進行圖案化構建的。

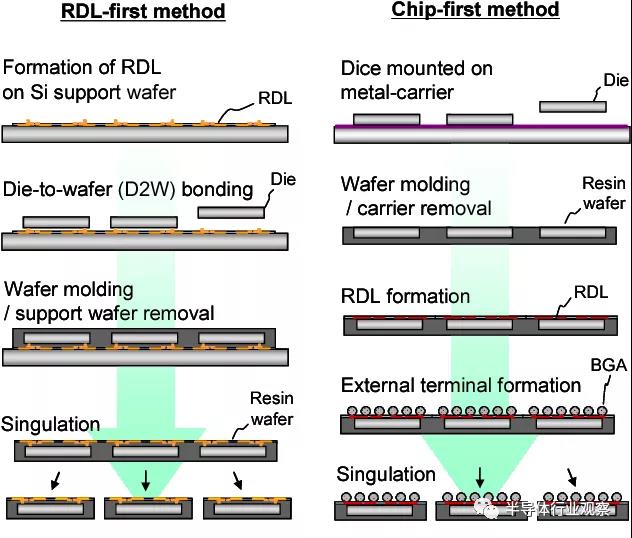
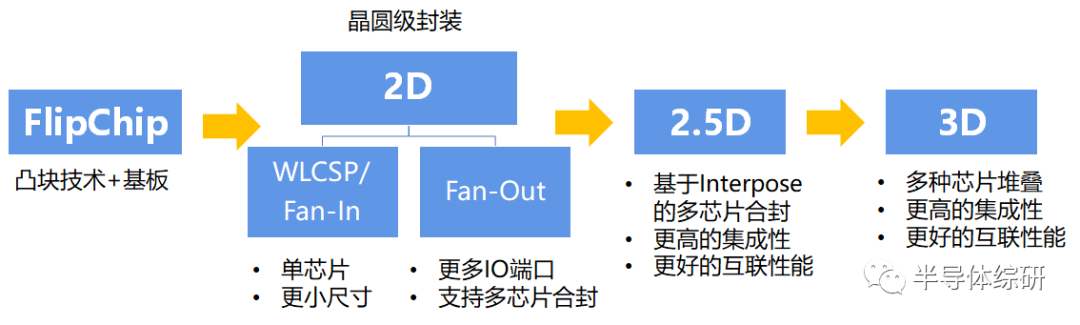
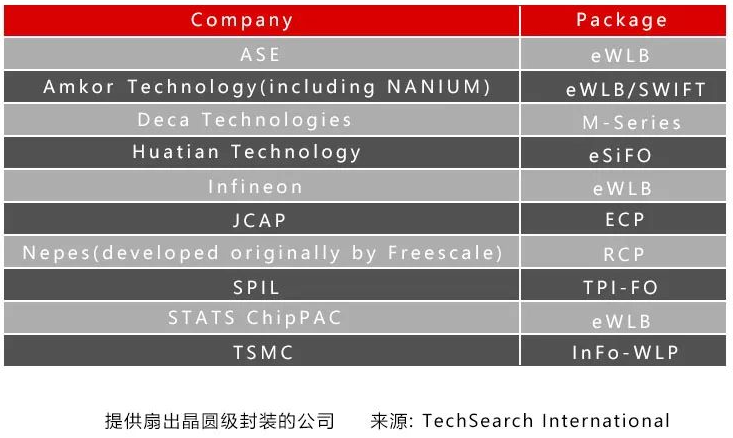
這就是臺積電的專業知識開始發揮其集成扇出 (InFO)?的地方。臺積電沒有使用 ABF?薄膜的標準流程,而是使用與硅制造更相關的工藝。臺積電將使用東京電子涂布機/顯影劑、ASML?光刻工具、應用材料銅沉積工具以光刻方式定義再分布層。重新分布層(RTL)比大多數 OSAT?可以生產的更小、更密集,因此可以容納更復雜的布線。此過程稱為扇出晶圓級封裝 (FOWLP)。ASE?是最大的 OSAT,他們提供 FoCoS(基板上的扇出芯片),這是 FOWLP?的一種形式,它也利用了硅制造技術。三星還有他們的扇出系統封裝 (FOSiP),主要用于智能手機、智能手表、通信和汽車。
使用 InFO-R (RDL),TSMC?可以封裝具有高 IO?密度、復雜路由和/或多個芯片的芯片。使用 InFO-R?最常見的產品是 Apple iPhone?和 Mac?芯片,但也有各種各樣的移動芯片、通信平臺、加速器,甚至網絡交換機 ASIC。三星還憑借 Cisco Silicon One?在網絡交換機 ASIC?扇出市場中獲勝。InFO-R?的進步主要與擴展到具有更多功耗和 IO?的更大封裝尺寸有關。
有不少傳言稱 AMD?將為其即將推出的 Zen 4?客戶端(如上圖所示)和服務器 CPU?采用扇出封裝。SemiAnalysis?可以確認基于 Zen 4?的桌面和服務器產品將使用扇出。然后,該扇出將傳統地封裝在標準有機基板的頂部,該基板的底部將具有 LGA?引腳。包裝這些產品的公司和轉向扇出的技術原因將后面揭曉。
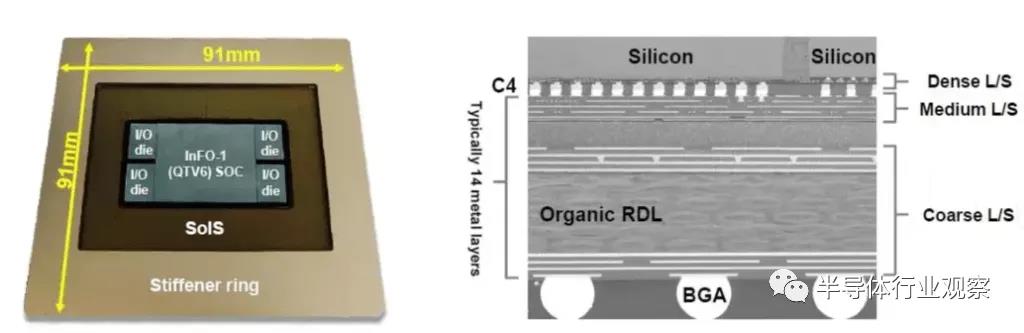
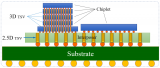
標準封裝將具有核心基板,每側有 2?到 5?層重分布層 (RDL),包括更高級的集成扇出。臺積電的 InFO-SoIS(集成基板系統)將這一概念提升到一個新的水平。它提供多達 14?個重新分布層 (RDL),可在芯片之間實現非常復雜的布線。在靠近管芯的基板上還有一層更高密度的布線層。

TSMC?還提供InFO-SOW(晶圓上系統),它允許扇出包含數十個芯片的整個晶圓的大小。我們撰寫了有關使用這種特殊包裝形式的 Tesla Dojo 1?的文章。我們還在特斯拉去年的 AI?日公布這項技術的幾周前獨家披露了該技術的使用情況。特斯拉將在 HW 4.0?中使用三星 FOSiP。

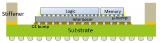
最后,在臺積電的集成扇出陣容中,還有 InFO-LSI(本地硅互連)。InFO-LSI?是 InFO-R,但在多個芯片下方有一塊硅。這種局部硅互連將開始作為多個die之間的無源互連,但未來可以演變為有源(晶體管和各種 IP)。它最終也將縮小到 25?微米,但我們認為第一代不會出現這種情況。第一款采用這種類型封裝的產品將在后面展示。
立即想到的比較最有可能是英特爾的 EMIB(嵌入式多芯片互連橋),但這并不是真正的最佳選擇。它更像是 Intel?的 Foveros Omni?或 ASE?的 FOEB。讓我們解釋一下。
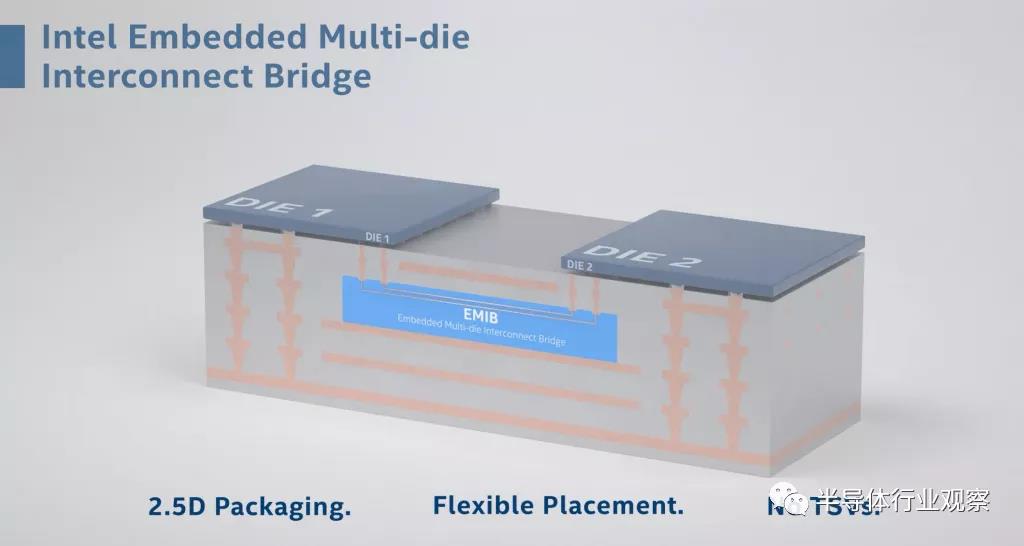
英特爾的嵌入式多芯片互連橋被放置在傳統的有機基板腔體中。然后繼續構建襯底。雖然這可以由英特爾完成,但 EMIB?的放置和構建也可以由傳統的有機基板供應商完成。由于 EMIB?芯片上的大焊盤以及沉積層壓布線和通孔的方法,不需要在基板上非常準確地放置芯片。
通過繼續使用現有的有機層壓板和 ABF?供應鏈,英特爾放棄了更昂貴的硅基板材料和硅制造工藝。總的來說,這條供應鏈是商品化的,盡管目前由于短缺而相當緊張。自 2018?年以來,英特爾的 EMIB?一直在產品中發貨,包括 Kaby Lake G、各種 FPGA、Xe HP GPU?和某些云服務器 CPU,包括 Sapphire Rapids。目前所有 EMIB?產品都使用 55?微米,但第二代是 45?微米,第三代是 40?微米。
英特爾可以通過這個芯片將功率推送到上面的有源芯片。如果需要,英特爾還可以靈活地設計封裝以在沒有 EMIB?和某些小芯片的情況下運行。在英特爾 FPGA?的一些拆解發現,如果英特爾發貨的 SKU?不需要它,英特爾將不會放置 EMIB?和有源芯片。這允許圍繞某些細分市場的物料清單進行一些優化。
最后,英特爾還可以通過僅在需要的地方使用硅橋來節省制造成本。這與臺積電的 CoWoS?形成鮮明對比,后者將所有芯片都放置在單個大型無源硅橋的頂部。稍后會詳細介紹,但臺積電的 InFO-LSI?和英特爾的 EMIB 之間的最大區別在于基板材料和制造工藝的選擇。

更復雜的是,日月光還擁有自己的2.5D封裝技術,與英特爾的EMIB和臺積電的InFO-LSI截然不同。它被用于 AMD?的 MI200 GPU,該 GPU?將用于多臺高性能計算機,包括美國能源部的 Frontier exascale?系統。ASE?的 FOEB?封裝技術與臺積電的 InFO-LSI?更相似,因為它也是扇出。TSMC 使用標準的硅制造技術來構建 RDL。一個主要區別是 ASE?使用玻璃基板面板而不是硅。這是一種更便宜的材料,但它還有一些其他好處,我們將在后面討論。
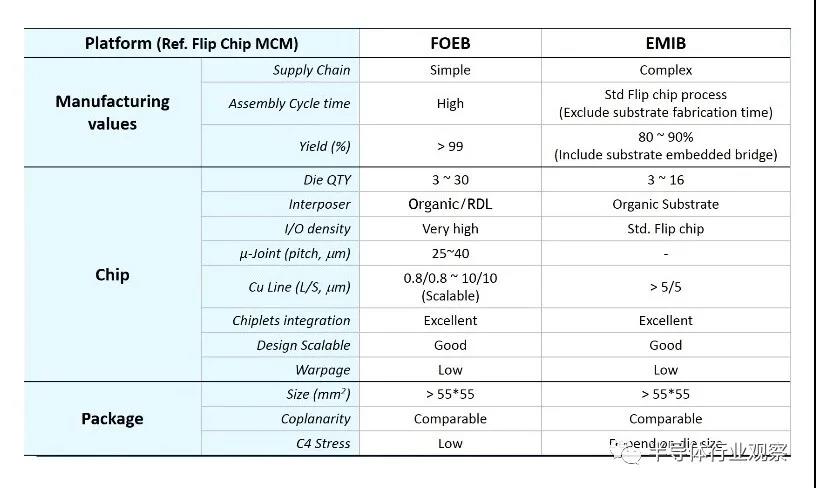
ASE?不是將無源互連芯片嵌入基板的空腔中,而是放置芯片,構建銅柱,然后構建整個 RDL。在 RDL?之上,有源硅 GPU die和 HBM die使用微凸塊進行連接。然后使用激光脫模工藝將玻璃中介層從封裝中移除,然后在使用標準倒裝芯片工藝將其安裝到有機基板上之前完成封裝的另一面。
ASE?對 FOEB?與 EMIB?提出了許多聲明,但有些是完全錯誤的。ASE?需要推銷他們的解決方案是可以理解的,但讓我們消除噪音。EMIB?收益率不在 80%?到 90%?的范圍內。EMIB?的收益率接近 100%。第一代 EMIB?在芯片數量方面確實有縮放限制,但第二代沒有。事實上,英特爾將發布有史以來最大封裝的產品,一種采用第二代 EMIB?的92mm x 92mm BGA?封裝的高級封裝。通過在整個封裝中使用扇出和光刻定義的 RDL,FOEB?確實保留了布線密度和芯片到封裝凸點尺寸方面的優勢,但這也更昂貴。
與臺積電相比,最大的區別似乎是最初的玻璃基板材料與硅。部分原因可能是因為 ASE?的成本受到更多限制。ASE?必須以更低的價格提供出色的技術來贏得客戶。臺積電是芯片大師,專注于他們熟悉的技術,臺積電有著將技術推向極致的文化,在這種推動下,他們最好選擇硅。
現在回到臺積電的其他高級封裝選項,因為我們還有一些要做。CoWoS?平臺還有 CoWoS-R?和 CoWoS-L?平臺。它們與 InFO-R?和 InFO-L?幾乎 1?比 1?對應。這兩者之間的區別更多地與過程有關。InFO?是先芯片工藝,首先放置芯片,然后圍繞它構建 RDL。使用 CoWoS,先建立 RDL,然后放置芯片。對于大多數試圖了解高級封裝的人來說,區別并不那么重要,所以今天我們將輕松地討論這個話題。
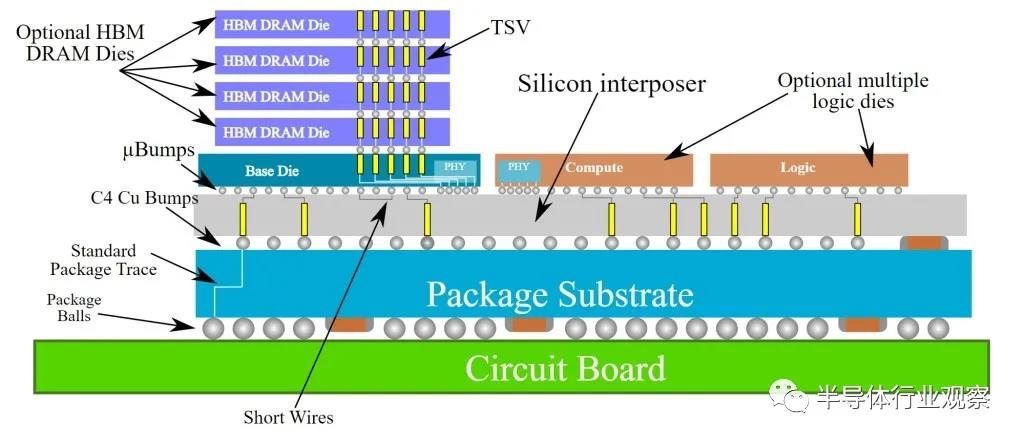
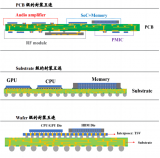
最大的亮點是 CoWoS-S(硅中介層)。它涉及采用已知良好的芯片,倒裝芯片將其封裝到無源晶圓上,該晶圓上具有圖案化的導線。這就是 CoWoS?名稱的來源,Chip on Wafer on Substrate。從長遠來看,它是體積最大的 2.5D?封裝平臺。如第 1?部分所述,這是因為 P100、V100?和 A100?等 Nvidia?數據中心 GPU?使用 CoWoS-S。雖然 Nvidia?的銷量最高,但 Broadcom、Google TPU、Amazon Trainium、NEC Aurora、Fujitsu A64FX、AMD Vega、Xillinx FPGA、Intel Spring Crest?和 Habana Labs Gaudi?只是 CoWoS?使用的幾個值得注意的例子。大多數使用 HBM?計算的重型芯片,包括來自各種初創公司的 AI?訓練芯片都使用 CoWoS。
為了進一步說明 CoWoS?的普及程度,這里有一些來自 AIchip?的引述。AIchip是一家臺灣設計和IP公司,主要利用臺積電CoWoS平臺協助與AI芯片相關的EDA、物理設計和產能工作。
臺積電甚至沒有參加與 CoWoS?容量相關的所有會議,因為臺積電已經銷售了他們生產的所有產品,而且要支持所有這些設計需要太多的工程時間。另一方面,臺積電的客戶集中度較高(英偉達),因此臺積電希望與其他公司合作。AIchip?有點像中間人,即使 Tier 1?客戶(Nvidia)預訂了一切,AIchip?仍然獲得一些容量。即便如此,他們也只能得到他們想要的 50%。
讓我們轉身看看英偉達在做什么。在第三季度,他們的長期供應義務躍升至 69億美元,更重要的是,Nvidia?預付款16.4億美元,并且未來將再預付款17.9億美元。英偉達正在吞噬供應,特別是針對 CoWoS。

回到技術上,CoWoS-S?多年來經歷了一次演變。主要特點是中介層面積越來越大。由于 CoWoS?平臺使用硅制造技術,因此它遵守稱為光罩限制的原則。使用 193nm ArF?光刻工具可以印刷的最大尺寸為 33mm x 26mm (858mm 2 )。硅中介層的主要用途也是光刻定義的,即連接位于其上的芯片的非常密集的電線。英偉達的芯片早已接近標線限制,但仍需要連接到封裝的高帶寬內存。
上圖包含一個 Nvidia V100,這是 Nvidia四年前推出的 GPU,它的面積是 815平方毫米。一旦包含 HBM,它就會超出光刻工具可以打印的光罩限制,但臺積電想出了如何連接它們。臺積電通過做光罩拼接來實現這一點。臺積電在此增強了他們的能力,可以為硅中介層提供 3?倍大小的掩模版。鑒于標線拼接的局限性,英特爾 EMIB、TSMC LSI?和 ASE FOEB?方法具有優點。他們也不必處理與大型硅中介層一樣多的費用。

除了增加掩模版尺寸外,他們還進行了其他改進,例如將微凸塊從焊料改為銅以提高性能/功率效率、iCap、新的 TIM/蓋子封裝等。
有一個關于 TIM/蓋子包裝的有趣故事。在Nvidia V100上,Nvidia 擁有一個無處不在的 HGX?平臺,該平臺可以運送到許多服務器 ODM,然后運送到數據中心。可以應用于冷卻器螺釘以實現正確安裝壓力的扭矩非常具體。這些服務器 ODM?在這些價值 10,000?美元的 GPU?上過度擰緊了冷卻器和芯片。Nvidia?的 A100?轉移到在芯片上有蓋子的封裝,而不是直接冷卻芯片。當 Nvidia?的 A100 和未來的 Hopper DC GPU?仍然需要散發大量熱量時,這類封裝的問題就會出現。為了解決這個問題,臺積電和英偉達在封裝上進行了很多優化。
三星也有類似于 CoWoS-S?的 I-Cube?技術。三星使用這種封裝的唯一主要客戶是百度的 AI?加速器。

接下來我們有 Foveros。這就是英特爾的3D芯片堆疊技術。Foveros?不是一個裸片在另一個裸片的頂部活動,而后者本質上只是密集的導線,Foveros?涉及兩個包含活動元素的裸片。有了這個,英特爾第一代 Foveros?于 2020 年 6?月在 Lakefield?混合 CPU SOC?中推出。該芯片不是特別大的容量或令人嘆為觀止的芯片,但它是英特爾的許多第一款芯片,包括 3D?封裝和他們的第一個混合 CPU?內核具有大性能核心和小效率核心的架構。它采用了 55?微米的凸點間距。
下一個 Foveros?產品是 Ponte Vecchio GPU,經過多次延遲,它應該在今年推出。它將包括與 EMIB?和 Foveros?一起封裝的 47?個不同的有源小芯片。Foveros?芯片到芯片的連接采用 36?微米的凸點間距。
未來,英特爾的大部分客戶端陣容都將采用3D堆棧技術,包括代號為Meteor Lake、Arrow Lake、Lunar Lake的客戶端產品。Meteor Lake?將是首款采用 Foveros Omni?和 36?微米凸點間距的產品。第一個包含 3D?堆棧技術的數據中心 CPU?代號為 Diamond Rapids,其名稱是 Granite Rapids。我們將在本文中討論其中一些產品使用的節點以及英特爾與臺積電的關系。
Foveros Omni?的全稱是 Foveros Omni-Directional Interconnect (ODI)。它彌補了 EMIB?和 Foveros?之間的差距,同時還提供了一些新功能。Foveros Omni?可以作為兩個其他芯片之間的有源橋接芯片,作為完全位于另一個芯片下方的有源芯片,或位于另一個芯片頂部但懸垂的芯片。
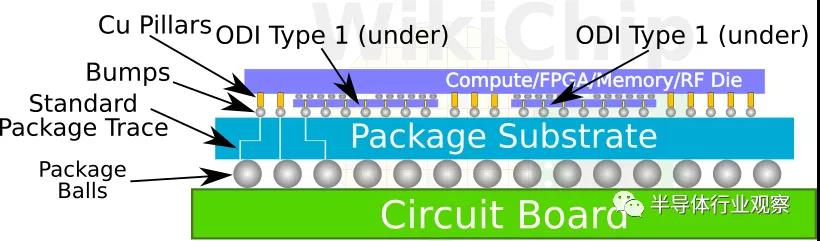
Foveros Omni?從未像 EMIB?那樣嵌入基板內部,它在任何情況下都完全位于基板之上。堆疊類型會導致封裝基板與位于其上的芯片的連接高度不同的問題。英特爾開發了一種銅柱技術,讓他們可以將信號和電源傳輸到不同的 z?高度并通過芯片,這樣芯片設計人員在設計 3D?異構芯片時可以有更多的自由。Foveros Omni?將從 36?微米的凸點間距開始,但在下一代將降低到 25?微米。
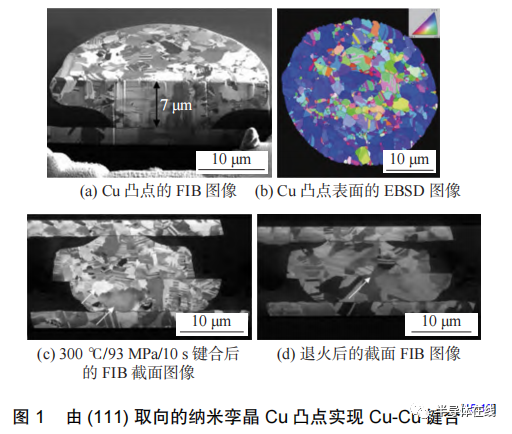
我們要注意的是,DRAM?還使用了先進的 3D?封裝。HBM?多年來一直在三星、SK?海力士和美光使用先進封裝。將制造存儲單元并連接到暴露并形成微凸塊的 TSV。最近,三星甚至開始推出 DDR5?和 LPDDR5X?堆棧,它們利用類似的堆棧技術來提高容量。SKHynix?正在其 HBM 3?中引入混合鍵合。SKHynix?將把 12?個芯片鍵合在一起,每個芯片的厚度約為 30?微米,并帶有混合鍵合 TSV。

混合鍵合是一種技術,它不使用凸點,而是將芯片直接與硅通孔連接。如果我們回到倒裝芯片工藝,沒有凸塊形成、助焊劑、回流或模下填充芯片之間的區域。銅直接遇到銅。實際過程非常困難,上面部分詳述。在本系列的下一部分中,我們將深入研究工具生態系統和混合綁定類型。與之前描述的任何其他封裝方法相比,混合鍵合能夠實現更密集的集成。
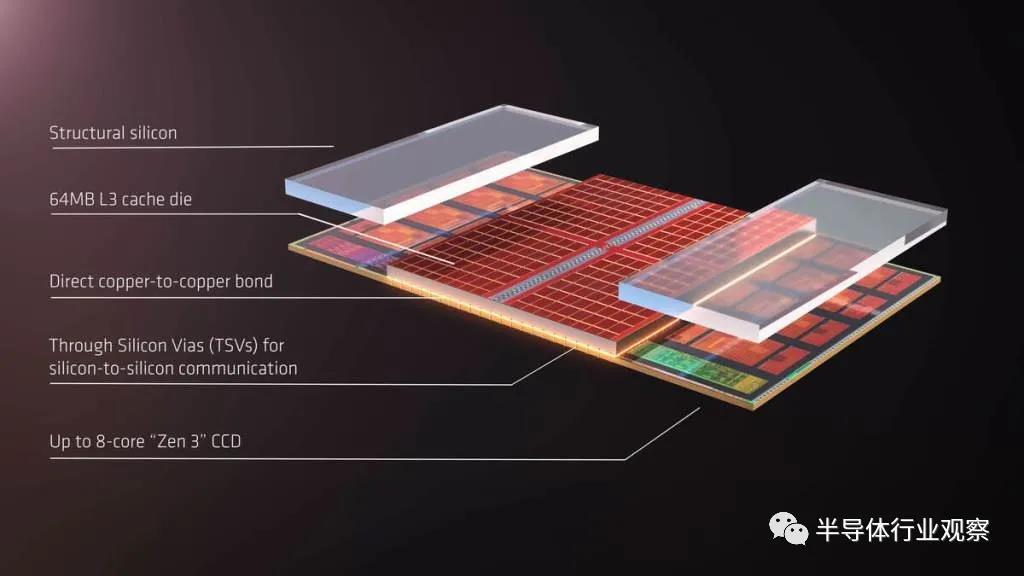
最著名的混合鍵合芯片當然是最近宣布的 AMD?的 3D?堆疊緩存,它將于今年晚些時候發布。這利用了臺積電的 SoIC?技術。英特爾的混合鍵合品牌稱為 Foveros Direct,三星的版本稱為 X-Cube。Global Foundries?公開了使用混合鍵合技術的 Arm?測試芯片。產量最高的混合鍵合半導體公司不是臺積電,今年甚至明年也不會是臺積電。出貨最多的混合鍵合芯片的公司實際上是擁有 CMOS?圖像傳感器的索尼。事實上,假設你有一部高端手機,你的口袋里可能有一個包含混合粘合 CMOS?圖像傳感器的設備。如第 1?部分所述,索尼已將間距縮小至 6.3?微米,而 AMD?的 V-cache?間距為 17?微米。
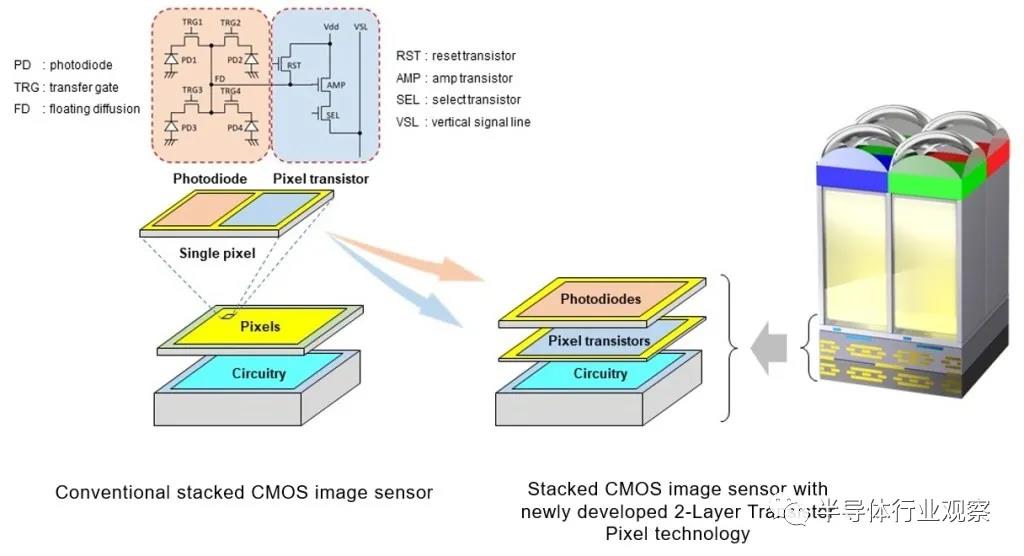
目前索尼提供 2 stack?和 3 stack?版本。在 2?堆棧中,像素位于電路的頂部。在 3?堆棧版本中,像素堆疊在電路頂部的 DRAM?緩沖區緩存的頂部。隨著索尼希望將像素晶體管從電路中分離出來并創建具有多達 4?層硅的更先進的相機,進步仍在繼續。由于其 CMOS?圖像傳感器業務,三星是混合鍵合芯片的第二大出貨量出貨商。
混合鍵合的另一個即將大批量應用是來自長江存儲技術公司的 Xtacking。YMTC?使用晶圓到晶圓鍵合技術將 CMOS?外圍堆疊在 NAND?門下方。我們在這里詳細介紹了這項技術的好處,但簡而言之,它允許 YMTC?在給定一定數量的 NAND?層數的情況下安裝更多的 NAND?單元,而不是任何其他 NAND?制造商,包括三星、SK?海力士、美光、Kioxia?和西部數據。
關于各種類型的倒裝芯片、熱壓鍵合和混合鍵合工具,有很多話要說,但我們將把這些留到下一篇。投資者對 Besi Semiconductor、ASM Pacific、Kulicke?和 Soffa、EV Group、Suss Microtec、SET、Shinkawa、Shibaura 和 Applied Materials?的共同認識是不正確的,這里的各種公司和封裝類型使用工具的多樣性非常廣泛.?但贏家并不像看起來那么明顯。
審核編輯:符乾江





































 工商網監
工商網監
評論