 電子發燒友App
電子發燒友App


基于深度學習的IRS輔助MIMO通信系統的CSI壓縮及恢復研究
摘要: 智能反射面(IRS, Intelligent Reflecting Surface)因成本低、功耗低、可提升通信質量等優點被廣泛研究。在采用正交頻分復用作為多載波調制方案的IRS輔助頻分雙工多輸入多輸出(MIMO, Multiple input Multiple Output)通信系統中,為了提升系統的系統增益,用戶端(UE, User Equipment)需要將多個信道的信道狀態信息(CSI, Channel State Information)通過反饋鏈路發送至基站端(BS, Base Station)。因此,相比于傳統的MIMO系統,該系統中CSI的數據量和反饋開銷無疑將會是更加巨大的。針對此問題,本文提出了一種基于注意力機制的深度殘差網絡IARNet (Inception-Attention-Residual-Net)來對大數據量的CSI進行壓縮重建。該網絡在傳統的Inception網絡結構上結合了多卷積特征融合、混合注意力機制以及殘差等子模塊,這種混合結構可以有效地將大數據量的CSI進行壓縮重建。仿真結果表明,與現有的2種深度學習網絡相比,IARNet在基于熱身法的模型訓練方案加持下可以顯著提高大數據量CSI的重建質量。
1. 引言
隨著5G通信網絡進入商業化階段,為了獲得更快和更可靠的數據傳輸,6G通信技術已經處于研究狀態,其中智能反射面(IRS, Intelligent Reflecting Surface)技術因其成本低、易部署、功耗低、可提升通信質量等特點被應用到各種無線通信系統。IRS是一種有大量無源反射單元的表面,該表面的反射單元可以將入射信號進行被動反射,通過調整IRS的反射系數還可以進一步提高反射信號的傳輸質量。因為IRS十分輕巧,所以人們可以輕易地將其部署在建筑外墻、廣告面板和樓頂等地方。在信號反射的過程中,由于IRS除了控制反射單元以外無需消耗額外能量的特點,因此IRS被業界廣泛視作為一種綠色、環保以及有前景的技術。基于上述優點,IRS技術很好地契合了現階段人們對6G的愿景,即智能、融合、綠色 [1] [2] [3] [4] [5]。
深度學習是一種通過構造深層網絡自動地提取出數據內在特征和規律的人工智能技術。自從2012年Geoffrey Hinton等人使用深度學習技術并以絕對優勢獲得了ImageNet圖像識別比賽的冠軍以來,越來越多的研究者參與對深度學習的研究并取得了巨大進展。最近研究表明,深度學習技術不僅在圖像識別領域有杰出表現,而且在自然語言處理和圖像壓縮等領域也取得了不俗的成績 [6] - [18]。近年來有很多通信領域的研究者將深度學習技術應用在了通信相關領域,和傳統的通信算法相比,深度學習在信道估計、信號檢測和CSI (CSI, Channel State Information)反饋等方向上獲取了更好的表現。
針對CSI反饋開銷過大的問題,文獻 [15] 首次提出了使用深度學習技術將CSI進行壓縮再重建,并提出了名為CsiNet的深度學習網絡。相比于傳統壓縮感知的方法,CsiNet有更好的重建質量和重建速度。文獻 [16] 在CsiNet的基礎上引入了Inception模塊,提出了多分辨率體系結構的網絡:CRNet。相比于CsiNet,CRNet可以在網絡參數變化不大的情況下進一步提升重建的質量。文獻 [17] 在CsiNet的基礎上引入了Dense Block模塊,提出了有極致殘差模塊的網絡:DS-NLCsiNet。相比于CsiNet,DS-NLCsiNet進一步提高了重建質量和恢復精讀。文獻 [18] 在CsiNet基礎上引入了量化模塊,提出了QuanCsiNet。相比于CsiNet,QuanCsiNet可以進一步壓縮反饋的CSI。此外文獻 [18] 在訓練深度學習網絡的時候還使用了基于真實信道的數據集,這進一步表明了基于深度學習的CSI壓縮反饋確實是有效的。
但是現有的網絡和工作都是在壓縮和重建數據量較小的CSI,數據量一般都不超過2048個32位浮點數。在IRS輔助的頻分雙工(FDD, Frequency Division Duplex)模式下的多輸入多輸出(MIMO, Multiple input Multiple Output)通信系統中采用正交頻分復用(OFDM, Orthogonal Frequency Division Multiplexing)作為多載波的傳輸方案。該系統中下行鏈路反饋的CSI不僅包括基站端(BS, Base Station)到用戶端(UE, User Equipment)的CSI,還需要包括BS到IRS的CSI以及IRS到UE的CSI,因此該系統的反饋開銷將會是更加巨大的,同時使用深度學習將CSI進行壓縮和重建的時候數據量也會大大增加。在本系統中壓縮和重建的數據量超過了一般工作研究的4倍,達8704個32位浮點數。現有的網絡在本系統中對數據量更大的CSI進行壓縮重建的時候會出現重建質量低下的問題。因此需要針對數據量更大的CSI設計出一種新的深度學習網絡來將CSI壓縮和重建,以提升系統的重建質量。
本文針對IRS輔助的通信系統中反饋開銷更加巨大的問題提出了一種新的深度學網絡IARNet以及基于熱身法的模型訓練方案 [7]。IARNet在傳統卷積神經網絡基礎上采用了多卷積特征融合、混合注意力機制以及殘差等模塊。通過仿真發現:與現有的深度學習網絡相比,IARNet在基于熱身法的模型訓練方案加持下可以顯著提高CSI重建質量,即使是在較低壓縮比下IARNet仍能很好地將CSI恢復出來。本文的貢獻總結如下:
1) 研究了在IRS輔助下的MIMO通信系統的CSI壓縮及重建問題,并提出了相關系統模型。
2) 針對一般深度學習網絡在大數據量CSI壓縮重建過程中出現重建質量低下的問題,本文在傳統卷積網絡的基礎上加入了多卷積特征融合、混合注意力機制以及殘差等模塊,提出了深度學習網絡IARNet,實驗表明,在基于熱身法的模型訓練方案加持下可以顯著提高CSI重建質量。
3) 進一步研究了基于熱身法的學習率調整策略與三種傳統的學習率調整策略在1/8壓縮比下對網絡的性能影響,實驗表明:相比于傳統方法基于熱身法的學習率調整策略可以進一步提高CSI的重建質量,重建質量至少提升24.9%。
2. 系統模型
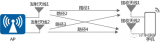
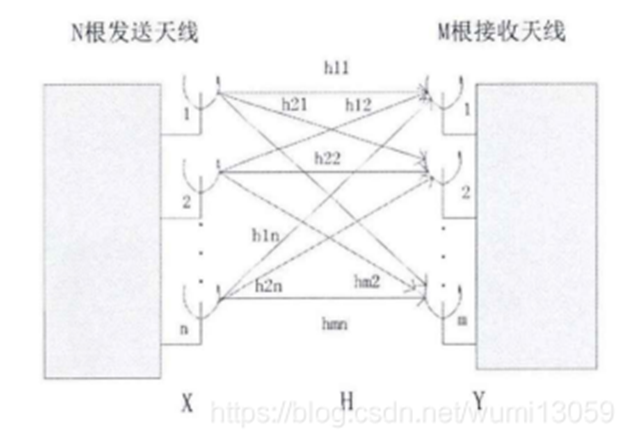
本文研究IRS輔助下的MIMO FDD通信系統,它采用OFDM作為多載波的傳輸方案,系統模型如圖1所示。
在該系統中,配置有 NiNi 個反射單元的IRS輔助有 NtNt 根天線的BS與有 NrNr 根天線的UE進行通信,而OFDM的子載波數量則設置為 NcNc。那么UE處第 mm 根天線在第 cc 個子載波接收到的信號 ym,cym,c 可以表達為:
Figure 1. A IRS-assisted MIMO FDD communication system model
圖1. IRS輔助下的MIMO FDD通信系統模型
BS需要設計合理的預編碼向量 vcvc 才能消除用戶間干擾進而提升通信質量。然而在FDD模式下,BS需要獲得精確的下行鏈路CSI才能對路預編碼向量進行合理設計。在該系統中,完整維度的下行鏈路的CSI H′H′ 包括BS到UE信道的CSI H1∈CNt×Ni×NcH1∈CNt×Ni×Nc 、BS到IRS信道的CSI H2∈CNi×Nr×NcH2∈CNi×Nr×Nc 、IRS到UE信道的CSI H3∈CNt×Nr×NcH3∈CNt×Nr×Nc,即 H′=[H1,H2,H3]H′=[H1,H2,H3]。完整的CSI數據如圖2所示。
Figure 2. Schematic of the complete CSI data
圖2. 完整的CSI數據示意圖
因為時延擴展的有限性,CSI中會有大量的0值,所以放入IARNet的CSI矩陣可以將CSI截斷并只保留前 N?cN?c 行的有效數據,階段后的CSI可以表示為
本文主要研究深度學習在IRS輔助下通信系統CSI壓縮與恢復,因此假設UE已經獲得了反饋的所有CSI,即忽略信道估計誤差,同時假設BS也能完整地接收到UE反饋的所有信息。
本系統在UE和BS分別設置了編碼器和譯碼器,UE處的編碼器可以將原始的 JJ 維的CSI HH 壓縮成 KK 維向量 cc,壓縮比可以表示為: η=K/Jη=K/J,其中 (K
式中: H?H^ 表示重建后的CSI矩陣; fdefde 表示譯碼器; ΘdeΘde 表示譯碼器的深度學習網絡參數。
為了評估本系統的重建質量,本系統使用歸一化均方誤差(NMSE, Normalized Mean Squared Error)作為判斷標準,NMSE可以評估原始CSI與重建后的CSI之間的誤差,這個值越小表示系統重建質量越佳,因此本文主要的目標是通過優化系統模型最小化該值。其中NMSE定義為:
式中: ∥?∥2‖?‖2 表示L2范數。
3. IARNet的結構
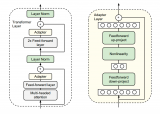
本文所提出的IARNet深度學習網絡結構如圖3所示,其由UE處的編碼器和BS處的解碼器構成。IARNet的輸入是信道CSI HH, HH 的具體尺寸為 128×16×6128×16×6,其中128表示角度,16表示截斷后的子載波數,6表示三個CSI的虛數和實數。IARNet的輸出是重建后的CSI H?H^,尺寸和 HH 一致。
Figure 3. Architecture of IARNet
圖3. IARNet的架構
在編碼器側。模型首先將 HH 放入混合注意力模塊進行特征提取。該模塊同時提取了CSI在空間和通道上的數據,經過該模塊后深度學習網絡可以更專注于信息量大的數據,提升數據權重,反之降低信息量小的數據權重,加強了特征表達能力。然后,將數據放入編碼器復合模塊處理。該模塊主要是借鑒了Inception網絡的思想,將多個尺寸卷積后的結果直接進行拼接處理,這可以讓拼接后的結果具有多維度特征信息的特點。此外該模塊還引入了分組卷積的處理方法以降低訓練參數。接著再利用混合注意力模塊進行特征提取,進一步加強了特征表達能力。接著,將數據Reshape成長度為 128×16×6=12288128×16×6=12288 的一維向量并將其輸入到神經元數量為 8704×η8704×η 的全連接層神經網絡中進行壓縮,其中8704表示 HH 的有效數據,為了對齊6個通道的尺寸, H′3H′3 需要補0處理,具體見第五章仿真部分。最后,通過反饋鏈路將壓縮后的數據發送給BS端的解碼器。
在解碼器側。模型首先將長度為 8704×η8704×η 的一維向量Reshape成 HH 尺寸大小的矩陣。然后,用解碼器復合模塊將數據進行處理。該模塊與編碼器復合模塊類似,但是更輕量化。其中該模塊引入了比例殘差的設計,相比一般的殘差網絡,網絡性能更佳。最后,解碼器輸出重建后的CSI矩陣 H?H^。
混合注意力模塊主要由通道注意力模塊和空間注意力模塊兩部分組成。通道注意力模塊中,首先通過兩種并行的平面平均池化和平面最大池化的處理,接著再將它們分別送入MLP神經網絡之中,最后通過Sigmoid函數輸出結果。通過通道注意力模塊處理讓模型關注到通道之間的關系并自動學習到不同通道特征的重要程度。空間注意力模塊中,將通道注意力模塊輸出的數據作為輸入,首先通過兩個并行的通道平均池化和通道最大池化處理并將兩個處理結果進行通道拼接,然后通過卷積操作將通道降為一維,最后進行Sigmoid激活函數處和殘差處理。通過通道注意力模塊處理,模型會關注到同一通道上不同數據位置的關系并自動學習到不同空間特征的重要程度。混合注意力模塊的結構如圖4所示。混合注意力模塊的輸入為 128×16×6128×16×6 的特征,其中6表示為輸入特征通道數;16表示特征的高度即子載波數;128表示特征的寬度即角度; 1×61×6 表示MLP神經網絡的神經元個數; ?? 表示矩陣乘法; ⊕⊕ 表示矩陣加法;
混合注意力模塊同時關注到了通道信息和空間信息的重要關系,增大了有效通道和空間的權重,減少了無效通道和空間的權重,進而提升了網絡性能。同時混合注意力模塊還可以很輕易地集成到現有的深度學習網絡架構上去,輸入與輸出的特征尺寸完全一致,這讓網絡的配置更加簡單和便捷。
Figure 4. Architecture of hybrid attention module
圖4. 混合注意力模塊的架構
復合網絡模塊的結構
編碼器復合模塊及解碼器復合模塊如圖5所示,其中每個方框附近的小數字表示此步的通道數(卷積核個數),在數據處理的過程中CSI的長寬不變,即保持為 128×16128×16 尺寸的數據,通道數隨著卷積核變化。
文獻 [15] 中已經證明基于 3×33×3 卷積和殘差網絡的CsiNet在信道壓縮中的應用是有效的。但CsiNet是一種固定卷積尺寸的網絡,固定尺寸卷積處理下的網絡并不能很好地同時提取稀疏矩陣和密集矩陣的特征。如果想較好地同時提取稀疏矩陣和密集矩陣的特征,就需要考慮同時用不同尺寸卷積處理CSI。小尺寸的卷積處理(如 3×33×3 卷積)可以提取CSI更加精細的特征,在處理密集CSI的時候小尺寸的卷積有更好的效果。大尺寸的卷積處理(如 9×99×9 卷積)可以提供更大的感受視野,在處理稀疏CSI的時候這種卷積有更好的效果。因此在編碼器復合模塊和解碼器復合模塊中大量使用了多支路并行的多尺寸卷積處理,然后將不同支路上的結果在通道上直接拼接起來,這樣可以將不同尺寸卷積處理下的結果進行多卷積特征融合,讓輸出擁有更加豐富的特征。特別是在編碼器復合模塊中,為了更好提取原始CSI的特征,編碼器復合模塊在中同時使用了 3×33×3 卷積、 5×55×5 卷積、 7×77×7 卷積和殘差的并行處理,這將極大地豐富了輸出特征。此外,每個卷積模塊進行卷積處理前都進行了一次批歸一化處理。
Figure 5. Composite module of encoder (left) and decoder (right)
圖5. 編碼器復合模塊(左)及解碼器復合模塊(右)
為減少復合網絡模塊中的參數數量和運算復雜度,模型還引入了分組卷積的處理方法。在分組卷積中通過以下步驟來分解 M×MM×M 卷積。首先,設置組數 gg 并將原來的特征通道數平均分解成 gg 組,每個小組的特征通道數為原來的 1/g1/g,每一個小組的卷積核個數也為原來的 1/g1/g,保持長寬不變。然后,每個小組進行 M×MM×M 的卷積計算。最后,將每個小組的結果進行通道拼接,最終輸出的特征尺寸不變。而且由于將標準的 M×MM×M 卷積拆分成了更小規模的子運算,這可以大幅度降低運算復雜度,減少設備的運行要求。
此外,為了解決梯度消失的問題,提高系統的性能,復合網絡模塊還加入了大量的殘差網絡。特別是在解碼器復合模塊的末端還利用了比例殘差的網絡,即將主干的輸出乘以一個小于1的系數(本網絡采用0.7),調整主干的輸出比例。經此設計,IARNet的性能有進一步的提升。
4. 學習率及其調整策略
在深度學習模型的訓練過程中,模型訓練方案對模型的最終呈現效果有著決定性的影響。在一些基于深度學習的信道壓縮反饋研究中,其模型訓練方案是相對簡要的,沒有針對特定的系統模型進一步優化模型訓練方案。如在CsiNet和DS-NLCsiNet的文章中,模型的batch size、epochs和初始學習率分別直接設置為200、1000和0.001,也沒有設置學習率調整策略。這些文章都省略了對模型訓練方案的介紹,特別是學習率及其調整策略上,而這恰恰是十分重要的。
如果學習率設置過高,雖然系統訓練會加快,但是在采用梯度下降算法來尋找全局最優解的過程中,損失函數將不會收斂至全局最小值附近。如果學習率設置過小,雖然網絡可以尋找到全局最優解,但是這會花費大量的訓練時間并且很容易陷入局部最優解。另外學習率調整策略對系統訓練也有很大的影響,一般采用的策略有固定法、步衰減法(Step Decay)法以及余弦衰減法(Cosine Decay)等。固定法需要多次試驗才能找到較好的學習率,而且網絡也很容易陷入局部最優解。衰減類的方法可以在較高的學習率上加速網絡訓練,然后在低學習率上尋找到全局最優解 [19]。在IARNet的模型訓練方案上采用基于熱身法的余弦衰減學習率調整策略。由于深度學習網絡在剛開始訓練的時候非常不穩定,所以我們需要將初始的學習率設置得很低,這可以讓深度學習網絡緩慢地趨向于穩定。當網絡趨于穩定的時候再升高學習率,這可以讓網絡可以快速地收斂,這個過程就稱之為熱身,熱身完之后將采用余弦衰減的方法減少學習率。這樣就可以讓整個訓練過程變得平穩、快速,同時也提高了網絡性能。本方案的學習率調整策略可以表達為:
 Figure 6. Learning rate adjustment strategy of cosine decay based on the warm-up method
Figure 6. Learning rate adjustment strategy of cosine decay based on the warm-up method
圖6. 基于熱身法的余弦衰減學習率調整策略
5. 仿真結果
仿真過程中BS的天線數設置為4,IRS的反射單元數設置為32,UE的天線數設置為4,子載波數設置為128。仿真采用COST 2100信道模型 [20] 在中心頻率為5.3GHz的頻帶的室內場景下生成數據集。其中BS到IRS之間信道用發射天線數為4、接收天線為32的信道替代,IRS到UE之間信道用發射天線數為32、接收天線為4的信道模型替代。然后將BS到IRS、IRS到UE以及BS到UE的CSI在通道上拼接起來。因為時延擴展的有限性,CSI中會有大量的0值,所以將CSI截斷并只保留前16行的有效數據。然后將截斷后CSI中的6個通道的特征尺寸補齊,即BS到UE的CSI由 16×1616×16 用0值擴展至 128×16128×16。6個通道保持 128×16128×16 的尺寸,其中有效數據為8704,其余數據為對齊CSI補的0值,壓縮比是按照有效數據8704與壓縮后的數據量計算。補齊后CSI的尺寸為: 128×16×6128×16×6。其中128表示為角度;16為子載波;6分別為BS到IRS的CSI、IRS到UE的CSI以及BS到UE的CSI的虛數和實數。
使用COST 2100模型生成10萬個數據集,然后按照4:1的比例將數據集分成訓練集和測試集。模型訓練時,采用均方誤差(MSE, Mean Squared Error)作為系統的損失函數,使用Adam算法 [21] 更新參數。batch size設置為150,epoch設置為100,初始學習率設置為0.0045并使用基于熱身法的模型訓練方法, epoch′epoch′ 設置為20。
本文比較了IARNet與CRNet與CsiNet在不同壓縮比下的性能表現,結果如表1所示,加粗表示為該壓縮比下的最佳性能表現。仿真結果表明,IARNet在大數據量CSI壓縮場景下對比其他基于深度學習的CSI重建算法有更好的性能表現,即使是在1/32的壓縮比下IARNet仍能將CSI較好地重建起來,這主要得益于IARNet采用了多卷積特征融合、混合注意力機制以及比例殘差等方法并進行了聯合優化,在優化過程中盡量避免了不必要的計算開銷,這讓網絡保持性能的同時也更輕量化。
| 壓縮比 | 深度學習網絡 | NMSE |
| 1/2 |
CsiNet CRNet IARNet |
1.0889 0.5529 0.0273 |
| 1/4 |
CsiNet CRNet IARNet |
1.0894 0.5537 0.0281 |
| 1/8 |
CsiNet CRNet IARNet |
1.0902 0.5625 0.0680 |
| 1/16 |
CsiNet CRNet IARNet |
1.0910 0.6172 0.1740 |
| 1/32 |
CsiNet CRNet IARNet |
1.0919 0.6578 0.3841 |
| 1/64 |
CsiNet CRNet IARNet |
1.2300 0.8266 0.6076 |
Table 1. Comparison of NMSE performance of IARNet with CRNet and CsiNet
表1. IARNet與CRNet和CsiNet算法的NMSE性能比較
圖7是IARNet、CRNet和CsiNet在壓縮比為1/8下系統的NMSE隨著epoch變化的曲線。由圖7所示,在訓練過程中,CsiNet的NMSE始終保持較高的水平,NMSE從最初的25.112收斂至1.0902,這表明數據集超出了系統的學習能力,CsiNet無法學習和重建大數據量的CSI。CRNet的NMSE從最初的3.11可以收斂至0.5625,但是33個epoch后系統的NMSE基本不變,這表明CRNet可以學習和重建部分CSI的數據,但是重建質量不佳。IARNet的NMSE從最初的0.9912可以收斂至0.0680,NMSE曲線在整個訓練過程中都趨于下降,在90個epoch后逐漸平穩,這表明IARNet可以很好地學習和重建大部分的CSI數據,重建質量佳。
Figure 7. NMSE variation curves of three networks at 1/8 compression ratio during the training process
圖7. 訓練過程中三種網絡在1/8壓縮比下的NMSE變化曲線
圖8是IARNet在壓縮比為1/8下系統的測試集損失函數和訓練集的損失函數隨著epoch變化的曲線。由圖7可見,測試集損失函數和訓練集的損失函數隨著epoch增加而逐漸減少,測試集損失函數在訓練集損失函數附近波動。訓練結束后,訓練集的損失函數可以收斂至0.03附近,訓練集的損失函數可以收斂至0.05附近,這說明IARNet有輕微的過擬合,但是整體上可以忽略不計。
Figure 8. Comparison of the loss functions of the training and test sets
圖8. 訓練集和測試集的損失函數對比
此外本文還比較了四種學習率調整策略配合其最佳初始學習率在壓縮比為1/8情況下對IARNet性能的影響。第一種是本方案采用基于熱身法的余弦衰減方案,最佳初始學習率為0.0045。第二種方案是固定法,最佳初始學習率為:0.0002。第三種方案是步衰減法,最佳初始學習率為:0.001。第四種方案是余弦衰減法,最佳初始學習率為0.0003。NMSE隨著訓練過程推進的仿真變化曲線如圖9所示。由圖9仿真結果表明,相比于傳統的學習率調整策略,本方案采用的方法可以讓系統有更好的重建性能,NMSE收斂至更低的水平,可達0.0683。而固定法、步衰減法和余弦衰減法訓練后的系統分別收斂至0.1572、0.0903和0.1822。相比傳統的方法基于熱身法學習率調整策略的重建質量至少提升24.9%。
Figure 9. NMSE variation curves of four learning rate adjustment strategies during training
圖9. 訓練過程中四種學習率調整策略的NMSE變化曲線
另外表2比較了IARNet與CRNet和CsiNet在不同壓縮比下的參數量,M表示百萬。IARNet除了在1/64壓縮比下參數量高于CRNet和CsiNe以外,其他壓縮比下的參數量均小于IARNet和CRNet,因此IARNet可以較易地被部署在各類設備里面,節省設備存儲空間。
| ? | 壓縮比 | 1/2 | 1/4 | 1/8 | 1/16 | 1/32 | 1/64 |
| 參數量 | CsiNet | 67.22M | 33.63M | 16.82M | 16.82M | 4.26M | 2.21M |
| CRNet | 67.13M | 33.57M | 16.79M | 16.79M | 4.21M | 2.11M | |
| IARNet | 40.95M | 24.17M | 15.78M | 15.78M | 3.91M | 2.86M |
Table 2. Comparison of the number of parameters of IARNet with CRNet and CsiNet at different compression ratios
表2. IARNet與CRNet和CsiNet在不同壓縮比下的參數量比較
6. 結論
本文針對IRS輔助的通信系統中反饋開銷更加巨大的問題提出了一種新的深度學網絡IARNet。該網絡在傳統的Inception網絡結構上結合了多卷積特征融合、混合注意力機制以及殘差等子模塊,這種混合結構可以有效地將大數據量的CSI進行壓縮重建。計算機仿真結果顯示IARNet在IRS通信系統中對大數據量的CSI進行壓縮重建有更好的表現,并且基于熱身法的模型訓練方案優于傳統的固定法和衰減類法。
審核編輯:湯梓紅




















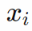









 工商網監
工商網監
評論