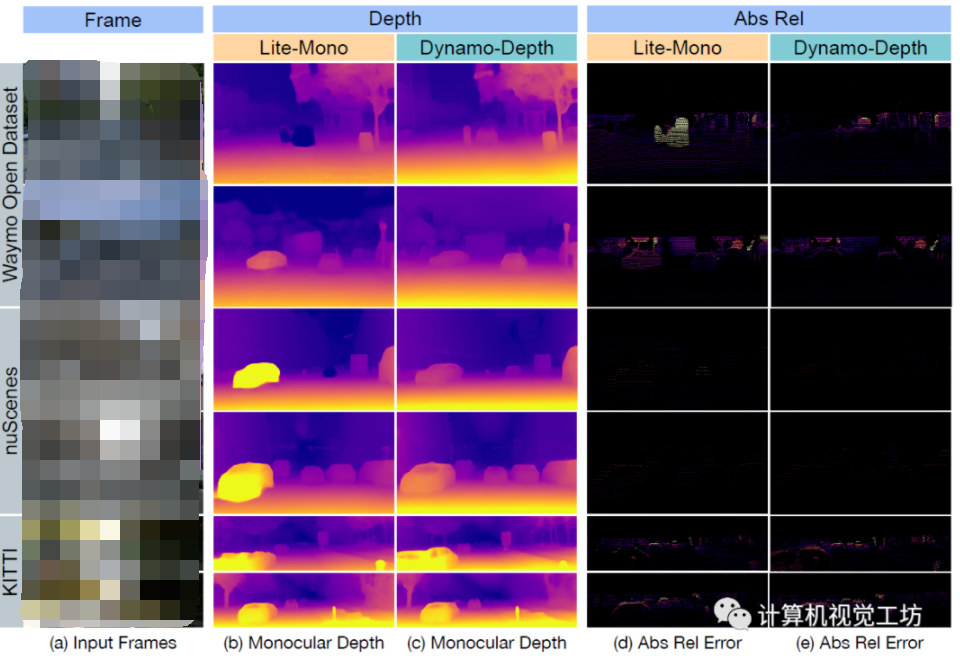
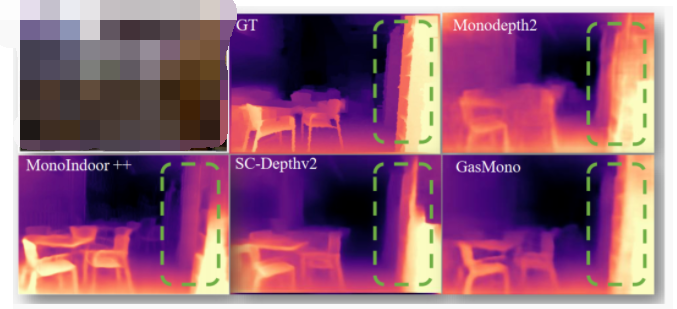
 電子發燒友App
電子發燒友App


來源:《西北工業大學學報》,作者史蘊豪等
摘 要:針對有標簽樣本較少條件下的通信信號調制識別問題,提出了一種基于偽標簽半監督學習技術的小樣本調制方式分類算法,通過優選人工特征集、設計高性能分類器以及基于輸出概率的偽標簽數據選擇方法,構建高效的偽標簽標注系統,然后通過該偽標簽標注系統與基于深度學習的信號分類方法配合,實現在少量有標簽樣本和大量無標簽樣本條件下的調制方式分類。仿真結果表明,對6種數字信號進行調制識別,在信噪比大于5 dB時,偽標簽算法可將模型識別性能提高5%~10%,該算法設計簡單,具有較大應用價值。
關 鍵 詞:調制識別; 偽標簽; 半監督學習
通信信號調制方式識別是通信偵察、認知電子戰領域的關鍵技術之一,在實際戰場環境中,由于敵我雙方的非協作特性,使得在還原敵方通信信號、獲取敵方情報信息之前必須進行調制方式識別,此外,通信信號調制方式識別也為后續的信號解調、比特流分析、協議識別、信號解密、靈巧干擾等提供了重要支撐。
調制識別技術發展至今,已逐漸形成兩大類基于似然比的調制識別方法和基于特征的調制識別方法。基于似然比的調制識別方法主要是通過計算似然概率模型估計不同調制方式的概率,然后將各個信號代入檢驗,最后判定似然概率最大的為識別結果。基于似然比的調制識別算法主要分為3類[1-3],但該類方法普適性差的缺點較為明顯,由于概率密度函數都是針對特殊環境提出來的,因此參數微小的偏差和模型失配都會導致識別率大幅降低。基于特征的調制識別方法通過提取信號不同特征搭配分類算法從而做到對信號的識別,如文獻[4]使用高階累積量對8種數字信號進行識別,文獻[5]混合高階累積量與循環譜特征對信號進行分類,文獻[6-7]使用信號熵特征對不同調制信號進行分類。但是基于人工提取特征的調制識別算法中,對特征區分度要求較高,一旦特征對于不同信號辨別性能差,識別模型效果就會顯著下降,因此有必要對自動提取特征的方法進行研究。
近年來,深度學習在模式識別、計算機視覺等領域取得了顯著突破,利用深度學習的方法自動提取信號特征并對信號調制方式進行識別也已經取得了不錯的效果,O′Shea等[8-9]最早于2016年利用有監督深度學習技術實現調制方式識別,該論文直接使用卷積祌經網絡(convolutional neural network,CNN)構建端到端的學習模型,成功對包括WBFM、DSB、BPSK、16QAM在內的11種數字或模擬調制方式進行了識別。Jeong等[10]學者在論文中提出了一種算法,利用短時傅里葉變換(short-time Fourier transform,STFT)將信號從時域轉換為時頻域,并通過深度卷積神經網絡提取時頻域特征,最終完成了對2-FSK、4-FSK、8-FSK等7種調制識別方式的識別,其在-4 dB的信噪比下仍有90%以上的識別正確率。Meng等[11]學者提出了一種聯合噪聲估計的調制識別算法,該研究提出了一種巧妙的網絡結構,同時將原始信號數據和信噪比作為神經網絡的輸入,仿真結果顯示這種算法在不同信噪比下、不同頻偏下的識別成功率已經非常接近理論識別率的上限。文獻[12]提出利用時頻圖的紋理信息進行調制識別,在大樣本條件下,可取得良好的分類效果。Zhang等[13]利用卷積神經網絡提取信號SPWVD時頻圖特征和BJD時頻圖特征并與大量手工特征融合對BPSK、QPSK,OFDM等8種調制方式進行識別,在-4 dB時仍有92.5%的識別準確率。
雖然基于深度學習的調制識別方法已經取得了非常顯著的成果,但是國內外專家的研究重點都偏向于有監督深度學習方法,而有監督深度學習方法需要大量有標簽信號樣本作為支撐。但在實際應用中,一些敏感的軍用通信信號由于受敵方保密要求的限制以及地理環境條件的制約,在平時只能獲取十分有限的信號樣本,而這些信號真正到了戰場又會大量出現。因此,如何利用少量有標簽信號結合大量無標簽信號的小樣本調制方式識別逐漸成了大家關注的重點方向之一。現階段,國內外針對小樣本調制識別的研究尚處于起步階段,但在其他領域已有一些半監督學習算法出現。半監督學習解決的就是有標簽樣本數量較少情況下如何提升模型性能的問題,其核心思想為結合無標簽數據進行優化。盡管無標簽數據沒有標簽信息但是它們和有標簽數據一樣都是從相同的數據源獨立同分布采樣得到的,因此它們包含的關于數據分布的信息對優化模型大有裨益[14]。半監督學習方法主要包括自訓練學習方法[15]、生成式學習方法[16]以及半監督支持向量機等[17]。
為了充分利用無標簽信號解決小樣本調制識別問題,本文提出了一種基于偽標簽半監督學習的小樣本調制識別模型。該模型通過優選人工特征集結合高性能分類器為無標簽信號進行預測打上偽標簽,然后利用深度學習類方法聯合訓練帶標簽樣本與偽標簽樣本從而實現小樣本調制識別。
1 小樣本識別模型
本文采用基于偽標簽的半監督學習方法,在僅有少量有標簽信號樣本的條件下進行調制方式識別。基于偽標簽的半監督學習是一種增量算法,算法流程圖如圖1所示,在分類器訓練部分,首先通過少量有標簽樣本提取優選人工特征送入高性能分類器中進行訓練,將信號識別準確率提升到一個較高水準,此時若環境中存在大量無標簽樣本,則進入偽標簽生成部分,利用訓練好的高性能分類器對無標簽樣本進行預測,通過預測的概率對無標簽樣本進行排序,給可靠的無標簽樣本打上偽標簽并加入到訓練集中,但該過程并非選擇所有的無標簽樣本均加入訓練集,因為全部無標簽樣本內包含的錯誤標簽樣本會嚴重干擾模型收斂。當環境中無標簽樣本不足時,也可利用分類器訓練部分模塊直接進行信號分類。
圖片
圖1 算法流程圖
偽標簽算法不斷迭代增加有標簽樣本數量,當有標簽樣本數量滿足迭代要求時,進入深度學習訓練部分,將所有帶標簽的樣本數據組合新的訓練集,使用分類能力更強的深度學習類方法對所有標簽樣本進行聯合訓練,最后利用訓練好的模型對測試信號進行預測。本文選取BP神經網絡作為生成偽標簽的高性能分類器,選取CNN卷積神經網絡作為深度學習方法訓練真實標簽樣本與偽標簽樣本的合集。
2 信號人工特征
本文選取多類具有良好區分性能的人工特征作為BP神經網絡輸入,這些特征均已被證明具有良好的區分能力,其中包括高階累積量特征、熵特征以及時頻特征。
2.1 信號高階累積量特征
在調制識別技術領域,高階累積量是應用非常廣泛的特征之一,其具有較強的周期分量,可用于準確識別不同的數字調制信號。為了提取高階累積量,首先要計算信號的高階矩,信號高階矩由(1)式計算:
Mpq=E[x(n)p-q(x*(n))q]
(1)
通過信號各高階矩便可計算得到許多高階累積量,本文選擇下列高階累積量,這些累積量均已被證明在調制樣式分類中有較好鑒別性能[18-19]
圖片
2.2 信息熵特征
熵是用于評價信號或系統狀態平均不確定性的指標。在信息論領域,熵用于衡量信息的信息量大小,信息的不確定程度越大,則其熵值越大,因此信息熵理論為我們提供了一個很好的信號特征描述方法。本文提取信號的功率譜熵、奇異譜熵和能量譜熵,以此作為信號的特征[20-21]。
2.2.1 功率譜熵
假設時間序列X長為L,對其進行離散傅里葉變換,變換結果為
圖片
(9)
式中:圖片表示傅里葉變換后的第k個頻譜;N表示變換點數,一般要求N為2的整數冪且接近序列X的長度。計算頻譜序列Y在y(k)處的功率譜
圖片
(10)
記
圖片
(11)
將(11)式代入香農熵計算公式,可得到功率譜香農熵。香農熵計算公式為:圖片式中,H表示熵值;pi表示信號概率分布。
2.2.2 奇異譜熵
奇異譜分析是近年來非常流行的一種研究非線性時間序列數據的強大方法,它結合相空間重構和奇異值分解對時間序列維數進行估計。若一段離散時間序列為
X=[x1,x2,x3…xN]
首先將信號分段,假設分段長度為m,在奇異譜分析過程中,m最好為信號周期的整數倍且不宜超過信號序列長度的1/3,重構后的序列軌跡矩陣為
圖片
(12)
對(12)式矩陣進行奇異值分解,可得
圖片
(13)
式中:U和V均為正交矩陣;U為左奇異矩陣;V為右奇異矩陣;Σ矩陣可化為對角陣
圖片
式中,σk表示矩陣M的奇異值且除對角線上元素以外其余值均為零,對角線上的非零元素便構成了序列的奇異值譜,即
σ={σ1,σ2,…σi,…σj|j
記pi表示非零奇異值σi占所有非零奇異值之和的比值
圖片
(14)
將(14)式代入香農熵計算公式,即可得到奇異值香農熵。
將(14)式帶入指數熵計算公式,即可得到奇異譜指數熵。指數熵的計算公式為:H=E[e1-pi]=∑pie1-pi。式中,H表示熵值;pi表示信號概率分布。
2.2.3 能量譜熵
對于序列信號X={x1,x2…xN},其能量譜定義為
圖片
(15)
式中,X(ω)表示序列X的離散傅里葉變換。記pi為
圖片
(16)
將(16)式代入指數熵計算公式,即可得到信號能量譜指數熵。
2.3 時頻特征
2.3.1 歸一化中心瞬時振幅功率密度最大值
歸一化中心瞬時振幅的功率密度最大值可在一定程度上反應不同信號的譜特征,其定義如下[22]:
圖片
式中:Ns表示信號序列長度;ma表示信號瞬時幅度的均值。
2.3.2 歸一化中心瞬時振幅絕對值的標準差
序列信號歸一化中心瞬時振幅絕對值的標準差可由(18)式求得,其定義如下
圖片
(21)
3 網絡結構
本節將對選擇的BP網絡與CNN卷積神經網絡作詳細介紹。選用BP網絡主要原因是BP網絡具有學習能力,可以自動學習各個特征對分類結果影響的權重,即送入網絡的特征中若有部分在分類方面作用不明顯那么其所屬權重就會減小。因此對于BP網絡而言,其對輸入的特征會自動進行“特征篩選”,這在一定程度上可以減輕對先驗信息的依賴,此外,由于深度神經網絡等模型參數龐大、權重太多,在小樣本條件時模型過擬合現象非常嚴重,因此淺層BP網絡用作小樣本階段訓練具有明顯優勢。
BP網絡的訓練過程如圖2所示,在開始訓練時,由于僅有少量的有標簽信號樣本,訓練出的模型泛化能力弱,而人工特征不依賴于訓練數據,可以彌補訓練數據量較少時特征表達能力不足的問題,因此本文設計的BP網絡模型輸入為已具備分類能力的優選特征集。首先對信號進行歸一化處理,然后計算信號熵特征、高階累積量特征和時頻特征,將所有特征組合后一起送入BP網絡訓練,最后利用softmax分類器輸出信號預測概率。
圖片
圖2 網絡訓練過程
BP網絡結構如圖3所示,本文設計的BP網絡由1層輸入層,4層全連接層以及softmax分類器構成,輸入層大小為1*13,分別代表13種人工提取的特征,各全連接層神經元個數分別為16,32,64,32,各神經元均采用ReLU激活函數。為提升網絡的泛化能力,在第三、四層全連接層后使用dropout技術干擾訓練以防止網絡過擬合,以提高網絡在測試樣本上的泛化能力,但干擾只發生在網絡訓練階段,在網絡模型生成偽標簽時則停止干擾,Dropout比率設置為0.5。BP網絡訓練產生的損失函數如下所示:
圖片
圖3 BP神經網絡結構
圖片
(22)
式中:圖片表示有標簽信號產生的分類損失;圖片表示偽標簽信號產生的分類損失;N表示有標簽信號數量;N′偽標簽信號數量,μ用于控制2類損失的比重。
在利用偽標簽算法迭代訓練BP網絡過程中,有時難免給無標簽信號樣本打上錯誤的偽標簽,因此偽標簽的準確性對網絡最終的識別率有決定性影響。由于softmax分類器輸出的是各個類別的預測概率,因此本文提出可靠條件為
p2+p3≤p1
(23)
式中:p1表示softmax分類器輸出的最大概率;p2,p3依次表示softmax分類器輸出的第二大、第三大概率。即只有softmax輸出的最大概率大于第二大概率與第三大概率之和時,才會給該無標簽信號打上偽標簽,通過此基于輸出概率的樣本選擇算法便可在一定程度上保證偽標簽的可靠性。
無標簽樣本標注偽標簽結束后,將真實標簽樣本與偽標簽樣本聯合起來送入CNN卷積神經網絡訓練,CNN結構如圖4所示。為充分發揮卷積神經網絡的特征提取能力,本文直接將IQ信號輸入卷積神經網絡,信號輸入網絡前,將其轉換為二維數據,即若信號長為L,則轉換后的數據格式為[2,L],兩路分別代表I路數據與Q路數據。網絡共包含3層卷積層和3層全連接層,其中第一個卷積層卷積核個數為64,核尺寸為2*4,第二個卷積層卷積核個數為32,核尺寸為1*4,第三個卷積層卷積核個數為16,核尺寸為1*4。卷積層完成對序列數據的特征提取,將提取后的特征轉換為一維序列送入全連接層,3層全連接層的維度分別為64,32,16,將第三個全連接層輸出的特征送入softmax分類器進行分類,輸出預測結果,并通過反向傳播不斷優化網絡參數。
圖片
圖4 卷積神經網絡結構圖
4 仿真結果及分析
本文選用的調制信號集為{BPSK,4PAM,4PSK,8PSK,16QAM,64QAM},共計6種數字調制信號,信號序列長度L=100,信噪比從-10至20 dB,間隔為2 dB。訓練集每類信號生成4 000個信號樣本,信噪比隨機,共計24 000個樣本。測試集每類信號每個信噪比點生成500個信號,共計48 000個信號,所有信號均由MATLABR2016a仿真生成。
網絡訓練均基于Python下的Keras深度學習框架實現,硬件平臺為Intel(R)Core(TM)i7-8700CPU,GPU為NVIDIA GeForce 1060Ti。
4.1 信號特征提取分析
本節對6類數字信號在-10至20 dB間每個信噪比點生成500個樣本,提取信號13種特征并取平均值,取其中具有代表性的特征并繪圖,得到圖5所示的特征曲線圖。在進行信號奇異譜分析時,由于信號序列長度L=100,且基帶序列為隨機生成無周期特性,因此設置分段長度m=33;在計算序列離散傅里葉變換時,由于要求傅里葉變換點數靠近序列長度且為2的整數冪,因此設置傅里葉變換點數
圖片
圖5 信號特征曲線圖
N=128。
圖5a)至5e)分別代表信號功率譜香農熵、高階累積量C40、高階累積量C61、奇異譜指數熵、功率譜峰值和瞬時幅度標準差隨信噪比變化的曲線。可以看出,隨著信噪比的不斷上升,各類信號特征間的差異越來越大,代表著特征的區分能力越來越強,但每個特征均有無法區分的調制信號,因此本文選擇綜合13類特征一起作為分類特征。
4.2 偽標簽算法可行性分析
本節對比3類識別算法在不同訓練樣本總量下的識別性能,分別為人工提取特征結合BP神經網絡、時序IQ序列結合CNN卷積神經網絡、時序IQ序列結合LSTM循環神經網絡,LSTM網絡為KERAS框架下的CuDNNLSTM。3類算法均迭代200次,使用Adam函數優化。當不同樣本量條件下進行調制方式識別時,各算法在測試集上的性能如圖6所示,從仿真結果可以看出,當訓練樣本數量有限時,例如圖6a)所示總樣本量為600個,通過人工提取特征結合BP神經網絡的識別率要遠高于CNN卷積神經網絡的識別率以及LSTM循環神經網絡的識別率。但隨著樣本數量的不斷增加,人工提取特征結合BP神經網絡的識別率變化不大,而CNN卷積神經網絡的識別率和LSTM網絡的識別率則上升的非常快,當總樣本量達到6 000時,CNN的最高識別性能已經優于人工提取特征結合BP網絡的性能,其最高識別率可以達到85%以上,當總樣本量達到24 000時,網絡的最高識別率可以達到95%以上。因此,利用人工特征結合BP神經網絡在樣本量較少的情況下采用偽標簽增量算法增加訓練數據總樣本量,而后采用CNN卷積神經網絡進行訓練是可行的。
圖片
圖6 不同樣本總量下各算法識別率曲線
4.3 偽標簽算法識別率分析
通過4.2節中的仿真結果可分析出,在樣本量充足的條件下本文提出的CNN深度卷積神經網絡模型性能優于CuDNNLSTM網絡,因此本文選用CNN作為訓練模型對打偽標簽后的樣本集進行訓練。
假設初始條件為有每類調制信號有100,500,1 000個帶標簽樣本,共600,3 000,6 000個帶標簽樣本以及48 000個無標簽樣本,首先通過人工提取特征結合BP神經網絡對600,3 000,6 000個帶標簽樣本進行訓練,而后通過偽標簽增量算法對無標簽樣本打偽標簽,最后利用CNN對有標簽樣本、偽標簽樣本的IQ序列進行聯合訓練。在CNN網絡訓練過程中,由于真實標簽樣本與測試集樣本分布相同且標簽準確,因此本文選用真實標簽樣本作為驗證集,以此提升網絡在測試集上的識別性能。
當使用600個真實標簽樣本對大量無標簽樣本預測偽標簽時,樣本數隨迭代次數的變化如表1所示。
表1 600個真實樣本
圖片
從表1的結果可以看出,隨著迭代次數的不斷增加,偽標簽數量不斷提升,但由于設置了可靠條件,所以偽標簽樣本總量并未達到48 000。將所有真實標簽樣本和偽標簽樣本一并送入CNN卷積神經網絡進行訓練,共計29 520個樣本,測試集的識別率如圖7所示。
圖片
圖7 偽標簽算法識別率對比
當訓練樣本總量為29 520時,算法各部分運行時間如表2所示,當使用3 000個真實標簽樣本對大量無標簽樣本預測偽標簽時,樣本數隨迭代次數的變化如表3所示,從表3的結果可以看出,隨著迭代次數的不斷增加,偽標簽數量不斷提升,經過5次迭代后訓練樣本數總數可達36 566個,測試集的識別率如圖8所示,當訓練樣本總量為36 566個時,算法各部分運行時間如表4所示。
表2 算法運行時間 單位:s
圖片
表3 3 000個真實樣本
圖片
表4 算法運行時間 單位:s
圖片
圖8 偽標簽算法識別率對比
當使用6 000個真實標簽樣本對大量無標簽樣本預測偽標簽時,樣本數隨迭代次數的變化如表5所示。從表5的結果可以看出,隨著迭代次數的不斷增加,偽標簽樣本數量不斷提升,經過5次迭代后訓練樣本數總數可達41 063個,測試集的識別率如圖9所示。
表5 6 000個真實樣本
圖片
圖9 偽標簽算法識別率對比
當訓練樣本總量為41 063時,算法各部分運行時間如表6所示。
表6 算法運行時間 單位:s
圖片
通過仿真結果可以看出,在小樣本條件下,利用偽標簽增量算法對傳統特征結合BP神經網絡的識別性能有一定的提升,當信噪比大于5 dB時,本文提出的偽標簽CNN的網絡識別率相較于BP神經網絡結合人工特征的識別率可提高約5%~10%。
實際上本文提出的偽標簽半監督模型,其性能與生成偽標簽所用的人工特征集以及分類器密切相關,通過大量實驗發現,如果偽標簽標注分類器不能很好區分信號類型,那么能夠獲得的有效偽標簽樣本就會較少,總體識別準確率就會偏低,但如果能進一步提升偽標簽分類器的識別率,將其控制到90%以上,那么整體算法的識別率甚至可以接近100%。在實際應用過程中,一方面可以實時監控偽標簽樣本數量分布,從而掌握深度學習類方法是否有足夠的樣本量支撐,另一方面還可以不斷改進特征集和分類器,繼續研究更具區分能力的特征并選擇更復雜的模型作為偽標簽生成器,這樣深度學習類方法的性能也會不斷提升。
5 結 論
本文針對戰場信號調制識別領域可能出現的小樣本情況進行研究,設計了基于人工優選特征集與BP神經網絡的信號偽標簽標注方法,并結合基于CNN的通信信號分類模型,形成了小樣本條件下通信信號分類新的解決方案,通過大量的實驗驗證了方案的可行性,在單個信號類型的帶標簽樣本量為100以上時,本文模型就可有效工作,且在不同標簽樣本量條件下,其總體性能均比常規方法有明顯提升。
審核編輯:符乾江


























 工商網監
工商網監
評論