 電子發燒友App
電子發燒友App


本文原標題How to Configure an Encoder-Decoder Model for Neural Machine Translation,作者為Jason Brownlee,全文由景智AI編譯。
翻譯/? 崔躍輝、葉倚青
校對/? 葉倚青
用于循環神經網絡的編碼-解碼架構,在標準機器翻譯基準上取得了最新的成果,并被用于工業翻譯服務的核心。
該模型很簡單,但是考慮到訓練所需的大量數據,以及調整模型中無數的設計方案,想要獲得最佳的性能是非常困難的。值得慶幸的是,研究科學家已經使用谷歌規模的硬件為我們做了這項工作,并提供了一套啟發式的方法,來配置神經機器翻譯的編碼-解碼模型和預測一般的序列。
在景智AI網這篇譯文中,您將會獲得,在神經機器翻譯和其他自然語言處理任務中,如何最好地配置編碼-解碼循環神經網絡的各種細節。
閱讀完景智AI網譯文后,你將知道:
谷歌的研究調查了各個模型針對編碼-解碼的設計方案,以此來分離出它們的作用效果。
關于一些設計方案的結果和建議,諸如關于詞嵌入、編碼和解碼深度以及注意力機制。
一系列基礎模型設計方案,它們可以作為你自己的序列到序列的項目的起始點。
讓我們開始吧:
Sporting Park
神經網絡機器翻譯的編碼-解碼模型
用于循環神經網絡的編碼-解碼架構,取代了經典的基于短語的統計機器翻譯系統,以獲得最新的結果。
根據他們2016年發表的論文“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”,谷歌現已在他們的Google翻譯服務的核心中使用這種方法。
這種架構的問題是模型很大,需要非常大量的數據集來訓練。 這受到模型訓練花費數天或數周的影響,并且需要非常昂貴的計算資源。 因此,關于不同設計選擇對模型的影響及其對模型技能的影響,已經做了很少的工作。
Denny Britz等人清楚地給出了解決方案。 在他們的2017年論文“神經機器翻譯體系的大量探索”中,他們為標準的英德翻譯任務設計了一個基準模型,列舉了一套不同的模型設計選擇,并描述了它們對技能的影響。他們聲稱,完整的實驗耗費了超過250,000個GPU計算時間,至少可以說是令人印象深刻的。
我們報告了數百次實驗運行的實驗結果和方差數,對應于標準WMT英語到德語翻譯任務超過250,000個GPU小時。我們的實驗為建立和擴展NMT體系結構提供了新的見解和實用建議 。
在本文中,我們將審視這篇文章的一些發現,我們可以用它來調整我們自己的神經網絡機器翻譯模型,以及一般的序列到序列模型 。
有關編碼-解碼體系結構和注意力機制的更多背景信息,請參閱以下文章:
Encoder-Decoder Long Short-Term Memory Networks
Attention in Long Short-Term Memory Recurrent Neural Networks
基線模型
我們可以通過描述用作所有實驗起點的基線模型開始。
選擇基線模型配置,使得模型在翻譯任務上能夠很好地執行。
嵌入:512維
RNN小區: 門控循環單元或GRU
編碼器:雙向
編碼深度: 2層 (每個方向一層)
解碼深度:2層
注意: Bahdanau風格
優化器:Adam
信息丟失:20%的投入
每個實驗都從基準模型開始,并且改變了一個要素,試圖隔離設計決策對模型技能的影響,在這種情況下,BLEU得分。
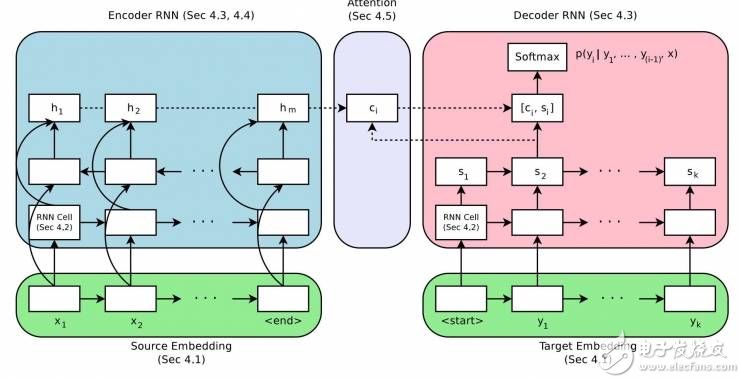
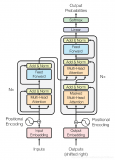
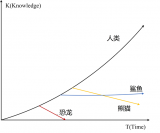
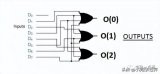
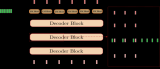
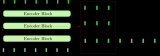
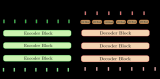
神經網絡機器翻譯的編碼-解碼體系結構
取自“Massive Exploration of Neural Machine Translation Architectures”
嵌入大小
一個詞嵌入(word embedding)用于表示單詞輸入到編碼器。
這是一個分散表示(distributed representation),其中每個單詞映射到一個具有連續值的固定大小向量上。這種方法的好處是,具有相似含義的不同詞語將具有類似的表示。
通常在訓練數據上擬合模型時學習這種分散表示。嵌入大小定義了用于表示單詞的矢量長度。一般認為,更大的維度會導致更具表現力的表示(representation),反過來功能更好。
有趣的是,結果顯示最大尺寸的測試確實取得了最好的結果,但增加尺寸的收益總體來說較小。
[結果顯示] 2048維的嵌入取得最佳的整體效果,他們只小幅這樣做了。即使是很小的128維嵌入也表現出色,收斂速度幾乎快了一倍。??
建議:從一個小的嵌入大小開始,比如128,也許稍后增加尺寸會輕微增強功能。
RNN 單元種類共有三種常用的循環神經網絡(RNN):
簡單循環神經網絡
長短期記憶網絡(LSTM)
門控循環單元(GRU)
LSTM是為了解決簡單循環神經網絡中限制循環神經網絡深度學習的梯度消失問題而開發的。GRU是為了簡化LSTM而開發的。結果顯示GRU和LSTM都顯著強于簡單RNN,但是LSTM總體上更好。
在我們的實驗中,LSTM?? 單元始終勝過GRU單元。
建議:在你的模型中使用LSTM RNN單元。
編碼-解碼深度
通常認為,深度網絡比淺層網絡表現更好。
關鍵在于找到網絡深度、模型功能和訓練時間之間的平衡。 這是因為,如果對功能的改善微小,我們一般沒有無窮的資源來訓練超深度網絡。
作者正在探索編碼模型和解碼模型的深度,以及對模型功能的影響。
說到編碼,研究發現深度對功能并沒有顯著影響,更驚人的是,一個1層的雙向模型僅優于一個4層的結構很少。一個2層雙向編碼器只比其他經測試的結構強一點點。
我們沒有發現確鑿證據可以證明編碼深度有必要超過兩層。
建議:?使用1層的雙向編碼器,然后擴展到2個雙向層,以此將功能小幅度強化。
關于解碼器也是類似的。1,2,4層的解碼器之間的功能差異很小。4層的解碼器略勝一籌。8層解碼器在測試條件下沒有收斂。
在解碼器這里,深度模型比淺層模型表現略好。
建議:用1層的解碼器作為起步,然后用4層的解碼器獲得更優的結果。
編碼器輸入的方向
源文本序列可以通過以下幾種順序發送給編碼器:
正向,即通常的方式
反向
正反向同時進行
作者發現了輸入序列的順序對模型功能的影響,相較于其他多種單向、雙向結構。
總之,他們證實了先前的發現:反向序列優于正向序列、雙向的比反向序列略好。
……雙向編碼器通常比單向編碼器表現更好,但不是絕對優勢。具有反向數據源的編碼器全部優于和它們相當的未反向的對照。
建議:使用反向輸入序列或者轉變為雙向,以此將功能小幅度強化。
注意力機制
原始的編碼-解碼模型有一個問題:編碼器會將輸入信息安排進一個固定長度的內部表達式,而解碼器必須從其中計算出整個輸出序列。
注意力機制是一個進步,它允許編碼器“關注”輸入序列中不同的字符并在輸出序列中分別輸出。
作者觀察了幾種簡單的注意力機制的變種。結果顯示具備注意力機制將大幅提升模型表現。
當我們期待基于注意力機制的模型完勝時,才驚訝地發現沒有“注意力”地模型表現多么糟糕。
Bahdanau, et al. 在他們2015年的論文“Neural machine translation by jointly learning to align and translate”中表述的一種簡單加權平均的注意力機制表現最好。
建議:使用注意力機制并優先使用Bahdanau的加權平均的注意力機制。
推斷
神經系統機器翻譯常常使用集束搜索來對模型輸出序列中的單詞的概率取樣。
通常認為,集束的寬度越寬,搜索就越全面,結果就越好。
結果顯示,3-5的適中的集束寬度表現最好,通過長度折損僅能略微優化。作者建議針對特定問題調節寬度。
我們發現,調節準確的集束搜索對好結果的取得非常關鍵,它可以持續獲得不止一個的BLE點。
建議:從貪婪式搜索開始(集束=1) 并且根據你的具體問題調節。
最終模型
作者把他們的發現都應用在同一個“最好的模型”中,然后將這個模型的結果與其他表現突出的模型和體現最高水平的結果比較。
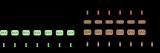
此模型的具體配置如下表,摘自論文。當你為自然語言處理程序開發自己的編碼-解碼模型時,這些參數可以作為一個好的起始點。
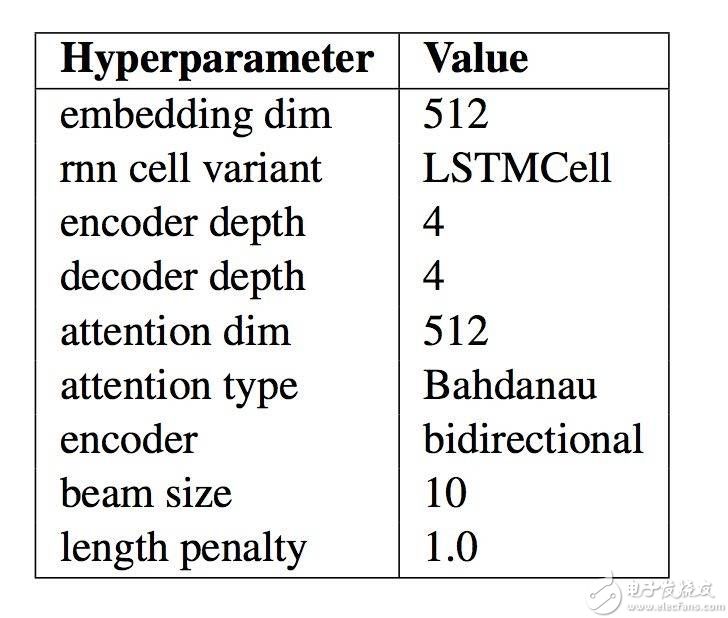
最終的神經網絡機器翻譯模型的模型配置總結
“Massive Exploration of Neural Machine Translation Architectures”
此系統的結果令人印象深刻,它用更簡單的模型達到了接近最先進的水平,而這并不是論文的最終目標。
……我們確實證明了通過仔細的超參數調整和優良的初始化,基于標準的WMT也可能達到最先進的水平。
很重要的一點,作者將他們的代碼作為了開源項目,稱作“tf-seq2seq”。2017年,因為其中兩位作者時谷歌的大腦訓練項目的成員,他們的成果在谷歌研究博客上發布,標題為“Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow“。
延伸閱讀
如果你想深入了解,這部分提供關于此話題的更多資源。
Massive Exploration of Neural Machine Translation Architectures, 2017.
Denny Britz Homepage
WildML Blog
Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow, 2017.
tf-seq2seq: A general-purpose encoder-decoder framework for Tensorflow
tf-seq2seq Project Documentation
tf-seq2seq Tutorial: Neural Machine Translation Background
Neural machine translation by jointly learning to align and translate, 2015.
總結
本文闡述了在神經網絡機器翻譯系統和其他自然語言處理任務中,如何最好地配置一個編碼-解碼循環神經網絡。具體是這些:
谷歌的研究調查了各個模型針對編碼-解碼的設計方案,以此來分離出它們的作用效果。
關于一些設計方案的結果和建議,諸如關于詞嵌入、編碼和解碼深度以及注意力機制。
一系列基礎模型設計方案,它們可以作為你自己的序列到序列的項目的起始點。



































 工商網監
工商網監
評論