 電子發(fā)燒友App
電子發(fā)燒友App


基于多視角融合的夜間無(wú)人車三維目標(biāo)檢測(cè)
來源:《應(yīng)用光學(xué)》,作者王宇嵐等
摘 要:為了提高無(wú)人車在夜間情況下對(duì)周圍環(huán)境的物體識(shí)別能力,提出一種基于多視角通道融合網(wǎng)絡(luò)的無(wú)人車夜間三維目標(biāo)檢測(cè)方法。引入多傳感器融合的思想,在紅外圖像的基礎(chǔ)上加入激光雷達(dá)點(diǎn)云進(jìn)行目標(biāo)檢測(cè)。通過對(duì)激光雷達(dá)點(diǎn)云進(jìn)行編碼變換成鳥瞰圖形式和前視圖形式,與紅外圖像組成多視角通道,各通道信息之間融合互補(bǔ),從而提高夜間無(wú)人車對(duì)周圍物體的識(shí)別能力。該網(wǎng)絡(luò)將紅外圖像與激光雷達(dá)點(diǎn)云作為網(wǎng)絡(luò)的輸入,網(wǎng)絡(luò)通過特征提取層、候選區(qū)域?qū)雍屯ǖ廊诤蠈訙?zhǔn)確地回歸檢測(cè)出目標(biāo)的位置以及所屬的類別。實(shí)驗(yàn)結(jié)果表明,該方法能夠提高無(wú)人車在夜間的物體識(shí)別能力,在實(shí)驗(yàn)室的測(cè)試數(shù)據(jù)中準(zhǔn)確率達(dá)到90%,速度0.43 s/幀,達(dá)到了實(shí)際應(yīng)用要求。
關(guān)鍵詞:紅外圖像;激光雷達(dá)點(diǎn)云;多視角通道;三維目標(biāo)檢測(cè)
引言
夜間無(wú)人車在道路上行駛需要感知周圍環(huán)境的車輛、行人[1-2]等,基于紅外攝像頭的感知方案[3-5]雖然能夠感知車輛前方的障礙物,但是無(wú)法準(zhǔn)確獲取障礙物的位置信息且準(zhǔn)確率有限。激光雷達(dá)是一種主動(dòng)傳感器,通過發(fā)射與接收激光光束獲取環(huán)境中物體的信息[6-7]。近幾年陸續(xù)有研究人員利用深度學(xué)習(xí)在激光雷達(dá)點(diǎn)云上進(jìn)行目標(biāo)檢測(cè),斯坦福大學(xué)的Point Net[8]直接將激光點(diǎn)云作為輸入,并解決了旋轉(zhuǎn)問題和無(wú)序性問題。2017年蘋果公司Voxel Net[9]將激光雷達(dá)分成等間距的體素,并引入新的體素特征編碼表示,在KITTI[10]上取得很好的成績(jī)。清華大學(xué)提出了MV3D[11],將彩色圖像與激光雷達(dá)點(diǎn)云融合進(jìn)行三維目標(biāo)檢測(cè),該算法在KITTI 上也表現(xiàn)出色。
上述前人的研究工作基本都是在白天條件下的彩色圖像上進(jìn)行,而在夜間,無(wú)人車往往需要依賴紅外圖像,但紅外圖像的成像原理是通過紅外攝像頭探測(cè)物體自身的紅外輻射,再通過光電變換將物體的溫度分布變換成圖像。紅外圖像具有無(wú)色彩、簡(jiǎn)紋理、低信噪比等特點(diǎn)。因此在紅外圖像上進(jìn)行目標(biāo)檢測(cè)效果較差。考慮到各個(gè)傳感器在不同方面均有利弊,本文利用多傳感器融合的思想,提出了利用多視角通道融合網(wǎng)絡(luò)的基于紅外圖像與激光雷達(dá)點(diǎn)云的夜間無(wú)人車三維目標(biāo)檢測(cè)方法。實(shí)驗(yàn)結(jié)果證明,該方法的準(zhǔn)確率高且能基本滿足實(shí)時(shí)性的要求。
1 多視角通道融合網(wǎng)絡(luò)
本文所采用的多視角通道融合網(wǎng)絡(luò)由特征提取模塊、候選區(qū)域生成模塊和通道融合模塊組成,整體結(jié)構(gòu)圖如圖1所示。
特征提取模塊由特征編碼網(wǎng)絡(luò)和特征解碼網(wǎng)絡(luò)2 部分組成,結(jié)構(gòu)如圖2所示。
圖1 多視角通道融合網(wǎng)絡(luò)結(jié)構(gòu)圖
Fig.1 Structure diagram of multi-view channel fusion network
圖2 特征提取模塊結(jié)構(gòu)圖
Fig.2 Structure diagram of feature extraction module
特征編碼網(wǎng)絡(luò)采用的是改進(jìn)后的VGG(visual geometry group)16 網(wǎng)絡(luò)[12],將原VGG16 網(wǎng)絡(luò)的通道數(shù)減少一半至50%,然后在網(wǎng)絡(luò)中加入批標(biāo)準(zhǔn)化層,并在Conv4 刪除最大池化層。特征編碼網(wǎng)絡(luò)將M×N×C的紅外圖像、鳥瞰圖或前視圖作為輸入,并輸出?
的特征圖。式中,M表示圖像的長(zhǎng),N表示圖像的寬,C表示通道數(shù)。對(duì)于紅外圖像,C為1。特征解碼網(wǎng)絡(luò)采用特征金字塔網(wǎng)絡(luò)[13]的形式,學(xué)習(xí)將特征映射上采樣回原始的輸入大小。特征解碼網(wǎng)絡(luò)將特征編碼網(wǎng)絡(luò)的輸出作為輸入,輸出新的?M×N×D的特征圖,如圖2所示,通過轉(zhuǎn)換-轉(zhuǎn)置操作對(duì)輸入進(jìn)行上采樣處理,并和來自特征編碼網(wǎng)絡(luò)的對(duì)應(yīng)特征映射進(jìn)行級(jí)聯(lián)操作,最后通過3×3 卷積來融合二者。
輸入一幅鳥瞰圖,候選區(qū)域生成模塊會(huì)生成一系列的三維候選區(qū)域。每個(gè)三維候選區(qū)域有六維的參數(shù):(x,y,z,l,w,h),分別表示三維候選區(qū)域在激光雷達(dá)坐標(biāo)系中的中心坐標(biāo)和長(zhǎng)寬高尺寸。對(duì)于每個(gè)三維候選區(qū)域,對(duì)應(yīng)在鳥瞰圖中的參數(shù)(xbv,ybv,lbv,wbv)利 用離散的 (x,y,l,w)變換可以得到,表示三維候選區(qū)域在鳥瞰圖中的坐標(biāo)和長(zhǎng)寬,其中 離散分辨率為0.1 m。
通道融合模塊結(jié)合各個(gè)視角的特征,對(duì)各視角上的目標(biāo)進(jìn)行聯(lián)合分類,并針對(duì)三維候選區(qū)域進(jìn)行定向回歸。由于不同的視角有不同的分辨率,對(duì)于每個(gè)視角通道所輸出的不同分辨率的特征向量,通過ROI(region of interest)池化操作將每個(gè)視角通道所輸出的特征向量調(diào)整到相同的長(zhǎng)度。通過下式得到3 個(gè)視角不同的ROI。
式中:T3D→v表示從激光雷達(dá)點(diǎn)云坐標(biāo)系到鳥瞰圖形式、前視圖形式,和紅外圖像的轉(zhuǎn)換函數(shù);P3D表示三維候選區(qū)域參數(shù)向量。對(duì)于區(qū)域候選網(wǎng)絡(luò)所生成的三維候選區(qū)域,將其投影到經(jīng)過ROI池化操作的鳥瞰圖形式(BV)特征向量、前視圖(FV)特征向量和紅外圖像(IR)特征向量中。對(duì)于從某個(gè)視角特征提取通道中輸出的特征向量?x,通過ROI池化獲得固定長(zhǎng)度的特征?fv。
式中:R表示相應(yīng)的矩陣變換。為了融合來自各個(gè)視角通道的特征信息,采用多層次融合的方法,分層融合多視角特征,使得各通道的信息可以在中間層有更多的交互。如圖3所示。
圖3 通道融合網(wǎng)絡(luò)結(jié)構(gòu)圖
Fig.3 Structure diagram of channel fusion network
對(duì)于通道融合網(wǎng)絡(luò)的每一層,輸入為鳥瞰圖形式、前視圖形式以及紅外圖像3 個(gè)通道的特征,經(jīng)過一次逐元素平均計(jì)算后,再經(jīng)過各自的中間卷積層進(jìn)一步提取特征。具體的融合過程如下式所示。
式中:fl表示第?l層的融合結(jié)果;fBV、fFV和?fIR分別表示鳥瞰圖通道、前視圖通道以及紅外圖像通道的輸入特征;
表示第l層不同通道的中間卷積層;⊕表示逐元素平均運(yùn)算;經(jīng)過通道融合網(wǎng)絡(luò)融合各個(gè)視角通道的特征之后,利用融合結(jié)果對(duì)候選區(qū)域模塊生成的三維候選區(qū)域進(jìn)行回歸校正,并將融合結(jié)果輸入Softmax 分類器對(duì)三維候選區(qū)域內(nèi)的物體進(jìn)行分類識(shí)別。
2 實(shí)驗(yàn)內(nèi)容
2.1 實(shí)驗(yàn)配置與數(shù)據(jù)預(yù)處理
本文算法中的網(wǎng)絡(luò)基于Tensor Flow[14]框架,實(shí)驗(yàn)硬件配置為處理器Intel i5-6600,內(nèi)存16 GB,顯卡NVIDIA GTX 1070;操作系統(tǒng)Ubuntu14.04。實(shí)驗(yàn)的所有數(shù)據(jù)由載有紅外攝像頭和激光雷達(dá)的車輛在南京理工大學(xué)夜晚的校園道路上拍攝所得,有車輛、行人和騎自行車的人3 種類別。其中訓(xùn)練集為1 500 張紅外圖像及其對(duì)應(yīng)的由激光雷達(dá)點(diǎn)云數(shù)據(jù),驗(yàn)證集為500 張紅外圖像及其對(duì)應(yīng)的由激光雷達(dá)點(diǎn)云數(shù)據(jù),測(cè)試集為600 張紅外圖像及其對(duì)應(yīng)的由激光雷達(dá)數(shù)據(jù)。
對(duì)于激光雷達(dá)點(diǎn)云數(shù)據(jù),其中每一個(gè)點(diǎn)由其三維坐標(biāo) (x,y,z)和 反射率?r組成,本文將其轉(zhuǎn)化為鳥瞰圖與前視圖的形式。鳥瞰圖形式指的是沿水平坐標(biāo)系(地面)將激光雷達(dá)點(diǎn)云分割成700×800 的網(wǎng)格,再沿Z軸方向把激光雷達(dá)點(diǎn)云平均分成5 層。對(duì)于每一個(gè)區(qū)域,提取其中最大高度的點(diǎn)的高度作為高度特征;該長(zhǎng)方體區(qū)域內(nèi)點(diǎn)的數(shù)目作為密度特征;對(duì)于密度特征ρ,作歸一化處理。
式中N是長(zhǎng)方體區(qū)域內(nèi)點(diǎn)的數(shù)目。最后將激光雷達(dá)點(diǎn)云轉(zhuǎn)換成通道數(shù)為700×800×6 的鳥瞰圖形式。前視圖形式指的是將激光雷達(dá)點(diǎn)云投射到一個(gè)前方的圓柱體平面上。給定激光雷達(dá)點(diǎn)云中的一個(gè)點(diǎn)的三維坐標(biāo)?p=(x,y,z),其在前視圖中的坐標(biāo)?pfv=(r,c)可以通過下式計(jì)算得出。
式中:Δθ是 激光的水平分辨率;Δ?是垂直分辨率。
2.2 實(shí)驗(yàn)結(jié)果及分析
把紅外圖像與激光點(diǎn)云數(shù)據(jù)輸入到多視角通道融合網(wǎng)絡(luò)中,網(wǎng)絡(luò)給出檢測(cè)結(jié)果。由于紅外攝像頭與激光雷達(dá)的采集頻率不一致,本文根據(jù)激光雷達(dá)幀號(hào)匹配紅外圖像,設(shè)定閾值為10 幀,尋找與雷達(dá)幀號(hào)小于閾值且最接近的圖像作為對(duì)應(yīng)圖像,如圖4所示。
圖4 輸入的紅外圖像與對(duì)應(yīng)的激光雷達(dá)點(diǎn)云
Fig.4 Input infrared image and lidar point cloud
使用傳統(tǒng)的AdaBoost[15]算法、和二維的目標(biāo)檢測(cè)算法Fast RCNN[16]算法、Faster RCNN[17]算法以及三維的目標(biāo)檢測(cè)算法Voxel Net[10]在測(cè)試集中進(jìn)行測(cè)試,并與本文算法進(jìn)行結(jié)果對(duì)比,結(jié)果見表1。
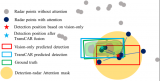
從表1的結(jié)果中可得,本文算法在犧牲部分時(shí)間的情況下提高了夜間目標(biāo)檢測(cè)的正確率。為了更直觀地顯示本文算法結(jié)果,將目標(biāo)檢測(cè)的結(jié)果顯示在激光雷達(dá)點(diǎn)云的鳥瞰圖形式上和紅外圖像上,其中綠色矩形框表示行人,紅色矩形框表示車輛。如圖5所示。
表1 不同算法在測(cè)試集上的結(jié)果對(duì)比
Table1 Comparison of results for different algorithms on test sets
圖5 目標(biāo)檢測(cè)可視化結(jié)果
Fig.5 Visualized result of detection
由圖5可以看出,對(duì)于圖5(a 組),本文算法可以很好地定位行人的位置;對(duì)于圖5(b 組),雖然紅外圖像分辨率較低,連人眼也不容易分辨圖片中的車輛,但加入激光雷達(dá)點(diǎn)云信息后對(duì)于該車的定位準(zhǔn)確;對(duì)于圖5(c 組),本文算法定位結(jié)果與人工標(biāo)注信息一致。
3 結(jié)論
本文采用多傳感器融合的思想,在原有紅外圖像的基礎(chǔ)上加入激光雷達(dá)點(diǎn)云,并使用多視角通道融合網(wǎng)絡(luò)對(duì)這2 種數(shù)據(jù)進(jìn)行特征融合,準(zhǔn)確地檢測(cè)出目標(biāo)的位置以及類別。實(shí)驗(yàn)結(jié)果表明,該方法能夠提高無(wú)人車在夜間的物體識(shí)別能力,在實(shí)驗(yàn)室的測(cè)試數(shù)據(jù)中準(zhǔn)確率達(dá)到90%,每幀耗時(shí)0.43 s,達(dá)到實(shí)際應(yīng)用要求。
審核編輯:符乾江

















































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論