 電子發燒友App
電子發燒友App


TLB的作用及工作過程
頁表一般都很大,并且存放在內存中,所以處理器引入MMU后,讀取指令、數據需要訪問兩次內存:首先通過查詢頁表得到物理地址,然后訪問該物理地址讀取指令、數據。為了減少因為MMU導致的處理器性能下降,引入了TLB,TLB是Translation Lookaside Buffer的簡稱,可翻譯為“地址轉換后援緩沖器”,也可簡稱為“快表”。簡單地說,TLB就是頁表的Cache,其中存儲了當前最可能被訪問到的頁表項,其內容是部分頁表項的一個副本。只有在TLB無法完成地址翻譯任務時,才會到內存中查詢頁表,這樣就減少了頁表查詢導致的處理器性能下降。
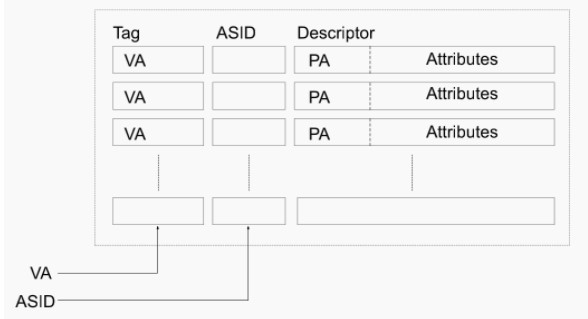
TLB中的項由兩部分組成:標識和數據。標識中存放的是虛地址的一部分,而數據部分中存放物理頁號、存儲保護信息以及其他一些輔助信息。虛地址與TLB中項的映射方式有三種:全關聯方式、直接映射方式、分組關聯方式。OR1200處理器中實現的是直接映射方式,所以本書只對直接映射方式作介紹。直接映射方式是指每一個虛擬地址只能映射到TLB中唯一的一個表項。假設內存頁大小是8KB,TLB中有64項,采用直接映射方式時的TLB變換原理如圖10.4所示。
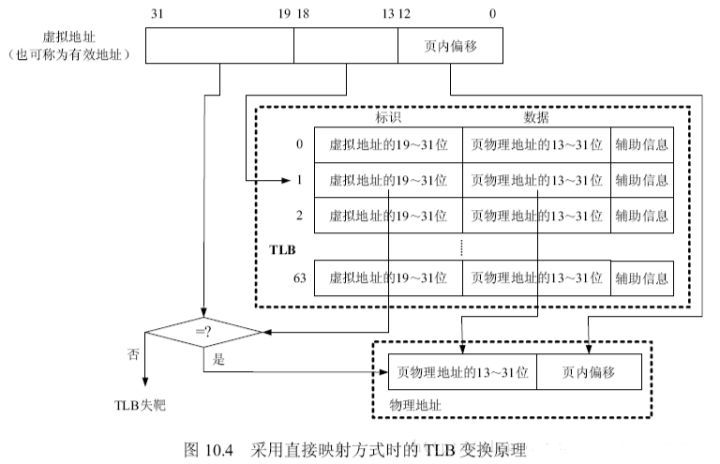
?
因為頁大小是8KB,所以虛擬地址的0-12bit作為頁內地址偏移。TLB表有64項,所以虛擬地址的13-18bit作為TLB表項的索引。假如虛擬地址的13-18bit是1,那么就會查詢TLB的第1項,從中取出標識,與虛擬地址的19-31位作比較,如果相等,表示TLB命中,反之,表示TLB失靶。TLB失靶時,可以由硬件將需要的頁表項加載入TLB,也可由軟件加載,具體取決于處理器設計,OR1200沒有提供硬件加載頁表項的功能,只能由軟件實現。TLB命中時,此時翻譯得到的物理地址就是TLB第1項中的標識(即物理地址13-31位)與虛擬地址0-12bit的結合。在地址翻譯的過程中還會結合TLB項中的輔助信息判斷是否發生違反安全策略的情況,比如:要修改某一頁,但該頁是禁止修改的,此時就違反了安全策略,會觸發異常。
OR1200中的MMU分為指令MMU、數據MMU,分別簡稱為IMMU、DMMU。采用的是頁式內存管理機制,每一頁大小是8KB,沒有實現頁表管理、頁表查詢、更新、鎖定等功能,都需要軟件實現。實際上OR1200的MMU模塊主要實現的就是TLB,OR1200中TLB的大小可以配置,默認是64項,采用的是直接映射方式。IMMU中有ITLB,DMMU中有DTLB,但是ITLB、DTLB的加載、更新、失效、替換等功能也都需要軟件實現。本章從下一節開始將分別對IMMU、DMMU進行分析。
TLB工作原理
TLB - translation lookaside buffer
快表,直譯為旁路快表緩沖,也可以理解為頁表緩沖,地址變換高速緩存。
由于頁表存放在主存中,因此程序每次訪存至少需要兩次:一次訪存獲取物理地址,第二次訪存才獲得數據。提高訪存性能的關鍵在于依靠頁表的訪問局部性。當一個轉換的虛擬頁號被使用時,它可能在不久的將來再次被使用到,。
TLB是一種高速緩存,內存管理硬件使用它來改善虛擬地址到物理地址的轉換速度。當前所有的個人桌面,筆記本和服務器處理器都使用TLB來進行虛擬地址到物理地址的映射。使用TLB內核可以快速的找到虛擬地址指向物理地址,而不需要請求RAM內存獲取虛擬地址到物理地址的映射關系。這與data cache和instruction caches有很大的相似之處。
TLB原理
當cpu要訪問一個虛擬地址/線性地址時,CPU會首先根據虛擬地址的高20位(20是x86特定的,不同架構有不同的值)在TLB中查找。如果是表中沒有相應的表項,稱為TLB miss,需要通過訪問慢速RAM中的頁表計算出相應的物理地址。同時,物理地址被存放在一個TLB表項中,以后對同一線性地址的訪問,直接從TLB表項中獲取物理地址即可,稱為TLB hit。
想像一下x86_32架構下沒有TLB的存在時的情況,對線性地址的訪問,首先從PGD中獲取PTE(第一次內存訪問),在PTE中獲取頁框地址(第二次內存訪問),最后訪問物理地址,總共需要3次RAM的訪問。如果有TLB存在,并且TLB hit,那么只需要一次RAM訪問即可。
TLB表項
TLB內部存放的基本單位是頁表條目,對應著RAM中存放的頁表條目。頁表條目的大小固定不變的,所以TLB容量越大,所能存放的頁表條目越多,TLB hit的幾率也越大。但是TLB容量畢竟是有限的,因此RAM頁表和TLB頁表條目無法做到一一對應。因此CPU收到一個線性地址,那么必須快速做兩個判斷:
所需的也表示否已經緩存在TLB內部(TLB miss或者TLB hit)
所需的頁表在TLB的哪個條目內
為了盡量減少CPU做出這些判斷所需的時間,那么就必須在TLB頁表條目和內存頁表條目之間的對應方式做足功夫
全相連 - full associative
在這種組織方式下,TLB cache中的表項和線性地址之間沒有任何關系,也就是說,一個TLB表項可以和任意線性地址的頁表項關聯。這種關聯方式使得TLB表項空間的利用率最大。但是延遲也可能相當的大,因為每次CPU請求,TLB硬件都把線性地址和TLB的表項逐一比較,直到TLB hit或者所有TLB表項比較完成。特別是隨著CPU緩存越來越大,需要比較大量的TLB表項,所以這種組織方式只適合小容量TLB
直接匹配
每一個線性地址塊都可通過模運算對應到唯一的TLB表項,這樣只需進行一次比較,降低了TLB內比較的延遲。但是這個方式產生沖突的幾率非常高,導致TLB miss的發生,降低了命中率。
比如,我們假定TLB cache共包含16個表項,CPU順序訪問以下線性地址塊:1, 17 , 1, 33。當CPU訪問地址塊1時,1 mod 16 = 1,TLB查看它的第一個頁表項是否包含指定的線性地址塊1,包含則命中,否則從RAM裝入;然后CPU方位地址塊17,17 mod 16 = 1,TLB發現它的第一個頁表項對應的不是線性地址塊17,TLB miss發生,TLB訪問RAM把地址塊17的頁表項裝入TLB;CPU接下來訪問地址塊1,此時又發生了miss,TLB只好訪問RAM重新裝入地址塊1對應的頁表項。因此在某些特定訪問模式下,直接匹配的性能差到了極點
組相連 - set-associative
為了解決全相連內部比較效率低和直接匹配的沖突,引入了組相連。這種方式把所有的TLB表項分成多個組,每個線性地址塊對應的不再是一個TLB表項,而是一個TLB表項組。CPU做地址轉換時,首先計算線性地址塊對應哪個TLB表項組,然后在這個TLB表項組順序比對。按照組長度,我們可以稱之為2路,4路,8路。
經過長期的工程實踐,發現8路組相連是一個性能分界點。8路組相連的命中率幾乎和全相連命中率幾乎一樣,超過8路,組內對比延遲帶來的缺點就超過命中率提高帶來的好處了。
這三種方式各有優缺點,組相連是個折衷的選擇,適合大部分應用環境。當然針對不同的領域,也可以采用其他的cache組織形式。
TLB表項更新
TLB表項更新可以有TLB硬件自動發起,也可以有軟件主動更新
TLB miss發生后,CPU從RAM獲取頁表項,會自動更新TLB表項
TLB中的表項在某些情況下是無效的,比如進程切換,更改內核頁表等,此時CPU硬件不知道哪些TLB表項是無效的,只能由軟件在這些場景下,刷新TLB。
在linux kernel軟件層,提供了豐富的TLB表項刷新方法,但是不同的體系結構提供的硬件接口不同。比如x86_32僅提供了兩種硬件接口來刷新TLB表項:
向cr3寄存器寫入值時,會導致處理器自動刷新非全局頁的TLB表項
在Pentium Pro以后,invlpg匯編指令用來無效指定線性地址的單個TLB表項無效。
MMU和cache詳解(TLB機制)
1. MMU
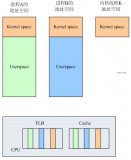
MMU:memory management unit,稱為內存管理單元,或者是存儲器管理單元,MMU是硬件設備,它被保存在主存(main memory)的兩級也表控制,并且是由協處理器CP15的寄存器1的M位來決定是enabled還是disabled。MMU的主要作用是負責從CPU內核發出的虛擬地址到物理地址的映射,并提供硬件機制的內存訪問權限檢查。MMU使得每個用戶進程擁有自己的地址空間(對于WINCE5.0,每個進程是32MB;而對于WINCE6.0,每個進程的獨占的虛擬空間是2GB),并通過內存訪問權限的檢查保護每個進程所用的內存不被其他進程破壞。
下面是MMU提供的功能和及其特征

?
VA和PA
VA:virtual address稱為虛擬地址,PA:physical address稱為物理地址。CPU通過地址來訪問內存中的單元,如果CPU沒有MMU,或者有MMU但沒有啟動,那么CPU內核在取指令或者訪問內存時發出的地址(此時必須是物理地址,假如是虛擬地址,那么當前的動作無效)將直接傳到CPU芯片的外部地址引腳上,直接被內存芯片(物理內存)接收,這時候的地址就是物理地址。如果CPU啟用了MMU(一般是在bootloader中的eboot階段的進入main()函數的時候啟用),CPU內核發出的地址將被MMU截獲,這時候從CPU到MMU的地址稱為虛擬地址,而MMU將這個VA翻譯成為PA發到CPU芯片的外部地址引腳上,也就是將VA映射到PA中。MMU將VA映射到PA是以頁(page)為單位的,對于32位的CPU,通常一頁為4k,物理內存中的一個物理頁面稱頁為一個頁框(page frame)。虛擬地址空間劃分成稱為頁(page)的單位,而相應的物理地址空間也被進行劃分,單位是頁框(frame).頁和頁框的大小必須相同。
VA到PA的映射過程
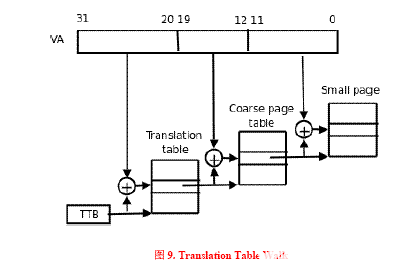
?
首先將CPU內核發送過來的32位VA[31:0]分成三段,前兩段VA[31:20]和VA[19:12]作為兩次查表的索引,第三段VA[11:0]作為頁內的偏移,查表的步驟如下:
從協處理器CP15的寄存器2(TTB寄存器,translation table base register)中取出保存在其中的第一級頁表(translation table)的基地址,這個基地址指的是PA,也就是說頁表是直接按照這個地址保存在物理內存中的。
以TTB中的內容為基地址,以VA[31:20]為索引值在一級頁表中查找出一項(2^12=4096項),這個頁表項(也稱為一個描述符,descriptor)保存著第二級頁表(coarse page table)的基地址,這同樣是物理地址,也就是說第二級頁表也是直接按這個地址存儲在物理內存中的。
以VA[19:12]為索引值在第二級頁表中查出一項(2^8=256),這個表項中就保存著物理頁面的基地址,我們知道虛擬內存管理是以頁為單位的,一個虛擬內存的頁映射到一個物理內存的頁框,從這里就可以得到印證,因為查表是以頁為單位來查的。
有了物理頁面的基地址之后,加上VA[11:0]這個偏移量(2^12=4KB)就可以取出相應地址上的數據了。
這個過程稱為Translation Table Walk,Walk這個詞用得非常形象。從TTB走到一級頁表,又走到二級頁表,又走到物理頁面,一次尋址其實是三次訪問物理內存。注意這個“走”的過程完全是硬件做的,每次CPU尋址時MMU就自動完成以上四步,不需要編寫指令指示MMU去做,前提是操作系統要維護頁表項的正確性,每次分配內存時填寫相應的頁表項,每次釋放內存時清除相應的頁表項,在必要的時候分配或釋放整個頁表。
CPU訪問內存時的硬件操作順序
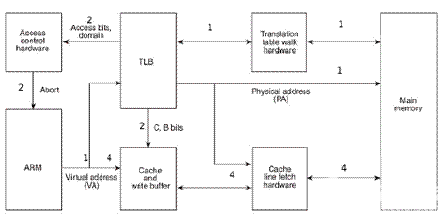
?
CPU訪問內存時的硬件操作順序,各步驟在圖中有對應的標號:
CPU內核(圖中的ARM)發出VA請求讀數據,TLB(translation lookaside buffer)接收到該地址,那為什么是TLB先接收到該地址呢?因為TLB是MMU中的一塊高速緩存(也是一種cache,是CPU內核和物理內存之間的cache),它緩存最近查找過的VA對應的頁表項,如果TLB里緩存了當前VA的頁表項就不必做translation table walk了,否則就去物理內存中讀出頁表項保存在TLB中,TLB緩存可以減少訪問物理內存的次數。
頁表項中不僅保存著物理頁面的基地址,還保存著權限和是否允許cache的標志。MMU首先檢查權限位,如果沒有訪問權限,就引發一個異常給CPU內核。然后檢查是否允許cache,如果允許cache就啟動cache和CPU內核互操作。
如果不允許cache,那直接發出PA從物理內存中讀取數據到CPU內核。
如果允許cache,則以VA為索引到cache中查找是否緩存了要讀取的數據,如果cache中已經緩存了該數據(稱為cache hit)則直接返回給CPU內核,如果cache中沒有緩存該數據(稱為cache miss),則發出PA從物理內存中讀取數據并緩存到cache中,同時返回給CPU內核。但是cache并不是只去CPU內核所需要的數據,而是把相鄰的數據都去上來緩存,這稱為一個cache line。ARM920T的cache line是32個字節,例如CPU內核要讀取地址0x30000134~0x3000137的4個字節數據,cache會把地址0x30000120~0x3000137(對齊到32字節地址邊界)的32字節都取上來緩存。
ARM920T支持多種尺寸規格的頁表
ARM體系結構最多使用兩級頁表來進行轉換,頁表由一個個條目組成,每個條目存儲一段虛擬地址對應的物理地址及訪問權限,或者下一級頁表的地址。S3C2443最多會用到兩級頁表,已段(section,大小為1M)的方式進行轉換時只用到一級頁表,以頁(page)的方式進行轉換時用到兩級頁表。而頁的大小有3種:大頁(large pages,64KB),小頁(small pages,4KB)和極小頁(tiny pages,1KB)。條目也成為描述符,有段描述符、大頁描述符、小頁描述符和極小頁描述符,分別保存段、大頁、小頁和極小頁的起始物理地址,見下圖
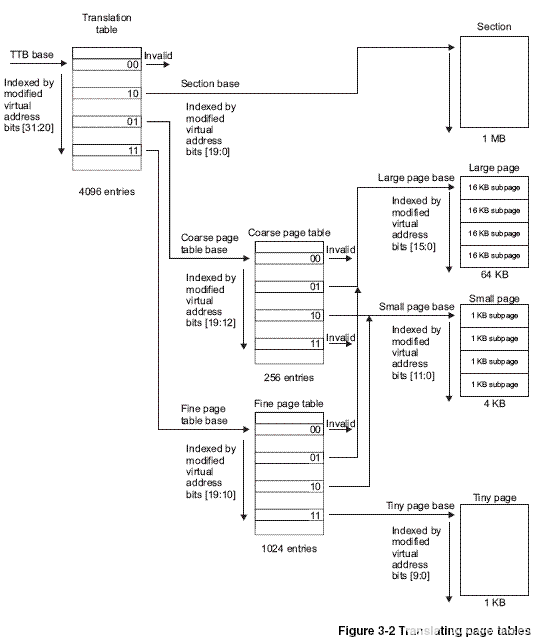
?
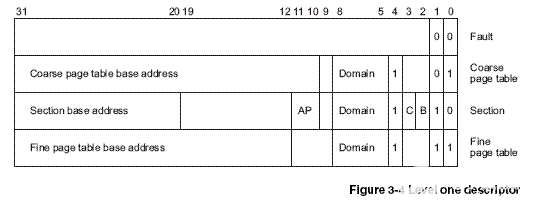
MMU的查表過程,首先從CP15的寄存器TTB找到一級頁表的基地址,再把VA[31:20]作為索引值從表中找出一項,這個表項稱為一級頁描述符(level one descriptor),一個這樣的表項占4個字節,那么一級頁表需要保存的物理內存的大小是4*4096=16KB,表項可以是一下四種格式之一:
?
如果描述符的最低位是00,屬于fault格式,表示該范圍的VA沒有映射到PA。
如果描述符的最低位是10,屬于section格式,這種格式沒有二級頁表而是直接映射到物理頁面,一個色彩體哦你是1M的大頁面,描述符中的VA[31:20]就是這個頁面的基地址,基地址的VA[19:0]低位全為0,對齊到1M地址邊界,描述符中的domain和AP位控制訪問權限,C、B兩位控制緩存。
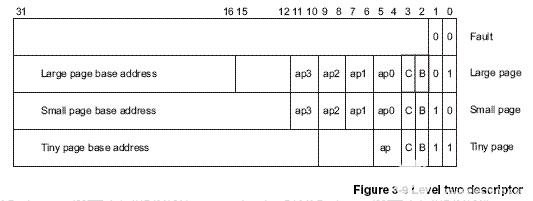
如果描述符的最低兩位是01或11,則分別對應兩種不同規格的二級頁表。根據地址對齊的規律想一下,這兩種頁表分別是多大?從一級描述符中取出二級頁表的基地址,再把VA的一部分作為索引去查二級描述符(level two descriptor),如果是coarse page,則VA[19:12](2^8=256)作為查找二級頁表表項的索引;如果是fine page,則VA[19:10](2^10=024)。二級描述符可以是下面四種格式之一:
?
二級描述符最低兩位是00是屬于fault格式,其它三種情況分別對應三種不同規格的物理頁面,分別是large page(64KB)、small page(4KB)和tiny page(1KB),其中large page和small page有4組AP權限位,每組兩個bit,這樣可以為每1/4個物理頁面分別設置不同的權限,也就是說large page可以為每16KB設置不同的權限,small page可以為每1KB設置不同的權限。
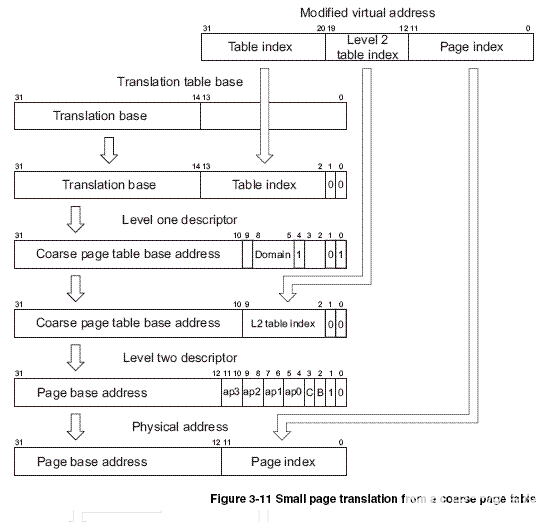
ARM920T提供了多種頁表和頁面規格,但操作系統只采用其中一種,WINCE采用的就是一級描述符是coarse page table格式(也即由VA[19:12]來作為查找二級頁表項的索引),二級描述符是small page格式(也即是VA[11:0]來作為查找物理頁面偏移量的索引),每個物理頁面大小是4KB。
?
根據上圖我們來分析translation table walk的過程
VA被劃分為三段用于地址映射過程,各段的長度取決于頁描述符的格式。
TTB寄存器中只有[31:14]位有效,低14位全為0,因此一級頁表的基地址對齊到16K地址邊界,而一級頁表的大小也是16K。
一級頁表的基地址加上VA[31:20]左移兩位組成一個物理地址。想一想為什么VA[31:20]要左移兩位占據[13:2]的位置,而空出[1:0]兩位呢?應該是需要空出最低兩位用于表示當前要尋找的一級描述符是coarse page格式,目前不清楚,有待了解。
用這個組裝的物理地址從物理內存中讀取一級頁表描述符,這是一個coarse page table格式的描述符。
通過domain權限檢查后,coarse page table的基地址再加上VA[19:12]左移兩位組裝成一個物理地址。
用這個組裝的物理地址從物理內存中讀取二級頁表描述符,這是一個small page格式的描述符。
通過AP權限檢查后,small page的基地址再加上VA[11:0]就是最終的物理地址了。
Linux內核-內存-硬件高速緩存和TLB原理
硬件高速緩存和TLB原理
基本概念
硬件高速緩存的引入是為了縮小CPU和RAM之間的速度不匹配,高速緩存單元插在分頁單元和主內存之間,它包含一個硬件高速緩存內存和一個高速緩存控制器。高速緩存內存存放內存中真正的行。高速緩存控制器存放一個表項數組,每個表項對應高速緩存內存中的一個行,如下圖:
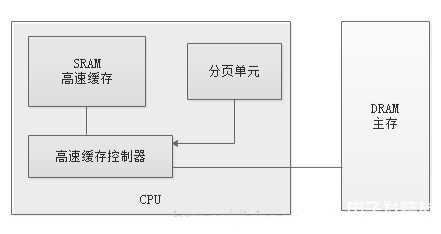
?
2.除了通用硬件高速緩存,80x86處理器還包含了另一個稱為轉換后援緩沖器或TLB(Translation Lookaside Buffer)的高速緩存用于加快線性地址的轉換。TLB是一個小的、虛擬尋址的緩存,其中的每一行都保存著一個由單個頁表條目組成的塊。
原理
下面通過一個具體的地址翻譯示例來說明緩存和TLB的原理(注意:這是簡化版的示例,實際過程可能復雜些,不過原理相同),地址翻譯基于以下設定:
存儲器是按字節尋址的
存儲器訪問是針對1字節的字的
虛擬地址(線性地址)是14位長的
物理地址是12位長的
頁面大小是64字節
TLB是四路組相連的,總共有16個條目
L1 Cache是物理尋址、直接映射的,行大小為4字節,總共有16個組
下面給出小存儲系統的一個快照,包括TLB、頁表的一部分和L1高速緩存
虛擬地址(TLBI為索引):

?
TLB:四組,16個條目,四路組相連(PPN為物理頁號):
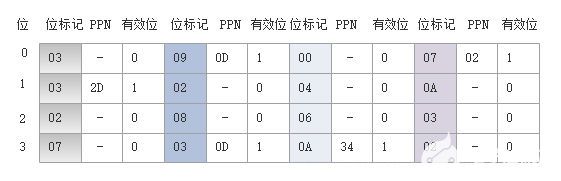
?
頁表:只展示前16個頁表條目(PTE)
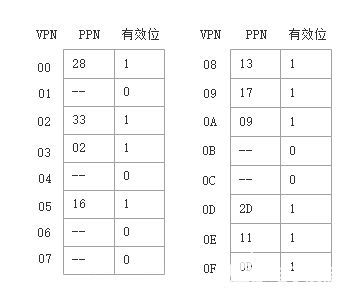
?
物理地址(CO為塊偏移):
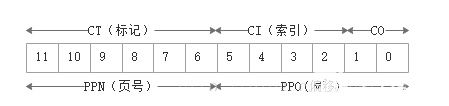
?
高速緩存:16個組,4字節的塊,直接映射
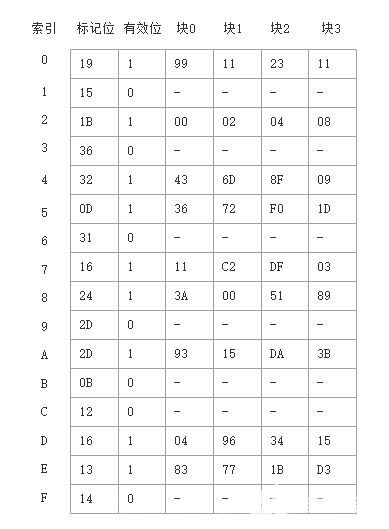
?
基于以上的設定,我們來看下當CPU執行一條讀地址0x3d4(虛擬地址)處字節的加載指令時發生了什么:
從0x3d4中取出如下幾個字段:
TLBT: 0x03
TLBI: 0x03
VPN: 0x0F
VPO: 0x14
?
首先,MMU從虛擬地址中取出以上字段,然后檢查TLB,看它是否因為前面的某個存儲器的引用而緩存了PTE0x0F的一個拷貝。TLB從VPN中抽取出TLB索引(TLBI:0x03)和TLB標記(TLBT:0x03),由上面的TLB表格可知,組0x3的第二個條目中有效匹配,所以命中,將緩存的PPN(0x0D)返回給MMU。
將上述的PPN(0x0D)和來自虛擬地址的VPO(0x14)連接起來,得到物理地址(0x354)。
接下來,MMU發送物理地址給緩存,緩存從物理地址中取出緩存偏移CO(0x0)、緩存組索引CI(0x5)以及緩存標記CT(0x0D)。
從上面高速緩存表格中可得,組0x5中的標記與CT相匹配,所以緩存檢測到一個命中,讀出在偏移量CO處的數據字節(0x36),并將它返回給MMU,隨后MMU將它傳遞回CPU。
?













 工商網監
工商網監
評論