 電子發燒友App
電子發燒友App


摘要: 推薦系統作為信息篩選工具,通過對用戶個人信息記錄分析以實現用戶興趣預測,推薦滿足用戶需求的物品列表,其核心是推薦算法。現有的推薦算法大多需要收集用戶大規模的數據訓練來實現,存在數據稀疏性的問題,且當用戶需要購買新物品時,往往無法進行有效的推薦。針對該問題,本文提出了一種基于知識圖譜和內容的推薦算法。首先,解析用戶記錄并構建知識圖譜,設計基于知識圖譜的相似度算法,對知識圖譜中的實體與關系進行相似度計算;其次,基于文本詞嵌入對內容進行向量化表示,并構建基于內容的相似度算法;最后,本文融合了基于知識圖譜的相似度算法和基于內容的相似度算法,通過權重計算選取得分高的值作為推薦結果。與其它模型在MovieLens數據集上進行了實驗對比,實驗結果表明,本文所提出的算法在召回率和準確率方面有明顯的提升。
1. 引言
隨著互聯網的發展,人們在享受網絡便利的同時,也越來越受到海量信息的影響,無法快速搜尋到滿足自己真正需求的內容。推薦系統應運而生,其是智能學習的一個研究領域,目標是根據用戶的喜好給用戶提供有效的推薦結果。推薦系統可以通過物品的內容信息,根據用戶的歷史偏好數據、用戶個人興趣、網絡社交信息、所在環境等信息,判斷用戶目前最需要或者最感興趣的內容(物品或服務) [1],已經廣泛應用于商務網站,資訊和旅游網站等 [2]。
推薦系統的核心是推薦算法的研究,目前主流的推薦算法主要有三類,包括協同過濾推薦算法、基于內容的推薦算法以及基于深度學習的推薦算法。協同過濾推薦算法的核心思想就是充分利用與目標用戶興趣偏好相同的用戶群體喜好來進行高精度推薦 [3]。文獻 [4] 中介紹了一個成熟的推薦系統LibFM (Lithium Bis Fuoromalonato),該系統依賴于協同過濾算法,利用鄰域模型分析用戶與物品特征之間的相似度,為用戶提供推薦服務。但是由于協同過濾推薦算法主要是根據用戶的歷史行為數據發掘偏好,因此推薦質量取決于用戶的歷史數據集,存在數據稀疏性問題。基于內容的推薦算法是將用戶偏好與項目內容特征進行匹配,進而為用戶提供推薦結果 [5],其原理就是通過對比目標用戶的中意項目元數據,根據內容相似程度為目標用戶產生新的推薦。因此較為直觀,應用較為廣泛,但其對于復雜屬性的項目較難處理。隨著深度神經網絡的發展,基于深度學習的推薦算法也越來越受到青睞。文獻 [6] 中提出了圖協同神經過濾算法,從卷積神經網絡出發,提取物品特征,聚合多鄰數特征以構建物品向量,通過提升物品相似度的計算結果來提升推薦性能。Sharma等人 [7] 專注于提高基于深度神經網絡技術的推薦系統的有效性,通過多個推薦方法的排列組合以進行推薦。文獻 [8] 提出了深度知識注意力網絡(Deep Knowledge-Aware Networks, DKN),融合了實體嵌入和詞嵌入,其中實體嵌入采用TransH (Translating on Hyperplanes)學習,但是DKN對實體的表征不明確,無法為個性化推薦提供有用的信息。與傳統推薦方法相比,基于深度神經網絡的推薦算法無需人工提取特征,具有處理復雜屬性項目的能力。但其需要大量的數據作為支撐,無法解決數據稀疏性問題。
隨著知識圖譜的出現,將知識圖譜作為輔助信息引入到推薦系統中,通過知識圖譜中實體之間豐富的關系能豐富項目和項目的聯系、增強推薦算法的挖掘能力,從而有效彌補數據稀疏性的問題 [9]。文獻 [10] 中利用通過異構信息網絡(Heterogeneous Information Network, HIN)學習實體之間的路徑信息,能夠利用任意用戶指定的實體連接路徑,并返回相似度最高的實體。但是由于用戶定義的元路徑很難達到最佳,所以當近鄰數達到一定程度時,其推薦性能作用有限。
綜上可以看出,單一的推薦算法存在或多或少的缺陷,譬如數據稀疏性問題、處理復雜屬性困難等問題,尤其是當用戶需要購買新物品時,其推薦效果不佳。為了解決這個問題,本文提出了一種基于知識圖譜與內容的推薦算法。首先,解析用戶記錄并構建知識圖譜,基于圖譜嵌入計算得到實體與關系的相似度;其次,基于文本詞嵌入對內容進行向量化表示,并構建算法對內容進行相似度計算;最后,本文融合了基于知識圖譜的相似度算法和基于內容的相似度算法,通過權重計算選取得分高的值作為推薦結果。通過7折交叉驗證的方法表明,在一個完備的推薦系統中,近鄰數的選取并不是越大越好,而是應該進行適當的選擇。通過對比驗證的方法表明,在相同近鄰數的情況下,本文提出的融合算法具有較高的召回率和準確率,這是由于本文的算法在基于內容的推薦算法基礎上,利用知識圖譜實體之間的多關系和屬性進行了融合相似度計算,提升了算法的性能。
2. 架構流程
2.1. 推薦系統架構
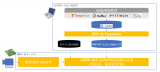
一個完整的推薦系統如圖1所示。首先,通過Lambda架構 [11] 進行數據采集,底層數據搜集起來,包括用戶的行為日志、一些后臺的業務數據以及通過爬蟲得到一些數據信息等;然后,將搜集到的數據信息傳遞到推薦算法模塊,基于這些信息來選擇合適的推薦算法;之后,進入用戶服務模塊,通過調參等步驟確定模型的具體參數,構建新的推薦模型,當有新的用戶數據到來之際,推薦模型將推薦的結果反饋給用戶;最后,用戶基于這些推薦結果產生一些行為數據,即用戶行為反饋模塊,推薦系統將這些用戶的行為反饋通過Lambda架構收集起來,進行分析處理,繼而為用戶提供更加完善的服務。
Figure 1. The framework of recommended system
圖1. 推薦系統整體架構圖
其中,大數據Lambda架構提供了一個結合實時數據和Hadoop預先計算的數據環境和混合平臺,能夠提供實時的數據視圖。推薦算法模塊基于用戶的歷史行為數據預估用戶對于某商品的點擊率,進而將推薦結果反饋給用戶,實現商品的推薦。由推薦系統整體架構可知,推薦算法的優劣直接決定了推薦系統的好壞,所以推薦算法的研究就尤為重要。
2.2. 基于內容的推薦算法流程
一般來說,基于內容的推薦算法包括以下三步 [12]:
1) 抽取該物品的一些特征用來表征這個物品;
2) 根據用戶的歷史行為數據信息學習出用戶感興趣的物品的特征,即構造用戶偏好文檔;
3) 比較步驟(2)得出的用戶偏好文檔和待推薦物品的特征(推薦項目文檔),確定出關聯性最大的一組物品作為推薦列表并將其推薦給用戶。
本文中,基于內容的推薦算法流程如圖2所示。
Figure 2. The procedure of content-based recommendation algorithm
圖2. 基于內容的推薦算法流程
2.3. 基于知識圖譜的推薦算法流程
基于知識圖譜的推薦算法流程如圖3所示。首先,根據物品知識及用戶知識構建物品知識圖譜,并將原有的物品信息及用戶信息轉化為三元組的形式;然后,對上述三元組進行知識表示,將構建好的物品知識圖譜數據作為表示模型的輸入;最后,計算求得物品的相似度,生成物品相似度矩陣,并依據相似度矩陣給出推薦列表。
Figure 3. The procedure of recommendation algorithm based on knowledge graph
圖3. 基于知識圖譜的推薦算法流程
基于內容的推薦算法較為直觀,但其對于復雜屬性的項目較難處理。基于知識圖譜的推薦算法通過知識圖譜中實體之間豐富的關系能豐富項目和項目的聯系、增強推薦算法的挖掘能力,適合處理屬性復雜的項目,兩者進行結合,可以有效解決數據稀疏性的問題和新物品的“冷啟動”問題。
3. 基于知識圖譜與內容的推薦算法
基于知識圖譜與內容的推薦算法如圖4所示。包括三個部分:基于知識圖譜的相似度計算,基于內容的相似度計算和基于權值的融合算法,其中輸入為用戶的喜好信息。在基于知識圖譜的相似度計算部分,構建基于內容的知識圖譜,并基于知識圖譜嵌入計算得到實體與實體關系的相似度。在基于內容的相似度計算部分,基于文本詞嵌入對內容進行向量化表示,并構建算法對內容進行相似度計算。在基于權值的融合算法部分,融合了基于知識圖譜的相似度計算和基于內容的相似度計算結果,通過權重計算,選取準確率得分高的值作為推薦結果。
Figure 4. The framework of the algorithm based on knowledge graph and content
圖4. 基于知識圖譜與內容的推薦算法框架
3.1. 基于知識圖譜的相似度計算
雖然不同用戶對于同一種類型的物品的描述會有所不同,但是其表達語意大都類似。例如,對于電影《東邪西毒》,用戶A認為它是武俠片,用戶B認為它是動作片,這是因為武俠片和動作片時有部分交疊的。利用不同用戶的偏好特征,挖掘其語義特征,能夠更完善地對物品進行描述,將更有利于對用戶感興趣物品的判斷。因此,本文利用概念知識圖譜,通過對概念的文本及知識的語義描述,在知識圖譜中發現相似的概念。
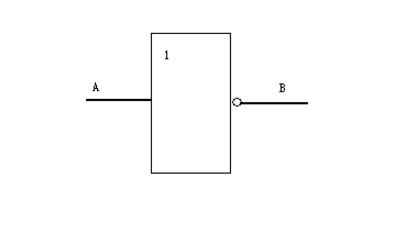
基于知識圖譜的相似度計算方法如下:首先,根據物品知識及用戶知識構建物品知識圖譜,并將原有的物品信息及用戶信息轉化為三元組的形式,將這些三元組存儲在知識圖譜中,作為進一步的查詢基礎。然后通過TransE (Translating Embeddings)模型對物品三元組進行知識表示,其中TransE模型以 h+r≈th+r≈t 為基本思想對實體和關系做低維空間映射 [13],知識的表示嵌入如圖5所示。如“金陵十三釵”向量為實體h,“電影類型”向量為關系r,“戰爭片”向量為實體t,因此可獲得物品實體的低維稠密向量表示為 eheh。
Figure 5. An example of algorithm TransE
圖5. TransE算法案例
根據以上算法,構建了知識圖譜對物品的知識表示,計算了兩個物品的相似度,由此可以生成一個物品相似度的矩陣。
3.2. 基于內容的相似度計算
基于內容的相似度計算算法提取用戶的偏好特征以及物品的描述特征,利用特征表示方法,在特征表示的基礎上計算用戶的偏好特征與物品的描述特征之間的相似度,從而實現高效準確的推薦 [14],具體步驟如下:首先對文本中的評價信息進行中文分詞;其次利用詞頻–逆文檔頻率(Terms Frequency-Inverse Document Frequency, TF-IDF)計算詞的權重;再次利用word2vec計算用戶特征和物品特征的詞向量,用向量表示詞的語義信息;然后利用詞向量構建物品向量,當一個物品包含多個關鍵詞,且每一個關鍵詞對應一個詞向量時,可以利用加權算法構建物品向量;最后基于用戶特征和物品特征的表示向量的相似度做推薦 [15]。
本文基于余弦相似度對物品向量的相似度做出評價,將用戶對某個物品的在n個方面的評分當成一個n維向量值 SniSni,則某個物品 IiIi 的評分向量為 Ii={S1i,S2i,?,Ski,?,Sni}Ii={S1i,S2i,?,Ski,?,Sni}, SkiSki 代表物品第k個方面的評分向量值。同樣地,物品 IjIj 的評分向量為 Ij={S1j,S2j,?,Skj,?,Snj}Ij={S1j,S2j,?,Skj,?,Snj}。計算 IiIi 與 IjIj 的余弦相似度:
如果余弦相似度得到的值大,則說明兩個物體間的相似度高,可推薦性就高;反之,余弦相似度的到的值越小,說明兩個物體間的相似程度低,可推薦性小。
3.3. 基于權值的融合算法
基于權值的融合算法結合基于知識圖譜計算出的相似度與基于內容計算出的相似度,選擇合適的權值進行算法融合,得到最終的綜合相似度;最后,將綜合相似度的結果作為是否推薦的依據。由于知識圖譜中含有豐富的實體信息,而用戶的文本信息中則蘊含了用戶的偏好特征,故分別設置其加權系數為 αα 和 ββ, αα 和 ββ 的取值范圍均在 [0,1][0,1] 之間,且 α+β=1α+β=1,關于 αα 和 ββ 合適的取值需要通過大量的實驗來獲得。融合后的物品間相似度結果,如下式所示:
其中, sim(Ii,Ij)sim(Ii,Ij) 是 IiIi 與 IjIj 的相似度, SujSuj 表示用戶對 IjIj 的評分, R(u)R(u) 表示用戶U評分過的物品的集合, S(i,k)S(i,k) 表示前k個與物品 IiIi 最相似的物品。用戶對 IjIj 物品的評分越高,同時物品 IiIi 與物品 IjIj 相似度越高,則 PuiPui 的值越大。通過計算每一位用戶的未點擊物品的預測評分 PuiPui,形成最終的 TOP?kTOP?k 推薦列表。
4. 實驗驗證
本節主要對所提的基于知識圖譜與內容的推薦算法開展實驗驗證。算法使用python3.8實現,在以Anaconda為環境的工作站上進行。
4.1. 數據集
實驗將使用MovieLens電影數據集中的1M數據集來驗證本文算法的準確性。構建電影知識圖譜數據集引用TMDB數據集,TMDB是一個包含詳細電影數據的數據庫。其中,本文在構建電影知識圖譜時只保留每部影視的主演實體,為降低圖譜的構建復雜度,實驗中構建電影知識圖譜時控制每部電影演員的實體數量不多于5個。圖6為使用TMDB數據集構建的知識圖譜(局部)。不同顏色表示不同的節點類型,其中黃色節點為電影演員,藍色節點為影片。演員作為父節點,電影作為子節點,父子節點用具體關系鏈接,大幅度減少從子節點到父節點的鏈接。
Figure 6. The movie graph used in experiment
圖6. 構建完成的電影圖譜
4.2. 對比算法
本文選取以下具有代表性的推薦算法進行推薦性能對比:
1) 深度知識注意力網絡(Deep Knowledge-Aware Networks, DKN):融合了實體嵌入和詞嵌入,為每個輸入新聞生成一個知識感知嵌入向量,然后對用戶進行動態建模,其中物品和書籍的標題用于生成詞嵌入,實體嵌入由TransH(Translating on Hyperplanes)學習 [8];
2) LibFM (Lithium Bis Fuoromalonato):將用戶ID、商品ID以及從TransR (Translating Relations)獲得的實體嵌入結合起來,作為LibFM的輸入 [4];
3) PER (Personalized Entity Recognition):將知識圖譜視為一個異構信息網絡(Heterogeneous Information Network, HIN),并提取基于元路徑的特征來表示用戶和項目之間的連通性 [10]。
4.3. 評估準則
在實驗驗證中,采用準確率和召回率進行推薦算法的性能評價。準確率(Precision, P)表示是預測用戶感興趣的物品為正確的結果的數量。計算公式為:
 4.4. 近鄰數對推薦性能的影響分析
4.4. 近鄰數對推薦性能的影響分析
本文通過7折交叉驗證的方法,在實驗中隨機選取70%的數據作為訓練集,30%的數據作為測試集。由于基于知識圖譜的相似度計算的精度是由節點的近鄰數所決定的,近鄰數越高,精確越低,但推薦結果越能覆蓋用戶感興趣的物品。因此,為了求得最佳結果,分別取近鄰數為5、10、25、50、70、100,并且重復進行10次取平均值作為最終結果。本文選取 α=0.7,β=0.3α=0.7,β=0.3。
圖7表示了不同近鄰數下召回率的變化關系,隨著近鄰數的增加,召回率越來越高,意味著覆蓋率越來越高。圖8表示了不同近鄰數下準確率的關系,隨著近鄰數的增加,準確率越來越低,意味著推薦
Figure 7. The movie graph used in experiment
圖7. 構建完成的電影圖譜
Figure 8. The precision of different nearest neighbor
圖8. 不同近鄰數下的準確率
結果的錯誤概率越來越高。從圖7和圖8中可以看出,當選取不同的近鄰數時,推薦給用戶的物品的召回率與準確率有所差異,這是由于當選取的近鄰數越多時,對用戶的偏好特征掌握越詳細,因此推薦給用戶的物品占用戶所感興趣的物品的比例會有所提升,但是當近鄰數足夠大時,對用戶的偏好掌握已經足夠,因此召回率會趨于平穩。但是當選取的近鄰數越多時,相似的用戶及物品也就越多,剔除掉用戶曾經購買或點擊過的物品,剩余的物品依舊數量龐大,用戶點擊或購買的物品占推薦物品的總數會有所下降,因此準確率會有所下降。可見,在一個完備的推薦系統中,近鄰數的選取并不是越大越好,而是應該進行適當的選擇。
4.5. 對比實驗
通過計算不同近鄰數下的召回率和準確率來驗證本文算法的性能。近鄰數選擇1、5、10、25、50、100,取10次結果并求平均值。實驗結果如圖9、圖10所示。
Figure 9. The recall of different nearest neighbor
圖9. 不同近鄰數的召回率
Figure 10. The precision of different nearest neighbor
圖10. 不同近鄰數的準確率
圖9展示了不同近鄰數下的召回率。近鄰數越多,召回率越高,意味著覆蓋率越高。在相同近鄰數下,本文所提算法的召回率均高于其它算法。圖10展示了不同近鄰數下的準確率。近鄰數越多,準確率越低,這表明推薦的結果中出現錯誤推薦的數量越高。在相同近鄰數下,本文算法的準確率均高于其他算法。這表明,利用實體之間的多關系和屬性進行相似度計算能夠提升算法的性能。由上圖所示對比結果可以進一步看出:與其他算法相比,DKN的表現最差,這是由于DKN對實體的表征不明確,無法為個性化推薦提供有用的信息;PER算法的推薦結果良好,但是由于用戶定義的元路徑很難達到最佳,所以當近鄰數達到一定程度時,PER算法的推薦性能作用有限;LibFM算法作為一種通用的推薦工具,在進行推薦時,準確率一直保持在較高水準,這表明LibFM算法可以很好地利用知識圖譜的知識進行個性化推薦。而本文所提算法與上述推薦算法相比,當近鄰數在100時召回率提升了約1%,準確率提升了約10%,說明本文算法是有效的。
5. 結束語
本文提出了一種基于知識圖譜與內容的推薦算法。利用用戶數據解析內容并構建知識圖譜,在知識圖譜相似度計算和內容的相似度計算基礎上,設計融合算法,完成對內容的啟發式推薦。與通用算法的對比實驗證明了本文算法具有較高的召回率和準確率。
后續研究開展可以考慮聯合實體的多個關聯關系及多跳關系,利用其他的Trans系列模型或者知識表示模型進行知識圖譜實體嵌入,以更充分地學習實體的表示向量,描述實體的語義信息,實現更進一步的推薦。
審核編輯:湯梓紅



























 工商網監
工商網監
評論